深度學(xué)習(xí)實戰(zhàn):手把手教你構(gòu)建多任務(wù)、多標簽?zāi)P?/h1>
多任務(wù)多標簽?zāi)P褪乾F(xiàn)代機器學(xué)習(xí)中的基礎(chǔ)架構(gòu),這個任務(wù)在概念上很簡單 -訓(xùn)練一個模型同時預(yù)測多個任務(wù)的多個輸出。
在本文中,我們將基于流行的 MovieLens 數(shù)據(jù)集,使用稀疏特征來創(chuàng)建一個多任務(wù)多標簽?zāi)P?并逐步介紹整個過程。所以本文將涵蓋數(shù)據(jù)準備、模型構(gòu)建、訓(xùn)練循環(huán)、模型診斷,最后使用 Ray Serve 部署模型的全部流程。
1.設(shè)置環(huán)境
在深入代碼之前,請確保安裝了必要的庫(以下不是詳盡列表):
pip install pandas scikit-learn torch ray[serve] matplotlib requests tensorboard我們在這里使用的數(shù)據(jù)集足夠小,所以可以使用 CPU 進行訓(xùn)練。
2.準備數(shù)據(jù)集
我們將從創(chuàng)建用于處理 MovieLens 數(shù)據(jù)集的下載、預(yù)處理的類開始,然后將數(shù)據(jù)分割為訓(xùn)練集和測試集。
MovieLens數(shù)據(jù)集包含有關(guān)用戶、電影及其評分的信息,我們將用它來預(yù)測評分(回歸任務(wù))和用戶是否喜歡這部電影(二元分類任務(wù))。
import os
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import torch
from torch.utils.data import Dataset, DataLoader
import zipfile
import io
import requests
class MovieLensDataset(Dataset):
def __init__(self, dataset_version="small", data_dir="data"):
print("Initializing MovieLensDataset...")
if not os.path.exists(data_dir):
os.makedirs(data_dir)
if dataset_version == "small":
url = "https://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
local_zip_path = os.path.join(data_dir, "ml-latest-small.zip")
file_path = 'ml-latest-small/ratings.csv'
parquet_path = os.path.join(data_dir, "ml-latest-small.parquet")
elif dataset_version == "full":
url = "https://files.grouplens.org/datasets/movielens/ml-latest.zip"
local_zip_path = os.path.join(data_dir, "ml-latest.zip")
file_path = 'ml-latest/ratings.csv'
parquet_path = os.path.join(data_dir, "ml-latest.parquet")
else:
raise ValueError("Invalid dataset_version. Choose 'small' or 'full'.")
if os.path.exists(parquet_path):
print(f"Loading dataset from {parquet_path}...")
movielens = pd.read_parquet(parquet_path)
else:
if not os.path.exists(local_zip_path):
print(f"Downloading {dataset_version} dataset from {url}...")
response = requests.get(url)
with open(local_zip_path, "wb") as f:
f.write(response.content)
with zipfile.ZipFile(local_zip_path, "r") as z:
with z.open(file_path) as f:
movielens = pd.read_csv(f, usecols=['userId', 'movieId', 'rating'], low_memory=True)
movielens.to_parquet(parquet_path, index=False)
movielens['liked'] = (movielens['rating'] >= 4).astype(int)
self.user_encoder = LabelEncoder()
self.movie_encoder = LabelEncoder()
movielens['user'] = self.user_encoder.fit_transform(movielens['userId'])
movielens['movie'] = self.movie_encoder.fit_transform(movielens['movieId'])
self.train_df, self.test_df = train_test_split(movielens, test_size=0.2, random_state=42)
def get_data(self, split="train"):
if split == "train":
data = self.train_df
elif split == "test":
data = self.test_df
else:
raise ValueError("Invalid split. Choose 'train' or 'test'.")
dense_features = torch.tensor(data[['user', 'movie']].values, dtype=torch.long)
labels = torch.tensor(data[['rating', 'liked']].values, dtype=torch.float32)
return dense_features, labels
def get_encoders(self):
return self.user_encoder, self.movie_encoder定義了 MovieLensDataset,就可以將訓(xùn)練集和評估集加載到內(nèi)存中
# Example usage with a single dataset object
print("Creating MovieLens dataset...")
