YOLOv10來啦!真正實(shí)時(shí)端到端目標(biāo)檢測
本文經(jīng)自動(dòng)駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
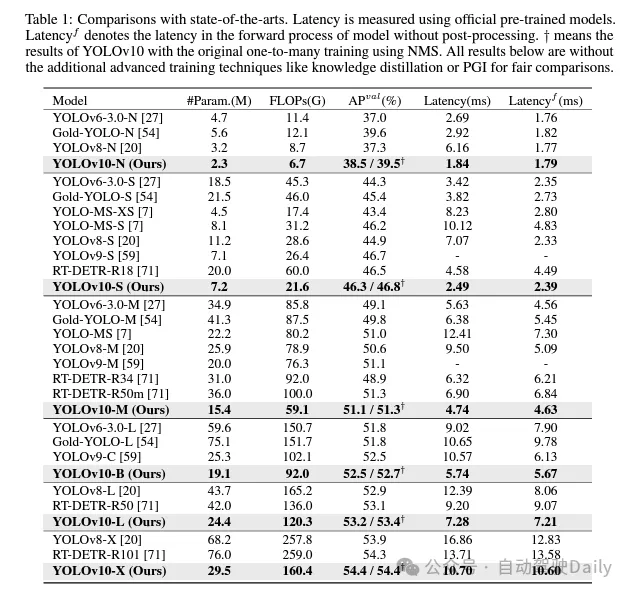
過去幾年里,YOLOs因在計(jì)算成本和檢測性能之間實(shí)現(xiàn)有效平衡而成為實(shí)時(shí)目標(biāo)檢測領(lǐng)域的主流范式。研究人員針對YOLOs的結(jié)構(gòu)設(shè)計(jì)、優(yōu)化目標(biāo)、數(shù)據(jù)增強(qiáng)策略等進(jìn)行了深入探索,并取得了顯著進(jìn)展。然而,對非極大值抑制(NMS)的后處理依賴阻礙了YOLOs的端到端部署,并對推理延遲產(chǎn)生負(fù)面影響。此外,YOLOs中各種組件的設(shè)計(jì)缺乏全面和徹底的審查,導(dǎo)致明顯的計(jì)算冗余并限制了模型的性能。這導(dǎo)致次優(yōu)的效率,以及性能提升的巨大潛力。在這項(xiàng)工作中,我們旨在從后處理和模型架構(gòu)兩個(gè)方面進(jìn)一步推進(jìn)YOLOs的性能-效率邊界。為此,我們首先提出了用于YOLOs無NMS訓(xùn)練的持續(xù)雙重分配,該方法同時(shí)帶來了競爭性的性能和較低的推理延遲。此外,我們?yōu)閅OLOs引入了全面的效率-準(zhǔn)確性驅(qū)動(dòng)模型設(shè)計(jì)策略。我們從效率和準(zhǔn)確性兩個(gè)角度全面優(yōu)化了YOLOs的各個(gè)組件,這大大降低了計(jì)算開銷并增強(qiáng)了模型能力。我們的努力成果是新一代YOLO系列,專為實(shí)時(shí)端到端目標(biāo)檢測而設(shè)計(jì),名為YOLOv10。廣泛的實(shí)驗(yàn)表明,YOLOv10在各種模型規(guī)模下均達(dá)到了最先進(jìn)的性能和效率。例如,在COCO數(shù)據(jù)集上,我們的YOLOv10-S在相似AP下比RT-DETR-R18快1.8倍,同時(shí)參數(shù)和浮點(diǎn)運(yùn)算量(FLOPs)減少了2.8倍。與YOLOv9-C相比,YOLOv10-B在相同性能下延遲減少了46%,參數(shù)減少了25%。代碼鏈接:https://github.com/THU-MIG/yolov10。
YOLOv10有哪些改進(jìn)?
