RoSA:一種新的大模型參數(shù)高效微調(diào)方法
隨著語言模型不斷擴展到前所未有的規(guī)模,對下游任務(wù)的所有參數(shù)進(jìn)行微調(diào)變得非常昂貴,PEFT方法已成為自然語言處理領(lǐng)域的研究熱點。PEFT方法將微調(diào)限制在一小部分參數(shù)中,以很小的計算成本實現(xiàn)自然語言理解任務(wù)的最先進(jìn)性能。
RoSA是一種新的PEFT技術(shù)。在一組基準(zhǔn)測試的實驗中,RoSA在使用相同參數(shù)預(yù)算的情況下優(yōu)于先前的低秩自適應(yīng)(Low-Rank Adaptation, LoRA)和純稀疏微調(diào)方法。
本文我們將深入探討RoSA原理、方法和結(jié)果。并解釋為什么它的性能標(biāo)志著有意義的進(jìn)步。對于那些希望有效地微調(diào)大型語言模型的人來說,RoSA提供了一種新的解決方案,該解決方案優(yōu)于以前的方案。
對參數(shù)高效微調(diào)的需求
NLP已經(jīng)被一系列越來越大的基于transformer的語言模型(如GPT-4)所徹底改變,通過對大量文本語料庫進(jìn)行預(yù)訓(xùn)練,這些模型學(xué)習(xí)強大的語言表征,并通過一個簡單的過程轉(zhuǎn)移到下游的語言任務(wù)。
隨著模型規(guī)模從數(shù)十億個參數(shù)增長到萬億個參數(shù),微調(diào)帶來了不可持續(xù)的計算負(fù)擔(dān)。微調(diào)GPT-4 1.76萬億參數(shù)可能會花費數(shù)百萬美元的費用。這使實際應(yīng)用中的部署在很大程度上不切實際。
參數(shù)高效微調(diào)(PEFT)方法通過將微調(diào)限制為每個任務(wù)的一小部分參數(shù)來解決這個問題。在最近的文獻(xiàn)中提出了一系列PEFT技術(shù),在效率和準(zhǔn)確性之間做出了不同的權(quán)衡。
LoRA
一個突出的PEFT方法是低秩適應(yīng)(LoRA)。LoRA是由Meta和麻省理工學(xué)院的研究人員于2021年推出的,其動機是觀察到transformer在其頭部矩陣中表現(xiàn)出低秩結(jié)構(gòu)。
LoRA只對每個變壓器頭的前k個奇異向量對進(jìn)行微調(diào),保持所有其他參數(shù)不變。這只需要調(diào)優(yōu)O(k)個額外參數(shù),而對所有n個參數(shù)進(jìn)行全面微調(diào)則需要O(n)個。
通過利用這種低秩結(jié)構(gòu),LoRA可以捕獲下游任務(wù)泛化所需的有意義的信號,并將微調(diào)限制在這些頂級奇異向量上,使優(yōu)化和推理更加有效。
