













重磅!騰訊宣布混元文生圖大模型開源: Sora 同架構,中英文原生DiT,可免費商用
原創5月14日,騰訊宣布旗下的混元文生圖大模型全面升級并對外開源,目前已在 Hugging Face 平臺及 Github 上發布,包含模型權重、推理代碼、模型算法等完整模型,可供企業與個人開發者免費商用。
這是業內首個中文原生的DiT架構文生圖開源模型,支持中英文雙語輸入及理解,參數量15億。升級后的混元文生圖大模型采用了與 sora 一致的DiT架構,不僅可支持文生圖,也可作為視頻等多模態視覺生成的基礎。
評測數據顯示,最新的騰訊混元文生圖模型效果遠超開源的 Stable Diffusion 模型,是目前效果最好的開源文生圖模型;整體能力屬于國際領先水平。
自研新一代文生圖模型
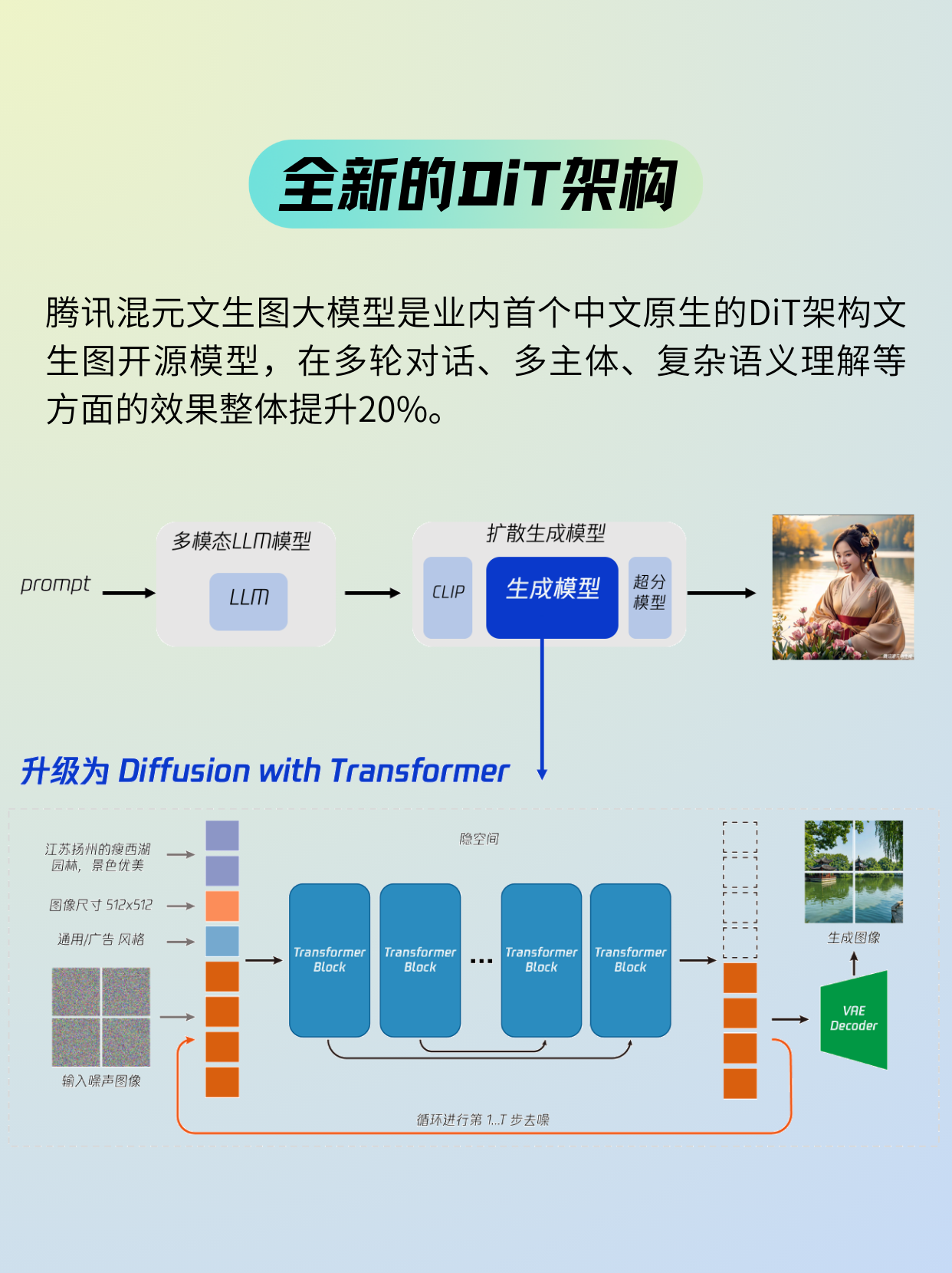
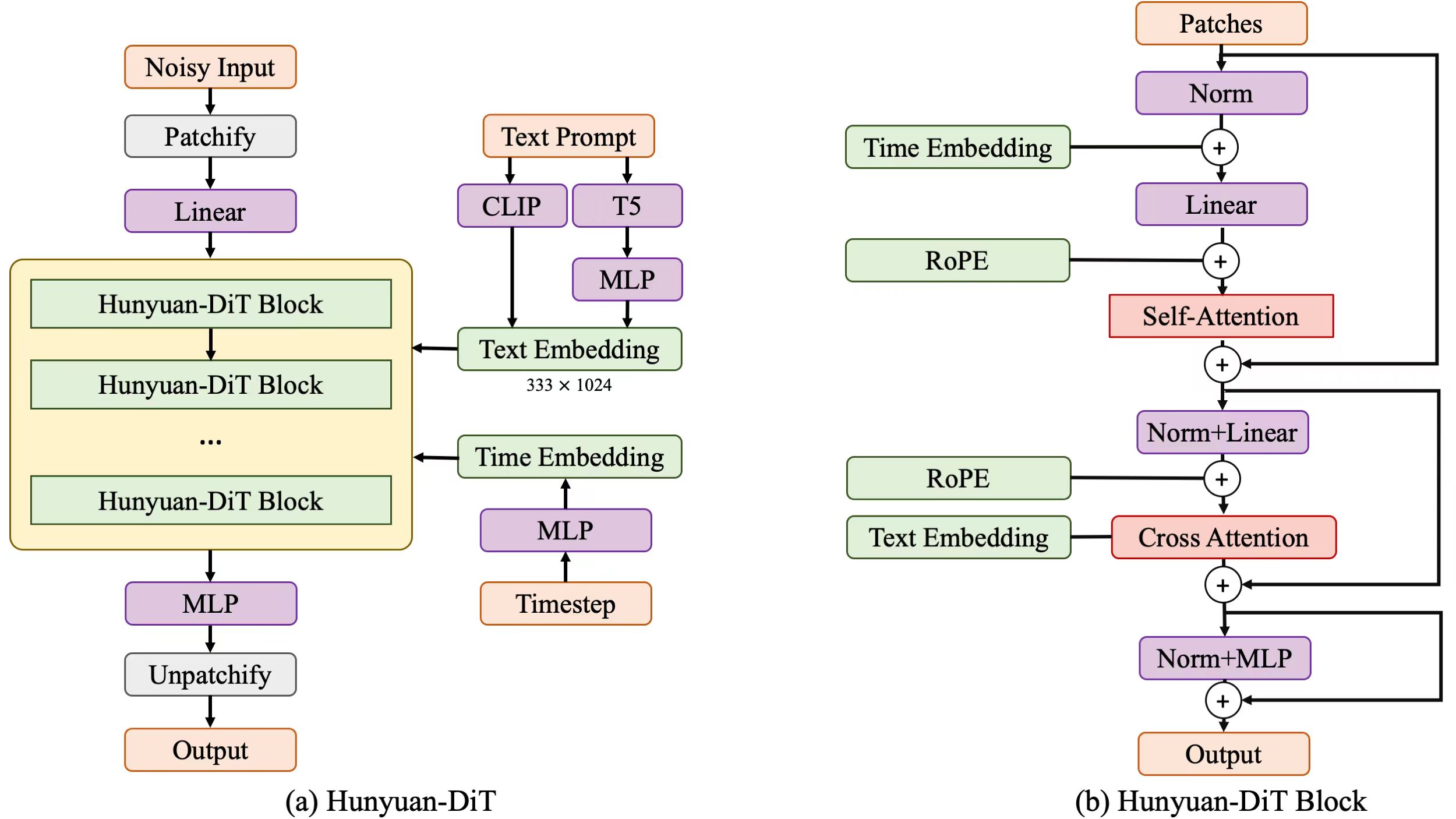
