短小精悍的BEV實例預測框架:PowerBEV
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
01 摘要
準確感知實例并預測其未來運動是自動駕駛汽車的關鍵任務,可使其在復雜的城市交通中安全導航。雖然鳥瞰圖(BEV)表示法在自動駕駛感知中很常見,但其在運動預測設置中的潛力卻較少被發掘。現有的環繞攝像頭 BEV 實例預測方法依賴于多任務自動回歸設置和復雜的后處理,以時空一致的方式預測未來實例。在本文中,我們偏離了這一模式,提出了一種名為 "POWER BEV "的高效新型端到端框架。首先,POWER BEV 并非以自動回歸的方式預測未來,而是使用由輕量級二維卷積網絡構建的并行多尺度模塊。其次,我們證明了分割和向心倒流足以進行預測,通過消除多余的輸出模式簡化了以往的多任務目標。在這種輸出表示法的基礎上,我們提出了一種簡單的、基于流經的后處理方法,這種方法能產生更穩定的跨時間實例關聯。通過這種輕量級但功能強大的設計,POWER BEV 在 NuScenes 數據集上的表現優于最先進的基準,為 BEV 實例預測提供了另一種范例。

▲圖1|PowerBEV和其他模式的對比
02 引言
準確獲取周圍車輛信息是自動駕駛系統面臨的一項關鍵挑戰。考慮到駕駛環境的高度復雜性和動態性,除了目前對道路使用者的精確檢測和定位外,預測他們的未來運動也非常重要。一種廣為接受的模式是將這些任務分解為不同的模塊。在這種模式下,首先通過復雜的感知模型對感興趣的物體進行檢測和定位,并在多個幀中進行關聯。然后,通過參數軌跡模型,利用這些檢測到的物體過去的運動來預測其未來的潛在運動。但由于感知和運動模型是分開進行預測的,因此整個系統在第一階段很容易出現誤差。
近年來,許多研究都證明了鳥瞰圖(BEV)表示法在以視覺為中心的精確駕駛環境感知方面的潛力。為解決誤差累積問題,研究人員試圖利用端到端框架直接確定 BEV 中的物體位置,并以占位網格圖的形式預測全局場景變化。
如圖1和圖4所示,雖然采用了端到端范例,但現有方法預測了多個部分冗余的表征,如分割圖、實例中心、前向流和指向實例中心的偏移。這些冗余表征不僅需要各種損失項,還需要復雜的后處理才能獲得實例預測。
在這項工作中,我們簡化了之前工作中使用的多任務設置,并提出了一種只需要兩種輸出模式的方法:分割圖和流量。具體來說,我們直接從分割中計算實例中心,從而省去了多余的單獨中心圖。這也消除了估計中心和預測分割之間不一致的可能性。此外,與前人使用的前向流不同,我們計算的是向心后向流。這是一個矢量場,從當前每個被占據的像素點指向上一幀中其對應的實例中心。它將像素級關聯和實例級關聯合并為單一的像素實例分配任務。因此,不再需要偏移頭。此外,這種設計選擇還簡化了關聯過程,因為它不再需要多個步驟。與自動回歸模型相比,我們還發現二維卷積網絡足以讓所提出的 POWER BEV 框架獲得令人滿意的實例預測,從而形成一個輕量級但功能強大的框架。
