超強!深度學習Top10算法!
自2006年深度學習概念被提出以來,20年快過去了,深度學習作為人工智能領域的一場革命,已經催生了許多具有影響力的算法。那么,你所認為深度學習的top10算法有哪些呢?

以下是花哥我心目中的深度學習top10算法,它們在創新性、應用價值和影響力方面都具有重要的地位。
1、深度神經網絡(DNN)
背景:深度神經網絡(DNN)也叫多層感知機,是最普遍的深度學習算法,發明之初由于算力瓶頸而飽受質疑,直到近些年算力、數據的爆發才迎來突破。
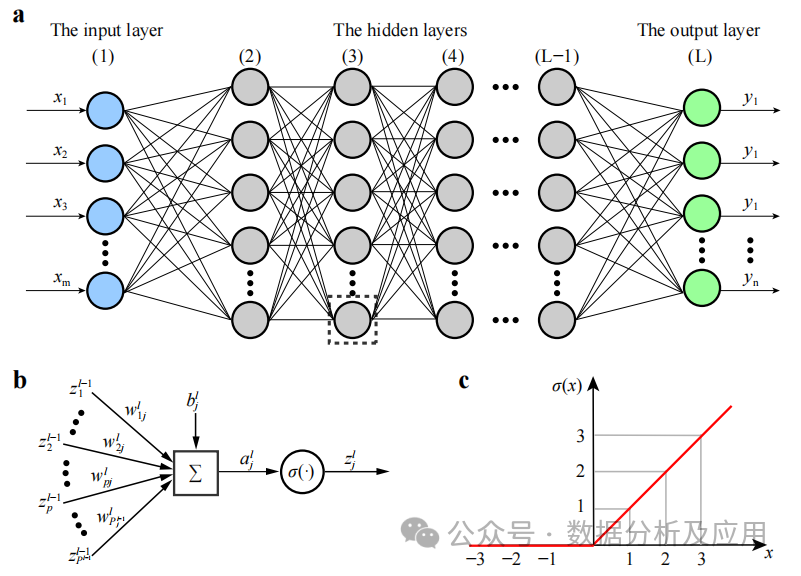
模型原理:它是一種包含多個隱藏層的神經網絡。每一層都將其輸入傳遞給下一層,并使用非線性激活函數來引入學習的非線性特性。通過組合這些非線性變換,DNN能夠學習輸入數據的復雜特征表示。
模型訓練:使用反向傳播算法和梯度下降優化算法來更新權重。在訓練過程中,通過計算損失函數關于權重的梯度,然后使用梯度下降或其他優化算法來更新權重,以最小化損失函數。
優點:能夠學習輸入數據的復雜特征,并捕獲非線性關系。具有強大的特征學習和表示能力。
缺點:隨著網絡深度的增加,梯度消失問題變得嚴重,導致訓練不穩定。容易陷入局部最小值,可能需要復雜的初始化策略和正則化技術。
使用場景:圖像分類、語音識別、自然語言處理、推薦系統等。
Python示例代碼:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 假設有10個輸入特征和3個輸出類別
input_dim = 10
num_classes = 3
# 創建DNN模型
model = Sequential()
model.add(Dense(64, activatinotallow='relu', input_shape=(input_dim,)))
model.add(Dense(32, activatinotallow='relu'))
model.add(Dense(num_classes, activatinotallow='softmax'))
# 編譯模型,選擇優化器和損失函數
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 假設有100個樣本的訓練數據和標簽
X_train = np.random.rand(100, input_dim)
y_train = np.random.randint(0, 2, size=(100, num_classes))
# 訓練模型
model.fit(X_train, y_train, epochs=10)2、卷積神經網絡(CNN)
模型原理:卷積神經網絡(CNN)是一種專門為處理圖像數據而設計的神經網絡,由Lechun大佬設計的Lenet是CNN的開山之作。CNN通過使用卷積層來捕獲局部特征,并通過池化層來降低數據的維度。卷積層對輸入數據進行局部卷積操作,并使用參數共享機制來減少模型的參數數量。池化層則對卷積層的輸出進行下采樣,以降低數據的維度和計算復雜度。這種結構特別適合處理圖像數據。
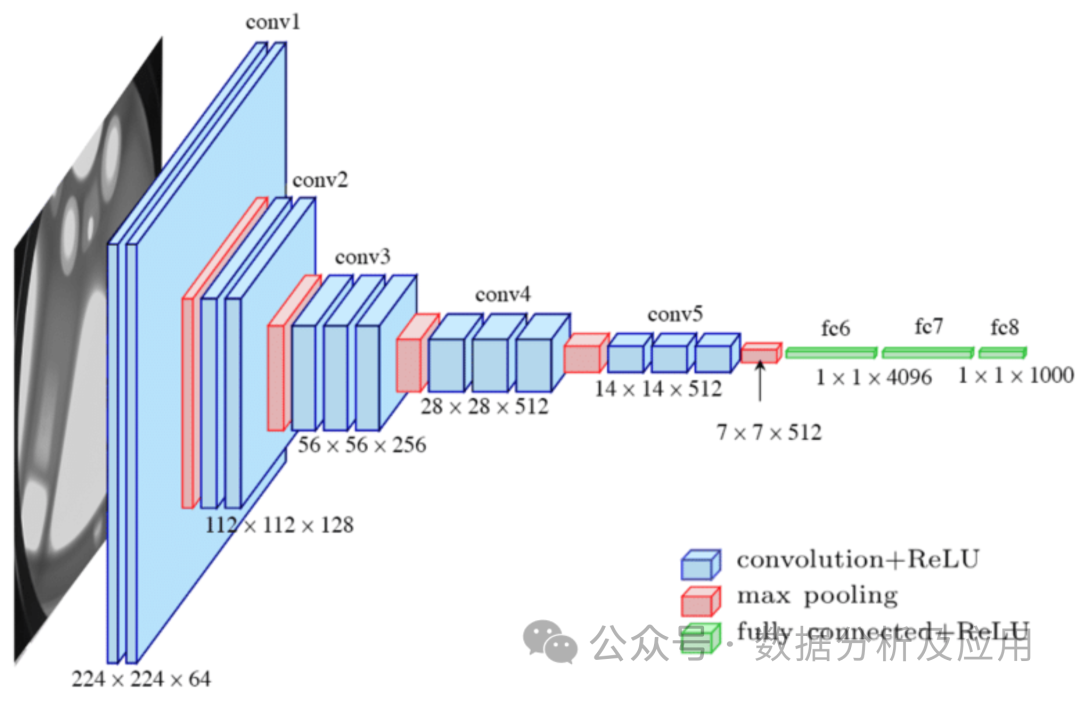
模型訓練:使用反向傳播算法和梯度下降優化算法來更新權重。在訓練過程中,通過計算損失函數關于權重的梯度,然后使用梯度下降或其他優化算法來更新權重,以最小化損失函數。
優點:能夠有效地處理圖像數據,并捕獲局部特征。具有較少的參數數量,降低了過擬合的風險。
缺點:對于序列數據或長距離依賴關系可能不太適用。可能需要對輸入數據進行復雜的預處理。
使用場景:圖像分類、目標檢測、語義分割等。
Python示例代碼
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 假設輸入圖像的形狀是64x64像素,有3個顏色通道
input_shape = (64, 64, 3)
# 創建CNN模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activatinotallow='relu', input_shape=input_shape))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activatinotallow='relu'))
model.add(Flatten())
model.add(Dense(128, activatinotallow='relu'))