# Feel free to use dataset_version="full" if you are using
# a GPU
dataset = MovieLensDataset(dataset_version="small")
print("Getting training data...")
train_dense_features, train_labels = dataset.get_data(split="train")
print("Getting testing data...")
test_dense_features, test_labels = dataset.get_data(split="test")
# Create DataLoader for training and testing
train_loader = DataLoader(torch.utils.data.TensorDataset(train_dense_features, train_labels), batch_size=64, shuffle=True)
test_loader = DataLoader(torch.utils.data.TensorDataset(test_dense_features, test_labels), batch_size=64, shuffle=False)
print("Accessing encoders...")
user_encoder, movie_encoder = dataset.get_encoders()
print("Setup complete.")
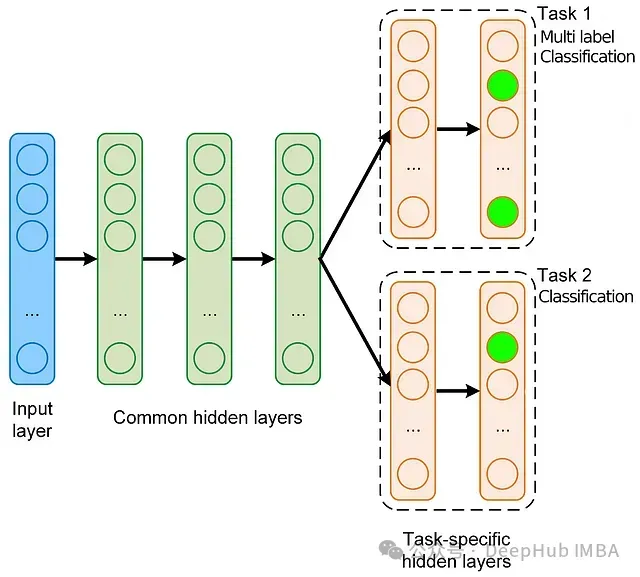
3.定義多任務(wù)多標簽?zāi)P?/h4>
我們將定義一個基本的 PyTorch 模型,處理兩個任務(wù):預(yù)測評分(回歸)和用戶是否喜歡這部電影(二元分類)。
模型使用稀疏嵌入來表示用戶和電影,并有共享層,這些共享層會輸入到兩個單獨的輸出層。
通過在任務(wù)之間共享一些層,并為每個特定任務(wù)的輸出設(shè)置單獨的層,該模型利用了共享表示,同時仍然針對每個任務(wù)定制其預(yù)測。
from torch import nn
class MultiTaskMovieLensModel(nn.Module):
def __init__(self, n_users, n_movies, embedding_size, hidden_size):
super(MultiTaskMovieLensModel, self).__init__()
self.user_embedding = nn.Embedding(n_users, embedding_size)
self.movie_embedding = nn.Embedding(n_movies, embedding_size)
self.shared_layer = nn.Linear(embedding_size * 2, hidden_size)
self.shared_activation = nn.ReLU()
self.task1_fc = nn.Linear(hidden_size, 1)
self.task2_fc = nn.Linear(hidden_size, 1)
self.task2_activation = nn.Sigmoid()
def forward(self, x):
user = x[:, 0]
movie = x[:, 1]
user_embed = self.user_embedding(user)
movie_embed = self.movie_embedding(movie)
combined = torch.cat((user_embed, movie_embed), dim=1)
shared_out = self.shared_activation(self.shared_layer(combined))
rating_out = self.task1_fc(shared_out)
liked_out = self.task2_fc(shared_out)
liked_out = self.task2_activation(liked_out)
return rating_out, liked_out輸入 (x):
- 輸入 x 預(yù)期是一個 2D 張量,其中每行包含一個用戶 ID 和一個電影 ID。
用戶和電影嵌入:
- user = x[:, 0]: 從第一列提取用戶 ID。
- movie = x[:, 1]: 從第二列提取電影 ID。
- user_embed 和 movie_embed 是對應(yīng)這些 ID 的嵌入。
連接:
- combined = torch.cat((user_embed, movie_embed), dim=1): 沿特征維度連接用戶和電影嵌入。
共享層:
- shared_out = self.shared_activation(self.shared_layer(combined)): 將組合的嵌入通過共享的全連接層和激活函數(shù)。
任務(wù)特定輸出:
- rating_out = self.task1_fc(shared_out): 從第一個任務(wù)特定層輸出預(yù)測評分。
- liked_out = self.task2_fc(shared_out): 輸出用戶是否喜歡電影的原始分數(shù)。
- liked_out = self.task2_activation(liked_out): 原始分數(shù)通過 sigmoid 函數(shù)轉(zhuǎn)換為概率。
返回 :
模型返回兩個輸出:
- rating_out:預(yù)測的評分(回歸輸出)。
- liked_out: 用戶喜歡電影的概率(分類輸出)。
4.訓(xùn)練循環(huán)
首先,用一些任意選擇的超參數(shù)(嵌入維度和隱藏層中的神經(jīng)元數(shù)量)實例化我們的模型。對于回歸任務(wù)將使用均方誤差損失,對于分類任務(wù),將使用二元交叉熵。
