













分割一切「3D高斯」版來(lái)了:幾毫秒完成3D分割、千倍加速
今年 4 月,Meta 發(fā)布「分割一切(SAM)」AI 模型,這項(xiàng)成果不僅成為很多 CV 研究者心中的年度論文,更是在 ICCV 2023 上斬獲最佳論文提名 。
「分割一切」實(shí)現(xiàn)了 2D 分割的「既能」和「又能」,可以輕松地執(zhí)行交互式分割和自動(dòng)分割,且能泛化到任意新任務(wù)和新領(lǐng)域。
現(xiàn)在,這種思路也延展到了 3D 分割領(lǐng)域。
輻射場(chǎng)中的交互式 3D 分割一直是個(gè)備受關(guān)注的課題,在場(chǎng)景操作、自動(dòng)標(biāo)注和 VR 等多個(gè)領(lǐng)域均有潛在應(yīng)用價(jià)值。以往的方法主要是通過(guò)訓(xùn)練特征場(chǎng)來(lái)模仿自監(jiān)督視覺(jué)模型提取的多視角 2D 特征,從而將 2D 視覺(jué)特征提升到 3D 空間,然后利用 3D 特征的相似性來(lái)衡量?jī)蓚€(gè)點(diǎn)是否屬于同一個(gè)物體。
這種方法由于分割管道簡(jiǎn)單,因此速度很快,但代價(jià)是分割粒度較粗,因?yàn)樗鼈內(nèi)狈馕銮度胩卣餍畔⒌臋C(jī)制(如分割解碼器)。
與此相反,另一種范式是將多視角細(xì)粒度 2D 分割結(jié)果直接投影到 3D 掩 ma 網(wǎng)格上,從而將 2D 分割基礎(chǔ)模型提升到 3D。雖然這種方法可以獲得精確的分割結(jié)果,但由于需要多次運(yùn)行基礎(chǔ)模型和體渲染,大量的時(shí)間開(kāi)銷(xiāo)限制了交互體驗(yàn)。特別是對(duì)于需要分割多個(gè)對(duì)象的復(fù)雜場(chǎng)景,這種計(jì)算成本變得難以承受。
近期,3D Gaussian Splatting(3DGS)因其高質(zhì)量和實(shí)時(shí)渲染的能力,為輻射場(chǎng)交互式 3D 分割帶來(lái)了新的突破。它采用一組 3D 彩色高斯來(lái)表示 3D 場(chǎng)景,高斯的平均值表示它們?cè)?3D 空間中的位置,因此 3DGS 可以看作是一種點(diǎn)云,它有助于繞過(guò)對(duì)空曠 3D 空間的大量處理,并提供豐富的顯式 3D 先驗(yàn)。有了這種類(lèi)似于點(diǎn)云的結(jié)構(gòu),3DGS 不僅能實(shí)現(xiàn)高效的渲染,還能成為分割任務(wù)的理想候選對(duì)象。
受到這種方法的啟發(fā),在最近的一篇論文中,來(lái)自上海交大和華為的研究者在 3DGS 的基礎(chǔ)上提出了將 2D 的「分割一切」模型的細(xì)粒度分割能力提煉到 3D 高斯中。

論文鏈接:https://arxiv.org/pdf/2312.00860.pdf
這一策略有別于以往將 2D 視覺(jué)特征提升到 3D 的方法,實(shí)現(xiàn)了精細(xì)的 3D 分割。此外,它還避免了推理過(guò)程中耗時(shí)的 2D 分割模型的多次 forward。這種蒸餾是通過(guò)使用 Segment Anything Model(SAM)根據(jù)自動(dòng)提取的掩碼訓(xùn)練高斯 3D 特征來(lái)實(shí)現(xiàn)的。在推理過(guò)程中,通過(guò)輸入提示生成一組查詢(xún),然后通過(guò)高效的特征匹配檢索預(yù)期的高斯。
研究者將這種方法命名為 Segment Any 3D GAussians (SAGA),可在幾毫秒內(nèi)實(shí)現(xiàn)精細(xì)的三維分割,并支持各種提示,包括點(diǎn)、涂鴉和掩碼。對(duì)現(xiàn)有基準(zhǔn)的評(píng)估表明,SAGA 的分割質(zhì)量與之前的 SOTA 水平相當(dāng)。

