谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓(xùn)練最快選擇
谷歌力推的JAX在最近的基準(zhǔn)測(cè)試中性能已經(jīng)超過(guò)Pytorch和TensorFlow,7項(xiàng)指標(biāo)排名第一。

而且測(cè)試并不是在JAX性能表現(xiàn)最好的TPU上完成的。

雖然現(xiàn)在在開(kāi)發(fā)者中,Pytorch依然比Tensorflow更受歡迎。

但未來(lái),也許有更多的大模型會(huì)基于JAX平臺(tái)進(jìn)行訓(xùn)練和運(yùn)行。
模型
最近,Keras團(tuán)隊(duì)為三個(gè)后端(TensorFlow、JAX、PyTorch)與原生PyTorch實(shí)現(xiàn)以及搭配TensorFlow的Keras 2進(jìn)行了基準(zhǔn)測(cè)試。
首先,他們?yōu)樯墒胶头巧墒饺斯ぶ悄苋蝿?wù)選擇了一組主流的計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理模型:

對(duì)于模型的Keras版本,其采用了KerasCV和KerasNLP中已有的實(shí)現(xiàn)進(jìn)行構(gòu)建。而對(duì)于原生的PyTorch版本,則選擇了網(wǎng)絡(luò)上最流行的幾個(gè)選項(xiàng):
- 來(lái)自HuggingFace Transformers的BERT、Gemma、Mistral
- 來(lái)自HuggingFace Diffusers的StableDiffusion
- 來(lái)自Meta的SegmentAnything
他們將這組模型稱(chēng)作「Native PyTorch」,以便與使用PyTorch后端的Keras 3版本進(jìn)行區(qū)分。
他們對(duì)所有基準(zhǔn)測(cè)試都使用了合成數(shù)據(jù),并在所有LLM訓(xùn)練和推理中使用了bfloat16精度,同時(shí)在所有LLM訓(xùn)練中使用了LoRA(微調(diào))。
根據(jù)PyTorch團(tuán)隊(duì)的建議,他們?cè)谠鶳yTorch實(shí)現(xiàn)中使用了torch.compile(model, mode="reduce-overhead")(由于不兼容,Gemma和Mistral訓(xùn)練除外)。
為了衡量開(kāi)箱即用的性能,他們使用高級(jí)API(例如HuggingFace的Trainer()、標(biāo)準(zhǔn)PyTorch訓(xùn)練循環(huán)和Keras model.fit()),并盡可能減少配置。
硬件配置
所有基準(zhǔn)測(cè)試均使用Google Cloud Compute Engine進(jìn)行,配置為:一塊擁有40GB顯存的NVIDIA A100 GPU、12個(gè)虛擬CPU和85GB的主機(jī)內(nèi)存。
基準(zhǔn)測(cè)試結(jié)果
表2顯示了基準(zhǔn)測(cè)試結(jié)果(以步/毫秒為單位)。每步都涉及對(duì)單個(gè)數(shù)據(jù)批次進(jìn)行訓(xùn)練或預(yù)測(cè)。
結(jié)果是100步的平均值,但排除了第一個(gè)步,因?yàn)榈谝徊桨四P蛣?chuàng)建和編譯,這會(huì)額外花費(fèi)時(shí)間。
為了確保比較的公平性,對(duì)于相同的模型和任務(wù)(不論是訓(xùn)練還是推理)都使用相同的批大小。
然而,對(duì)于不同的模型和任務(wù),由于它們的規(guī)模和架構(gòu)有所不同,可根據(jù)需要調(diào)整數(shù)據(jù)批大小,從而避免因過(guò)大而導(dǎo)致內(nèi)存溢出,或是批過(guò)小而導(dǎo)致GPU使用不足。
過(guò)小的批大小也會(huì)使PyTorch看起來(lái)較慢,因?yàn)闀?huì)增加Python的開(kāi)銷(xiāo)。
對(duì)于大型語(yǔ)言模型(Gemma和Mistral),測(cè)試時(shí)也使用了相同的批處理大小,因?yàn)樗鼈兪窍嗤?lèi)型的模型,具有類(lèi)似數(shù)量的參數(shù)(7B)。
考慮到用戶對(duì)單批文本生成的需求,也對(duì)批大小為1的文本生成情況進(jìn)行了基準(zhǔn)測(cè)試。

關(guān)鍵發(fā)現(xiàn)
發(fā)現(xiàn)1
不存在「最優(yōu)」后端。
Keras的三種后端各展所長(zhǎng),重要的是,就性能而言,并沒(méi)有哪一個(gè)后端能夠始終勝出。
選擇哪個(gè)后端最快,往往取決于模型的架構(gòu)。
這一點(diǎn)突出了選擇不同框架以追求最佳性能的重要性。Keras 3可以幫助輕松切換后端,以便為模型找到最合適的選擇。
發(fā)現(xiàn)2
Keras 3的性能普遍超過(guò)PyTorch的標(biāo)準(zhǔn)實(shí)現(xiàn)。
相對(duì)于原生PyTorch,Keras 3在吞吐量(步/毫秒)上有明顯的提升。
特別是,在10個(gè)測(cè)試任務(wù)中,有5個(gè)的速度提升超過(guò)了50%。其中,最高更是達(dá)到了290%。