我們可以通過它們的初始值來歸一化兩個損失,以確保它們都大致處于相似的尺度(這里也可以使用不確定性加權(quán)來歸一化損失)
然后將使用數(shù)據(jù)加載器訓(xùn)練模型,并跟蹤兩個任務(wù)的損失。損失將被繪制成圖表,以可視化模型在評估集上隨時間的學(xué)習(xí)和泛化情況。
import torch.optim as optim
import matplotlib.pyplot as plt
# Check if GPU is available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
embedding_size = 16
hidden_size = 32
n_users = len(dataset.get_encoders()[0].classes_)
n_movies = len(dataset.get_encoders()[1].classes_)
model = MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size).to(device)
criterion_rating = nn.MSELoss()
criterion_liked = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_rating_losses, train_liked_losses = [], []
eval_rating_losses, eval_liked_losses = [], []
epochs = 10
# used for loss normalization
initial_loss_rating = None
initial_loss_liked = None
for epoch in range(epochs):
model.train()
running_loss_rating = 0.0
running_loss_liked = 0.0
for dense_features, labels in train_loader:
optimizer.zero_grad()
dense_features = dense_features.to(device)
labels = labels.to(device)
rating_pred, liked_pred = model(dense_features)
rating_target = labels[:, 0].unsqueeze(1)
liked_target = labels[:, 1].unsqueeze(1)
loss_rating = criterion_rating(rating_pred, rating_target)
loss_liked = criterion_liked(liked_pred, liked_target)
# Set initial losses
if initial_loss_rating is None:
initial_loss_rating = loss_rating.item()
if initial_loss_liked is None:
initial_loss_liked = loss_liked.item()
# Normalize losses
loss = (loss_rating / initial_loss_rating) + (loss_liked / initial_loss_liked)
loss.backward()
optimizer.step()
running_loss_rating += loss_rating.item()
running_loss_liked += loss_liked.item()
train_rating_losses.append(running_loss_rating / len(train_loader))
train_liked_losses.append(running_loss_liked / len(train_loader))
model.eval()
eval_loss_rating = 0.0
eval_loss_liked = 0.0
with torch.no_grad():
for dense_features, labels in test_loader:
dense_features = dense_features.to(device)
labels = labels.to(device)
rating_pred, liked_pred = model(dense_features)
rating_target = labels[:, 0].unsqueeze(1)
liked_target = labels[:, 1].unsqueeze(1)
loss_rating = criterion_rating(rating_pred, rating_target)
loss_liked = criterion_liked(liked_pred, liked_target)
eval_loss_rating += loss_rating.item()
eval_loss_liked += loss_liked.item()
eval_rating_losses.append(eval_loss_rating / len(test_loader))
eval_liked_losses.append(eval_loss_liked / len(test_loader))
print(f'Epoch {epoch+1}, Train Rating Loss: {train_rating_losses[-1]}, Train Liked Loss: {train_liked_losses[-1]}, Eval Rating Loss: {eval_rating_losses[-1]}, Eval Liked Loss: {eval_liked_losses[-1]}')