作為在 3D 高斯中進(jìn)行交互式分割的首次嘗試,SAGA 具有多功能性,可適應(yīng)各種提示類(lèi)型,包括掩碼、點(diǎn)和涂鴉。值得注意的是,高斯特征的訓(xùn)練通常只需 5-10 分鐘即可完成。隨后,大多數(shù)目標(biāo)對(duì)象的分割可在幾毫秒內(nèi)完成,實(shí)現(xiàn)了近 1000 倍的加速。

方法概覽
下圖 2 為 SAGA 的整體 pipeline。給定預(yù)訓(xùn)練的 3DGS 模型及其訓(xùn)練集,研究者首先使用 SAM 編碼器來(lái)提取一個(gè) 2D 特征圖 ,以及 I 中每個(gè)圖像 I ∈ R^H×W 的一組多粒度掩碼 M^SAM_I。接著基于提取的掩碼來(lái)訓(xùn)練一個(gè)低維特征 f_g ∈ R^C,以聚合交叉視圖一致的多粒度分割信息(其中 C 表示特征維度,默認(rèn)值設(shè)置為了 32)。這些通過(guò)精心設(shè)計(jì)的 SAM 引導(dǎo)損失來(lái)實(shí)現(xiàn)。
,以及 I 中每個(gè)圖像 I ∈ R^H×W 的一組多粒度掩碼 M^SAM_I。接著基于提取的掩碼來(lái)訓(xùn)練一個(gè)低維特征 f_g ∈ R^C,以聚合交叉視圖一致的多粒度分割信息(其中 C 表示特征維度,默認(rèn)值設(shè)置為了 32)。這些通過(guò)精心設(shè)計(jì)的 SAM 引導(dǎo)損失來(lái)實(shí)現(xiàn)。
為了進(jìn)一步增強(qiáng)特征緊湊性,研究者從提取的掩碼中導(dǎo)出點(diǎn)對(duì)應(yīng)關(guān)系,并將它們提煉為特征(即對(duì)應(yīng)損失)。

在推理階段,對(duì)于具有相機(jī)姿態(tài) v 的特定視圖,研究者基于輸入提示 P 來(lái)生成一組查詢(xún) Q。接著通過(guò)與學(xué)得的特征進(jìn)行高效特征匹配,使用這些查詢(xún)來(lái)檢索對(duì)應(yīng)目標(biāo)的 3D 高斯。
此外,研究者還引入了一種高效的后處理操作,利用類(lèi)點(diǎn)云結(jié)構(gòu)的 3DGS 提供的強(qiáng)大 3D 先驗(yàn)來(lái)細(xì)化檢索到的 3D 高斯。
高斯訓(xùn)練特征
給定一個(gè)具有特定相機(jī)姿態(tài) v 的訓(xùn)練圖像 I,研究者首先根據(jù)預(yù)訓(xùn)練的 3DGS 模型 來(lái)渲染對(duì)應(yīng)的特征圖。像素 p 的渲染后特征 F^r_I,p 計(jì)算為如下公式 (3)。
來(lái)渲染對(duì)應(yīng)的特征圖。像素 p 的渲染后特征 F^r_I,p 計(jì)算為如下公式 (3)。

SAM 引導(dǎo)的損失。研究者提出使用 SAM 生成的特征來(lái)做引導(dǎo)。如上圖 2 所示,他們首先采用一個(gè) MLP φ,將 SAM 特征映射到與 3D 特征相同的低維空間。

對(duì)應(yīng)關(guān)系損失。在實(shí)踐中,研究者發(fā)現(xiàn)使用 SAM 引導(dǎo)損失學(xué)得的特征在緊湊性上不夠,從而導(dǎo)致各種提示的分割質(zhì)量下降。他們從以往的對(duì)比對(duì)應(yīng)關(guān)系蒸餾方法中汲取靈感,提出用對(duì)應(yīng)關(guān)系損失來(lái)解決問(wèn)題。掩碼對(duì)應(yīng)關(guān)系 K_I (p1, p2) 定義如下公式(8)。

