10年前,word2vec經(jīng)典論文就預(yù)定了今天的NeurIPS時間檢驗獎
NeurIPS 是當(dāng)前全球最負盛名的 AI 學(xué)術(shù)會議之一,全稱是 Neural Information Processing Systems,神經(jīng)信息處理系統(tǒng)大會,通常在每年 12 月由 NeurIPS 基金會主辦。大會討論的內(nèi)容包含深度學(xué)習(xí)、計算機視覺、大規(guī)模機器學(xué)習(xí)、學(xué)習(xí)理論、優(yōu)化、稀疏理論等眾多細分領(lǐng)域。
12 月 10 日,NeurIPS 2023 在美國路易斯安那州新奧爾良市拉開帷幕。根據(jù)官網(wǎng)博客公布的數(shù)據(jù),今年大會收到的論文投稿數(shù)量創(chuàng)造了新紀錄,達到 13321 篇,由 1100 名領(lǐng)域主席、100 名高級領(lǐng)域主席和 396 名倫理審稿人審查,其中 3584 篇論文被接收。
剛剛,NeurIPS 官方公布了 2023 年度的獲獎?wù)撐模〞r間檢驗獎、兩篇杰出論文、兩篇杰出論文 runner-up、一個杰出數(shù)據(jù)集和一個杰出基準,其中大部分論文都是圍繞大型語言模型(LLM)展開的工作。值得注意的是,十年前發(fā)布的 word2vec 相關(guān)論文摘得了時間檢驗獎,可謂實至名歸。

以下是獲獎?wù)撐牡木唧w信息。
時間檢驗獎
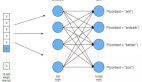
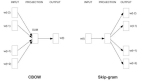
今年的時間檢驗獎頒給了十年前的 NeurIPS 論文「Distributed Representations of Words and Phrases and their Compositionality」。

這篇論文由當(dāng)時都還在谷歌的 Tomas Mikolov、Ilya Sutskever、Kai Chen、Greg Corrado、Jeffrey Dean 等人撰寫,被引量超過 4 萬次。

論文地址:https://arxiv.org/pdf/1310.4546.pdf
NeurIPS 官方給出的頒獎理由是:這項工作引入了開創(chuàng)性的詞嵌入技術(shù) word2vec,展示了從大量非結(jié)構(gòu)化文本中學(xué)習(xí)的能力,推動了自然語言處理新時代的到來。
在機器之心原創(chuàng)技術(shù)分析文章《從 word2vec 開始,說下 GPT 龐大的家族系譜》中,我們曾介紹過 word2vec 的重要性。Word2Vec 和 Glove 等詞嵌入方法可以說是當(dāng)前最為熱門的 GPT 家族老祖級別的研究,引領(lǐng)了后續(xù)龐大的 NLP「家族集團」,也為整個 NLP 技術(shù)的蓬勃發(fā)展奠定了堅實的基礎(chǔ)。

從 Word2Vec 等詞嵌入技術(shù)開始到后續(xù)的重要模型

機器之心整理的重要 NLP 模型發(fā)展脈絡(luò)
所以說,在大模型備受關(guān)注的 2023 年,Word2vec 獲得 NeurIPS 的時間檢驗獎也實至名歸了。
這里補充一句,其實提到 Word2vec,首篇論文應(yīng)該是 Tomas Mikolov 等同一作者的「Efficient Estimation of Word Representations in Vector Space」。而投稿到當(dāng)年 NeurIPS 這篇「Distributed Representations of Words and Phrases and their Compositionality」算是真正讓 Word2vec 被廣泛應(yīng)用的改進論文。
如果有讀者想要詳細了解、學(xué)習(xí) Word2vec,也可以查閱機器之心原創(chuàng)技術(shù)分析文章《詞嵌入的經(jīng)典方法,六篇論文遍歷 Word2vec 的另類應(yīng)用》。
Main Track 杰出論文獎
獲獎?wù)撐?1:Privacy Auditing with One (1) Training Run

- 論文地址:https://arxiv.org/abs/2305.08846
- 機構(gòu):Google
摘要:本文提出了一種通過單次訓(xùn)練來檢查差分隱私機器學(xué)習(xí)系統(tǒng)的方案。該方案利用了差分隱私機器學(xué)習(xí)系統(tǒng)能夠獨立添加或刪除多個訓(xùn)練示例的并行性。研究者們從這一點入手,分析了差分隱私和統(tǒng)計泛化的聯(lián)系,從而避免了群體隱私的成本。這種方案對算法的假設(shè)要求極低,可應(yīng)用于黑盒或白盒環(huán)境。研究者們在 DP-SGD 中運用了這項方案,以檢驗其有效性。在 DP-SGD 中,本文中提出的框架只需要訓(xùn)練一個模型,就能實現(xiàn)有意義的經(jīng)驗隱私下界。相比之下,標準方法需要訓(xùn)練數(shù)百個模型。
獲獎?wù)撐?2:Are Emergent Abilities of Large Language Models a Mirage?