我們在NuScenes數據集上對我們的方法進行了評估,結果表明我們的方法優于現有框架,并達到了最先進的實例預測性能。我們還進一步進行了消融研究,以驗證我們強大而輕巧的框架設計。
我們的主要貢獻可總結如下:
●我們提出了 POWER BEV,這是一種新穎而優雅的基于視覺的端到端框架,它僅由二維卷積層組成,可對 BEV 中的多個物體進行感知和預測。
●我們證明,冗余表征導致的過度監督會損害預測能力。相比之下,我們的方法通過簡單的預測分割和向心后向流就能完成語義和實例級代理預測。
●基于向心后向流的分配方案優于之前的前向流和傳統的匈牙利匹配算法。
03 相關工作
■3.1 BEV針對基于相機的3D感知
雖然基于激光雷達的感知方法通常會將三維點云映射到 BEV 平面上,并進行 BEV 分割或三維邊界框回歸,但將單目相機圖像轉換為 BEV 表示仍然是一個難題。雖然有一些方法結合激光雷達和相機數據生成 BEV,但這些方法依賴于精確的多傳感器校準和同步。
LSS(Lift Splat Shoot)可被視為第一個將二維特征提升到三維并將提升后的特征投射到 BEV 平面上的工作。它將深度離散化,并預測深度分布。然后,圖像特征將根據該分布在深度維度上進行縮放和分布。BEVDet 將 LSS 適應于從 BEV 特征圖進行 3D 物體檢測。2021 年特斯拉人工智能日首先提出使用 Transformer 架構將多視角相機特征融合到 BEV 特征圖中,其中密集 BEV 查詢和透視圖像特征之間的交叉關注充當視圖變換。通過利用 BEVFormer和 BEVSegFormer中的相機校準和可變形注意力來降低變換器的二次方復雜性,這種方法得到了進一步改進。此外,已有研究表明,BEV 特征的時間建模可顯著提高三維檢測性能,但代價是高計算量和內存消耗。與檢測或分割不同,預測任務自然需要對歷史信息進行時間建模。為此,我們的方法在 LSS 的基礎上使用輕量級全卷積網絡提取時空信息,既有效又高效。
■3.2 BEV未來預測
早期基于 BEV 的預測方法將過去的軌跡渲染為 BEV 圖像,并使用 CNN 對光柵化輸入進行編碼,假設完美檢測和跟蹤物體。另一項工作是直接從 LiDAR 點云進行端到端軌跡預測。與實例級軌跡預測不同,MotionNet和 MP3 通過每個占用網格的運動(流)場來處理預測任務。與上述依賴 LiDAR 數據的方法相比,FIERY 首先僅根據多視圖相機數據預測 BEV 實例分割。FIERY 按照 LSS 提取多幀 BEV 特征,使用循環網絡將它們融合成時空狀態,然后進行概率實例預測。StretchBEV 使用具有隨機殘差更新的隨機時間模型改進了 FIERY。BVerse 提出了一種潛在空間中的迭代流扭曲,用于多任務 BEV 感知框架中的預測。這些方法遵循 Panoptic-DeepLab ,它利用四個不同的頭來計算語義分割圖、實例中心、每像素向心偏移和未來流。他們依靠復雜的后處理從這四種表示生成最終的實例預測。在本文中,我們表明只需兩個頭,即語義分割和向心向后流,再加上簡化的后處理就足以用于未來的實例預測。

