













一些 Llama3 微調(diào)工具以及如何在 Ollama 中運(yùn)行
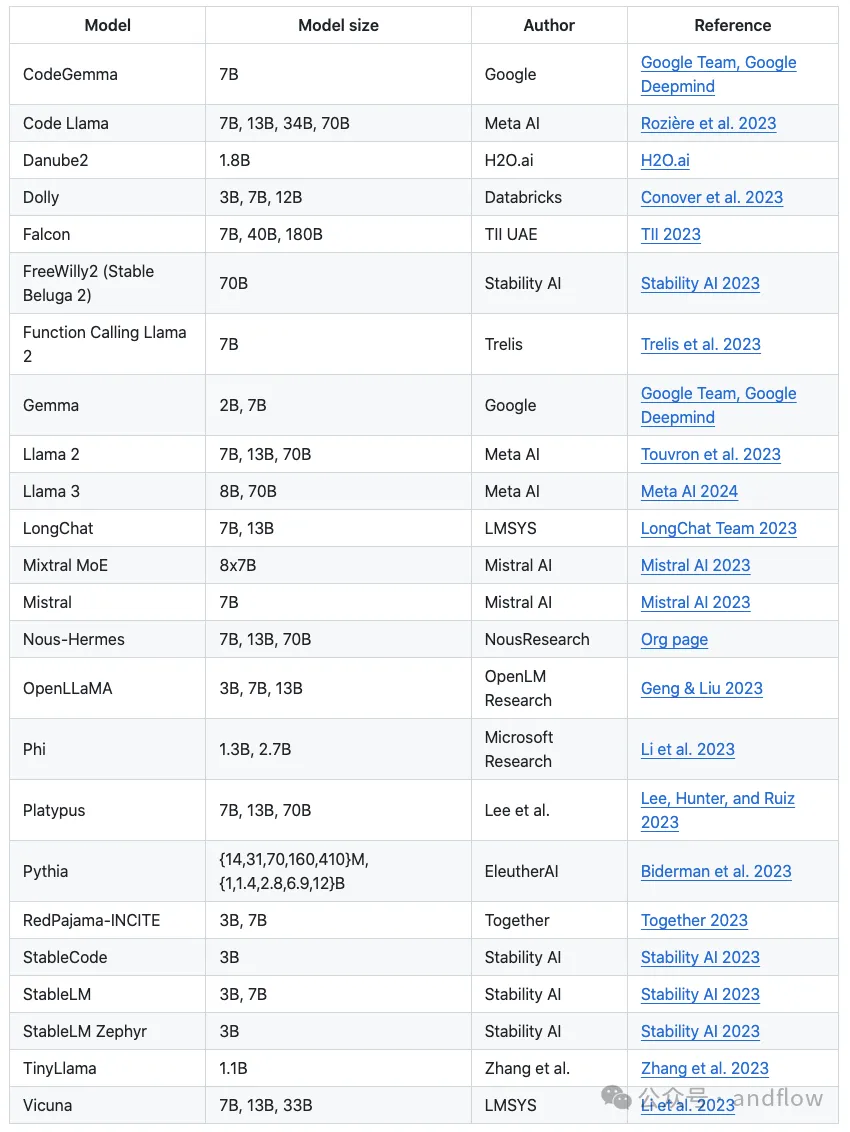
Llama3是Meta提供的一個(gè)開源大模型,包含8B和 70B兩種參數(shù)規(guī)模,涵蓋預(yù)訓(xùn)練和指令調(diào)優(yōu)的變體。這個(gè)開源模型推出已經(jīng)有一段時(shí)間,并且在許多標(biāo)準(zhǔn)測(cè)試中展示了其卓越的性能。特別是Llama3 8B,其具備小尺寸和高質(zhì)量的輸出使其成為邊緣設(shè)備或者移動(dòng)設(shè)備上實(shí)現(xiàn)LLM的完美選擇。但是Llama3也還有許多缺陷,因此,在場(chǎng)景應(yīng)用中,有時(shí)候還需要對(duì)其進(jìn)行微調(diào),以提升中文能力、場(chǎng)景應(yīng)用的專業(yè)度等。

目前有許多團(tuán)隊(duì)在做微調(diào)工具,他們的貢獻(xiàn)提高了我們的效率、減少失誤。比較優(yōu)秀的例如:
- MLX-LM
- PyReft
- litgpt
- LLaMA-Factory
本文主要介紹如何使用這幾個(gè)工具進(jìn)行微調(diào),以及如何在Ollama中安裝運(yùn)行微調(diào)后的模型。
一、MLX-LM
MLX團(tuán)隊(duì)一直在不懈地努力改進(jìn)MLX-LM庫(kù)在模型微調(diào)工具方面的能力。使用MLX-LM微調(diào)llama3十分簡(jiǎn)單。
可以參考相關(guān)例子:https://github.com/ml-explore/mlx-examples/tree/main/llms/llama
大致步驟如下:
1.準(zhǔn)備訓(xùn)練數(shù)據(jù)
glaiveai/glaive-function-calling-v2是一個(gè)專門用于訓(xùn)練大語(yǔ)言模型處理函數(shù)調(diào)用方面的數(shù)據(jù)集。我們可以下載這個(gè)數(shù)據(jù)集,并將數(shù)據(jù)轉(zhuǎn)換為適合Llama3對(duì)話的格式,并保存到"/data"目錄下。
數(shù)據(jù)下載地址:https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2
數(shù)據(jù)格式轉(zhuǎn)換的腳本如下:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments,BitsAndBytesConfig
from datasets import load_dataset
import json
model_name ="meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
dataset = load_dataset("glaiveai/glaive-function-calling-v2",split="train")
def cleanup(input_string):
arguments_index = input_string.find('"arguments"')
if arguments_index == -1:
return input_string
start_quote = input_string.find("'", arguments_index)
if start_quote == -1:
return input_string
end_quote = input_string.rfind("'")
if end_quote == -1 or end_quote <= start_quote:
return input_string
arguments_value = input_string[start_quote+1:end_quote]
output_string = input_string[:start_quote] + arguments_value + input_string[end_quote+1:]
return output_string
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['system'])):
messages = [
{
"role": "system",
"content": example['system'][i][len("SYSTEM:"):].strip(),
},
]
conversations = example['chat'][i].split("<|endoftext|>")
for message in conversations:
continue_outer = False
message = message.strip()
if message:
if "USER:" in message:
user_content = message.split("ASSISTANT:")[0].strip()
messages.append({"role": "user", "content": user_content[5:].strip()})