model.add(Dense(num_classes, activatinotallow='softmax'))
# 編譯模型,選擇優化器和損失函數
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 假設有100個樣本的訓練數據和標簽
X_train = np.random.rand(100, *input_shape)
y_train = np.random.randint(0, 2, size=(100, num_classes))
# 訓練模型
model.fit(X_train, y_train, epochs=10)3、殘差網絡(ResNet)
隨著深度學習的快速發展,深度神經網絡在多個領域取得了顯著的成功。然而,深度神經網絡的訓練面臨著梯度消失和模型退化等問題,這限制了網絡的深度和性能。為了解決這些問題,殘差網絡(ResNet)被提出。
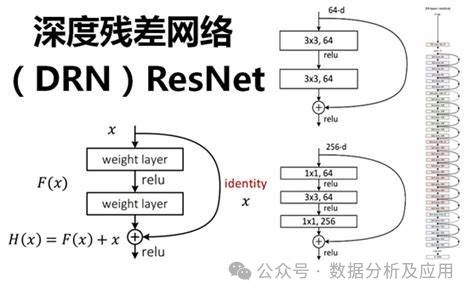
模型原理:
ResNet通過引入“殘差塊”來解決深度神經網絡中的梯度消失和模型退化問題。殘差塊由一個“跳躍連接”和一個或多個非線性層組成,使得梯度可以直接從后面的層反向傳播到前面的層,從而更好地訓練深度神經網絡。通過這種方式,ResNet能夠構建非常深的網絡結構,并在多個任務上取得了優異的性能。
模型訓練:
ResNet的訓練通常使用反向傳播算法和優化算法(如隨機梯度下降)。在訓練過程中,通過計算損失函數關于權重的梯度,并使用優化算法更新權重,以最小化損失函數。此外,為了加速訓練過程和提高模型的泛化能力,還可以采用正則化技術、集成學習等方法。
優點:
- 解決了梯度消失和模型退化問題:通過引入殘差塊和跳躍連接,ResNet能夠更好地訓練深度神經網絡,避免了梯度消失和模型退化的問題。
- 構建了非常深的網絡結構:由于解決了梯度消失和模型退化問題,ResNet能夠構建非常深的網絡結構,從而提高了模型的性能。
- 在多個任務上取得了優異的性能:由于其強大的特征學習和表示能力,ResNet在多個任務上取得了優異的性能,如圖像分類、目標檢測等。
缺點:
- 計算量大:由于ResNet通常構建非常深的網絡結構,因此計算量較大,需要較高的計算資源和時間進行訓練。
- 參數調優難度大:ResNet的參數數量眾多,需要花費大量時間和精力進行調優和超參數選擇。
- 對初始化權重敏感:ResNet對初始化權重的選擇敏感度高,如果初始化權重不合適,可能會導致訓練不穩定或過擬合問題。
使用場景:
ResNet在計算機視覺領域有著廣泛的應用場景,如圖像分類、目標檢測、人臉識別等。此外,ResNet還可以用于自然語言處理、語音識別等領域。
Python示例代碼(簡化版):
在這個簡化版的示例中,我們將演示如何使用Keras庫構建一個簡單的ResNet模型。
from keras.models import Sequential
from keras.layers import Conv2D, Add, Activation, BatchNormalization, Shortcut
def residual_block(input, filters):
x = Conv2D(filters=filters, kernel_size=(3, 3), padding='same')(input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=filters, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x4、LSTM(長短時記憶網絡)
在處理序列數據時,傳統的循環神經網絡(RNN)面臨著梯度消失和模型退化等問題,這限制了網絡的深度和性能。為了解決這些問題,LSTM被提出。
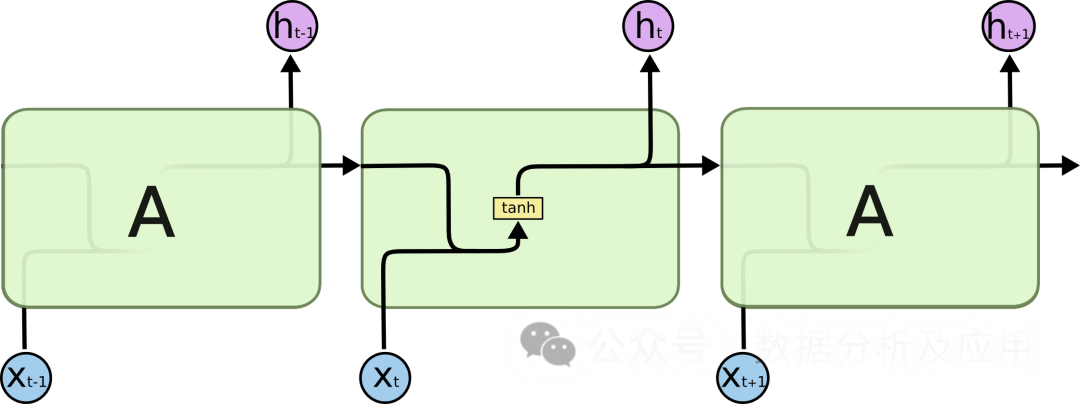
模型原理:
LSTM通過引入“門控”機制來控制信息的流動,從而解決梯度消失和模型退化問題。LSTM有三個門控機制:輸入門、遺忘門和輸出門。輸入門決定了新信息的進入,遺忘門決定了舊信息的遺忘,輸出門決定最終輸出的信息。通過這些門控機制,LSTM能夠在長期依賴問題上表現得更好。
模型訓練:
LSTM的訓練通常使用反向傳播算法和優化算法(如隨機梯度下降)。在訓練過程中,通過計算損失函數關于權重的梯度,并使用優化算法更新權重,以最小化損失函數。此外,為了加速訓練過程和提高模型的泛化能力,還可以采用正則化技術、集成學習等方法。
優點:
- 解決梯度消失和模型退化問題:通過引入門控機制,LSTM能夠更好地處理長期依賴問題,避免了梯度消失和模型退化的問題。