實驗表明,LoRA在GLUE基準(zhǔn)測試中可以匹配完全微調(diào)的性能,同時使用的參數(shù)減少了100倍以上。但是隨著模型規(guī)模的不斷擴大,通過LoRA獲得強大的性能需要增加rank k,與完全微調(diào)相比減少了計算節(jié)省。
在RoSA之前,LoRA代表了PEFT方法中最先進(jìn)的技術(shù),只是使用不同的矩陣分解或添加少量額外的微調(diào)參數(shù)等技術(shù)進(jìn)行了適度的改進(jìn)。
Robust Adaptation (RoSA)
Robust Adaptation(RoSA)引入了一種新的參數(shù)高效微調(diào)方法。RoSA的靈感來自于穩(wěn)健的主成分分析(robust PCA),而不是僅僅依賴于低秩結(jié)構(gòu)。
在傳統(tǒng)的主成分分析中,數(shù)據(jù)矩陣X被分解為X≈L + S,其中L是一個近似主成分的低秩矩陣,S是一個捕獲殘差的稀疏矩陣。robust PCA更進(jìn)一步,將X分解為干凈的低秩L和“污染/損壞”的稀疏S。
RoSA從中汲取靈感,將語言模型的微調(diào)分解為:
- 一個類似于LoRA的低秩自適應(yīng)(L)矩陣,經(jīng)過微調(diào)以近似于主導(dǎo)任務(wù)相關(guān)信號
- 一個高度稀疏的微調(diào)(S)矩陣,包含非常少量的大的、選擇性微調(diào)的參數(shù),這些參數(shù)編碼L錯過的殘差信號。
顯式地建模殘差稀疏分量可以使RoSA比單獨的LoRA達(dá)到更高的精度。
RoSA通過對模型的頭部矩陣進(jìn)行低秩分解來構(gòu)建L。這將編碼對下游任務(wù)有用的底層語義表示。然后RoSA選擇性地將每層最重要的前m個參數(shù)微調(diào)為S,而所有其他參數(shù)保持不變。這個步驟會捕獲不適合低秩擬合的殘差信號。
微調(diào)參數(shù)的數(shù)量m比LoRA單獨所需的rank k要小一個數(shù)量級。因此結(jié)合L中的低秩頭矩陣,RoSA保持了極高的參數(shù)效率。
RoSA還采用了一些其他簡單但有效果的優(yōu)化:
- 殘差稀疏連接:在每個transformer塊的輸出經(jīng)過層歸一化和前饋子層之前,直接向其添加S個殘差。這可以模擬L錯過的信號。
- 獨立稀疏掩碼:S中選擇的用于微調(diào)的指標(biāo)是為每個transformer層獨立生成的。
- 共享低秩結(jié)構(gòu):在L的所有層之間共享相同的低秩基U,V矩陣,就像在LoRA中一樣。這將捕獲一致子空間中的語義概念。
這些架構(gòu)選擇為RoSA建模提供了類似于完全微調(diào)的靈活性,同時保持了優(yōu)化和推理的參數(shù)效率。利用這種結(jié)合魯棒低秩自適應(yīng)和高度稀疏殘差的PEFT方法,RoSA實現(xiàn)了精度效率折衷的新技術(shù)。