推理
3D 高斯的分割可以利用 2D 渲染的特征來(lái)實(shí)現(xiàn)。這一特性使得 SAGA 兼容了各種提示,包括點(diǎn)、涂鴉和掩碼。此外基于 3DGS 提供的 3D 先驗(yàn),研究者還引入了一種高效的后處理算法。
基于 3D 先驗(yàn)的后處理
3D 高斯的初始分割 存在兩個(gè)問(wèn)題,分別是存在多余的噪聲高斯,缺少對(duì)目標(biāo)對(duì)象至關(guān)重要的特定高斯。為了解決這兩個(gè)問(wèn)題,研究者利用了傳統(tǒng)的點(diǎn)云分割技術(shù),包括統(tǒng)計(jì)過(guò)濾和區(qū)域生長(zhǎng)。
存在兩個(gè)問(wèn)題,分別是存在多余的噪聲高斯,缺少對(duì)目標(biāo)對(duì)象至關(guān)重要的特定高斯。為了解決這兩個(gè)問(wèn)題,研究者利用了傳統(tǒng)的點(diǎn)云分割技術(shù),包括統(tǒng)計(jì)過(guò)濾和區(qū)域生長(zhǎng)。
對(duì)于基于點(diǎn)和涂鴉提示的分割,他們使用統(tǒng)計(jì)過(guò)濾來(lái)過(guò)濾掉噪聲高斯。對(duì)于掩碼提示和基于 SAM 的提示,他們分別將 2D 掩碼映射到 和
和 上,前者得到一組驗(yàn)證后的高斯,后者消除不想要的高斯。
上,前者得到一組驗(yàn)證后的高斯,后者消除不想要的高斯。
所得到的驗(yàn)證后的高斯作為區(qū)域生成算法的種子(seed)。最后使用基于球查詢(xún)的區(qū)域生長(zhǎng)算法來(lái)從原始模型 中檢索目標(biāo)需要的所有高斯。
中檢索目標(biāo)需要的所有高斯。
實(shí)驗(yàn)評(píng)估
研究者在定量實(shí)驗(yàn)中使用了 NVOS(Neural Volumetric Object Selection)和 SPIn-NeRF 兩個(gè)數(shù)據(jù)集,在定性實(shí)驗(yàn)中使用了 LLFF、MIP-360、T&T 和 LERF 數(shù)據(jù)集。此外他們使用 SA3D 來(lái)為 LERF-figurines 場(chǎng)景中的一些對(duì)象做注釋?zhuān)哉宫F(xiàn) SAGA 能夠取得更好的權(quán)衡效率和分割質(zhì)量。
定量結(jié)果
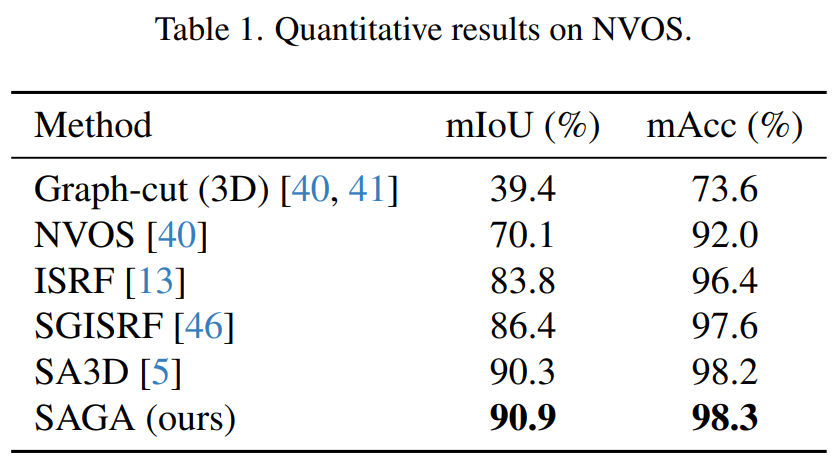
NVOS 數(shù)據(jù)集。研究者遵照 SA3D 的方法來(lái)處理 NVOS 數(shù)據(jù)集提供的涂鴉,以滿(mǎn)足 SAM 的要求。結(jié)果如下表 1 所示,SAGA 能夠媲美以往的 SOTA 方法 SA3D,并顯著優(yōu)于 ISRF 和 SGISRF 等以往基于特征模擬的方法,展現(xiàn)了自身的細(xì)粒度分割質(zhì)量。
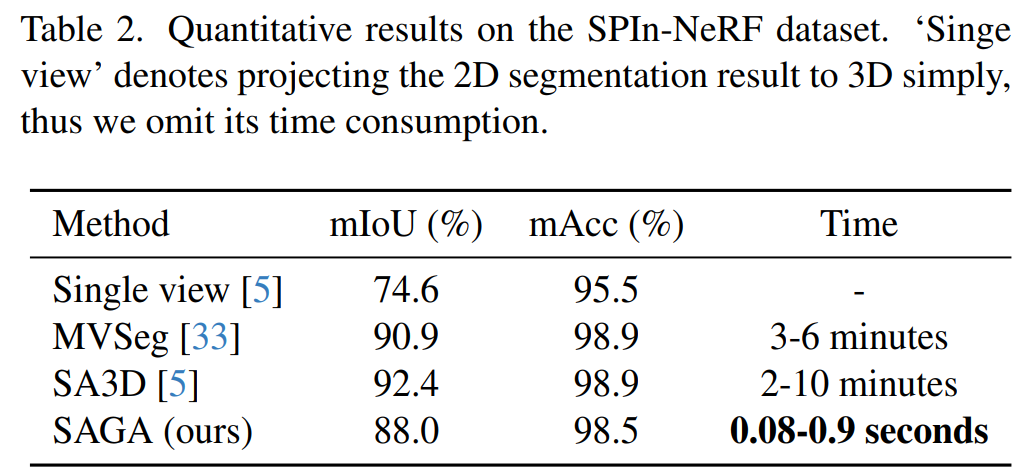
SPIn-NeRF 數(shù)據(jù)集。研究者遵照 SPIn-NeRF 方法來(lái)進(jìn)行標(biāo)簽傳播評(píng)估,其中指定了一個(gè)視圖及它的 ground-truth 掩碼,并將該掩碼傳播給其他視圖以檢查掩碼的準(zhǔn)確性,這一操作可以視為掩碼提示。結(jié)果如下表 2 所示,SAGA 在僅用千分之一的時(shí)間便取得了與 MVSeg 和 SA3D 相當(dāng)?shù)男阅堋?/span>
與 SA3D 比較。為了進(jìn)一步展示 SAGA 的有效性,研究者在分割時(shí)間和質(zhì)量?jī)蓚€(gè)指標(biāo)上與 SA3D 進(jìn)行了比較。他們基于 LERF-figurines 場(chǎng)景運(yùn)行 SA3D,為很多對(duì)象提供了一組注釋。然后使用 SAGA 來(lái)分割相同的對(duì)象,并檢查了每個(gè)對(duì)象的 IoU 和時(shí)間開(kāi)銷(xiāo)。結(jié)果如下表 3 所示,展示了 SAGA 可以使用更少的時(shí)間獲得更高質(zhì)量的 3D 資產(chǎn)。

