













走在GPT 4.5前面?3D、視頻直接扔進(jìn)對(duì)話框,大模型掌握跨模態(tài)推理
給你一首曲子的音頻和一件樂(lè)器的 3D 模型,然后問(wèn)你這件樂(lè)器能否演奏出這首曲子。你可以通過(guò)聽(tīng)覺(jué)來(lái)辨認(rèn)這首曲子的音色,看它是鋼琴曲還是小提琴曲又或是來(lái)自吉他;同時(shí)用視覺(jué)識(shí)別那是件什么樂(lè)器。然后你就能得到問(wèn)題的答案。但語(yǔ)言模型有能力辦到這一點(diǎn)嗎?

實(shí)際上,這個(gè)任務(wù)所需的能力名為跨模態(tài)推理,也是當(dāng)今多模態(tài)大模型研究熱潮中一個(gè)重要的研究主題。近日,賓夕法尼亞大學(xué)、Salesforce 研究院和斯坦福大學(xué)的一個(gè)研究團(tuán)隊(duì)給出了一個(gè)解決方案 X-InstructBLIP,能以較低的成本讓語(yǔ)言模型掌握跨模態(tài)推理。
人類天生就會(huì)利用多種感官來(lái)解讀周圍環(huán)境并和制定決策。通過(guò)讓人工智能體具備跨模態(tài)推理能力,我們可以促進(jìn)系統(tǒng)的開(kāi)發(fā),讓其能更全面地理解環(huán)境,從而能應(yīng)對(duì)僅有單個(gè)模態(tài)導(dǎo)致難以辨別模式和執(zhí)行推理的情況。這就催生了多模態(tài)語(yǔ)言模型(MLM),其可將大型語(yǔ)言模型(LLM)的出色能力遷移到靜態(tài)視覺(jué)領(lǐng)域。
近期一些研究進(jìn)展的目標(biāo)是通過(guò)整合音頻和視頻來(lái)擴(kuò)展 MLM 的推理能力,其用的方法要么是引入預(yù)訓(xùn)練的跨模態(tài)表征來(lái)在多個(gè)模態(tài)上訓(xùn)練基礎(chǔ)模型,要么是訓(xùn)練一個(gè)投影模型來(lái)將多模態(tài)與 LLM 的表征空間對(duì)齊。這些方法雖然有效,但前者往往需要針對(duì)具體任務(wù)進(jìn)行微調(diào),而后者則需要在聯(lián)合模態(tài)數(shù)據(jù)上微調(diào)模型,這樣一來(lái)就需要很多數(shù)據(jù)收集和計(jì)算資源成本。
該研究團(tuán)隊(duì)提出的 X-InstructBLIP 是一個(gè)可擴(kuò)展框架,讓模型可以在學(xué)習(xí)單模態(tài)數(shù)據(jù)的同時(shí)不受預(yù)訓(xùn)練的跨模態(tài)嵌入空間或與解凍 LLM 參數(shù)相關(guān)的計(jì)算成本和潛在過(guò)擬合風(fēng)險(xiǎn)的限制。