▲圖2|PowerBEV算法架構
04 方法
在本節中,我們概述了我們提出的端到端框架。該方法的概述如圖 2 所示。它由三個主要部分組成:感知模塊、預測模塊和后處理階段。感知模塊遵循 LSS ,并以時間戳中的 T 為輸入,將 M 個多視圖相機圖像作為輸入,并將它們提升到 BEV 特征圖中的 T(參見第 3.1節)。然后,預測模塊融合提取的 BEV 特征中包含的時空信息(參見第 3.2 節),并并行預測未來幀的分割圖序列和向心向后流(參見第 3.3 節)。最后,從預測的分割中恢復未來的實例預測,并通過基于變形的后處理(參見第 3.4 節)。下面我們詳細描述每個涉及的組件。

▲圖3|多尺度預測模型架構
■4.1 基于LSS的感知模塊
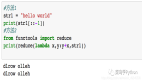
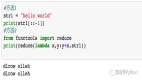
為了獲得用于預測的視覺特征,本文遵循他人的工作并且在 LSS 上構建,從周圍相機圖像中提取 BEV 特征網格。更準確的,針對每張圖像在時刻,然后應用一個共享的EfficientNet基干,提取透視特征,其中我們指定的第一個通道參數表示一個上下文特征,接著通道表示一個類別深度分布。一個3D特征張量是由外積均值組成:
這個公式表示了上下文特征提升到不同深度,根據估計到的深度分布置信度。之后,每個相機特征分布圖,在每個時間戳被轉換到本體車輛中心坐標系統,同時利用對應相機的內參和外參。之后,將轉換后的特征沿著高度維度進行加權,得到全局的BEV狀態在時間戳,其中是狀態通道數量,是BEV狀態圖的網格尺度。最后,所有BEV狀態被統一到當前幀,然后如同FIERY一樣堆疊,因此表示當前全局狀態且獨立于本體車輛位置。
■4.2 多尺度預測模塊
在獲得對于過去上下文的一個緊湊表示之后,我們使用一個類似于U-Net的多尺度編解碼架構,以觀測到的BEV特征作為輸入,預測未來分割圖和向心后向流場,如圖3所示。為了獲得時空特征,本文僅用2D卷積進行處理,具體是將時間和特征維度壓縮進單個維度,生成一個輸入張量結果。編碼器首先按照空間尺度逐步對進行下采樣,得到一個多尺度BEV特征,其中。在一個中間預測階段,特征圖從映射到得到。最后,解碼器在輸入尺度重建未來BEV特征。
每個分支在監督下分別預測未來的分割圖或向心后流場,考慮到任務和監督的不同,我們對每個分支采用相同的架構,但不進行權重共享。與之前基于空間 LSTM 或空間 GRU 的工作相比,我們的架構只利用了2D卷積,在很大程度上緩解了空間 RNN 在解決長程時間依賴性方面的局限性。

▲圖4|任務相似度
■4.3 多任務設定
現有方法采用自下而上的流程,為每幀生成實例分割,然后根據前向流使用匈牙利匹配(HM)跨幀關聯實例。因此,在 BEV 中需要四個不同的頭部:語義分割、中心性、未來前向流和每像素向心偏移(圖1.a)。這就導致了多任務訓練帶來的模型冗余和不穩定性。通過比較,我們首先發現流量和向心偏移都是實例掩碼內的回歸任務(圖4.b),流量可以理解為運動偏移。
此外,這兩個量與中心度的結合分為兩個階段:
(1)向心偏移將像素分組到每幀中預測的實例中心,為像素分配實例 ID;
(2)流量用于匹配連續兩幀中的中心,進行實例 ID 關聯。
基于上述分析,我們可以直觀地使用統一的表示方法來解決這兩項任務。
總之,我們的網絡僅產生兩個輸出:語義分割圖,以及向心后向流。我們使用top-k交叉熵,且k=25%作為分割損失,以及一個平滑距離作為流損失,整體的損失函數表示如下:
■4.4 實例關聯

