













自動駕駛與軌跡預測看這一篇就夠了!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指通過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模塊,軌跡預測的質量對于下游的規劃控制至關重要。軌跡預測任務技術棧豐富,需要熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網絡架構(CNN&GNN&Transformer)技能等,入門難度很大!很多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!
入門相關知識
1.預習的論文有沒有切入順序?
A:先看survey,problem formulation, deep learning-based methods里的sequential network,graph neural network和Evaluation。
2.行為預測是軌跡預測嗎
A:是耦合的,但不一樣。行為一般指目標車未來會采取什么動作,變道停車超車加速左右轉直行等等。軌跡的話就是具體的具有時間信息的未來可能的位置點
3.請問Argoverse數據集里提到的數據組成中,labels and targets指的是什么呢?labels是指要預測時間段內的ground truth嗎
A:我猜這里想說的是右邊表格里的OBJECT_TYPE那一列。AV代表自動駕駛車自己,然后數據集往往會給每個場景指定一個或多個待預測的障礙物,一般會叫這些待預測的目標為target或者focal agent。某些數據集還會給出每個障礙物的語義標簽,比如是車輛、行人還是自行車等。
Q2:車輛和行人的數據形式是一樣的嗎?我的意思是說,比如一個點云點代表行人,幾十個點代表車輛?
A:這種軌跡數據集里面其實給的都是物體中心點的xyz坐標,行人和車輛都是
Q3:argo1和argo2的數據集都是只指定了一個被預測的障礙物吧?那在做multi-agent prediction的時候 這兩個數據集是怎么用的
A:argo1是只指定了一個,argo2其實指定了多個,最多可能有二十來個的樣子。但是只指定一個并不妨礙你自己的模型預測多個障礙物。
4.路徑規劃一般考慮低速和靜態障礙物 軌跡預測結合的作用是??關鍵snapshot?
A:”預測“自車軌跡當成自車規劃軌跡,可以參考uniad
5.軌跡預測對于車輛動力學模型的要求高嗎?就是需要數學和汽車理論等來建立一個精準的車輛動力學模型么?
A:nn網絡基本不需要哈,rule based的需要懂一些
6. 模模糊糊的新手小白,應該從哪里在著手拓寬一下知識面(還不會代碼撰寫)
A:先看綜述,把思維導圖整理出來,例如《Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions》這篇綜述去看看英文原文
7.預測和決策啥關系捏,為啥我覺得好像預測沒那么重要?
A1(stu): 默認預測屬于感知吧,或者決策中隱含預測,反正沒有預測不行。
A2(stu): 決策該規控做,有行為規劃,高級一點的就是做交互和博弈,有的公司會有單獨的交互博弈組8.目前頭部公司,一般預測是屬于感知大模塊還是規控大模塊?
A:預測是出他車軌跡,規控是出自車軌跡,這倆軌跡還互相影響,所以預測一般放規控。
Q: 一些公開的資料,比如小鵬的感知xnet會同時出預測軌跡,這時候又感覺預測的工作是放在感知大模塊下,還是說兩個模塊都有自己的預測模塊,目標不一樣?
A:是會相互影響,所以有的地方預測和決策就是一個組。比如自車規劃的軌跡意圖去擠別的車,他車一般情況是會讓道的。所以有些工作會把自車的規劃當成他車模型輸入的一部分。可以參考下M2I(M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction). 這篇思路差不多,可以了解 PiP: Planning-informed Trajectory Prediction for Autonomous Driving
9.argoverse的這種車道中線地圖,在路口里面沒有車道線的地方是怎么得到的呀?
A: 人工標注的
10.用軌跡預測寫論文的話,哪篇論文的代碼可以做baseline?
A: hivt可以做baseline,蠻多人用的
11.現在軌跡預測基本都依賴地圖,如果換一個新的地圖環境,原模型是否就不適用了,要重新訓練嗎?
A: 有一定的泛化能力,不需要重新訓練效果也還行
12.對多模態輸出而言,選擇最佳軌跡的時候是根據概率值最大的選嗎
A(stu): 選擇結果最好的
Q2:結果最好是根據什么來判定呢?是根據概率值大小還是根據和gt的距離
A: 實際在沒有ground truth的情況下,你要取“最好”的軌跡,那只能選擇相信預測概率值最大的那條軌跡了
Q3: 那有gt的情況下,選擇最好軌跡的時候,根據和gt之間的end point或者average都可以是嗎
A: 嗯嗯,看指標咋定義軌跡預測基礎模塊
1.Argoverse數據集里HD-Map怎么用,能結合motion forecast作為輸入,構建駕駛場景圖嗎,異構圖又怎么理解?