- 論文地址:https://arxiv.org/pdf/2311.18799.pdf
- GitHub 地址:https://github.com/salesforce/LAVIS/
X-InstructBLIP 無(wú)縫地整合了多種模態(tài)并且這些模態(tài)各自獨(dú)立,從而不必再使用聯(lián)合模態(tài)數(shù)據(jù)集,同時(shí)還能保留執(zhí)行跨模態(tài)任務(wù)的能力。
據(jù)介紹,這種方法使用了 Q-Former 模塊,使用來(lái)自 BLIP-2 的圖像 - 文本預(yù)訓(xùn)練權(quán)重進(jìn)行了初始化,并在單模態(tài)數(shù)據(jù)集上進(jìn)行了微調(diào)以將來(lái)自不同模態(tài)嵌入空間的輸入映射到一個(gè)凍結(jié)的 LLM。
由于某些模態(tài)缺乏指令微調(diào)數(shù)據(jù),該團(tuán)隊(duì)又提出了一個(gè)簡(jiǎn)單又有效的方法:一種三階段查詢數(shù)據(jù)增強(qiáng)技術(shù),能使用開(kāi)源 LLM 來(lái)從字幕描述數(shù)據(jù)集提取指令微調(diào)數(shù)據(jù)。
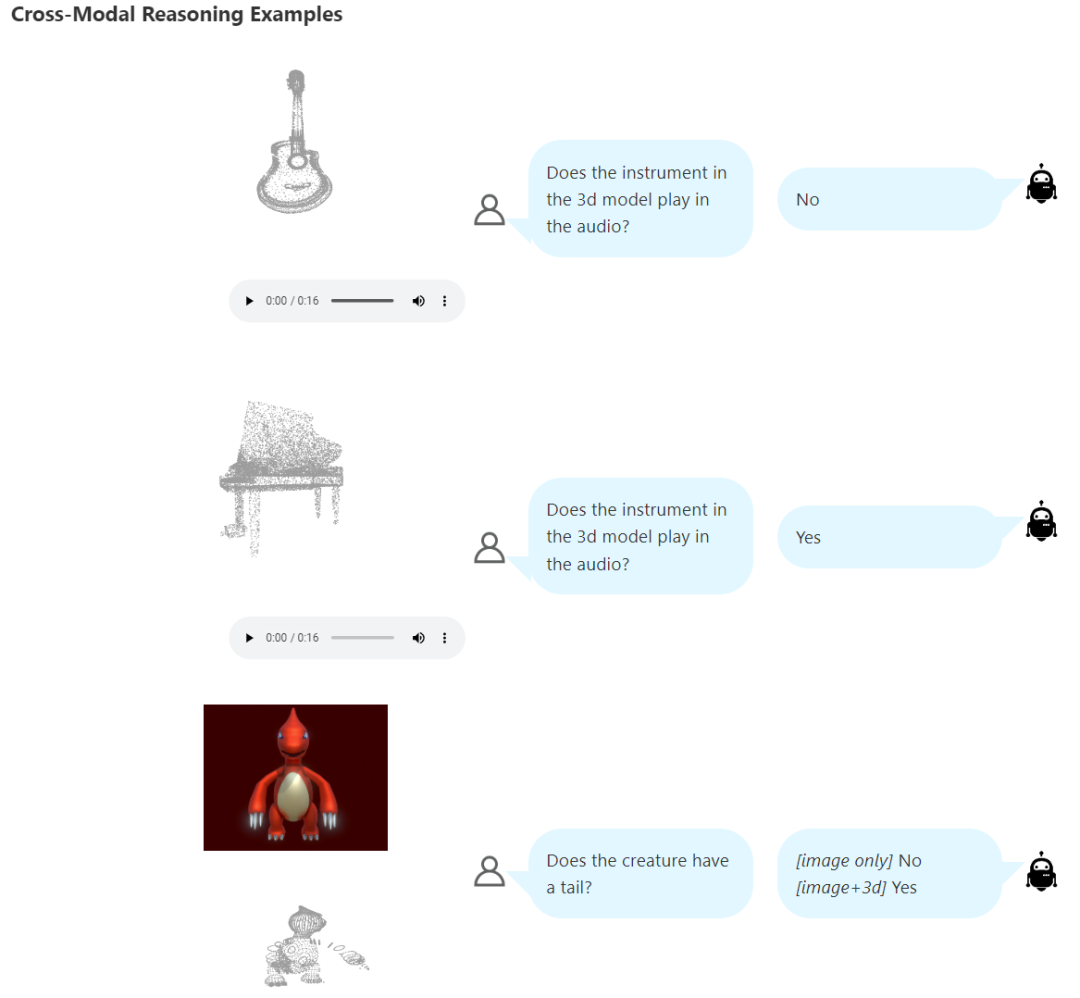
圖 2 給出的結(jié)果凸顯了這個(gè)框架的多功能性。定量分析表明,X-InstructBLIP 的表現(xiàn)與現(xiàn)有的單模態(tài)模型相當(dāng),并且能在跨模態(tài)任務(wù)上表現(xiàn)出涌現(xiàn)能力。而為了量化和檢驗(yàn)這種涌現(xiàn)能力,該團(tuán)隊(duì)又構(gòu)建了 DisCRn。這是一個(gè)自動(dòng)收集和調(diào)整的判別式跨模態(tài)推理挑戰(zhàn)數(shù)據(jù)集,其需要模型分辨不同的模態(tài)組合,比如「音頻 - 視頻」和「3D - 圖像」。

