清華微軟開(kāi)源全新提示詞壓縮工具,長(zhǎng)度驟降80%!GitHub怒砍3.1K星
在自然語(yǔ)言處理中,有很多信息其實(shí)是重復(fù)的。
如果能將提示詞進(jìn)行有效地壓縮,某種程度上也相當(dāng)于擴(kuò)大了模型支持上下文的長(zhǎng)度。
現(xiàn)有的信息熵方法是通過(guò)刪除某些詞或短語(yǔ)來(lái)減少這種冗余。
然而,作為依據(jù)的信息熵僅僅考慮了文本的單向上下文,進(jìn)而可能會(huì)遺漏對(duì)于壓縮至關(guān)重要的信息;此外,信息熵的計(jì)算方式與壓縮提示詞的真正目的并不完全一致。
為了應(yīng)對(duì)這些挑戰(zhàn),來(lái)自清華和微軟的研究人員提出了一種全新的數(shù)據(jù)精煉流程——LLMLingua-2,目的是從大型語(yǔ)言模型(LLM)中提取知識(shí),實(shí)現(xiàn)在不丟失關(guān)鍵信息的前提下對(duì)提示詞進(jìn)行壓縮。

項(xiàng)目在GitHub上已經(jīng)斬獲3.1k星
結(jié)果顯示,LLMLingua-2可以將文本長(zhǎng)度大幅縮減至最初的20%,有效減少了處理時(shí)間和成本。
此外,與前一版本LLMLingua以及其他類似技術(shù)相比,LLMLingua 2的處理速度提高了3到6倍。

論文地址:https://arxiv.org/abs/2403.12968
在這個(gè)過(guò)程中,原始文本首先被輸入模型。
模型會(huì)評(píng)估每個(gè)詞的重要性,決定是保留還是刪除,同時(shí)也會(huì)考慮到詞語(yǔ)之間的關(guān)系。
最終,模型會(huì)選擇那些評(píng)分最高的詞匯組成一個(gè)更簡(jiǎn)短的提示詞。

團(tuán)隊(duì)在包括MeetingBank、LongBench、ZeroScrolls、GSM8K和BBH在內(nèi)的多個(gè)數(shù)據(jù)集上測(cè)試了LLMLingua-2模型。
盡管這個(gè)模型體積不大,但它在基準(zhǔn)測(cè)試中取得了顯著的性能提升,并且證明了其在不同的大語(yǔ)言模型(從GPT-3.5到Mistral-7B)和語(yǔ)種(從英語(yǔ)到中文)上具有出色的泛化能力。
系統(tǒng)提示:
作為一名杰出的語(yǔ)言學(xué)家,你擅長(zhǎng)將較長(zhǎng)的文段壓縮成簡(jiǎn)短的表達(dá)方式,方法是去除那些不重要的詞匯,同時(shí)盡可能多地保留信息。
用戶提示:
請(qǐng)將給定的文本壓縮成簡(jiǎn)短的表達(dá)形式,使得你(GPT-4)能夠盡可能準(zhǔn)確地還原原文。不同于常規(guī)的文本壓縮,我需要你遵循以下五個(gè)條件:
1. 只移除那些不重要的詞匯。
2. 保持原始詞匯的順序不變。
3. 保持原始詞匯不變。
4. 不使用任何縮寫(xiě)或表情符號(hào)。
5. 不添加任何新的詞匯或符號(hào)。
請(qǐng)盡可能地壓縮原文,同時(shí)保留盡可能多的信息。如果你明白了,請(qǐng)對(duì)以下文本進(jìn)行壓縮:{待壓縮文本}
壓縮后的文本是:[...]

結(jié)果顯示,在問(wèn)答、摘要撰寫(xiě)和邏輯推理等多種語(yǔ)言任務(wù)中,LLMLingua-2都顯著優(yōu)于原有的LLMLingua模型和其他選擇性上下文策略。
值得一提的是,這種壓縮方法對(duì)于不同的大語(yǔ)言模型(從GPT-3.5到Mistral-7B)和不同的語(yǔ)言(從英語(yǔ)到中文)同樣有效。
而且,只需兩行代碼,就可以實(shí)現(xiàn)LLMLingua-2的部署。
目前,該模型已經(jīng)被集成到了廣泛使用的RAG框架LangChain和LlamaIndex當(dāng)中。
實(shí)現(xiàn)方法
為了克服現(xiàn)有基于信息熵的文本壓縮方法所面臨的問(wèn)題,LLMLingua-2采取了一種創(chuàng)新的數(shù)據(jù)提煉策略。
這一策略通過(guò)從GPT-4這樣的大語(yǔ)言模型中抽取精華信息,實(shí)現(xiàn)了在不損失關(guān)鍵內(nèi)容和避免添加錯(cuò)誤信息的前提下,對(duì)文本進(jìn)行高效壓縮。
提示設(shè)計(jì)
要想充分利用GPT-4的文本壓縮潛力,關(guān)鍵在于如何設(shè)定精確的壓縮指令。
也就是在壓縮文本時(shí),指導(dǎo)GPT-4僅移除那些在原始文本中不那么重要的詞匯,同時(shí)避免在此過(guò)程中引入任何新的詞匯。
這樣做的目的是為了確保壓縮后的文本盡可能地保持原文的真實(shí)性和完整性。