A:這個課程里都有講的,可以參照第二章,后續的第四章也會講. 異構圖和同構圖的區別:同構圖中,node的種類只有一種,一個node和另一個node的連接關系只有一種,例如在社交網絡中,可以想象node只有‘人’這一個種類,edge只有‘認識’這一種連接。而人和人要么認識,要么不認識。但是也可能細分有人,點贊,推文。則人和人可能通過認識連接,人和推文可能通過點贊連接,人和人也可能通過點贊同一篇推文連接(meta path)。這里節點、節點之間關系的多樣性表達就需要引入異構圖了。異構圖中,有很多種node。node之間也有很多種連接關系(edge),這些連接關系的組合則種類更多(meta-path), 而這些node之間的關系有輕重之分,不同連接關系也有輕重之分。
2.A-A交互考慮的是哪些車輛與被預測車輛的交互呢?
A:可以選擇一定半徑范圍內的車,也可以考慮K近鄰的車,你甚至可以自己提出更高級的啟發式鄰居篩選策略,甚至有可能可以讓模型自己學出來兩個車是否是鄰居
Q2:還是考慮一定范圍內的吧,那半徑大小有什么選取的原則嗎?另外,選取的這些車輛是在哪個時間步下的呢
A:半徑的選擇很難有標準答案,這本質上就是在問模型做預測的時候到底需要多遠程的信息,有點像在選擇卷積核的大小對于第二個問題,我個人的準則是,想要建模哪個時刻下物體之間的交互,就根據哪個時刻下的物體相對位置來選取鄰居
Q3:這樣的話對于歷史時域都要建模嗎?不同時間步下在一定范圍內的周邊車輛也會變化吧,還是說只考慮在當前時刻的周邊車輛信息
A:都行啊,看你模型怎么設計
3.老師uniad端到端模型中預測部分存在什么缺陷啊?
A:只看它motion former的操作比較常規,你在很多論文里都會看到類似的SA和CA。現在sota的模型很多都比較重,比如decoder會有循環的refine
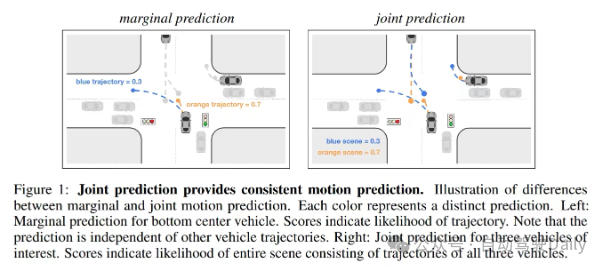
A2:做的是marginal prediction不是joint prediction;2. prediction和planning是分開來做的,沒有顯式考慮ego和周圍agent的交互博弈;3.用的是scene-centric representation,沒有考慮對稱性,效果必拉
Q2:啥是marginal prediction啊
A:具體可以參考scene transformer
Q3:關于第三點,scene centric沒有考慮對稱性,怎么理解呢
A:建議看HiVT, QCNet, MTR++.當然對于端到端模型來說對稱性的設計也不好做就是了
A2:可以理解成輸入的是scene的數據,但在網絡里會建模成以每個目標為中心視角去看它周邊的scene,這樣你就在forward里得到了每個目標以它自己為中心的編碼,后續可以再考慮這些編碼間的交互
4. 什么是以agent為中心?
A:每個agent有自己的local region,local region是以這個agent為中心
5.軌跡預測里yaw和heading是混用的嗎
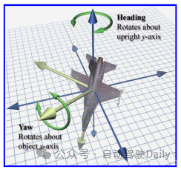
A:可以理解為車頭朝向
6.argoverse地圖中的has_traffic_control這個屬性具體代表什么意思?
A:其實我也不知道我理解的對不對,我猜是指某個lane是否被紅綠燈/stop sign/限速標志等所影響
7. 請問Laplace loss和huber loss 對于軌跡預測而言所存在的優劣勢在哪里呢?如果我只預測一條車道線的話
A:兩個都試一下,哪個效果好哪個就有優勢。Laplace loss要效果好還是有些細節要注意的
Q2:是指參數要調的好嗎
A:Laplace loss相比L1 loss其實就是多預測了一個scale參數
Q3:對的 但似乎這個我不知道有啥用 如果只預測一個軌跡的話。感覺像是多余的。我把它理解為不確定性 不知道是否正確
A:如果你從零推導過最小二乘法就會知道,MSE其實是假設了方差為常數的高斯分布的NLL。同理,L1 loss也是假設了方差為常數的Laplace分布的NLL。所以說LaplaceNLL也可以理解為方差非定值的L1 loss。這個方差是模型自己預測出來的。為了使loss更低,模型會給那些擬合得不太好的樣本一個比較大的方差,而給擬合得好的樣本比較小的方差
Q4:那是不是可以理解為對于非常隨機的數據集【軌跡數據存在缺幀 抖動】 就不太適合Laplace 因為模型需要去擬合這個方差?需要數據集質量比較高
A:這個說法我覺得不一定成立。從效果上來看,會鼓勵模型優先學習比較容易擬合的樣本,再去學習難學習的樣本
Q5:還想請問下這句話(Laplace loss要效果好還是有些細節要注意的)如何理解 A:主要是預測scale那里。在模型上,預測location的分支和預測scale的分支要盡量解耦,不要讓他們相互干擾。預測scale的分支要保證輸出結果>0,一般人會用exp作為激活函數保證非負,但是我發現用ELU +1會更好。然后其實scale的下界最好不要是0,最好讓scale>0.01或者>0.1啥的。以上都是個人看法。其實我開源的代碼(周梓康大佬的github開源代碼)里都有這些細節,不過可能大家不一定注意到。
給出鏈接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做軌跡預測的嗎,給個鏈接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 請問大伙一個問題,就是Polyline到底是啥?另外說polyline由向量Vector組成,這些Vector是相當于節點嗎?