方法
圖 1 展示了該模型架構(gòu)的總體概況:其擴(kuò)展了 Dai et al. 在 InstructBLIP 項(xiàng)目中提出的指令感知型投影方法,通過(guò)獨(dú)立微調(diào)具體模態(tài)的 Q-Former 到一個(gè)凍結(jié) LLM 的映射,使其可用于任意數(shù)量的模態(tài)。

圖 3 展示了這個(gè)模態(tài)到 LLM 的對(duì)齊過(guò)程,其中突出強(qiáng)調(diào)了與每個(gè)模態(tài)相關(guān)的所有組件。

算法 1 概述了 X-InstructBLIP 對(duì)齊框架。

本質(zhì)上講,對(duì)于每一對(duì)文本指令和非語(yǔ)言輸入樣本:(1) 使用一個(gè)凍結(jié)的預(yù)訓(xùn)練編碼器對(duì)文本指令進(jìn)行 token 化,對(duì)非文本輸入進(jìn)行嵌入化。(2) 將非語(yǔ)言輸入的歸一化編碼和 token 化的指令輸入 Q-Former 模塊,并附帶上一組可學(xué)習(xí)的查詢嵌入。(3) 通過(guò) Q-Former 對(duì)這些查詢嵌入進(jìn)行變換,通過(guò) transformer 模塊的交替層中的跨注意力層來(lái)?xiàng)l件式地適應(yīng)這些輸入。(4) 通過(guò)一個(gè)可訓(xùn)練的線性層將修改后的查詢嵌入投影到凍結(jié) LLM 的嵌入空間。
數(shù)據(jù)集
X-InstructBLIP 的優(yōu)化和評(píng)估使用了之前已有的數(shù)據(jù)集和自動(dòng)生成的數(shù)據(jù)集,如圖 4 所示。

對(duì)數(shù)據(jù)集進(jìn)行微調(diào)
對(duì)于已有的數(shù)據(jù)集,研究者對(duì)它們進(jìn)行了一些微調(diào),詳見(jiàn)原論文。
此外,他們還對(duì)指令數(shù)據(jù)進(jìn)行了增強(qiáng)。由于他們尤其需要 3D 和音頻模態(tài)的數(shù)據(jù),于是他們使用開(kāi)源大型語(yǔ)言模型 google/flan-t5-xxl 基于相應(yīng)的字幕描述自動(dòng)生成了 3D 和音頻模態(tài)的問(wèn)答對(duì)。這個(gè)過(guò)程最終從 Cap3D 的 3D 數(shù)據(jù)得到了大約 25 萬(wàn)個(gè)示例,從 AudioCaps 的音頻數(shù)據(jù)得到了大約 2.4 萬(wàn)個(gè)示例。
判別式跨模態(tài)推理
X-InstructBLIP 明顯展現(xiàn)出了一個(gè)涌現(xiàn)能力:盡管訓(xùn)練是分模態(tài)進(jìn)行的,但它卻能跨模態(tài)推理。這凸顯了該模型的多功能性以及潛在的跨大量模態(tài)的可擴(kuò)展性。為了研究這種跨模態(tài)推理能力,該團(tuán)隊(duì)構(gòu)建了一個(gè)判別式跨模態(tài)推理挑戰(zhàn)數(shù)據(jù)集 DisCRn。
如圖 5 所示,該任務(wù)需要模型跨模態(tài)分辨兩個(gè)實(shí)體的性質(zhì),做法是選出哪個(gè)模態(tài)滿足查詢的性質(zhì)。該任務(wù)要求模型不僅能分辨所涉模態(tài)的內(nèi)在特征,而且還要考慮它們?cè)谳斎胫械南鄬?duì)位置。這一策略有助于讓模型不再依賴于簡(jiǎn)單的文本匹配啟發(fā)式特征、順序偏差或潛在的欺騙性相關(guān)性。