大模型的優異表現,離不開領先的技術架構。升級后的騰訊混元文生圖大模型采用了全新的DiT架構(DiT,即Diffusion With Transformer),這也是Sora和 Stable Diffusion 3 的同款架構和關鍵技術,是一種基于Transformer架構的擴散模型。
過去,視覺生成擴散模型主要基于 U-Net 架構,但隨著參數量的提升,基于 Transformer 架構的擴散模型展現出了更好的擴展性,有助于進一步提升模型的生成質量及效率。騰訊混元是業界最早探索并應用大語言模型結合 DiT 結構的文生圖模型之一。從 2023 年 7 月起,騰訊混元文生圖團隊就明確了基于DiT架構的模型方向,并啟動了新一代模型研發。今年初,混元文生圖大模型已全面升級為DiT架構。
在DiT架構之上,騰訊混元團隊在算法層面優化了模型的長文本理解能力,能夠支持最多 256 字符的內容輸入,達到行業領先水平。同時,在算法層面創新實現了多輪生圖和對話能力,可實現在一張初始生成圖片的基礎上,通過自然語言描述進行調整,從而達到更滿意的效果。
中文原生也是騰訊混元文生圖大模型的一大亮點,此前,像 Stable Diffusion 等主流開源模型核心數據集以英文為主,對中國的語言、美食、文化、習俗都理解不夠。混元文生圖是首個中文原生的DiT模型,具備中英文雙語理解及生成能力,在古詩詞、俚語、傳統建筑、中華美食等中國元素的生成上表現出色。