▲圖5|實例匹配
關于實例預測,現有方法使用前向流將實例中心投射到下一幀,然后使用匈牙利匹配法(Hungarian Matching)匹配最近的代理中心,如圖5.a 所示。因此,只有位于物體中心的流向量才會被用于運動預測。這種方法有兩個缺點:首先,沒有考慮物體的旋轉;其次,單個位移矢量比覆蓋整個實例的多個位移矢量更容易出錯。在實踐中,這可能會導致投影實例重疊,從而導致 ID 分配錯誤。在較長的預測范圍內,這一點對于距離較近的物體尤為明顯。
利用我們的后向心流,我們進一步提出了基于經變的像素級關聯來解決上述問題。圖 5.b 展示了我們的關聯方法。對于每個前景網格單元,該操作直接將實例 ID 從上一幀中位于流矢量目的地的像素傳播到當前幀。使用這種方法,每個像素的實例 ID 都是單獨分配的,從而產生像素級關聯。
與實例級關聯相比,我們的方法可以容忍更嚴重的流量預測誤差,因為真實中心周圍的相鄰網格單元傾向于共享相同的標識,而誤差往往發生在單個外圍像素上。此外,通過使用后向流量扭曲,可以將多個未來位置與前一幀中的一個像素相關聯,這有利于多模態未來預測。
05 實驗驗證
■5.1 實驗設定
· 數據集:
我們在 NuScenes 數據集上對我們的方法進行評估,并將其與最先進的框架進行比較,這是一個廣泛用于自動駕駛感知和預測的公共數據集。該數據集包含從波士頓和新加坡收集的 1000 個駕駛場景,分為訓練集、驗證集和測試集,分別有 750、150 和 150 個場景。每個場景由 20 秒的交通數據組成,并以 2 Hz 的頻率標注語義注釋。
· 實施細節
我們沿用了現有研究的設置,即使用過去 1 秒(包括當前幀)對應的 3 個幀的信息來預測未來 2 秒對應的 4 個幀的語義分割、流量和實例運動。為了評估模型在不同感知范圍內的性能,采用了兩種空間分辨率:
(1)100 米 ×100 米區域,分辨率為 0.5 米(長);
(2)30 米 ×30 米區域,分辨率為 0.15 米(短)。
使用學習率為 3 × 10 -4 的 Adam 優化器,端到端框架在 4 個配備 16 GB 內存的 Tesla V100 GPU 上進行了20 次訓練,批量大小為 8。我們的實現基于 FIERY 的代碼。
· 指標
我們沿用了 FIERY 的評估程序。為了評估分割的準確性,我們使用“交集大于聯合”(Intersection-over-Union,IoU)作為分割質量的評估指標。
· 基準方法
我們將 PowerBEV 與三種最先進的方法 FIERY、Stretch-BEV 和 BEVerse進行了比較。FIERY 和 StretchBEV 的實驗設置與我們的工作相同,只是批量更大,為 12 批,使用 4 個 Tesla V100 GPU,每個GPU 有 32GB 內存。BEVerse 將骨干系統升級為更先進的 SwinTransformer,將圖像輸入大小大幅增加到 704 × 256,批量大小增加到 32,使用32 個 NVIDIA GeForceRTX 3090 GPU 訓練端到端模型。為了證明我們框架的有效性,我們故意不使用像 BEVerse 那樣的大型模型或大尺寸圖像,而是在 FLOPs 和 GPU 內存使用量方面將自己限制在FIERY 設置中,以便進行公平的比較。
■5.2 實驗結果
(1)量化結果
我們首先在表 1 中比較了我們的方法與基準框架的性能。我們還將 FIERY 與我們提出的標簽生成方法(參見第 4.1 節)進行了比較,結果發現我們在遠距離領域的性能有所提高,這對自動駕駛汽車的安全性至關重要。

▲表1|實例預測對比結果
如表2所示,我們改變了額外訓練目標的數量和類型。只有兩個頭部的方法(模型 [D])比所有其他變體的表現都要好。增加中心點(模型 [B])或偏移點(模型 [C])會對各種指標產生負面影響。

▲表2|不同預測頭對比結果
從表 3 的上半部分可以看出,我們的方法(模型 [F])在 IoU 和 VPQ 方面都優于基于 HM 的實例級關聯(模型 [E])。

▲表3|PowerBEV與HM的對比結果
(2)定性結果
如圖6所示,該結果展示了在三個典型駕駛場景中與 FIERY 的比較:動態交通密集的城市場景、靜態車輛眾多的停車場和雨天場景。在最常見的密集交通場景中,我們的方法提供了更精確、更可靠的軌跡預測,這一點在第一個例子中尤為明顯,即車輛在本體車輛左側拐入小路。

▲圖6|實例預測示意圖
06 結語
在這項工作中,我們提出了一個新穎的框架 POWERBEV,用于預測 BEV 中的未來實例。我們的方法采用并行方案,利用2D網絡(2D-CNNs)僅預測語義分割和向心后向流。此外,它還采用了一種新穎的后處理方法,能更好地處理多模態未來運動,在 NuScenes 基準中實現了最先進的實例預測性能。我們提供了詳盡的消融研究,對我們的方法進行了分析,并展示了其有效性。實驗證實,POWERBEV 比以前的方法更輕便,但性能有所提高。因此,我們相信這種方法可以成為 BEV 實例預測的新設計范例。

原文鏈接:https://mp.weixin.qq.com/s/KpJ9SsfkdR5vpawz6suvFQ