實驗與結(jié)果
研究人員在12個NLU數(shù)據(jù)集的綜合基準(zhǔn)上對RoSA進(jìn)行了評估,這些數(shù)據(jù)集涵蓋了文本檢測、情感分析、自然語言推理和魯棒性測試等任務(wù)。他們使用基于人工智能助理LLM的RoSA進(jìn)行了實驗,使用了120億個參數(shù)模型。
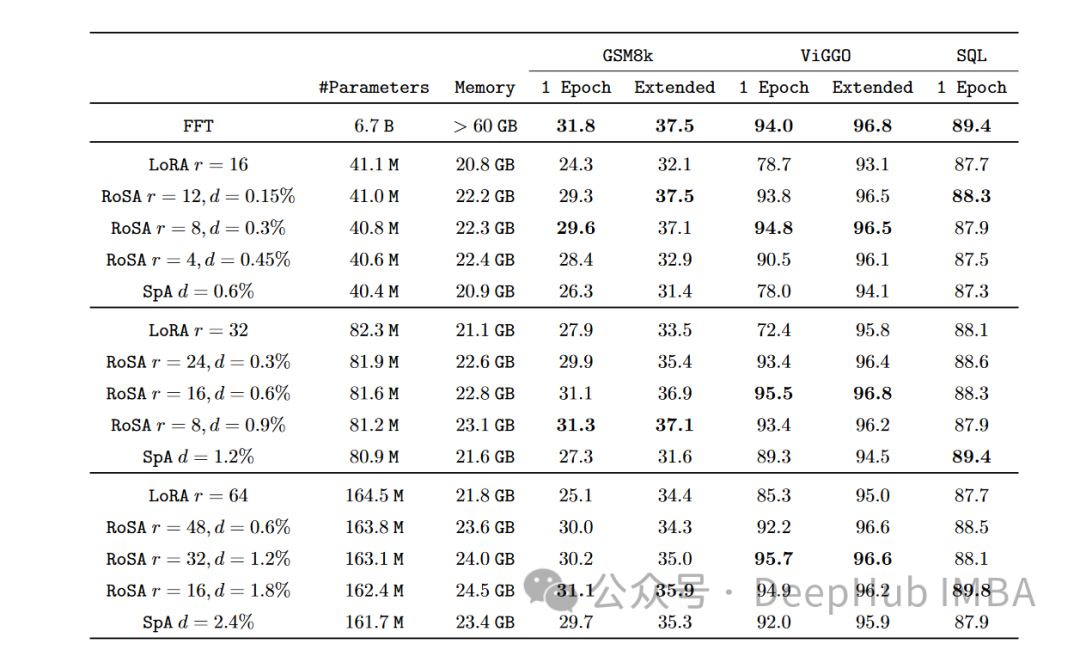
在每個任務(wù)上,在使用相同的參數(shù)時,RoSA的性能都明顯優(yōu)于LoRA。兩種方法的總參數(shù)都差不多為整個模型的0.3%左右。這意味著LoRA的k = 16, RoSA的m =5120這兩種情況下都有大約450萬個微調(diào)參數(shù)。
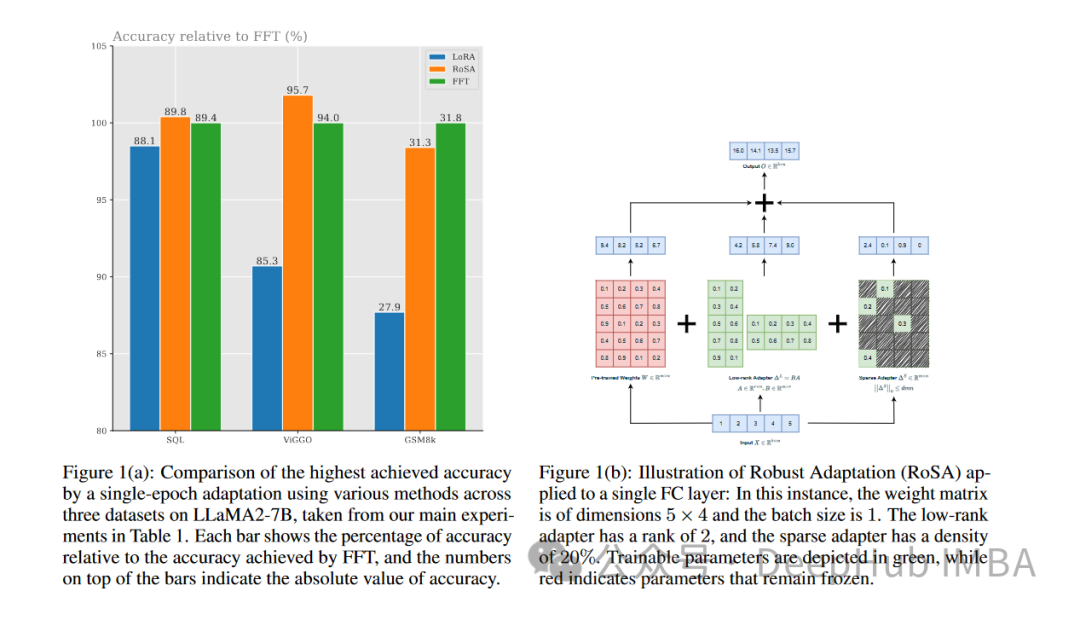
RoSA還匹配或超過了純稀疏微調(diào)基線的性能。
在評估對對抗示例的魯棒性的ANLI基準(zhǔn)上,RoSA的得分為55.6,而LoRA的得分為52.7。這表明了泛化和校準(zhǔn)的改進(jìn)。
對于情感分析任務(wù)SST-2和IMDB, RoSA的準(zhǔn)確率達(dá)到91.2%和96.9%,而LoRA的準(zhǔn)確率為90.1%和95.3%。
在WIC(一項具有挑戰(zhàn)性的詞義消歧測試)上,RoSA的F1得分為93.5,而LoRA的F1得分為91.7。
在所有12個數(shù)據(jù)集中,RoSA在匹配的參數(shù)預(yù)算下普遍表現(xiàn)出比LoRA更好的性能。
值得注意的是,RoSA能夠在不需要任何特定于任務(wù)的調(diào)優(yōu)或?qū)iT化的情況下實現(xiàn)這些增益。這使得RoSA適合作為通用的PEFT解決方案使用。
總結(jié)
隨著語言模型規(guī)模的持續(xù)快速增長,減少對其微調(diào)的計算需求是一個迫切需要解決的問題。像LoRA這樣的參數(shù)高效自適應(yīng)訓(xùn)練技術(shù)已經(jīng)顯示出初步的成功,但面臨低秩近似的內(nèi)在局限性。
RoSA將魯棒低秩分解和殘差高度稀疏微調(diào)有機地結(jié)合在一起,提供了一個令人信服的新解決方案。通過考慮通過選擇性稀疏殘差逃避低秩擬合的信號,它大大提高了PEFT的性能。經(jīng)驗評估表明,在不同的NLU任務(wù)集上,LoRA和不受控制的稀疏性基線有了明顯的改進(jìn)。
RoSA在概念上簡單但高性能,能進(jìn)一步推進(jìn)參數(shù)效率、適應(yīng)性表征和持續(xù)學(xué)習(xí)的交叉研究,以擴大語言智能。