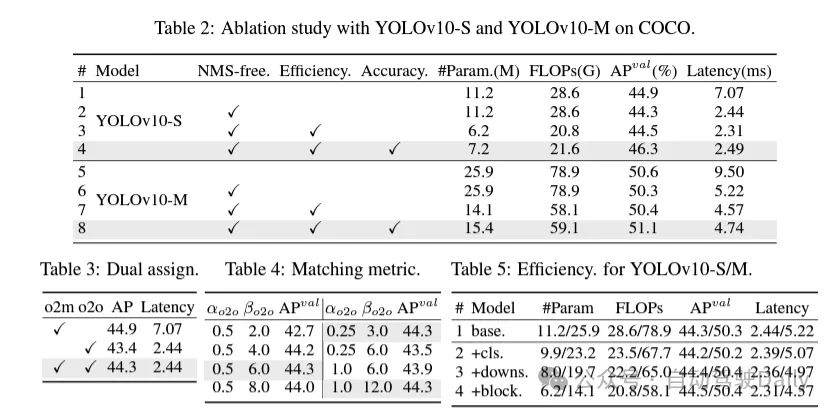
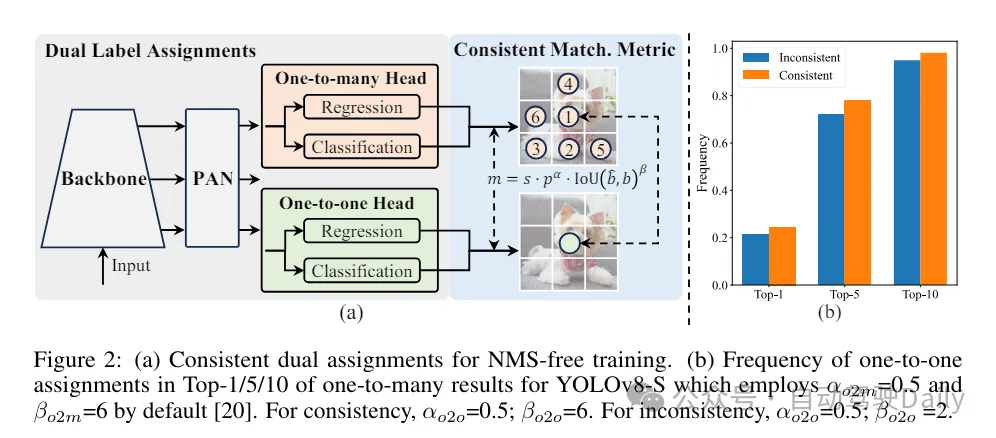
首先通過為無NMS的YOLOs提出一種持續(xù)雙重分配策略來解決后處理中的冗余預(yù)測問題,該策略包括雙重標(biāo)簽分配和一致匹配度量。這使得模型在訓(xùn)練過程中能夠獲得豐富而和諧的監(jiān)督,同時(shí)消除了推理過程中對NMS的需求,從而在保持高效率的同時(shí)獲得了競爭性的性能。
其次,為模型架構(gòu)提出了全面的效率-準(zhǔn)確度驅(qū)動(dòng)模型設(shè)計(jì)策略,對YOLOs中的各個(gè)組件進(jìn)行了全面檢查。在效率方面,提出了輕量級分類頭、空間-通道解耦下采樣和rank引導(dǎo)block設(shè)計(jì),以減少明顯的計(jì)算冗余并實(shí)現(xiàn)更高效的架構(gòu)。
在準(zhǔn)確度方面,探索了大核卷積并提出了有效的部分自注意力模塊,以增強(qiáng)模型能力,以低成本挖掘性能提升潛力。
基于這些方法,作者成功地實(shí)現(xiàn)了一系列不同模型規(guī)模的實(shí)時(shí)端到端檢測器,即YOLOv10-N / S / M / B / L / X。在標(biāo)準(zhǔn)目標(biāo)檢測基準(zhǔn)上進(jìn)行的廣泛實(shí)驗(yàn)表明,YOLOv10在各種模型規(guī)模下,在計(jì)算-準(zhǔn)確度權(quán)衡方面顯著優(yōu)于先前的最先進(jìn)模型。如圖1所示,在類似性能下,YOLOv10-S / X分別比RT-DETR R18 / R101快1.8倍/1.3倍。與YOLOv9-C相比,YOLOv10-B在相同性能下實(shí)現(xiàn)了46%的延遲降低。此外,YOLOv10展現(xiàn)出了極高的參數(shù)利用效率。YOLOv10-L / X在參數(shù)數(shù)量分別減少了1.8倍和2.3倍的情況下,比YOLOv8-L / X高出0.3 AP和0.5 AP。YOLOv10-M在參數(shù)數(shù)量分別減少了23%和31%的情況下,與YOLOv9-M / YOLO-MS實(shí)現(xiàn)了相似的AP。

在訓(xùn)練過程中,YOLOs通常利用TAL(任務(wù)分配學(xué)習(xí)) 為每個(gè)實(shí)例分配多個(gè)正樣本。采用一對多的分配方式產(chǎn)生了豐富的監(jiān)督信號,有助于優(yōu)化并實(shí)現(xiàn)卓越的性能。然而,這也使得YOLOs 必須依賴于NMS(非極大值抑制)后處理,這導(dǎo)致在部署時(shí)的推理效率不是最優(yōu)的。雖然之前的工作探索了一對一的匹配方式來抑制冗余預(yù)測,但它們通常會增加額外的推理開銷或?qū)е麓蝺?yōu)的性能。在這項(xiàng)工作中,我們?yōu)閅OLOs提出了一種無需NMS的訓(xùn)練策略,該策略采用雙重標(biāo)簽分配和一致匹配度量,實(shí)現(xiàn)了高效率和具有競爭力的性能。