- 構建非常深的網絡結構:由于解決了梯度消失和模型退化問題,LSTM能夠構建非常深的網絡結構,從而提高了模型的性能。
- 在多個任務上取得了優異的性能:由于其強大的特征學習和表示能力,LSTM在多個任務上取得了優異的性能,如文本生成、語音識別、機器翻譯等。
缺點:
- 參數調優難度大:LSTM的參數數量眾多,需要花費大量時間和精力進行調優和超參數選擇。
- 對初始化權重敏感:LSTM對初始化權重的選擇敏感度高,如果初始化權重不合適,可能會導致訓練不穩定或過擬合問題。
- 計算量大:由于LSTM通常構建非常深的網絡結構,因此計算量較大,需要較高的計算資源和時間進行訓練。
使用場景:
LSTM在自然語言處理領域有著廣泛的應用場景,如文本生成、機器翻譯、語音識別等。此外,LSTM還可以用于時間序列分析、推薦系統等領域。
Python示例代碼(簡化版):
from keras.models import Sequential
from keras.layers import LSTM, Dense
def lstm_model(input_shape, num_classes):
model = Sequential()
model.add(LSTM(units=128, input_shape=input_shape)) # 添加一個LSTM層
model.add(Dense(units=num_classes, activatinotallow='softmax')) # 添加一個全連接層
return model5、Word2Vec
Word2Vec模型是表征學習的開山之作。由Google的科學家們開發的一種用于自然語言處理的(淺層)神經網絡模型。Word2Vec模型的目標是將每個詞向量化為一個固定大小的向量,這樣相似的詞就可以被映射到相近的向量空間中。
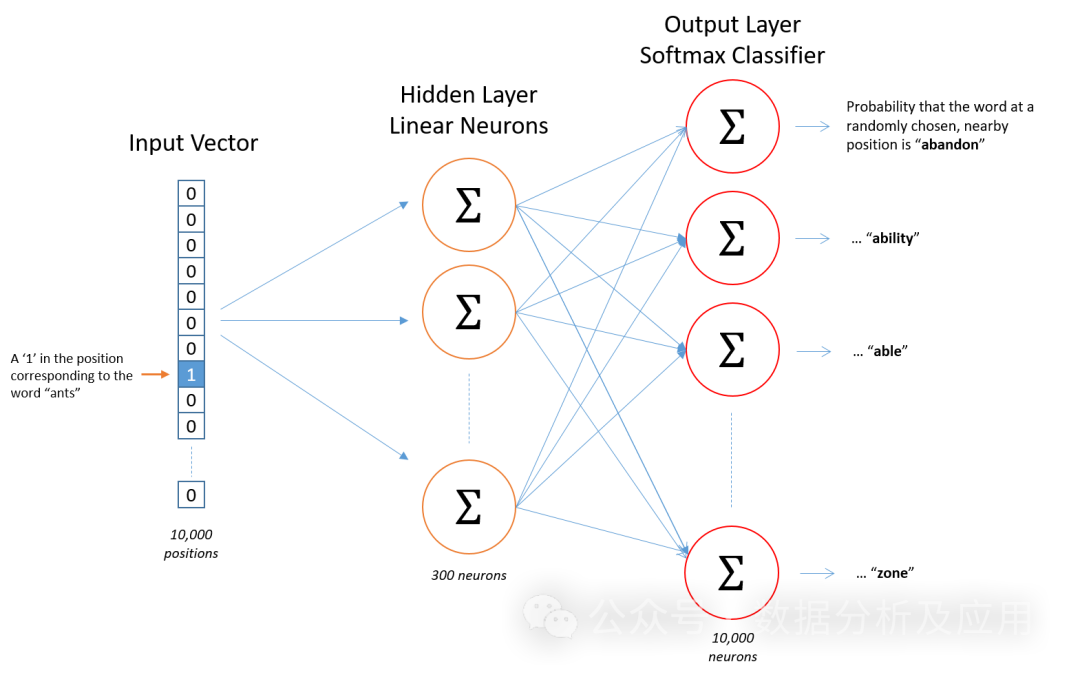
模型原理
Word2Vec模型基于神經網絡,利用輸入的詞預測其上下文詞。在訓練過程中,模型嘗試學習到每個詞的向量表示,使得在給定上下文中出現的詞與目標詞的向量表示盡可能接近。這種訓練方式稱為“Skip-gram”或“Continuous Bag of Words”(CBOW)。
模型訓練
訓練Word2Vec模型需要大量的文本數據。首先,將文本數據預處理為一系列的詞或n-gram。然后,使用神經網絡訓練這些詞或n-gram的上下文。在訓練過程中,模型會不斷地調整詞的向量表示,以最小化預測誤差。
優點
- 語義相似性: Word2Vec能夠學習到詞與詞之間的語義關系,相似的詞在向量空間中距離相近。
- 高效的訓練: Word2Vec的訓練過程相對高效,可以在大規模文本數據上訓練。
- 可解釋性: Word2Vec的詞向量具有一定的可解釋性,可以用于諸如聚類、分類、語義相似性計算等任務。
缺點
- 數據稀疏性: 對于大量未在訓練數據中出現的詞,Word2Vec可能無法為其生成準確的向量表示。
- 上下文窗口: Word2Vec只考慮了固定大小的上下文,可能會忽略更遠的依賴關系。
- 計算復雜度: Word2Vec的訓練和推理過程需要大量的計算資源。
- 參數調整: Word2Vec的性能高度依賴于超參數(如向量維度、窗口大小、學習率等)的設置。
使用場景
Word2Vec被廣泛應用于各種自然語言處理任務,如文本分類、情感分析、信息提取等。例如,可以使用Word2Vec來識別新聞報道的情感傾向(正面或負面),或者從大量文本中提取關鍵實體或概念。
Python示例代碼
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
from nltk.corpus import abc
import nltk
# 下載和加載abc語料庫
nltk.download('abc')
corpus = abc.sents()
# 將語料庫分詞并轉換為小寫
sentences = [[word.lower() for word in word_tokenize(text)] for text in corpus]
# 訓練Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=5, workers=4)
# 查找詞"the"的向量表示
vector = model.wv['the']
# 計算與其他詞的相似度
similarity = model.wv.similarity('the', 'of')