if "ASSISTANT:" in message:
assistant_content = message.split("ASSISTANT:")[1].strip()
if "<functioncall>" in assistant_content:
text = assistant_content.replace("<functioncall>","").strip()
json_str = cleanup(text)
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"0 - Failed to decode JSON: {json_str} - {assistant_content}")
continue_outer = True
break
new_func_text = "<functioncall> "+ json_str
messages.append({"role": "assistant", "content": new_func_text})
else:
messages.append({"role": "assistant", "content": assistant_content})
elif message.startswith("FUNCTION RESPONSE:"):
function_response = message[18:].strip()
if "ASSISTANT:" in function_response:
function_content, assistant_content = function_response.split("ASSISTANT:")
try:
data = json.loads(function_content.strip())
except json.JSONDecodeError as e:
print(f"1 - Failed to decode JSON: {function_content}")
continue_outer = True
break
messages.append({"role": "user", "content": function_content.strip()})
messages.append({"role": "assistant", "content": assistant_content.strip()})
else:
try:
data = json.loads(function_response.strip())
except json.JSONDecodeError as e:
print(f"2 - Failed to decode JSON: {function_response}")
continue_outer = True
break
messages.append({"role": "user", "content": function_response.strip()})
elif message.startswith("ASSISTANT:"):
assistant_content = message.split("ASSISTANT:")[1].strip()
if "<functioncall>" in assistant_content:
text = assistant_content.replace("<functioncall>","").strip()
json_str = cleanup(text)
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"3 - Failed to decode JSON: {json_str} - {assistant_content}")
continue_outer = True
break
new_func_text = "<functioncall> "+ json_str
messages.append({"role": "assistant", "content": new_func_text})
if continue_outer:
continue
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
output_texts.append(text)
del example['system']
del example['chat']
return {"text": output_texts}
dataset = dataset.map(formatting_prompts_func, batched=True)2.安裝mlx-lm包
pip install mlx-lm這個(gè)庫(kù)為微調(diào)LLM提供了一個(gè)友好的用戶交互方式,省去了許多麻煩,并實(shí)現(xiàn)更好的效果。
3.創(chuàng)建LoRA配置
通過(guò)配置LoRA來(lái)微調(diào)Llama3 8B模型。更改一些關(guān)鍵參數(shù)以優(yōu)化性能:
- 使用fp16代替qlora,以避免由于量化和解量化而導(dǎo)致的潛在性能下降。
- 將lora_layers設(shè)置為32,并使用全線性層,以獲得與全微調(diào)相媲美的結(jié)果。
以下是lora_config.yaml文件的示例:
# The path to the local model directory or Hugging Face repo.
model: "meta-llama/Meta-Llama-3-8B-Instruct"
# Whether or not to train (boolean)
train: true
# Directory with {train, valid, test}.jsonl files
data: "data"
# The PRNG seed
seed: 0
# Number of layers to fine-tune
lora_layers: 32
# Minibatch size.
batch_size: 1
# Iterations to train for.
iters: 6000
# Number of validation batches, -1 uses the entire validation set.
val_batches: 25
# Adam learning rate.
learning_rate: 1e-6
# Number of training steps between loss reporting.
steps_per_report: 10
# Number of training steps between validations.
steps_per_eval: 200
# Load path to resume training with the given adapter weights.
resume_adapter_file: null
# Save/load path for the trained adapter weights.
adapter_path: "adapters"
# Save the model every N iterations.
save_every: 1000
# Evaluate on the test set after training
test: false
# Number of test set batches, -1 uses the entire test set.
test_batches: 100
# Maximum sequence length.
max_seq_length: 8192
# Use gradient checkpointing to reduce memory use.
grad_checkpoint: true
# LoRA parameters can only be specified in a config file
lora_parameters:
# The layer keys to apply LoRA to.
# These will be applied for the last lora_layers
keys: ['mlp.gate_proj', 'mlp.down_proj', 'self_attn.q_proj', 'mlp.up_proj', 'self_attn.o_proj','self_attn.v_proj', 'self_attn.k_proj']
rank: 128
alpha: 256
scale: 10.0
dropout: 0.05
# Schedule can only be specified in a config file, uncomment to use.
# lr_schedule:
# name: cosine_decay
# warmup: 100 # 0 for no warmup
# warmup_init: 1e-7 # 0 if not specified
# arguments: [1e-6, 1000, 1e-7] # passed to scheduler4.執(zhí)行微調(diào)
在數(shù)據(jù)準(zhǔn)備和LoRA配置就緒后,就可以開始微調(diào)Llama3 8B了,只需要運(yùn)行以下命令。
mlx_lm.lora --config lora_config.yaml5.模型融合發(fā)布
LoRa模型是無(wú)法單獨(dú)完成推理的,需要和原生Llama結(jié)合才能運(yùn)行。因?yàn)樗黤reeze了原來(lái)的模型,單獨(dú)加了一些層,后續(xù)的訓(xùn)練都在這些層上做,所以需要進(jìn)行模型融合。
可以使用mlx_lm.fuse將訓(xùn)練過(guò)的適配器與原始的Llama3 8B模型以HF格式融合:
mlx_lm.fuse --model meta-llama/Meta-Llama-3-8B-Instruct二、PyReft
項(xiàng)目源碼:https://github.com/stanfordnlp/pyreft
ReFT方法的出發(fā)點(diǎn)是基于干預(yù)模型可解釋性的概念,該概念強(qiáng)調(diào)改變表示而不是權(quán)重。這個(gè)概念基于線性表示假設(shè),該假設(shè)指出概念被編碼在神經(jīng)網(wǎng)絡(luò)的線性子空間中。
PyReFT是一個(gè)基于ReFT方法的庫(kù),支持通過(guò)可訓(xùn)練的干預(yù)來(lái)調(diào)整內(nèi)部語(yǔ)言模型的表示。PyReFT具有更少的微調(diào)參數(shù)和更強(qiáng)的魯棒性,可以提高微調(diào)效率、降低微調(diào)成本,同時(shí)也為研究自適應(yīng)參數(shù)的可解釋性打開了大門。
PyReft支持:
- 微調(diào)發(fā)布在HuggingFace上任何預(yù)訓(xùn)練大模型
- 可配置ReFT超參數(shù)
- 輕松將微調(diào)后的結(jié)果分享到HuggingFace
1.安裝依賴庫(kù)
使用Pip安裝最新版本的transformers以支持llama3。此外,還需要安裝bitsandbytes庫(kù)。
!pip install -q git+https://github.com/huggingface/transformers
!pip install -q bitsandbytes2.安裝或?qū)雙yreft
安裝Pyreft庫(kù)。如果已經(jīng)安裝則將導(dǎo)入pyreft。
try:
import pyreft
except ModuleNotFoundError:
!pip install git+https://github.com/stanfordnlp/pyreft.git3.加載模型
在加載模型之前需要確保登陸到huggingface,以便于訪問(wèn)Llama3模型,可以使用下面的代碼片段:
from huggingface_hub import notebook_login