# Plotting losses
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
plt.plot(train_rating_losses, label='Train Rating Loss')
plt.plot(eval_rating_losses, label='Eval Rating Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Rating Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_liked_losses, label='Train Liked Loss')
plt.plot(eval_liked_losses, label='Eval Liked Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Liked Loss')
plt.legend()
plt.tight_layout()
plt.show()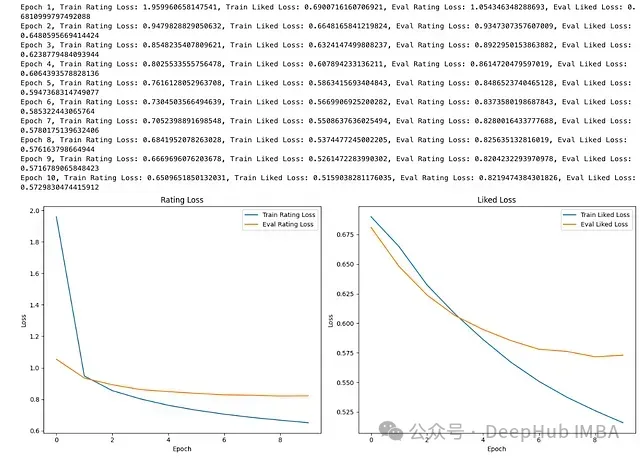
還可以通過利用 Tensorboard 監(jiān)控訓(xùn)練的過程
from torch.utils.tensorboard import SummaryWriter
# Check if GPU is available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Model and Training Setup
embedding_size = 16
hidden_size = 32
n_users = len(user_encoder.classes_)
n_movies = len(movie_encoder.classes_)
model = MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size).to(device)
criterion_rating = nn.MSELoss()
criterion_liked = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 10
# used for loss normalization
initial_loss_rating = None
initial_loss_liked = None
# TensorBoard setup
writer = SummaryWriter(log_dir='runs/multitask_movie_lens')
# Training Loop with TensorBoard Logging
for epoch in range(epochs):
model.train()
running_loss_rating = 0.0
running_loss_liked = 0.0
for batch_idx, (dense_features, labels) in enumerate(train_loader):
# Move data to GPU
dense_features = dense_features.to(device)
labels = labels.to(device)
optimizer.zero_grad()
rating_pred, liked_pred = model(dense_features)
rating_target = labels[:, 0].unsqueeze(1)
liked_target = labels[:, 1].unsqueeze(1)
loss_rating = criterion_rating(rating_pred, rating_target)
loss_liked = criterion_liked(liked_pred, liked_target)
# Set initial losses
if initial_loss_rating is None:
initial_loss_rating = loss_rating.item()
if initial_loss_liked is None:
initial_loss_liked = loss_liked.item()
# Normalize losses
loss = (loss_rating / initial_loss_rating) + (loss_liked / initial_loss_liked)
loss.backward()
optimizer.step()
running_loss_rating += loss_rating.item()
running_loss_liked += loss_liked.item()
# Log loss to TensorBoard
writer.add_scalar('Loss/Train_Rating', loss_rating.item(), epoch * len(train_loader) + batch_idx)
writer.add_scalar('Loss/Train_Liked', loss_liked.item(), epoch * len(train_loader) + batch_idx)
print(f'Epoch {epoch+1}/{epochs}, Train Rating Loss: {running_loss_rating / len(train_loader)}, Train Liked Loss: {running_loss_liked / len(train_loader)}')
# Evaluate on the test set
model.eval()
eval_loss_rating = 0.0
eval_loss_liked = 0.0
with torch.no_grad():
for dense_features, labels in test_loader:
# Move data to GPU
dense_features = dense_features.to(device)
labels = labels.to(device)
rating_pred, liked_pred = model(dense_features)
rating_target = labels[:, 0].unsqueeze(1)
liked_target = labels[:, 1].unsqueeze(1)
loss_rating = criterion_rating(rating_pred, rating_target)
loss_liked = criterion_liked(liked_pred, liked_target)
eval_loss_rating += loss_rating.item()
eval_loss_liked += loss_liked.item()
eval_loss_avg_rating = eval_loss_rating / len(test_loader)
eval_loss_avg_liked = eval_loss_liked / len(test_loader)
print(f'Epoch {epoch+1}/{epochs}, Eval Rating Loss: {eval_loss_avg_rating}, Eval Liked Loss: {eval_loss_avg_liked}')
# Log evaluation loss to TensorBoard
writer.add_scalar('Loss/Eval_Rating', eval_loss_avg_rating, epoch)
writer.add_scalar('Loss/Eval_Liked', eval_loss_avg_liked, epoch)
# Close the TensorBoard writer
writer.close()我們在同一目錄下運行 TensorBoard 來啟動服務(wù)器,并在網(wǎng)絡(luò)瀏覽器中檢查訓(xùn)練和評估曲線。在以下 bash 命令中,將 runs/mutlitask_movie_lens 替換為包含事件文件(日志)的目錄路徑。
(base) $ tensorboard --logdir=runs/multitask_movie_lens
TensorFlow installation not found - running with reduced feature set.運行結(jié)果如下:
NOTE: Using experimental fast data loading logic. To disable, pass
"--load_fast=false" and report issues on GitHub. More details:
<https://github.com/tensorflow/tensorboard/issues/4784>
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.12.0 at <http://localhost:6006/> (Press CTRL+C to quit)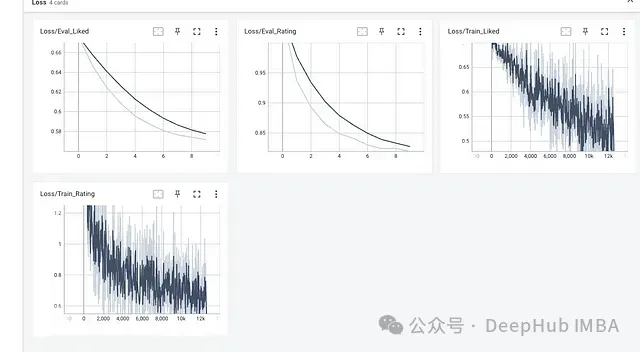
Tensorboard 損失曲線視圖如上所示
5.推理
在訓(xùn)練完成后要使用 torch.save 函數(shù)將模型保存到磁盤。這個函數(shù)允許你保存模型的狀態(tài)字典,其中包含模型的所有參數(shù)和緩沖區(qū)。保存的文件通常使用 .pth 或 .pt 擴展名。
import torch
torch.save(model.state_dict(), "model.pth")狀態(tài)字典包含所有模型參數(shù)(權(quán)重和偏置),當想要將模型加載回代碼中時,可以使用以下步驟:
# Initialize the model (make sure the architecture matches the saved model)
model = MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size)
# Load the saved state dictionary into the model
model.load_state_dict(torch.load("model.pth"))
# Set the model to evaluation mode (important for inference)
model.eval()為了在一些未見過的數(shù)據(jù)上評估模型,可以對單個用戶-電影對進行預(yù)測,并將它們與實際值進行比較。
def predict_and_compare(user_id, movie_id, model, user_encoder, movie_encoder, train_dataset, test_dataset):
user_idx = user_encoder.transform([user_id])[0]
movie_idx = movie_encoder.transform([movie_id])[0]
example_user = torch.tensor([[user_idx]], dtype=torch.long)
example_movie = torch.tensor([[movie_idx]], dtype=torch.long)
example_dense_features = torch.cat((example_user, example_movie), dim=1)
model.eval()
with torch.no_grad():
rating_pred, liked_pred = model(example_dense_features)
predicted_rating = rating_pred.item()
predicted_liked = liked_pred.item()