- 論文地址:https://arxiv.org/abs/2304.15004
- 機構(gòu):斯坦福大學(xué)
摘要:最近有研究稱,大語言模型「涌現(xiàn)」出了在小規(guī)模模型中不存在的能力。大模型「涌現(xiàn)」能力之所以吸引人,有兩個原因:一是其突現(xiàn)性,這些能力幾乎是一瞬間出現(xiàn)的;二是涌現(xiàn)的能力具體將在哪種規(guī)模的模型中出現(xiàn),不可預(yù)測。因此,研究者們對涌現(xiàn)能力提出了一種新解釋:對于特定的任務(wù)和模型家族,在分析固定的模型輸出時,「涌現(xiàn)」能力的出現(xiàn)是由于研究者選擇了特定的度量標準,而不是模型的表現(xiàn)隨規(guī)模發(fā)生了根本性的變化。
具體來說,非線性或者不連續(xù)度量會產(chǎn)生明顯的「涌現(xiàn)」能力,而線性或連續(xù)度量則會產(chǎn)生平滑、連續(xù)、可預(yù)測的模型性能變化。研究者們在一個簡單的數(shù)學(xué)模型中提出了這項新解釋,并通過三種互補的方式對其進行了檢驗。首先,他們在 InstructGPT/GPT-3 系列中對聲稱具有「涌現(xiàn)」能力的任務(wù)檢驗了這項新假設(shè)的三項內(nèi)容;其次,在 BIG-Bench 的涌現(xiàn)能力元分析中制定、測試并證實了兩個關(guān)于度量標準選擇的預(yù)測;最后,論文中展示了如何選擇度量標準,以在不同深度網(wǎng)絡(luò)的多個視覺任務(wù)中「創(chuàng)造出」前所未有的「涌現(xiàn)」能力。
通過以上的分析,論文證明了所謂的「涌現(xiàn)」能力會隨著不同的度量或統(tǒng)計方式消失,而并非人工智能的基本屬性得到了擴展。
Main Track 杰出論文 Runner-up 獎
獲獎?wù)撐?1:Scaling Data-Constrained Language Models

- 論文鏈接:https://arxiv.org/abs/2305.16264
- 項目鏈接:https://github.com/huggingface/datablations
- 機構(gòu):Hugging Face、哈佛大學(xué)、圖爾庫大學(xué)
摘要:增加參數(shù)數(shù)量、擴大訓(xùn)練數(shù)據(jù)集的規(guī)模是當(dāng)今語言模型的發(fā)展趨勢。根據(jù)這一趨勢推斷,訓(xùn)練數(shù)據(jù)集的規(guī)模可能很快就會受互聯(lián)網(wǎng)上可用文本數(shù)據(jù)量的限制。受到這一可見趨勢的啟發(fā),有研究者對數(shù)據(jù)受限情況下語言模型的拓展進行了探索。
具體來說,他們通過改變數(shù)據(jù)的重復(fù)程度和計算預(yù)算,進行了大量的實驗。實驗中的數(shù)據(jù)量最高可達 9000 億個訓(xùn)練 token,模型規(guī)模可達 90 億個參數(shù)。研究者發(fā)現(xiàn),在計算預(yù)算固定、數(shù)據(jù)受限的情況下,使用重復(fù)數(shù)據(jù)進行 4 個周期(epoch)的訓(xùn)練,與使用不重復(fù)的數(shù)據(jù)相比,損失的變化可以忽略不計。然而,隨著重復(fù)次數(shù)的增加,增加計算量的價值最終會降至零。研究者們進而提出并實證驗證了一個計算最優(yōu)化的擴展定律(scaling law),該定律考慮了重復(fù) token 和多余參數(shù)價值遞減的問題。最后,他們嘗試了多種緩解數(shù)據(jù)稀缺性的方法,包括使用代碼數(shù)據(jù)擴充訓(xùn)練數(shù)據(jù)集或刪除常用的過濾器。本研究的模型和數(shù)據(jù)集可在以下鏈接中免費獲取:https://github.com/huggingface/datablations
獲獎?wù)撐?2:Direct Preference Optimization: Your Language Model is Secretly a Reward Model