# 打印相似度值
print(similarity)6、Transformer
背景:
在深度學習的早期階段,卷積神經網絡(CNN)在圖像識別和自然語言處理領域取得了顯著的成功。然而,隨著任務復雜度的增加,序列到序列(Seq2Seq)模型和循環神經網絡(RNN)成為處理序列數據的常用方法。盡管RNN及其變體在某些任務上表現良好,但它們在處理長序列時容易遇到梯度消失和模型退化問題。為了解決這些問題,Transformer模型被提出。而后的GPT、Bert等大模型都是基于Transformer實現了卓越的性能!
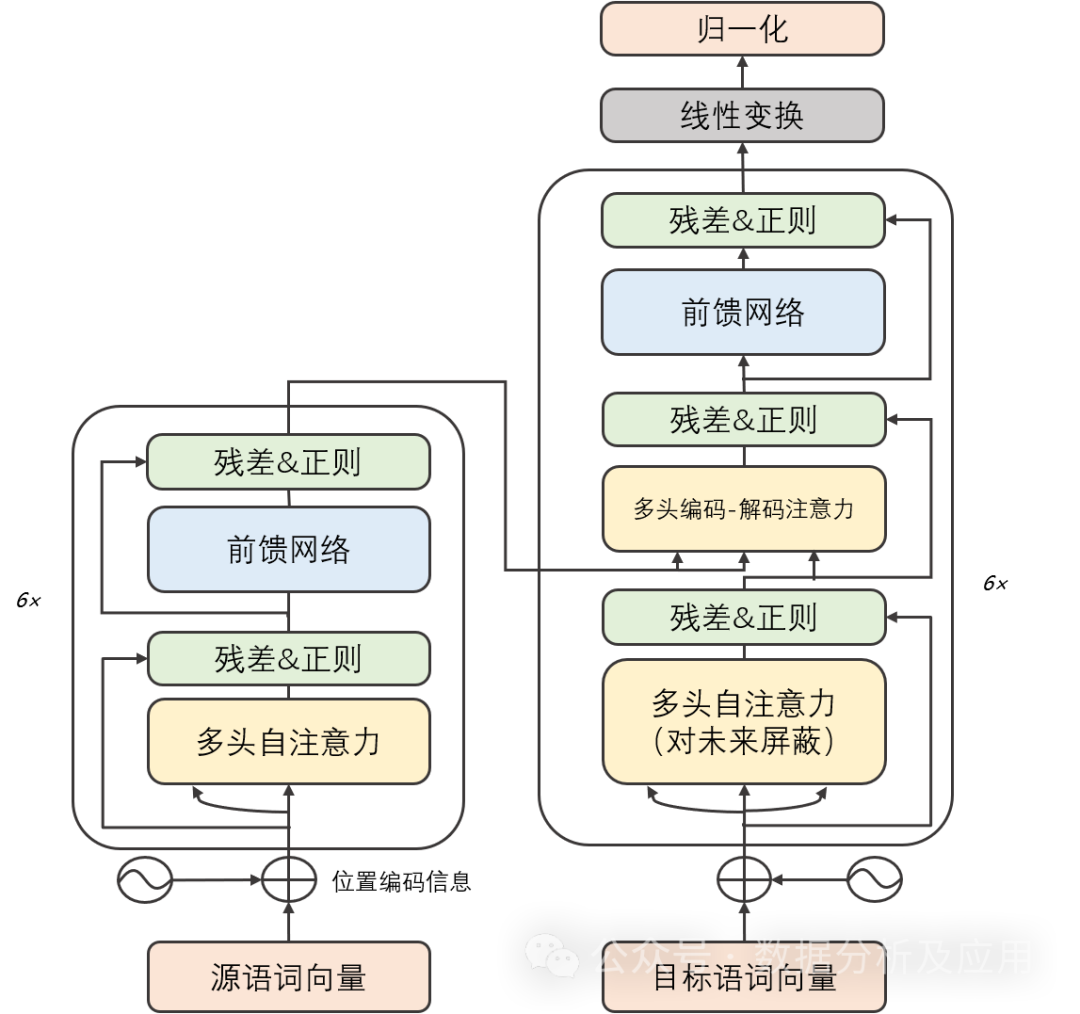
模型原理:
Transformer模型主要由兩部分組成:編碼器和解碼器。每個部分都由多個相同的“層”組成。每一層包含兩個子層:自注意力子層和線性前饋神經網絡子層。自注意力子層利用點積注意力機制計算輸入序列中每個位置的表示,而線性前饋神經網絡子層則將自注意力層的輸出作為輸入,并產生一個輸出表示。此外,編碼器和解碼器都包含一個位置編碼層,用于捕獲輸入序列中的位置信息。
模型訓練:
Transformer模型的訓練通常使用反向傳播算法和優化算法(如隨機梯度下降)。在訓練過程中,通過計算損失函數關于權重的梯度,并使用優化算法更新權重,以最小化損失函數。此外,為了加速訓練過程和提高模型的泛化能力,還可以采用正則化技術、集成學習等方法。
優點:
- 解決了梯度消失和模型退化問題:由于Transformer模型采用自注意力機制,它能夠更好地捕捉序列中的長期依賴關系,從而避免了梯度消失和模型退化的問題。
- 高效的并行計算能力:由于Transformer模型的計算是可并行的,因此在GPU上可以快速地進行訓練和推斷。
- 在多個任務上取得了優異的性能:由于其強大的特征學習和表示能力,Transformer模型在多個任務上取得了優異的性能,如機器翻譯、文本分類、語音識別等。
缺點:
- 計算量大:由于Transformer模型的計算是可并行的,因此需要大量的計算資源進行訓練和推斷。
- 對初始化權重敏感:Transformer模型對初始化權重的選擇敏感度高,如果初始化權重不合適,可能會導致訓練不穩定或過擬合問題。
- 無法學習長期依賴關系:盡管Transformer模型解決了梯度消失和模型退化問題,但在處理非常長的序列時仍然存在挑戰。
使用場景:
Transformer模型在自然語言處理領域有著廣泛的應用場景,如機器翻譯、文本分類、文本生成等。此外,Transformer模型還可以用于圖像識別、語音識別等領域。
Python示例代碼(簡化版):
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_heads, num_layers, dropout_rate=0.5):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.transformer = nn.Transformer(d_model=embedding_dim, nhead=num_heads, num_encoder_layers=num_layers, num_decoder_layers=num_layers, dropout=dropout_rate)
self.fc = nn.Linear(embedding_dim, vocab_size)
def forward(self, src, tgt):
embedded = self.embedding(src)
output = self.transformer(embedded)
output = self.fc(output)
return output
pip install transformers7、生成對抗網絡(GAN)
GAN的思想源于博弈論中的零和游戲,其中一個玩家試圖生成最逼真的假數據,而另一個玩家則嘗試區分真實數據與假數據。GAN由蒙提霍爾問題(一種生成模型與判別模型組合的問題)演變而來,但與蒙提霍爾問題不同,GAN不強調逼近某些概率分布或生成某種樣本,而是直接使用生成模型與判別模型進行對抗。
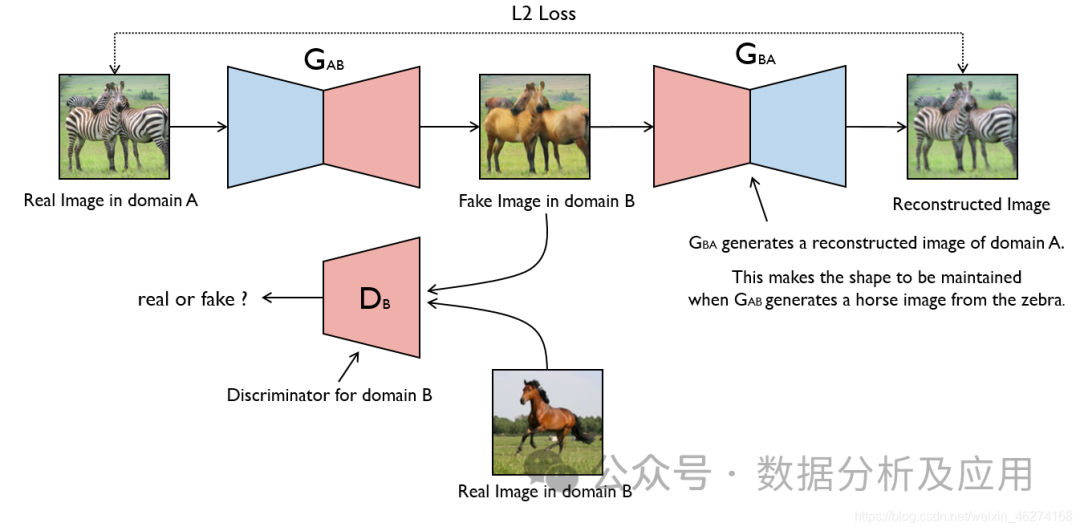
模型原理:
GAN由兩部分組成:生成器(Generator)和判別器(Discriminator)。生成器的任務是生成假數據,而判別器的任務是判斷輸入的數據是來自真實數據集還是生成器生成的假數據。在訓練過程中,生成器和判別器進行對抗,不斷調整參數,直到達到一個平衡狀態。此時,生成器生成的假數據足夠逼真,使得判別器無法區分真實數據與假數據。
