克服403錯(cuò)誤:Python爬蟲(chóng)的反爬蟲(chóng)機(jī)制應(yīng)對(duì)指南
作者:架構(gòu)師老盧
HTTP狀態(tài)碼403表示服務(wù)器理解請(qǐng)求,但拒絕執(zhí)行它。在爬蟲(chóng)中,這通常是由于網(wǎng)站的反爬蟲(chóng)機(jī)制導(dǎo)致的。網(wǎng)站可能檢測(cè)到了你的爬蟲(chóng)行為,因此拒絕提供服務(wù)。

概述:在Python爬蟲(chóng)過(guò)程中,HTTP狀態(tài)碼403通常是因?yàn)榫W(wǎng)站的反爬蟲(chóng)機(jī)制生效。解決方法包括設(shè)置合適的User-Agent、使用代理IP、降低爬取頻率、攜帶必要的Cookies和模擬合法的頁(yè)面跳轉(zhuǎn)。對(duì)于動(dòng)態(tài)渲染頁(yè)面,可考慮使用Selenium等工具。在爬取前需遵循網(wǎng)站的robots.txt規(guī)定,尊重合法API。綜合這些方法,可以規(guī)避反爬蟲(chóng)機(jī)制,但需確保遵守法規(guī)和網(wǎng)站規(guī)定。
HTTP狀態(tài)碼403表示服務(wù)器理解請(qǐng)求,但拒絕執(zhí)行它。在爬蟲(chóng)中,這通常是由于網(wǎng)站的反爬蟲(chóng)機(jī)制導(dǎo)致的。網(wǎng)站可能檢測(cè)到了你的爬蟲(chóng)行為,因此拒絕提供服務(wù)。以下是可能導(dǎo)致403錯(cuò)誤的一些原因以及相應(yīng)的解決方法:
1.缺少合適的請(qǐng)求頭(User-Agent):
- 原因: 有些網(wǎng)站會(huì)檢查請(qǐng)求的User-Agent字段,如果該字段不符合瀏覽器的標(biāo)準(zhǔn),就會(huì)拒絕服務(wù)。
- 解決方法: 設(shè)置合適的User-Agent頭,模擬正常瀏覽器訪(fǎng)問(wèn)。
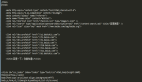
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)2.IP被封禁:
- 原因: 如果你的爬蟲(chóng)頻繁訪(fǎng)問(wèn)某個(gè)網(wǎng)站,可能會(huì)觸發(fā)網(wǎng)站的IP封禁機(jī)制。
- 解決方法: 使用代理IP輪換或者減緩爬取速度,以避免IP被封。
proxies = {'http': 'http://your_proxy', 'https': 'https://your_proxy'}
response = requests.get(url, headers=headers, proxies=proxies)3.請(qǐng)求頻率過(guò)高:
- 原因: 爬取速度過(guò)快可能會(huì)被網(wǎng)站認(rèn)為是惡意行為。
- 解決方法: 在請(qǐng)求之間增加適當(dāng)?shù)难舆t,以模擬人類(lèi)訪(fǎng)問(wèn)行為。
import time
time.sleep(1) # 1秒延遲4.缺少必要的Cookies:
- 原因: 有些網(wǎng)站需要在請(qǐng)求中包含特定的Cookie信息。
- 解決方法: 使用瀏覽器登錄網(wǎng)站,獲取登錄后的Cookie,并在爬蟲(chóng)中使用。
headers = {'User-Agent': 'your_user_agent', 'Cookie': 'your_cookie'}
response = requests.get(url, headers=headers)5.Referer檢查:
- 原因: 有些網(wǎng)站會(huì)檢查請(qǐng)求的Referer字段,確保請(qǐng)求是從合法的頁(yè)面跳轉(zhuǎn)而來(lái)。
- 解決方法: 設(shè)置合適的Referer頭,模擬正常的頁(yè)面跳轉(zhuǎn)。
headers = {'User-Agent': 'your_user_agent', 'Referer': 'https://example.com'}
response = requests.get(url, headers=headers)6.使用動(dòng)態(tài)渲染的頁(yè)面:
- 原因: 一些網(wǎng)站使用JavaScript動(dòng)態(tài)加載內(nèi)容,如果只是簡(jiǎn)單的基于文本的爬取可能無(wú)法獲取完整的頁(yè)面內(nèi)容。
- 解決方法: 使用Selenium等工具模擬瀏覽器行為。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
page_source = driver.page_source7.遵循Robots.txt規(guī)定:
- 原因: 爬蟲(chóng)爬取的行為可能違反了網(wǎng)站的robots.txt中的規(guī)定。
- 解決方法: 查看robots.txt文件,確保你的爬蟲(chóng)遵循了網(wǎng)站的規(guī)定。
8.使用合法的API:
- 原因: 有些網(wǎng)站提供了正式的API,通過(guò)API訪(fǎng)問(wèn)可能更合法。
- 解決方法: 查看網(wǎng)站是否有提供API,并合法使用API進(jìn)行數(shù)據(jù)獲取。
通過(guò)以上方法,你可以嘗試規(guī)避反爬蟲(chóng)機(jī)制,但請(qǐng)注意在進(jìn)行爬取時(shí)應(yīng)該尊重網(wǎng)站的使用規(guī)定,避免過(guò)度請(qǐng)求和濫用爬蟲(chóng)行為。
責(zé)任編輯:姜華
來(lái)源:
今日頭條