標(biāo)注與篩選
研究人員利用了從GPT-4等大語(yǔ)言模型中提煉出的知識(shí),開(kāi)發(fā)了一種新穎的數(shù)據(jù)標(biāo)注算法。
這個(gè)算法能夠?qū)υ闹械拿恳粋€(gè)詞匯進(jìn)行標(biāo)注,明確指出在壓縮過(guò)程中哪些詞匯是必須保留的。
為了保證所構(gòu)建數(shù)據(jù)集的高質(zhì)量,他們還設(shè)計(jì)了兩種質(zhì)量監(jiān)控機(jī)制,專門(mén)用來(lái)識(shí)別并排除那些品質(zhì)不佳的數(shù)據(jù)樣本。

壓縮器
最后,研究人員將文本壓縮的問(wèn)題轉(zhuǎn)化為了一個(gè)對(duì)每個(gè)詞匯(Token)進(jìn)行分類的任務(wù),并采用了強(qiáng)大的Transformer作為特征提取器。
這個(gè)工具能夠理解文本的前后關(guān)系,從而精確地抓取對(duì)于文本壓縮至關(guān)重要的信息。
通過(guò)在精心構(gòu)建的數(shù)據(jù)集上進(jìn)行訓(xùn)練,研究人員的模型能夠根據(jù)每個(gè)詞匯的重要性,計(jì)算出一個(gè)概率值來(lái)決定這個(gè)詞匯是應(yīng)該被保留在最終的壓縮文本中,還是應(yīng)該被舍棄。