模型訓練:
GAN的訓練過程是一個優化問題。在每個訓練步驟中,首先使用當前參數下的生成器生成假數據,然后使用判別器判斷這些數據是真實的還是生成的。接著,根據這個判斷結果更新判別器的參數。同時,為了防止判別器過擬合,還需要對生成器進行訓練,使得生成的假數據能夠欺騙判別器。這個過程反復進行,直到達到平衡狀態。
優點:
- 強大的生成能力:GAN能夠學習到數據的內在結構和分布,從而生成非常逼真的假數據。
- 無需顯式監督:GAN的訓練過程中不需要顯式的標簽信息,只需要真實數據即可。
- 靈活性高:GAN可以與其他模型結合使用,例如與自編碼器結合形成AutoGAN,或者與卷積神經網絡結合形成DCGAN等。
缺點:
- 訓練不穩定:GAN的訓練過程不穩定,容易陷入模式崩潰(mode collapse)的問題,即生成器只生成某一種樣本,導致判別器無法正確判斷。
- 難以調試:GAN的調試比較困難,因為生成器和判別器之間存在復雜的相互作用。
- 難以評估:由于GAN的生成能力很強,很難評估其生成的假數據的真實性和多樣性。
使用場景:
- 圖像生成:GAN最常用于圖像生成任務,可以生成各種風格的圖像,例如根據文字描述生成圖像、將一幅圖像轉換為另一風格等。
- 數據增強:GAN可以用于生成類似真實數據的假數據,用于擴充數據集或改進模型的泛化能力。
- 圖像修復:GAN可以用于修復圖像中的缺陷或去除圖像中的噪聲。
- 視頻生成:基于GAN的視頻生成是當前研究的熱點之一,可以生成各種風格的視頻。
簡單的Python示例代碼:
以下是一個簡單的GAN示例代碼,使用PyTorch實現:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定義生成器和判別器網絡結構
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 實例化生成器和判別器對象
input_dim = 100 # 輸入維度可根據實際需求調整
output_dim = 784 # 對于MNIST數據集,輸出維度為28*28=784
gen = Generator(input_dim, output_dim)
disc = Discriminator(output_dim)
# 定義損失函數和優化器
criterion = nn.BCELoss() # 二分類交叉熵損失函數適用于GAN的判別器部分和生成器的logistic損失部分。但是,通常更常見的選擇是采用二元交叉熵損失函數(binary cross8、Diffusion擴散模型
Diffusion模型是一種基于深度學習的生成模型,它主要用于生成連續數據,如圖像、音頻等。Diffusion模型的核心思想是通過逐步添加噪聲來將復雜數據分布轉化為簡單的高斯分布,然后再通過逐步去除噪聲來從簡單分布中生成數據。
模型原理
Diffusion模型包含兩個主要過程:前向擴散過程和反向擴散過程。
前向擴散過程:
- 從真實數據分布中采樣一個數據點(x_0)。
- 在(T)個時間步內,逐步向(x_0)中添加噪聲,生成一系列逐漸遠離真實數據分布的噪聲數據點(x_1, x_2, ..., x_T)。
- 這個過程可以看作是將數據分布逐漸轉化為高斯分布。
反向擴散過程(也稱為去噪過程):
- 從噪聲數據分布(x_T)開始,逐步去除噪聲,生成一系列逐漸接近真實數據分布的數據點(x_{T-1}, x_{T-2}, ..., x_0)。
- 這個過程是通過學習一個神經網絡來預測每一步的噪聲,并用這個預測來逐步去噪。
模型訓練
訓練Diffusion模型通常涉及以下步驟:
- 前向擴散:對訓練數據集中的每個樣本(x_0),按照預定的噪聲調度方案,生成對應的噪聲序列(x_1, x_2, ..., x_T)。
- 噪聲預測:對于每個時間步(t),訓練一個神經網絡來預測(x_t)中的噪聲。這個神經網絡通常是一個條件變分自編碼器(Conditional Variational Autoencoder, CVAE),它接收(x_t)和時間步(t)作為輸入,并輸出預測的噪聲。
- 優化:通過最小化真實噪聲和預測噪聲之間的差異來優化神經網絡參數。常用的損失函數是均方誤差(Mean Squared Error, MSE)。
優點
- 強大的生成能力:Diffusion模型能夠生成高質量、多樣化的數據樣本。
- 漸進式生成:模型可以在生成過程中提供中間結果,這有助于理解模型的生成過程。
- 穩定訓練:相較于其他一些生成模型(如GANs),Diffusion模型通常更容易訓練,并且不太容易出現模式崩潰(mode collapse)問題。