為了生成這個(gè)數(shù)據(jù)集,研究者再次使用了增強(qiáng)指令數(shù)據(jù)時(shí)用過(guò)的 google/flan-t5-xxl 模型。
在生成過(guò)程中,首先是通過(guò)思維鏈方式為語(yǔ)言模型提供 prompt,從而為每個(gè)數(shù)據(jù)集實(shí)例生成一組屬性。然后,通過(guò)三個(gè)上下文示例使用語(yǔ)言模型,使之能利用上下文學(xué)習(xí),讓每個(gè)實(shí)例都與數(shù)據(jù)集中的一個(gè)隨機(jī)實(shí)例配對(duì),以構(gòu)建一個(gè) (問(wèn)題,答案,解釋) 三元組。
在這個(gè)數(shù)據(jù)集創(chuàng)建過(guò)程中,一個(gè)關(guān)鍵步驟是反復(fù)進(jìn)行的一致性檢查:給定字幕說(shuō)明上,只有當(dāng)模型對(duì)生成問(wèn)題的預(yù)測(cè)結(jié)果與示例答案匹配時(shí)(Levenshtein 距離超過(guò) 0.9),該示例才會(huì)被加入到最終數(shù)據(jù)集中。
這個(gè)優(yōu)化調(diào)整后的數(shù)據(jù)集包含 8802 個(gè)來(lái)自 AudioCaps 驗(yàn)證集的音頻 - 視頻樣本以及來(lái)自 Cap3D 的包含 5k 點(diǎn)云數(shù)據(jù)的留存子集的 29072 個(gè)圖像 - 點(diǎn)云實(shí)例。該數(shù)據(jù)集中每個(gè)實(shí)例都組合了兩個(gè)對(duì)應(yīng)于字幕說(shuō)明的表征:來(lái)自 AudioCaps 的 (音頻,視頻) 和來(lái)自 Cap3D 的 (點(diǎn)云,圖像)。
實(shí)驗(yàn)
該團(tuán)隊(duì)研究了能否將 X-InstructBLIP 有效地用作將跨模態(tài)整合進(jìn)預(yù)訓(xùn)練凍結(jié) LLM 的綜合解決方案。
實(shí)現(xiàn)細(xì)節(jié)
X-InstructBLIP 的構(gòu)建使用了 LAVIS 軟件庫(kù)的框架,基于 Vicuna v1.1 7b 和 13b 模型。每個(gè) Q-Former 優(yōu)化 188M 個(gè)可訓(xùn)練參數(shù)并學(xué)習(xí) K=32 個(gè)隱藏維度大小為 768 的查詢 token。表 1 列出了用于每種模態(tài)的凍結(jié)預(yù)訓(xùn)練編碼器。

優(yōu)化模型的硬件是 8 臺(tái) A100 40GB GPU,使用了 AdamW。
結(jié)果
在展示的結(jié)果中,加下劃線的數(shù)值表示領(lǐng)域內(nèi)的評(píng)估結(jié)果。粗體數(shù)值表示最佳的零樣本性能。藍(lán)色數(shù)值表示第二好的零樣本性能。
對(duì)各個(gè)模態(tài)的理解

該團(tuán)隊(duì)在一系列單模態(tài)到文本任務(wù)上評(píng)估了 X-InstructBLIP 的性能,結(jié)果展現(xiàn)了其多功能性,即能有效應(yīng)對(duì)實(shí)驗(yàn)中的所有四種模態(tài)。表 2、3、4 和 6 總結(jié)了 X-InstructBLIP 在 3D、音頻、圖像和無(wú)聲視頻模態(tài)上的領(lǐng)域外性能。




跨模態(tài)聯(lián)合推理
盡管 X-InstructBLIP 的每個(gè)模態(tài)投影都是分開(kāi)訓(xùn)練的,但它卻展現(xiàn)出了很強(qiáng)的聯(lián)合模態(tài)推理能力。表 7 展示了 X-InstructBLIP 在視頻 (V) 和音頻 (A) 上執(zhí)行聯(lián)合推理的能力。