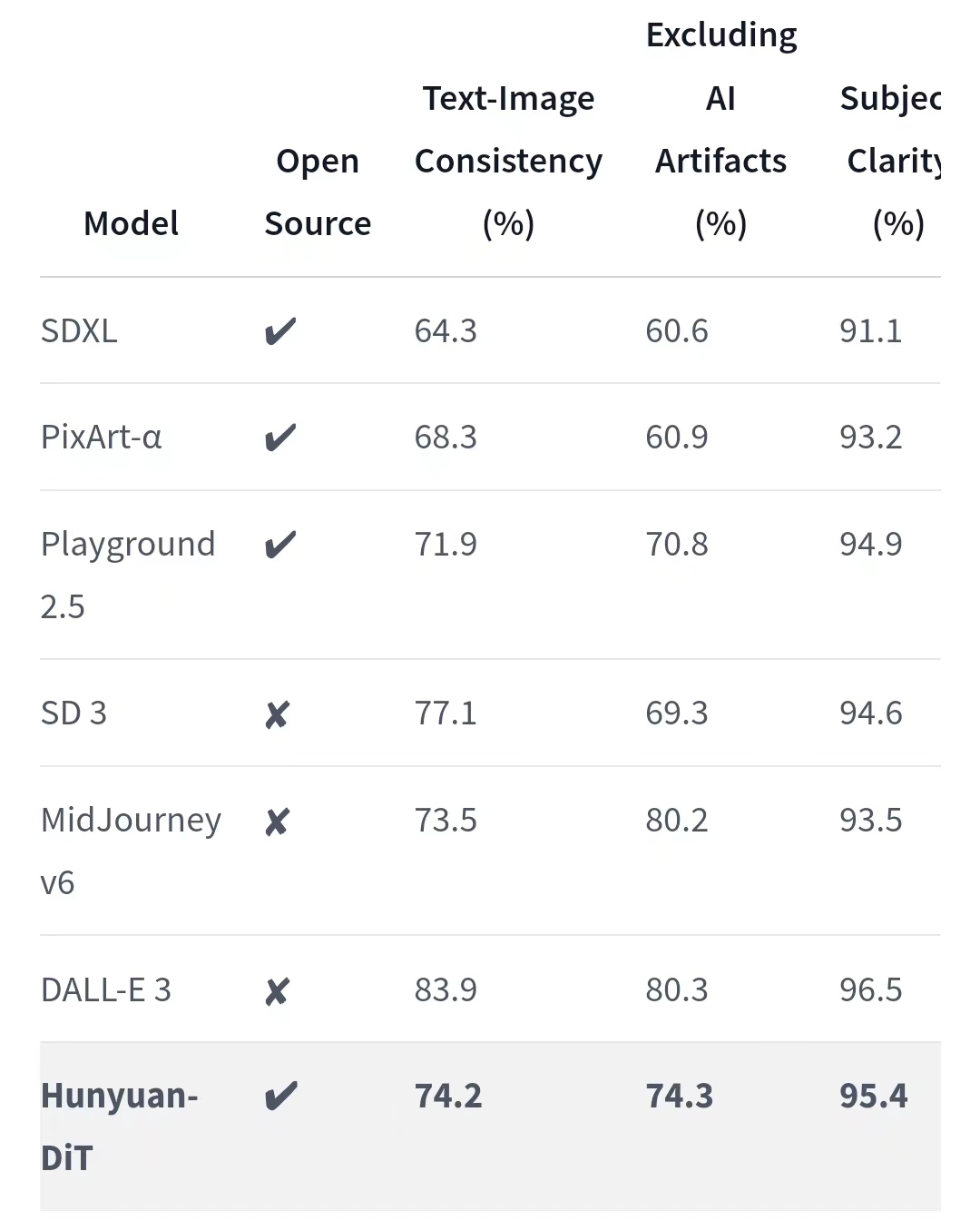
評測結果顯示,新一代騰訊混元文生圖大模型視覺生成整體效果,相比前代提升超過 20%,在語義理解、畫面質感與真實性方面全面提升,在多輪對話、多主體、中國元素、真實人像生成等場景下效果提升顯著。
為了全面比較HunyuanDiT與其他模型的生成能力,研究團隊構建了4個維度的測試集,包括文本圖像一致性、排除AI偽影、主題清晰度、審美。超過50名專業評估人員進行評估。
目前Hunyuan-DiT已經在HuggingFace和Github上開源,感想趣的朋友可親手體驗一番。
全面開源,惠及行業
騰訊混元文生圖能力,已經廣泛被用于素材創作、商品合成、游戲出圖等多項業務及場景中。今年初,騰訊廣告基于騰訊混元大模型,發布了一站式 AI 廣告創意平臺騰訊廣告妙思,可為廣告主提供文生圖、圖生圖、商品背景合成等多場景創意工具,有效提高了廣告生產及投放效率。《央視新聞》《新華日報》《深圳特區報》《南方都市報》《羊城晚報》等20余家媒體,也已經將騰訊混元文生圖用于新聞內容生產。
騰訊文生圖負責人蘆清林表示:“騰訊混元文生圖的研發思路就是實用,堅持從實踐中來,到實踐中去。此次把最新一代模型完整開源出來,是希望與行業共享騰訊在文生圖領域的實踐經驗和研究成果,豐富中文文生圖開源生態,共建下一代視覺生成開源生態,推動大模型行業加速發展。”

基于騰訊此次開源的文生圖模型,開發者及企業無需重頭訓練,即可直接用于推理,并可基于混元文生圖打造專屬的AI繪畫應用及服務,能夠節約大量人力及算力。透明公開的算法,也讓模型的安全性和可靠性得到保障。
同時,基于開放、前沿的混元文生圖基礎模型,也有利于在以 Stable Diffusion 等為主的英文開源社區之外,豐富以中文為主的文生圖開源生態,形成更多樣的原生插件,推動中文文生圖技術研發和應用。
據了解,騰訊在開源上一直持開放態度,已開源了超 170 個優質項目,均來源于騰訊真實業務場景,覆蓋微信、騰訊云、騰訊游戲、騰訊AI、騰訊安全等核心業務板塊,目前在Github上已累計獲得超 47 萬開發者關注及點贊。
