性能評(píng)估
研究人員在一系列任務(wù)上測(cè)試了LLMLingua-2的性能,這些任務(wù)包括上下文學(xué)習(xí)、文本摘要、對(duì)話生成、多文檔和單文檔問(wèn)答、代碼生成以及合成任務(wù),既包括了域內(nèi)的數(shù)據(jù)集也包括了域外的數(shù)據(jù)集。
測(cè)試結(jié)果顯示,研究人員的方法在保持高性能的同時(shí),減少了最小的性能損失,并且在任務(wù)不特定的文本壓縮方法中表現(xiàn)突出。
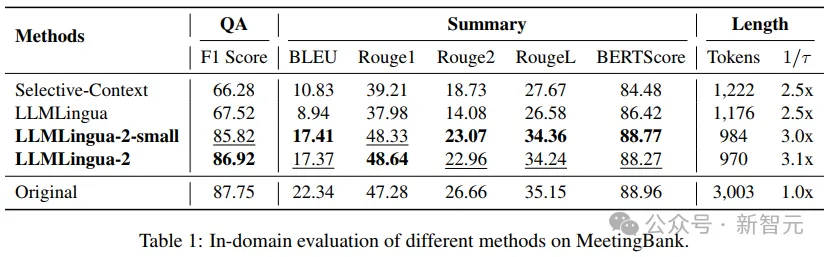
- 域內(nèi)測(cè)試(MeetingBank)
研究人員將LLMLingua-2在MeetingBank測(cè)試集上的表現(xiàn)與其他強(qiáng)大的基線方法進(jìn)行了對(duì)比。
盡管他們的模型規(guī)模遠(yuǎn)小于基線中使用的LLaMa-2-7B,但在問(wèn)答和文本摘要任務(wù)上,研究人員的方法不僅大幅提升了性能,而且與原始文本提示的表現(xiàn)相差無(wú)幾。
- 域外測(cè)試(LongBench、GSM8K和BBH)
考慮到研究人員的模型僅在MeetingBank的會(huì)議記錄數(shù)據(jù)上進(jìn)行了訓(xùn)練,研究人員進(jìn)一步探索了其在長(zhǎng)文本、邏輯推理和上下文學(xué)習(xí)等不同場(chǎng)景下的泛化能力。
值得一提的是,盡管LLMLingua-2只在一個(gè)數(shù)據(jù)集上訓(xùn)練,但在域外的測(cè)試中,它的表現(xiàn)不僅與當(dāng)前最先進(jìn)的任務(wù)不特定壓縮方法相媲美,甚至在某些情況下還有過(guò)之而無(wú)不及。
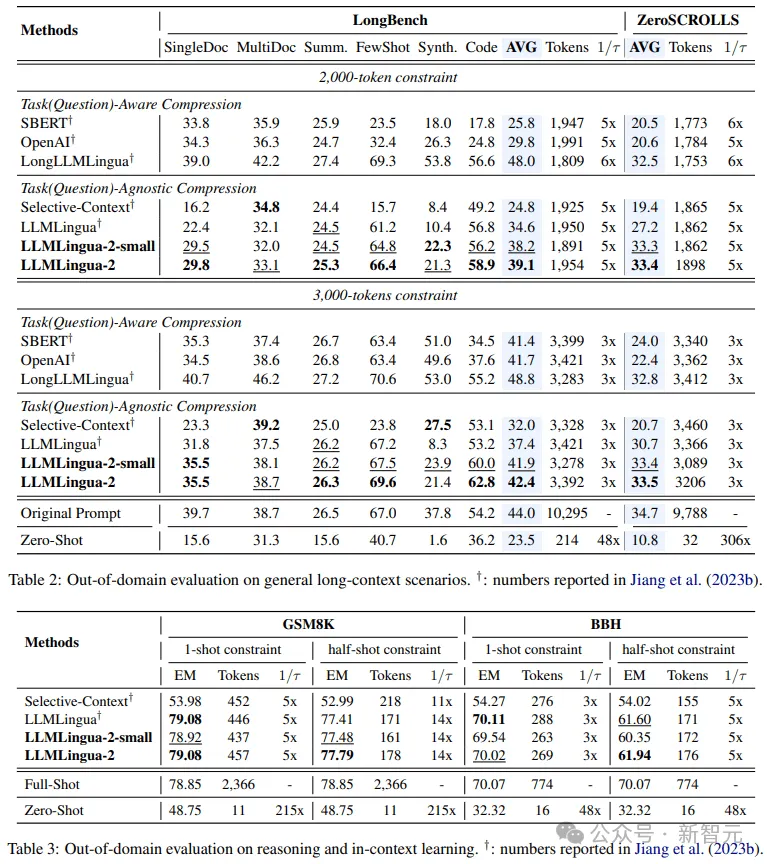
即使是研究人員的較小模型(BERT-base大小),也能達(dá)到與原始提示相當(dāng)?shù)男阅埽谀承┣闆r下甚至略高于原始提示。
雖然研究人員的方法取得了可喜的成果,但與其他任務(wù)感知壓縮方法(如Longbench上的LongLLMlingua)相比,研究人員的方法還存在不足。