- 論文鏈接:https://arxiv.org/abs/2305.18290
- 機構(gòu):斯坦福大學(xué)、 CZ Biohub
摘要:雖然大規(guī)模無監(jiān)督語言模型(LMs)可以廣泛地學(xué)習(xí)世界中的知識,獲得一些推理技能,但由于其訓(xùn)練完全不受監(jiān)督,因此很難實現(xiàn)對其行為的精確控制。目前獲得這種可控性通常依靠人類反饋強化學(xué)習(xí)(RLHF)這種方法實現(xiàn),收集人類對各種模型生成質(zhì)量打出的標簽,并根據(jù)這些偏好對無監(jiān)督語言模型進行微調(diào)。然而,RLHF 是一個復(fù)雜并且經(jīng)常不穩(wěn)定的過程。它首先需要擬合一個反映人類偏好的獎勵模型,然后利用強化學(xué)習(xí)對大型無監(jiān)督語言模型進行微調(diào),以最大限度地提高預(yù)計中的獎勵,同時又不會偏離原始模型太遠。
在這項研究中,研究者們通過獎勵函數(shù)和最優(yōu)策略之間的映射關(guān)系證明了只需進行一個階段的策略訓(xùn)練,就能精確優(yōu)化受限獎勵的最大化問題。從根本上解決了人類偏好數(shù)據(jù)的分類問題。研究者們稱這種新方法為:直接偏好優(yōu)化(DPO),它穩(wěn)定、高效、計算量小,無需擬合獎勵模型、在微調(diào)過程中從語言模型中采樣,或執(zhí)行重要的超參數(shù)調(diào)整。實驗表明,DPO 能夠微調(diào) LM 以符合人類偏好,其效果與現(xiàn)有方法相當(dāng)或更好。值得注意的是,與 RLHF 相比,使用 DPO 進行微調(diào)在控制生成內(nèi)容的情感、提高摘要和單輪對話的響應(yīng)質(zhì)量方面表現(xiàn)更好,同時實現(xiàn)和訓(xùn)練過程大大簡化。
杰出數(shù)據(jù)集和基準論文
數(shù)據(jù)集
獲獎?wù)撐模篊limSim: A large Multi-scale Dataset for Hybrid Physics-ML Climate Emulation

- 論文地址:https://arxiv.org/pdf/2306.08754.pdf
- 機構(gòu):UCI、 LLNL、Columbia、UCB、MIT、DLR、Princeton 等
論文摘要:由于計算限制,現(xiàn)代氣候預(yù)測缺乏足夠的空間和時間分辨率,導(dǎo)致對風(fēng)暴等極端氣候預(yù)測不準確、不精確。這時融合物理與機器學(xué)習(xí)的混合方法引入了新一代保真度更高的氣候模擬器,它們可以通過將計算需求巨大、短時、高分辨率的模擬任務(wù)「外包」給機器學(xué)習(xí)模擬器以繞過摩爾定律桎梏。不過,這種混合的機器學(xué)習(xí) - 物理模擬方法需要針對特定領(lǐng)域具體處理,并且由于缺乏訓(xùn)練數(shù)據(jù)以及相關(guān)易用的工作流程,機器學(xué)習(xí)專家們也無法使用。
本文中,研究者推出了 ClimSim,一個專為混合機器學(xué)習(xí) - 物理研究設(shè)計的迄今為止最大的數(shù)據(jù)集,包含了氣候科學(xué)家和機器學(xué)習(xí)研究人員聯(lián)合開發(fā)的多尺度氣候模擬。具體來講,ClimSim 由 57 億個多元輸入和輸出向量對組成,它們隔絕了局部嵌套、高分辨率、高保真度物理對主機氣候模擬器宏觀物理狀態(tài)的影響。該數(shù)據(jù)集覆蓋全球,以高采樣頻率持續(xù)多年,設(shè)計生成的模擬器能夠與下游的操作氣候模擬器相兼容。

ClimSlim 的局部空間版本。
研究者實現(xiàn)了一系列確定性和隨機回歸基線,以突出機器學(xué)習(xí)挑戰(zhàn)和基線得分。他們公開了相關(guān)數(shù)據(jù)和代碼,用以支持混合機器學(xué)習(xí) - 物理和高保真氣候模擬的開發(fā),造福科學(xué)和社會。
項目地址:https://leap-stc.github.io/ClimSim/README.html
基準
獲獎?wù)撐模篋ECODINGTRUST: A Comprehensive Assessment of Trustworthiness in GPT Models

- 論文地址:https://arxiv.org/pdf/2306.11698.pdf
- 機構(gòu):伊利諾伊大學(xué)厄巴納 - 香檳分校、斯坦福大學(xué)、UC 伯克利、AI 安全中心、微軟
論文摘要:GPT 模型在能力層面已經(jīng)展現(xiàn)出了無與倫比的進展,但有關(guān) GPT 模型可信度的文獻仍然不多。從業(yè)者提議將強大的 GPT 模型用于醫(yī)療和金融領(lǐng)域的敏感性應(yīng)用,可能面臨高昂的代價。
為此,本文研究者對大型語言模型進行了全面可信度評估,并以 GPT-4 和 GPT-3.5 為重點模型,充分考慮了不同的視角,包括毒性(toxicity)、刻板印象偏差、對抗穩(wěn)健性、分布外穩(wěn)健性、對抗演示穩(wěn)健性、隱私、機器倫理道德和公平性等。評估結(jié)果發(fā)現(xiàn)了以往未曾披露的可信度威脅漏洞,例如 GPT 模型很容易被誤導(dǎo),從而輸出有毒和有偏見的內(nèi)容,并泄露訓(xùn)練數(shù)據(jù)和對話記錄中的個人信息。

大模型可信度評估指標。
研究者還發(fā)現(xiàn),雖然在標準基準上 GPT-4 比 GPT-3.5 更值得信賴,但由于 GPT-4 更精確地遵循誤導(dǎo)性指令,因而它也更容易受到攻擊。
基準測試:https://decodingtrust.github.io/