如果是100%,意味著Keras 3的速度是PyTorch的2倍;如果是0%,則表示兩者性能相當(dāng)
發(fā)現(xiàn)3
Keras 3提供一流的「開(kāi)箱即用」性能。
也就是,所有參與測(cè)試的Keras模型都未進(jìn)行過(guò)任何優(yōu)化。相比之下,使用原生PyTorch實(shí)現(xiàn)時(shí),通常需要用戶自行進(jìn)行更多性能優(yōu)化。
除了上面分享的數(shù)據(jù),測(cè)試中還注意到在HuggingFace Diffusers的StableDiffusion推理功能上,從版本0.25.0升級(jí)到0.3.0時(shí),性能提升超過(guò)了100%。
同樣,在HuggingFace Transformers中,Gemma從4.38.1版本升級(jí)至4.38.2版本也顯著提高了性能。
這些性能的提升凸顯了HuggingFace在性能優(yōu)化方面的專(zhuān)注和努力。
對(duì)于一些手動(dòng)優(yōu)化較少的模型,如SegmentAnything,則使用了研究作者提供的實(shí)現(xiàn)。在這種情況下,與Keras相比,性能差距比大多數(shù)其他模型更大。
這表明,Keras能夠提供卓越的開(kāi)箱即用性能,用戶無(wú)需深入了解所有優(yōu)化技巧即可享受到快速的模型運(yùn)行速度。
發(fā)現(xiàn)4
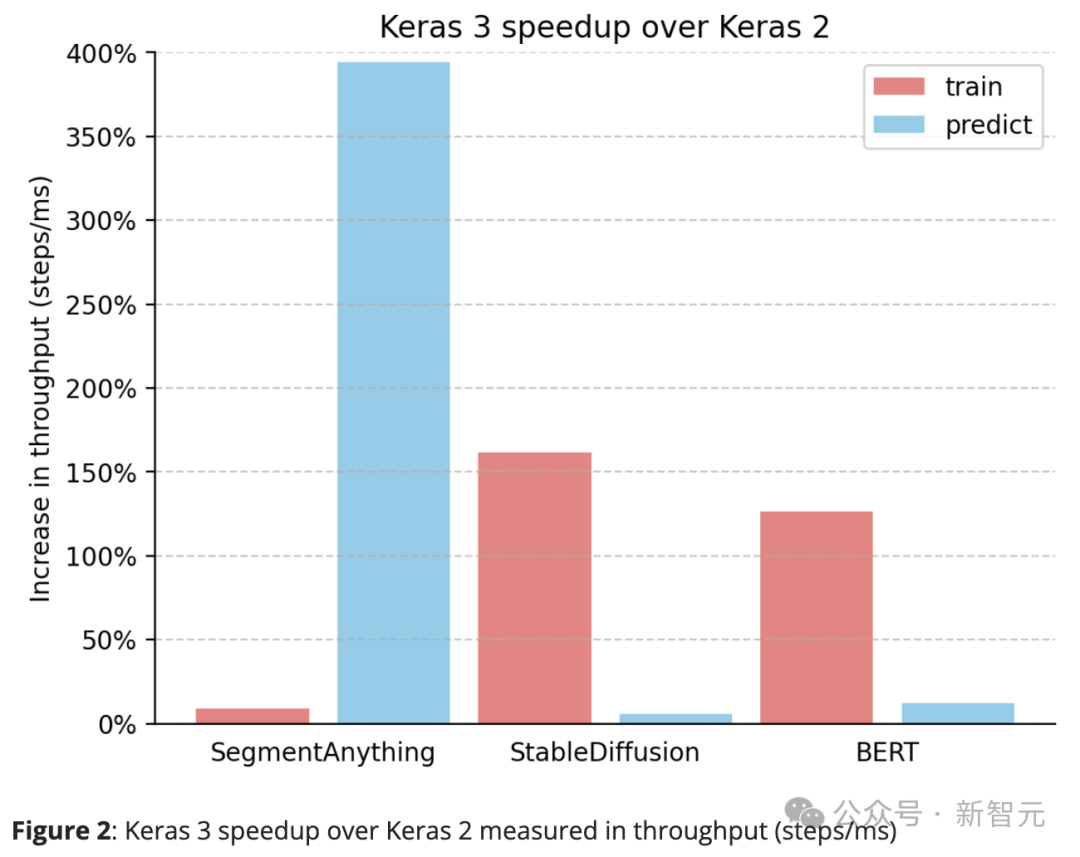
Keras 3的表現(xiàn)始終優(yōu)于Keras 2。
例如,SegmentAnything的推理速度提升了驚人的380%,StableDiffusion的訓(xùn)練處理速度提升了150%以上,BERT的訓(xùn)練處理速度也提升了100%以上。
這主要是因?yàn)镵eras 2在某些情況下直接使用了更多的TensorFlow融合操作,而這可能對(duì)于XLA的編譯并不是最佳選擇。
值得注意的是,即使僅升級(jí)到Keras 3并繼續(xù)使用TensorFlow后端,也能顯著提升性能。
結(jié)論
框架的性能在很大程度上取決于具體使用的模型。
Keras 3能夠幫助為任務(wù)選擇最快的框架,這種選擇幾乎總能超越Keras 2和PyTorch實(shí)現(xiàn)。
更為重要的是,Keras 3模型無(wú)需進(jìn)行復(fù)雜的底層優(yōu)化,即可提供卓越的開(kāi)箱即用性能。