研究人員將這種性能差距歸因于它們從問(wèn)題中獲取的額外信息。不過(guò),研究人員的模型具有與任務(wù)無(wú)關(guān)的特點(diǎn),因此在不同場(chǎng)景中部署時(shí),它是一種具有良好通用性的高效選擇。
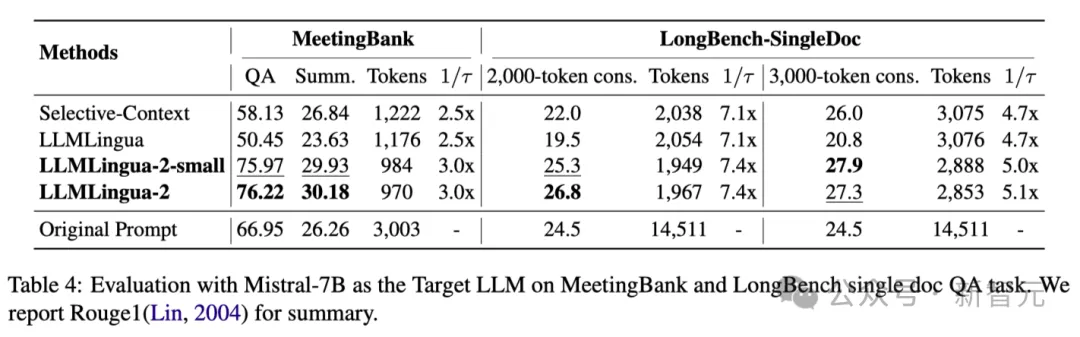
上表4列出了使用Mistral-7Bv0.1 4作為目標(biāo)LLM的不同方法的結(jié)果。
與其他基線方法相比,研究人員的方法在性能上有明顯的提升,展示了其在目標(biāo)LLM上良好的泛化能力。
值得注意的是,LLMLingua-2的性能甚至優(yōu)于原始提示。
研究人員推測(cè),Mistral-7B在管理長(zhǎng)上下文方面的能力可能不如GPT-3.5-Turbo。
研究人員的方法通過(guò)提供信息密度更高的短提示,有效提高了 Mistral7B 的最終推理性能。
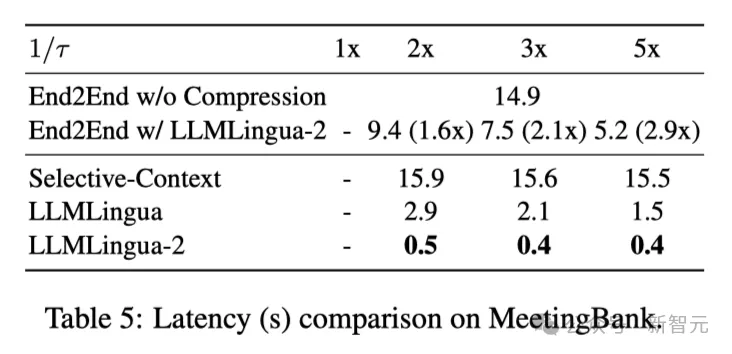
上表5顯示了不同系統(tǒng)在不同壓縮比的V100-32G GPU上的延遲。
結(jié)果表明,與其他壓縮方法相比,LLMLingua2的計(jì)算開(kāi)銷要小得多,可以實(shí)現(xiàn)1.6倍到2.9倍的端到端速度提升。
此外,研究人員的方法還能將GPU內(nèi)存成本降低8倍,從而降低對(duì)硬件資源的需求。
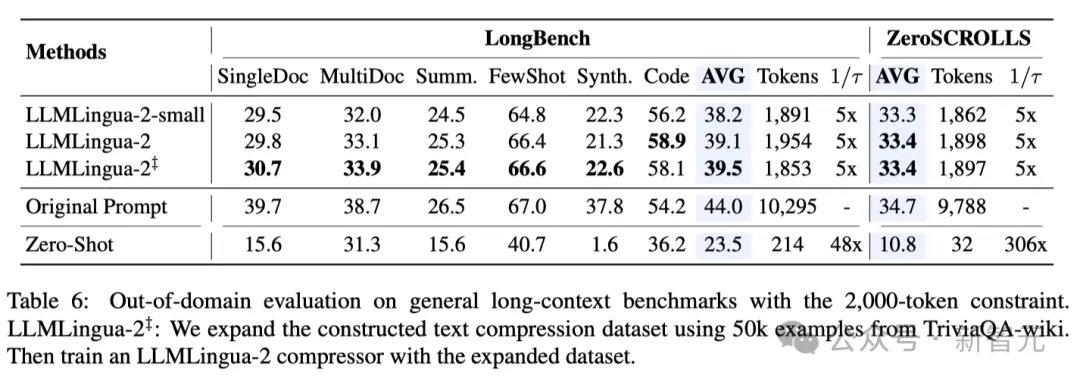
上下文意識(shí)觀察 研究人員觀察到,隨著壓縮率的增加,LLMLingua-2可以有效地保持與完整上下文相關(guān)的信息量最大的單詞。
這要?dú)w功于雙向上下文感知特征提取器的采用,以及明確朝著及時(shí)壓縮目標(biāo)進(jìn)行優(yōu)化的策略。
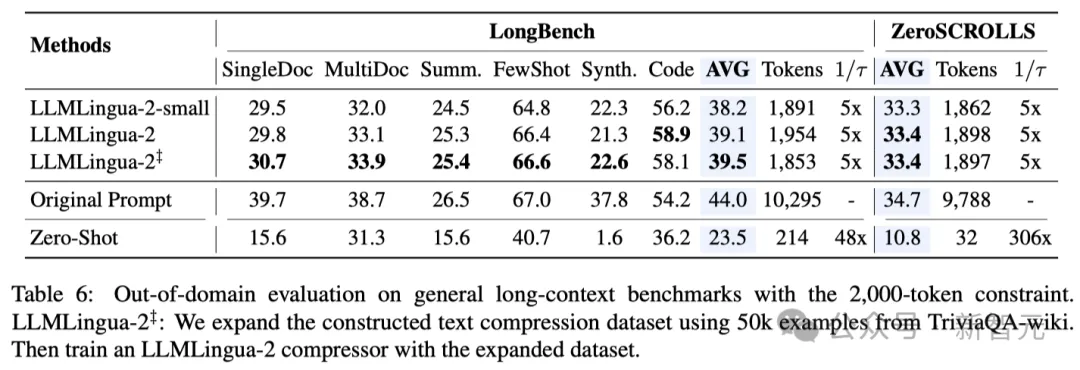
研究人員觀察到,隨著壓縮率的增加,LLMLingua-2可以有效地保持與完整上下文相關(guān)的信息量最大的單詞。
這要?dú)w功于雙向上下文感知特征提取器的采用,以及明確朝著及時(shí)壓縮目標(biāo)進(jìn)行優(yōu)化的策略。
最后研究人員讓GPT-4 從 LLMLingua-2壓縮提示中重構(gòu)原始提示音。
結(jié)果表明,GPT-4可以有效地重建原始提示,這表明在LLMLingua-2壓縮過(guò)程中并沒(méi)有丟失基本信息。