notebook_login()接下來(lái)就是設(shè)置用于訓(xùn)練的提示詞模板。由于我們將使用基礎(chǔ)模型,因此需要添加特殊的標(biāo)記,以便模型能夠?qū)W會(huì)停止并且不繼續(xù)生成文本。下面的代碼片段用于執(zhí)行加載模型和標(biāo)記器。
import torch, transformers, pyreft
device = "cuda"
prompt_no_input_template = """<|begin_of_text|><|start_header_id|>user<|end_header_id|>%s<|eot_id|><|start_header_id|>assistant<|end_header_id|>"""
model_name_or_path = "meta-llama/Meta-Llama-3-8B"
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name_or_path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
# # get tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_name_or_path, model_max_length=2048,
padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token接著,設(shè)置pyreft配置,然后使用pyreft.get_reft_model()方法準(zhǔn)備好模型。
# get reft model
reft_config = pyreft.ReftConfig(representations={
"layer": 8, "component": "block_output",
"low_rank_dimension": 4,
"intervention": pyreft.LoreftIntervention(embed_dim=model.config.hidden_size,
low_rank_dimension=4)})
reft_model = pyreft.get_reft_model(model, reft_config)
reft_model.set_device("cuda")
reft_model.print_trainable_parameters()4.準(zhǔn)備數(shù)據(jù)集
下面以O(shè)penHermes—2.5數(shù)據(jù)集為例。由于Reft Trainer的數(shù)據(jù)需要采用特定格式,因此我們使用:
pyreft.make_last_position_supervised_data_module()來(lái)準(zhǔn)備數(shù)據(jù)。
dataset_name = "teknium/OpenHermes-2.5"
from datasets import load_dataset
dataset = load_dataset(dataset_name, split="train")
dataset = dataset.select(range(10_000))
data_module = pyreft.make_last_position_supervised_data_module(
tokenizer, model, [prompt_no_input_template % row["conversations"][0]["value"] for row in dataset],
[row["conversations"][1]["value"] for row in dataset])5.執(zhí)行訓(xùn)練
為pyreft.ReftTrainerForCausalLM()設(shè)置訓(xùn)練參數(shù)。可以根據(jù)自己的使用情況和計(jì)算資源進(jìn)行更改。下面的代碼參數(shù)設(shè)置只訓(xùn)練1個(gè)epoch。
# train
training_args = transformers.TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 8,
warmup_steps = 100,
num_train_epochs = 1,
learning_rate = 5e-4,
bf16 = True,
logging_steps = 1,
optim = "paged_adamw_32bit",
weight_decay = 0.0,
lr_scheduler_type = "cosine",
output_dir = "outputs",
report_to=[]
)
trainer = pyreft.ReftTrainerForCausalLM(model=reft_model, tokenizer=tokenizer, args=training_args, **data_module)
_ = trainer.train()訓(xùn)練完成后,將干預(yù)塊保存到reft_to_share目錄中。
reft_model.save(
save_directory="./reft_to_share",
)6.發(fā)布與推理
模型微調(diào)訓(xùn)練完成后要進(jìn)行推理。需要加載基本模型,并通過(guò)合并干預(yù)塊來(lái)準(zhǔn)備reft模型。然后將reft模型轉(zhuǎn)移到cuda。
import torch, transformers, pyreft
device = "cuda"
model_name_or_path = "meta-llama/Meta-Llama-3-8B"
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name_or_path, torch_dtype=torch.bfloat16, device_map=device)
reft_model = pyreft.ReftModel.load(
"Syed-Hasan-8503/Llama-3-openhermes-reft", model, from_huggingface_hub=True
)
reft_model.set_device("cuda")接著進(jìn)行推理測(cè)試:
instruction = "A rectangular garden has a length of 25 feet and a width of 15 feet. If you want to build a fence around the entire garden, how many feet of fencing will you need?"