actual_row = train_dataset.data[(train_dataset.data['userId'] == user_id) & (train_dataset.data['movieId'] == movie_id)]
if actual_row.empty:
actual_row = test_dataset.data[(test_dataset.data['userId'] == user_id) & (test_dataset.data['movieId'] == movie_id)]
if not actual_row.empty:
actual_rating = actual_row['rating'].values[0]
actual_liked = actual_row['liked'].values[0]
return {
'User ID': user_id,
'Movie ID': movie_id,
'Predicted Rating': round(predicted_rating, 2),
'Actual Rating': actual_rating,
'Predicted Liked': 'Yes' if predicted_liked >= 0.5 else 'No',
'Actual Liked': 'Yes' if actual_liked == 1 else 'No'
}
else:
return None
example_pairs = test_dataset.data.sample(n=5)
results = []
for _, row in example_pairs.iterrows():
user_id = row['userId']
movie_id = row['movieId']
result = predict_and_compare(user_id, movie_id, model, user_encoder, movie_encoder, train_dataset, test_dataset)
if result:
results.append(result)
results_df = pd.DataFrame(results)
results_df.head()
6.使用 Ray Serve 部署模型
最后就是將模型部署為一個服務(wù),使其可以通過 API 訪問,這里使用使用 Ray Serve。
使用 Ray Serve是因為它可以從單機無縫擴展到大型集群,可以處理不斷增加的負載。Ray Serve 還集成了 Ray 的儀表板,為監(jiān)控部署的健康狀況、性能和資源使用提供了用戶友好的界面。
步驟 1:加載訓(xùn)練好的模型
# Load your trained model (assuming it's saved as 'model.pth')
n_users = 1000 # 示例值,替換為實際用戶數(shù)
n_movies = 1000 # 示例值,替換為實際電影數(shù)
embedding_size = 16
hidden_size = 32
model = MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size)
model.load_state_dict(torch.load("model.pth"))
model.eval()步驟 2:定義模型服務(wù)類
import ray
from ray import serve
@serve.deployment
class ModelServeDeployment:
def __init__(self, model):
self.model = model
self.model.eval()
async def __call__(self, request):
json_input = await request.json()
user_id = torch.tensor([json_input["user_id"]])
movie_id = torch.tensor([json_input["movie_id"]])
with torch.no_grad():
rating_pred, liked_pred = self.model(user_id, movie_id)
return {
"rating_prediction": rating_pred.item(),
"liked_prediction": liked_pred.item()
}步驟 3:初始化 Ray 服務(wù)器
# 初始化 Ray 和 Ray Serve
ray.init()
serve.start()
# 部署模型
model_deployment = ModelServeDeployment.bind(model)
serve.run(model_deployment)現(xiàn)在應(yīng)該能夠在 localhost:8265 看到 ray 服務(wù)器
步驟 4:查詢模型
最后就是測試 API 了。運行以下代碼行時,應(yīng)該可以看到一個響應(yīng),其中包含查詢用戶和電影的評分和喜歡預(yù)測
import requests
# 定義服務(wù)器地址(Ray Serve 默認為 http://127.0.0.1:8000)
url = "http://127.0.0.1:8000/ModelServeDeployment"
# 示例輸入
data = {
"user_id": 123, # 替換為實際用戶 ID
"movie_id": 456 # 替換為實際電影 ID
}
# 向模型服務(wù)器發(fā)送 POST 請求
response = requests.post(url, json=data)
# 打印模型的響應(yīng)
print(response.json())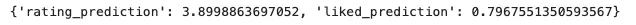
就是這樣,我們剛剛訓(xùn)練并部署了一個多任務(wù)多標簽?zāi)P停?/p>