值得注意的是,X-InstructBLIP 具備協(xié)調(diào)統(tǒng)籌輸入的能力,因?yàn)楫?dāng)同時(shí)使用 MusicAVQA 和 VATEX Captioning 中的不同模態(tài)作為線索時(shí),模型在使用多模態(tài)時(shí)的表現(xiàn)勝過(guò)使用單模態(tài)。但是,這個(gè)行為與模型沒(méi)有前綴提示的模型不一致。
一開(kāi)始的時(shí)候,理論上認(rèn)為模型沒(méi)有能力區(qū)分對(duì)應(yīng)每種模態(tài)的 token,而是將它們看作是連續(xù)流。這可能是原因。但是,來(lái)自圖像 - 3D 跨模態(tài)推理任務(wù)的結(jié)果卻對(duì)這一看法構(gòu)成了挑戰(zhàn) —— 其中沒(méi)有前綴的模型超過(guò)有前綴的模型 10 個(gè)點(diǎn)。似乎包含線索可能會(huì)讓模型對(duì)特定于模態(tài)的信息進(jìn)行編碼,這在聯(lián)合推理場(chǎng)景中是有益的。
但是,這種針對(duì)性的編碼并不能讓模型識(shí)別和處理通常與其它模態(tài)相關(guān)的特征,而這些特征卻是增強(qiáng)對(duì)比任務(wù)性能所需的。其根本原因是:語(yǔ)言模型已經(jīng)過(guò)調(diào)整,就是為了生成與模態(tài)相關(guān)的輸出,這就導(dǎo)致 Q-Former 在訓(xùn)練期間主要接收與特定于模態(tài)的生成相關(guān)的反饋。這一機(jī)制還可以解釋模型在單模態(tài)任務(wù)上出人意料的性能提升。
跨模態(tài)判別式推理
該團(tuán)隊(duì)使用新提出的 DisCRn 基準(zhǔn)評(píng)估了 X-InstructBLIP 在不同模態(tài)上執(zhí)行判別式推理的能力。他們將該問(wèn)題描述成了一個(gè)現(xiàn)實(shí)的開(kāi)放式生成問(wèn)題。在給 LLM 的 prompt 中會(huì)加上如下前綴:
在向 X-InstructBLIP (7b) 輸入 prompt 時(shí),該團(tuán)隊(duì)發(fā)現(xiàn):使用 Q-Former 字幕描述 prompt(這不同于提供給 LLM 模型的比較式 prompt)會(huì)導(dǎo)致得到一種更適用于比較任務(wù)的更通用的表征,因此他們采用這種方法得到了表 8 的結(jié)果。其原因很可能是微調(diào)過(guò)程中缺乏比較數(shù)據(jù),因?yàn)槊總€(gè)模態(tài)的 Q-Former 都是分開(kāi)訓(xùn)練的。

為了對(duì)新提出的模型進(jìn)行基準(zhǔn)測(cè)試,該團(tuán)隊(duì)整合了一個(gè)穩(wěn)健的字幕描述基準(zhǔn),其做法是使用 Vicuna 7b 模型用對(duì)應(yīng)于各模態(tài)的字幕描述來(lái)替換查詢輸出。對(duì)于圖像、3D 和視頻模態(tài),他們的做法是向 InstructBLIP 輸入 prompt 使其描述圖像 / 視頻,從而得出字幕描述。對(duì)于 3D 輸入,輸入給 InstructBLIP 的是其點(diǎn)云的一個(gè)隨機(jī)選取的渲染視圖。
結(jié)果可以看到,在準(zhǔn)確度方面,X-InstructBLIP 分別優(yōu)于音頻 - 視頻和圖像 - 3D 基準(zhǔn)模型 3.2 和 7.7 個(gè)百分點(diǎn)。用等價(jià)的線性投影模塊替換其中一個(gè) Q-Former 后,圖像 - 3D 的性能會(huì)下降一半以上,音頻 - 視頻的性能會(huì)下降超過(guò) 10 個(gè)點(diǎn)。