# tokenize and prepare the input
prompt = prompt_no_input_template % instruction
prompt = tokenizer(prompt, return_tensors="pt").to(device)
base_unit_location = prompt["input_ids"].shape[-1] - 1 # last position
_, reft_response = reft_model.generate(
prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])},
intervene_on_prompt=True, max_new_tokens=512, do_sample=True,
eos_token_id=tokenizer.eos_token_id, early_stopping=True
)
print(tokenizer.decode(reft_response[0], skip_special_tokens=True))三、litgpt
源代碼:https://github.com/Lightning-AI/litgpt

LitGPT是一個(gè)可以用于微調(diào)預(yù)訓(xùn)練模型的命令行工具,支持20多個(gè)LLM的評(píng)估、部署。它為世界上最強(qiáng)大的開源大型語(yǔ)言模型(LLM)提供了高度優(yōu)化的訓(xùn)練配方。
1.安裝
pip install 'litgpt[all]'2.評(píng)估測(cè)試
選擇一個(gè)模型并執(zhí)行:下載、對(duì)話、微調(diào)、預(yù)訓(xùn)練以及部署等。
# ligpt [action] [model]
litgpt download meta-llama/Meta-Llama-3-8B-Instruct
litgpt chat meta-llama/Meta-Llama-3-8B-Instruct
litgpt finetune meta-llama/Meta-Llama-3-8B-Instruct
litgpt pretrain meta-llama/Meta-Llama-3-8B-Instruct
litgpt serve meta-llama/Meta-Llama-3-8B-Instruct例如:使用微軟的phi-2進(jìn)行對(duì)話評(píng)估。
# 1) Download a pretrained model
litgpt download --repo_id microsoft/phi-2
# 2) Chat with the model
litgpt chat \
--checkpoint_dir checkpoints/microsoft/phi-2
>> Prompt: What do Llamas eat?3.微調(diào)模型
下面是在phi-2基礎(chǔ)上進(jìn)行微調(diào)的命令。
# 1) Download a pretrained model
litgpt download --repo_id microsoft/phi-2
# 2) Finetune the model
curl -L https://huggingface.co/datasets/ksaw008/finance_alpaca/resolve/main/finance_alpaca.json -o my_custom_dataset.json
litgpt finetune \
--checkpoint_dir checkpoints/microsoft/phi-2 \
--data JSON \
--data.json_path my_custom_dataset.json \
--data.val_split_fraction 0.1 \
--out_dir out/custom-model
# 3) Chat with the model
litgpt chat \
--checkpoint_dir out/custom-model/final除此外,還可以基于自己的數(shù)據(jù)進(jìn)行訓(xùn)練。詳細(xì)參考GitHub。
4.部署
通過(guò)下面的部署命令,啟動(dòng)模型服務(wù)。
# locate the checkpoint to your finetuned or pretrained model and call the `serve` command:
litgpt serve --checkpoint_dir path/to/your/checkpoint/microsoft/phi-2
# Alternative: if you haven't finetuned, download any checkpoint to deploy it:
litgpt download --repo_id microsoft/phi-2
litgpt serve --checkpoint_dir checkpoints/microsoft/phi-2通過(guò)Http API訪問(wèn)服務(wù)。
# Use the server (in a separate session)
import requests, json
response = requests.post(
"http://127.0.0.1:8000/predict",
json={"prompt": "Fix typos in the following sentence: Exampel input"}
)
print(response.json()["output"])四、LLaMA-Factory
源代碼:https://github.com/hiyouga/LLaMA-Factory/

LLaMA-Factory 是一個(gè)開源項(xiàng)目,它提供了一套全面的工具和腳本,用于微調(diào)、部署和基準(zhǔn)測(cè)試LLaMA模型。
LLaMA-Factory 提供以下功能,使得我們可以輕松地使用LLaMA模型:
- 數(shù)據(jù)預(yù)處理和標(biāo)記化的腳本
- 用于微調(diào) LLaMA 模型的訓(xùn)練流程
- 使用經(jīng)過(guò)訓(xùn)練的模型生成文本的推理腳本
- 評(píng)估模型性能的基準(zhǔn)測(cè)試工具
- 用于交互式測(cè)試的 Gradio Web UI
使用LLaMA-Factory 進(jìn)行微調(diào)的步驟如下:
1.數(shù)據(jù)準(zhǔn)備
LLaMA-Factory要求訓(xùn)練數(shù)據(jù)的格式如下:
[
{
"instruction": "What is the capital of France?",
"input": "",
"output": "Paris is the capital of France."