定性結(jié)果
研究者首先確定了 SAGA 的分割精度與先前的 SOTA SA3D 相當(dāng),同時(shí)顯著降低了時(shí)間成本。隨后,他們展示了 SAGA 在部件和目標(biāo)分割任務(wù)中比 ISRF 更強(qiáng)的性能。結(jié)果如圖 3 所示。

第一行顯示了 SA3D 和 SAGA 對(duì) LERF-figurines 場(chǎng)景的分割結(jié)果,每個(gè)分割對(duì)象的右下方標(biāo)注了分割時(shí)間;第二行比較了 SAGA 和 ISRF,后者通過(guò)模仿自監(jiān)督視覺(jué) transformer(如 DINO [4])提取的 2D 特征來(lái)訓(xùn)練特征字段;第三行展示了 MIP360-counter 和 T&T-truck 場(chǎng)景的其他分割結(jié)果。
在表 2 中有一些失敗案例,與之前的 SOTA 方法相比,SAGA 的性能并不理想。這是因?yàn)?LLFF-room 場(chǎng)景的分割失敗,暴露了 SAGA 的局限性。圖 4 展示了彩色高斯平均值,它可以看作是一種點(diǎn)云,SAGA 容易受到 3DGS 模型幾何重建不足的影響。

更多技術(shù)細(xì)節(jié)和實(shí)驗(yàn)結(jié)果請(qǐng)閱讀原論文。



