缺點
- 計算量大:由于需要在多個時間步上進行前向和反向擴散,Diffusion模型的訓練和生成過程通常比較耗時。
- 參數數量多:對于每個時間步,都需要一個單獨的神經網絡進行噪聲預測,這導致模型參數數量較多。
使用場景
Diffusion模型適用于需要生成連續數據的場景,如圖像生成、音頻生成、視頻生成等。此外,由于模型具有漸進式生成的特點,它還可以用于數據插值、風格遷移等任務。
Python示例代碼
下面是一個簡化的Diffusion模型訓練的示例代碼,使用了PyTorch庫:
import torch
import torch.nn as nn
import torch.optim as optim
# 假設我們有一個簡單的Diffusion模型
class DiffusionModel(nn.Module):
def __init__(self, input_dim, hidden_dim, num_timesteps):
super(DiffusionModel, self).__init__()
self.num_timesteps = num_timesteps
self.noises = nn.ModuleList([
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim)
] for _ in range(num_timesteps))
def forward(self, x, t):
noise_prediction = self.noises[t](x)
return noise_prediction
# 設置模型參數
input_dim = 784 # 假設輸入是28x28的灰度圖像
hidden_dim = 128
num_timesteps = 1000
# 初始化模型
model = DiffusionModel(input_dim, hidden_dim, num_timesteps)
# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)9.圖神經網絡(GNN)
圖神經網絡(Graph Neural Networks,簡稱GNN)是一種專門用于處理圖結構數據的深度學習模型。在現實世界中,許多復雜系統都可以用圖來表示,例如社交網絡、分子結構、交通網絡等。傳統的機器學習模型在處理這些圖結構數據時面臨諸多挑戰,而圖神經網絡則為這些問題的解決提供了新的思路。
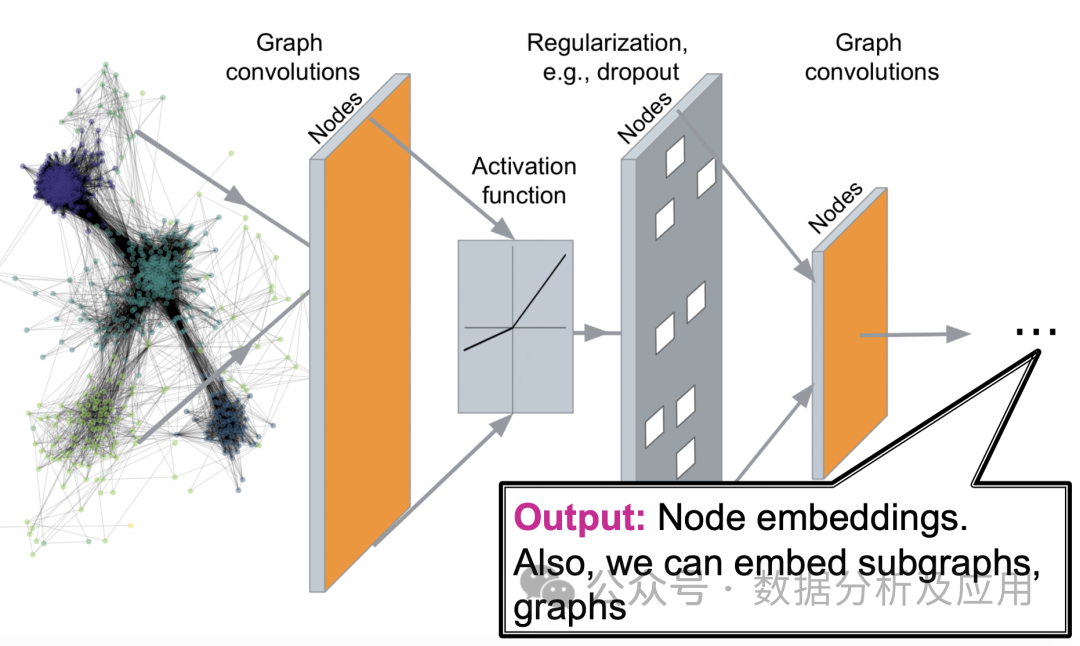
模型原理:
圖神經網絡的核心思想是通過神經網絡對圖中的節點進行特征表示學習,同時考慮節點間的關系。具體來說,GNN通過迭代地傳遞鄰居信息來更新節點的表示,使得相同的社區或相近的節點具有相近的表示。在每一層,節點會根據其鄰居節點的信息來更新自己的表示,從而捕捉到圖中的復雜模式。
模型訓練:
訓練圖神經網絡通常采用基于梯度的優化算法,如隨機梯度下降(SGD)。訓練過程中,通過反向傳播算法計算損失函數的梯度,并更新神經網絡的權重。常用的損失函數包括節點分類的交叉熵損失、鏈接預測的二元交叉熵損失等。
優點:
- 強大的表示能力:圖神經網絡能夠有效地捕捉圖結構中的復雜模式,從而在節點分類、鏈接預測等任務上取得較好的效果。
- 自然處理圖結構數據:圖神經網絡直接對圖結構數據進行處理,不需要將圖轉換為矩陣形式,從而避免了大規模稀疏矩陣帶來的計算和存儲開銷。
- 可擴展性強:圖神經網絡可以通過堆疊更多的層來捕獲更復雜的模式,具有很強的可擴展性。
缺點:
- 計算復雜度高:隨著圖中節點和邊的增多,圖神經網絡的計算復雜度也會急劇增加,這可能導致訓練時間較長。
- 參數調整困難:圖神經網絡的超參數較多,如鄰域大小、層數、學習率等,調整這些參數可能需要對任務有深入的理解。
- 對無向圖和有向圖的適應性不同:圖神經網絡最初是為無向圖設計的,對于有向圖的適應性可能較差。
使用場景:
- 社交網絡分析:在社交網絡中,用戶之間的關系可以用圖來表示。通過圖神經網絡可以分析用戶之間的相似性、社區發現、影響力傳播等問題。
- 分子結構預測:在化學領域,分子的結構可以用圖來表示。通過訓練圖神經網絡可以預測分子的性質、化學反應等。
- 推薦系統:推薦系統可以利用用戶的行為數據構建圖,然后使用圖神經網絡來捕捉用戶的行為模式,從而進行精準推薦。
- 知識圖譜:知識圖譜可以看作是一種特殊的圖結構數據,通過圖神經網絡可以對知識圖譜中的實體和關系進行深入分析。
簡單的Python示例代碼:
import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv
from torch_geometric.data import DataLoader
import time
# 加載Cora數據集
dataset = Planetoid(root='/tmp/Cora', name='Cora')
# 定義GNN模型
class GNN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super(GNN, self).__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, out_channels)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# 定義超參數和模型訓練過程
num_epochs = 1000
lr = 0.01
hidden_channels = 16
out_channels = dataset.num_classes
data = dataset[0] # 使用數據集中的第一個數據作為示例數據
model = GNN(dataset.num_features, hidden_channels, out_channels)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
data = DataLoader([data], batch_size=1) # 將數據集轉換為DataLoader對象,以支持批量訓練和評估
model.train() # 設置模型為訓練模式
for epoch in range(num_epochs):
for data in data: # 在每個epoch中遍歷整個數據集一次
optimizer.zero_grad() # 清零梯度
out = model(data) # 前向傳播,計算輸出和損失函數值
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask]) # 計算損失函數值,這里使用負對數似然損失函數作為示例損失函數
loss.backward() # 反向傳播,計算梯度
optimizer.step() # 更新權重參數10、深度Q網絡(DQN)
在傳統的強化學習算法中,智能體使用一個Q表來存儲狀態-動作值函數的估計。然而,這種方法在處理高維度狀態和動作空間時遇到限制。為了解決這個問題,DQN是種深度強化學習算法,引入了深度學習技術來學習狀態-動作值函數的逼近,從而能夠處理更復雜的問題。
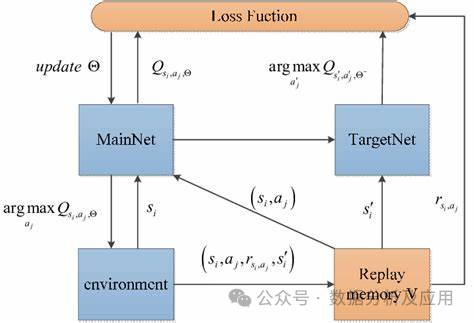
模型原理:
DQN使用一個神經網絡(稱為深度Q網絡)來逼近狀態-動作值函數。該神經網絡接受當前狀態作為輸入,并輸出每個動作的Q值。在訓練過程中,智能體通過不斷與環境交互來更新神經網絡的權重,以逐漸逼近最優的Q值函數。
模型訓練:
DQN的訓練過程包括兩個階段:離線階段和在線階段。在離線階段,智能體從經驗回放緩沖區中隨機采樣一批經驗(即狀態、動作、獎勵和下一個狀態),并使用這些經驗來更新深度Q網絡。在線階段,智能體使用當前的狀態和深度Q網絡來選擇和執行最佳的行動,并將新的經驗存儲在經驗回放緩沖區中。
優點:
- 處理高維度狀態和動作空間:DQN能夠處理具有高維度狀態和動作空間的復雜問題,這使得它在許多領域中具有廣泛的應用。
- 減少數據依賴性:通過使用經驗回放緩沖區,DQN可以在有限的樣本下進行有效的訓練。
- 靈活性:DQN可以與其他強化學習算法和技術結合使用,以進一步提高性能和擴展其應用范圍。
缺點:
- 不穩定訓練:在某些情況下,DQN的訓練可能會不穩定,導致學習過程失敗或性能下降。
- 探索策略:DQN需要一個有效的探索策略來探索環境并收集足夠的經驗。選擇合適的探索策略是關鍵,因為它可以影響學習速度和最終的性能。
- 對目標網絡的需求:為了穩定訓練,DQN通常需要使用目標網絡來更新Q值函數。這增加了算法的復雜性并需要額外的參數調整。
使用場景:
DQN已被廣泛應用于各種游戲AI任務,如圍棋、紙牌游戲等。此外,它還被應用于其他領域,如機器人控制、自然語言處理和自動駕駛等。
python
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