},
...
]每個(gè) JSON 對(duì)象代表一個(gè)訓(xùn)練示例,其中包含以下字段:
- instruction:任務(wù)指令或提示
- input:任務(wù)的附加上下文(可以為空)
- output:目標(biāo)完成或響應(yīng)
2.下載安裝依賴包
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt3.執(zhí)行微調(diào)
支持使用Python進(jìn)行微調(diào)也支持圖形化界面的方式。
下面是執(zhí)行python腳本進(jìn)行微調(diào):
python finetune.py \
--model_name llama-7b \
--data_path data/alpaca_data_tokenized.json \
--output_dir output/llama-7b-alpaca \
--num_train_epochs 3 \
--batch_size 128 \
--learning_rate 2e-5 \
--fp16該腳本將加載預(yù)訓(xùn)練的LLaMA模型,準(zhǔn)備訓(xùn)練數(shù)據(jù)集,并使用指定的超參數(shù)運(yùn)行微調(diào)腳步。微調(diào)后的模型檢查點(diǎn)將保存在 中output_dir。
主要參數(shù)設(shè)置如下:
- model_name:要微調(diào)的基礎(chǔ) LLaMA 模型,例如llama-7b
- data_path:標(biāo)記數(shù)據(jù)集的路徑
- output_dir:保存微調(diào)模型的目錄
- num_train_epochs:訓(xùn)練周期數(shù)
- batch_size:訓(xùn)練的批次大小
- learning_rate:優(yōu)化器的學(xué)習(xí)率
- fp16:使用 FP16 混合精度來(lái)減少內(nèi)存使用量
接著使用微調(diào)后的結(jié)果進(jìn)行推理測(cè)試:
python generate.py \
--model_path output/llama-7b-alpaca \
--prompt "What is the capital of France?"當(dāng)然,微調(diào)過(guò)程也可以在可視化界面上進(jìn)行。首先需要啟動(dòng)GUI界面。
python web_ui.py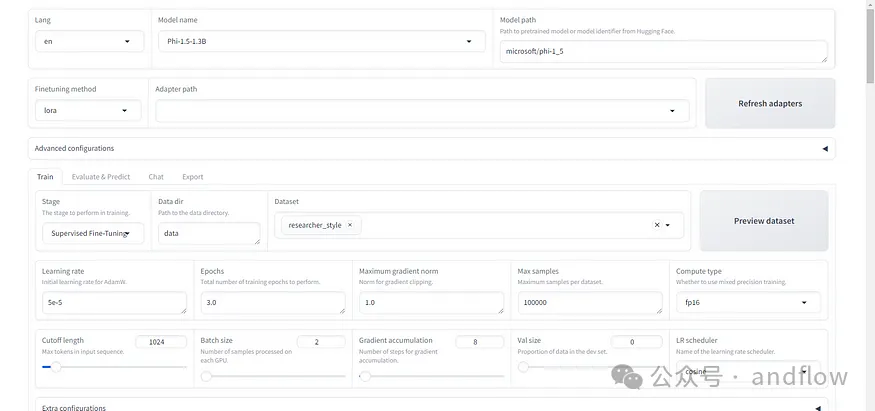
4.基準(zhǔn)測(cè)試
LLaMA-Factory 包含了基于各種評(píng)估數(shù)據(jù)集進(jìn)行基準(zhǔn)測(cè)試的腳本:
benchmark.py例如:
python benchmark.py \
--model_path output/llama-7b-alpaca \
--benchmark_datasets alpaca,hellaswag這個(gè)Python命令將加載經(jīng)過(guò)微調(diào)的模型并評(píng)估其在指定方面的表現(xiàn)。
benchmark_datasets參數(shù)指明使用哪些數(shù)據(jù)集進(jìn)行評(píng)估。評(píng)估報(bào)告包括:準(zhǔn)確度、困惑度和 F1分?jǐn)?shù)等指標(biāo)。
還可以使用DatasetBuilder實(shí)現(xiàn)一個(gè)類并將其注冊(cè)到基準(zhǔn)腳本來(lái)添加您自己的評(píng)估數(shù)據(jù)集。
如何在Ollama中安裝微調(diào)后的Llama3模型?