效率驅(qū)動(dòng)的模型設(shè)計(jì)。YOLO中的組件包括主干(stem)、下采樣層、帶有基本構(gòu)建塊的階段和頭部。主干部分的計(jì)算成本很低,因此我們對其他三個(gè)部分進(jìn)行效率驅(qū)動(dòng)的模型設(shè)計(jì)。
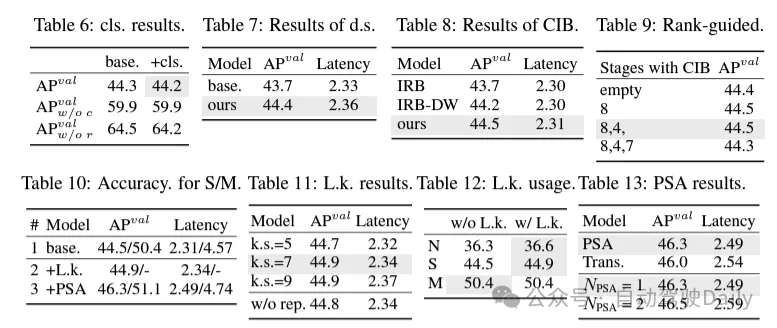
(1)輕量級的分類頭。在YOLO中,分類頭和回歸頭通常具有相同的架構(gòu)。然而,它們在計(jì)算開銷上存在顯著的差異。例如,在YOLOv8-S中,分類頭(5.95G/1.51M的FLOPs和參數(shù)計(jì)數(shù))的FLOPs和參數(shù)計(jì)數(shù)分別是回歸頭(2.34G/0.64M)的2.5倍和2.4倍。然而,通過分析分類錯(cuò)誤和回歸錯(cuò)誤的影響(見表6),我們發(fā)現(xiàn)回歸頭對YOLO的性能更為重要。因此,我們可以在不擔(dān)心對性能造成太大損害的情況下減少分類頭的開銷。因此,我們簡單地采用了輕量級的分類頭架構(gòu),它由兩個(gè)深度可分離卷積組成,卷積核大小為3×3,后跟一個(gè)1×1卷積。
(2)空間-通道解耦下采樣。YOLO通常使用步長為2的常規(guī)3×3標(biāo)準(zhǔn)卷積,同時(shí)實(shí)現(xiàn)空間下采樣(從H × W到H/2 × W/2)和通道變換(從C到2C)。這引入了不可忽視的計(jì)算成本 和參數(shù)計(jì)數(shù)。相反,我們提出將空間縮減和通道增加操作解耦,以實(shí)現(xiàn)更高效的下采樣。具體來說,首先利用逐點(diǎn)卷積來調(diào)制通道維度,然后利用深度卷積進(jìn)行空間下采樣。這將計(jì)算成本降低到并將參數(shù)計(jì)數(shù)降低到。同時(shí),它在下采樣過程中最大限度地保留了信息,從而在降低延遲的同時(shí)保持了競爭性能。
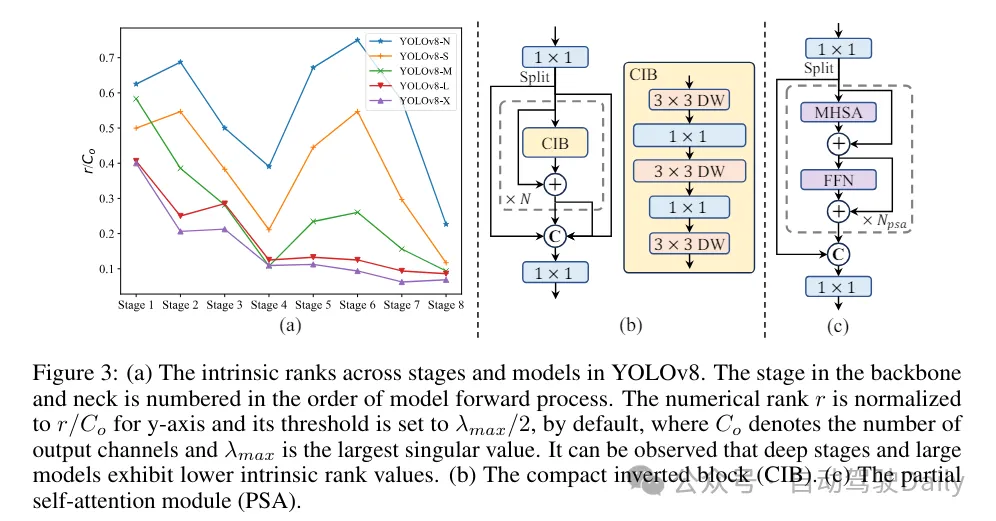
(3)基于rank引導(dǎo)的模塊設(shè)計(jì)。YOLOs通常對所有階段都使用相同的基本構(gòu)建塊,例如YOLOv8中的bottleneck塊。為了徹底檢查YOLOs的這種同構(gòu)設(shè)計(jì),我們利用內(nèi)在秩來分析每個(gè)階段的冗余性。具體來說,計(jì)算每個(gè)階段中最后一個(gè)基本塊中最后一個(gè)卷積的數(shù)值秩,它計(jì)算大于閾值的奇異值的數(shù)量。圖3(a)展示了YOLOv8的結(jié)果,表明深層階段和大型模型更容易表現(xiàn)出更多的冗余性。這一觀察表明,簡單地對所有階段應(yīng)用相同的block設(shè)計(jì)對于實(shí)現(xiàn)最佳容量-效率權(quán)衡來說并不是最優(yōu)的。為了解決這個(gè)問題,提出了一種基于秩的模塊設(shè)計(jì)方案,旨在通過緊湊的架構(gòu)設(shè)計(jì)來降低被證明是冗余的階段的復(fù)雜性。