class DQN:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = np.zeros((MEM_CAPACITY, state_size * 2 + 2))
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.005
self.model = self.create_model()
def create_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory[self.memory_counter % MEM_CAPACITY, :] = [state, action, reward, next_state, done]
self.memory_counter += 1
def act(self, state):
if np.random.rand() <= self.epsilon:
return np.random.randint(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def replay(self):
batch_size = 32
start = np.random.randint(0, self.memory_counter - batch_size, batch_size)
sample = self.memory[start:start + batch_size]
states = np.array([s[0] for s in sample])
actions = np.array([s[1] for s in sample])
rewards = np.array([s[2] for s in sample])
next_states = np.array([s[3] for s in sample])
done = np.array([s[4] for s in sample])
target = self.model.predict(next_states)
target_q = rewards + (1 - done) * self.gamma * np.max(target, axis=1)
target_q = np.asarray([target_q[i] for i in range(batch_size)])
target = self.model.predict(states)
indices = np.arange(batch_size)
for i in range(batch_size):
if done[i]: continue # no GAE calc for terminal states (if you want to include terminal states see line 84)
target[indices[i]] = rewards[i] + self.gamma * target_q[indices[i]] # GAE formula line 84 (https://arxiv.org/pdf/1506.02438v5) instead of line 85 (https://arxiv.org/pdf/1506.02438v5) (if you want to include terminal states see line 84)
indices[i] += batch_size # resets the indices for the next iteration (https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail/blob/master/a2c.py#L173) (if you want to include terminal states see line 84)
target[indices[i]] = target[indices[i]] # resets the indices for the next iteration (https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail/blob/master/a2c.py#L173) (if you want to include terminal states see line 84) (https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail/blob/master/a2c.py#L173)