Ollama 是一個(gè)開源的大模型管理工具,它提供了豐富的功能,包括模型的訓(xùn)練、部署、監(jiān)控等。通過(guò)Ollama,可以輕松地管理本地的大模型,提高模型的訓(xùn)練速度和部署效率。Ollama支持多種機(jī)器學(xué)習(xí)框架,如TensorFlow、PyTorch等,因此,我們可以根據(jù)需要選擇合適的框架進(jìn)行模型訓(xùn)練。
在使用LLaMA-Factory進(jìn)行微調(diào)之后,會(huì)生成LoRA文件,如何在Ollama中運(yùn)行l(wèi)lama3和我們訓(xùn)練出來(lái)的LoRA呢?
步驟如下:
1.運(yùn)行Ollama
直接安裝或者通過(guò)Docker安裝運(yùn)行Ollama
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama2.GGML格式轉(zhuǎn)換
按照 Ollama modelfile ADAPTER 的說(shuō)明,Ollama 支持 ggml 格式的 LoRA,所以我們需要把微調(diào)生成的 LoRA 轉(zhuǎn)換成ggml格式。為此,我們需要使用到 Llama.cpp 的格式轉(zhuǎn)換腳本:“conver-lora-to-ggml.py”。
例如:
./conver-lora-to-ggml.py /output/llama3_cn_01 llama執(zhí)行完命令后,將在 /output/llama3_cn_01 下生成 ggml-adapter-model.bin 文件。這個(gè)文件就是 Ollama 所需要的ggml格式LoRA文件。
3.在Ollama中創(chuàng)建自定義Llama3模型
使用 ollama 的 modelfile 來(lái)創(chuàng)建自定義llama3模型。需要?jiǎng)?chuàng)建一個(gè)modefile文件。
我們創(chuàng)建一個(gè)llama3.modelfile,其內(nèi)容如下:
# set the base model
FROM llama3:8b
# set custom parameter values
PARAMETER temperature 1
PARAMETER num_keep 24
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
PARAMETER stop <|reserved_special_token
# set the model template
TEMPLATE """
{{ if .System }}<|
start_header_id
|>system<|
end_header_id
|>
{{ .System }}<|
eot_id
|>{{ end }}{{ if .Prompt }}<|
start_header_id
|>user<|
end_header_id
|>
{{ .Prompt }}<|
eot_id
|>{{ end }}<|
start_header_id
|>assistant<|
end_header_id
|>
{{ .Response }}<|
eot_id
|>
"""
# set the system message
SYSTEM You are llama3 from Meta, customized and hosted @ HY's Blog (https://blog.yanghong.dev).
# set Chinese lora support
ADAPTER /root/.ollama/models/lora/ggml-adapter-model.bin接著使用Ollama命令以及modelfile來(lái)創(chuàng)建自定義模型:
ollama create llama3:c01 -f llama3.modelfile查看模型列表:
ollama list運(yùn)行模型:
ollama run llama3:c01






