A:Polyline就是折線,折線就是一段一段的,每一段都可以看成是一段向量
Q2:請問這個折線段和圖神經網絡的節點之間的邊有關系嗎?或者說Polyline這個折現向量相當于是圖神經網絡當中的節點還是邊呀?
A:一根折線可以理解為一個節點。軌跡預測里面沒有明確定義的邊,邊如何定義取決于你怎么理解這個問題。
Q3: VectorNet里面有很多個子圖,每個子圖下面有很多個Polyline,把Polyline當做向量的話,就相當于把Polyline這個節點變成了向量,相當于將節點進行特征向量化對嗎?然后Polyline里面有多個Vector向量,就是相當于是構成這個節點的特征矩陣么?
A: 一個地圖里有很多條polyline;一個Polyline就是一個子圖;一個polyline由很多段比較短的向量組成,每一段向量都是子圖上的一個節點10. 有的論文,像multipath++對于地圖兩個點就作為一個單元,有的像vectornet是一條線作為一個單元,這兩種有什么區別嗎?
A: 節點的粒度不同,要說效果的話那得看具體實現;速度的話,顯然粒度越粗效率越高
Q2:從效果角度看,什么時候選用哪種有沒有什么原則?
A: 沒有原則,都可以嘗試11.有什么可以判斷score的平滑性嗎? 如果一定要做的話
A: 這個需要你輸入是流動的輸入比如0-19和1-20幀然后比較兩幀之間的對應軌跡的score的差的平方,統計下就可以了
Q2: Thomas老師有哪些指標推薦呢,我目前用一階導數和二階導數。但好像不是很明顯,絕大多數一階導和二階導都集中在0附近。
A: 我感覺連續幀的對應軌跡的score的差值平方就可以了呀,比如你有連續n個輸入,求和再除以n。但是scene是實時變化的,發生交互或者從非路口到路口的時候score就應該是突變的
12.hivt里的軌跡沒有進行縮放嗎,就比如×0.01+10這種。分布盡可能在0附近。我看有的方法就就用了,有的方法就沒有。取舍該如何界定?
A:就是把數據標準化歸一化唄。可能有點用 但應該不多
13.HiVT里地圖的類別屬性經過embedding之后為什么和數值屬性是相加的,而不是concat?
A:相加和concat區別不大,而對于類別embedding和數值embedding融合來說,實際上完全等價
Q2: 完全等價應該怎么理解?
A: 兩者Concat之后再過一層線性層,實際上等價于把數值embedding過一層線性層以及把類別embedding過一層線性層后,兩者再相加起來.把類別embedding過一層線性層其實沒啥意義,理論上這一層線性層可以跟nn.Embeddding里面的參數融合起來
14.作為用戶可能更關心的是,HiVT如果要實際部署的話,最小的硬件要求是多少?
A:我不知道,但根據我了解到的信息,不知道是NV還是哪家車廠是拿HiVT來預測行人的,所以實際部署肯定是可行的
15. 基于occupancy network的預測有什么特別嗎?有沒有論文推薦?
A:目前基于occupancy的未來預測的方案里面最有前途的應該是這個:https://arxiv.org/abs/2308.01471
16.考慮規劃軌跡的預測有什么論文推薦嗎?就是預測其他障礙物的時候,考慮自車的規劃軌跡?
A:這個可能公開的數據集比較困難,一般不會提供自車的規劃軌跡。上古時期有一篇叫做PiP的,港科Haoran Song。我感覺那種做conditional prediction的文章都可以算是你想要的,比如M2I
17.有沒有適合預測算法進行性能測試的仿真項目可以學習參考的呢
A(stu):這個論文有討論:Choose Your Simulator Wisely A Review on Open-source Simulators for Autonomous Driving
18.請問如何估計GPU顯存需要多大,如果使用Argoverse數據集的話,怎么算
A:和怎么用有關系,之前跑hivt我1070都可以,現在一般電腦應該都可以
原文鏈接:https://mp.weixin.qq.com/s/EEkr8g4w0s2zhS_jmczUiA