首先介紹了一種緊湊的倒置塊(CIB)結(jié)構(gòu),它采用廉價(jià)的深度卷積進(jìn)行空間混合和成本效益高的逐點(diǎn)卷積進(jìn)行通道混合,如圖3(b)所示。它可以作為有效的基本構(gòu)建塊,例如嵌入在ELAN結(jié)構(gòu)中(圖3(b))。然后,倡導(dǎo)一種基于秩的模塊分配策略,以在保持競爭力量的同時(shí)實(shí)現(xiàn)最佳效率。具體來說,給定一個(gè)模型,根據(jù)其內(nèi)在秩的升序?qū)λ须A段進(jìn)行排序。進(jìn)一步檢查用CIB替換領(lǐng)先階段的基本塊后的性能變化。如果與給定模型相比沒有性能下降,我們將繼續(xù)替換下一個(gè)階段,否則停止該過程。因此,我們可以在不同階段和模型規(guī)模上實(shí)現(xiàn)自適應(yīng)緊湊塊設(shè)計(jì),從而在不影響性能的情況下實(shí)現(xiàn)更高的效率。
基于精度導(dǎo)向的模型設(shè)計(jì)。論文進(jìn)一步探索了大核卷積和自注意力機(jī)制,以實(shí)現(xiàn)基于精度的設(shè)計(jì),旨在以最小的成本提升性能。
(1)大核卷積。采用大核深度卷積是擴(kuò)大感受野并增強(qiáng)模型能力的一種有效方法。然而,在所有階段簡單地利用它們可能會在用于檢測小目標(biāo)的淺層特征中引入污染,同時(shí)也在高分辨率階段引入顯著的I/O開銷和延遲。因此,作者提出在深層階段的跨階段信息塊(CIB)中利用大核深度卷積。這里將CIB中的第二個(gè)3×3深度卷積的核大小增加到7×7。此外,采用結(jié)構(gòu)重參數(shù)化技術(shù),引入另一個(gè)3×3深度卷積分支,以緩解優(yōu)化問題,而不增加推理開銷。此外,隨著模型大小的增加,其感受野自然擴(kuò)大,使用大核卷積的好處逐漸減弱。因此,僅在小模型規(guī)模上采用大核卷積。
(2)部分自注意力(PSA)。自注意力機(jī)制因其出色的全局建模能力而被廣泛應(yīng)用于各種視覺任務(wù)中。然而,它表現(xiàn)出高計(jì)算復(fù)雜度和內(nèi)存占用。為了解決這個(gè)問題,鑒于普遍存在的注意力頭冗余,作則提出了一種高效的部分自注意力(PSA)模塊設(shè)計(jì),如圖3.(c)所示。具體來說,在1×1卷積之后將特征均勻地按通道分成兩部分。只將一部分特征輸入到由多頭自注意力模塊(MHSA)和前饋網(wǎng)絡(luò)(FFN)組成的NPSA塊中。然后,將兩部分特征通過1×1卷積進(jìn)行拼接和融合。此外,將MHSA中查詢和鍵的維度設(shè)置為值的一半,并將LayerNorm替換為BatchNorm以實(shí)現(xiàn)快速推理。PSA僅放置在具有最低分辨率的第4階段之后,以避免自注意力的二次計(jì)算復(fù)雜度帶來的過多開銷。通過這種方式,可以在計(jì)算成本較低的情況下將全局表示學(xué)習(xí)能力融入YOLOs中,從而很好地增強(qiáng)了模型的能力并提高了性能。
實(shí)驗(yàn)對比
這里就不做過多介紹啦,直接上結(jié)果!!!latency減少,性能繼續(xù)增加。