













譯者 | 陳峻
審校 | 重樓
現(xiàn)如今,像ChatGPT、以及phind之類基于AI的聊天機(jī)器人,已經(jīng)能夠?yàn)槲覀兩畹姆椒矫婷嫣峁└鞣N幫助了。但是,您可能并不總是希望由外部應(yīng)用程序來處理您提出的問題以及敏感數(shù)據(jù)。尤其是在一些平臺上,您與AI的互動,很可能會被后臺人工監(jiān)控,甚至被用于幫助訓(xùn)練其未來的模型。

對此,您自然而然地會想到下載大語言模型(LLM),并在自己的機(jī)器上運(yùn)行。如此,外部公司就無法訪問您的數(shù)據(jù)。同時,這也是嘗試一些新的專業(yè)模型的快速試錯方式。例如,Meta最近發(fā)布的針對編程領(lǐng)域的Code Llama 系列模型,以及針對文本到語音、以及語言翻譯的SeamlessM4T。
“在本地運(yùn)行LLM”這聽起來可能有些復(fù)雜,但是只要您擁有合適的工具,就會變得出奇簡單。由于許多模型對硬件的要求并不高,因此我在兩個系統(tǒng)上進(jìn)行了測試。它們分別是:配備了英特爾i9處理器、64GB內(nèi)存和Nvidia GeForce 12GB GPU的戴爾PC,以及配備了M1芯片,但只有16GB內(nèi)存的Mac。
需要注意的是,您可能需要花點(diǎn)時間研究、并關(guān)注開源模型的不斷迭代,以發(fā)現(xiàn)一款能在自己桌面硬件上運(yùn)行的、性能合適的模型。
1.使用GPT4All運(yùn)行本地聊天機(jī)器人
GPT4All提供了Windows、macOS和Ubuntu版本桌面客戶端的下載,以及在系統(tǒng)上運(yùn)行不同模型的選項(xiàng)。總的說來,其設(shè)置并不復(fù)雜。
首次在打開GPT4All桌面應(yīng)用時,您將看到約10個(截至本文撰寫時)可下載到本地運(yùn)行的模型選項(xiàng),其中就包含了來自Meta AI的模型Llama-2-7B chat。如果您有API密鑰的話,也可以設(shè)置OpenAI的GPT-3.5和GPT-4(如果您有訪問權(quán)限的話)為非本地使用。
上圖為GPT4All的模型下載界面部分。在我打開該應(yīng)用時,事先下載的模型就自動出現(xiàn)了。
在設(shè)置好模型后,簡潔易用的聊天機(jī)器人界面就出現(xiàn)了。說它便捷,是因?yàn)槲覀兛梢詫⒘奶靸?nèi)容復(fù)制到剪貼板上,以生成回復(fù)。
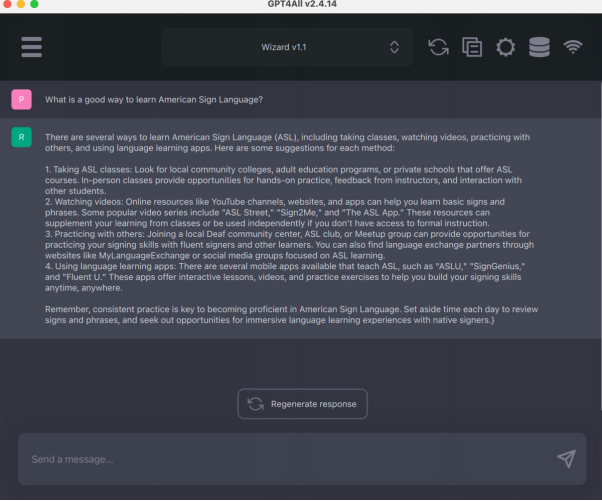
同時,它提供了一個新的測試版LocalDocs插件,方便您與自己的本地文檔進(jìn)行“聊天”。您可以在“設(shè)置”>“插件”選項(xiàng)卡中啟用它。在此,您會看到一個 “LocalDocs Plugin (BETA) Settings”標(biāo)題和一個在特定文件夾路徑下創(chuàng)建集合的選項(xiàng)。當(dāng)然,該插件仍在開發(fā)中,其相關(guān)文檔聲稱,這是一個有趣的功能,并會隨著開源模型功能的不斷完善,而得到持續(xù)改進(jìn)。
除了聊天機(jī)器人應(yīng)用,GPT4All也綁定了Python、Node和命令行界面(CLI)。同時,GPT4All還有一個服務(wù)器模式,方便您可以通過結(jié)構(gòu)類似OpenAI的HTTP API,與本地LLM進(jìn)行交互。可見,其目標(biāo)是讓您只需修改幾行代碼,就能將本地LLM換成OpenAI的LLM。
2.命令行模式下的LLM
由Simon Willison提供的LLM是我見過的,這是在本地計算機(jī)上下載和使用開源LLM的最簡單方法之一。雖然運(yùn)行它需要安裝Python,但您不需要接觸任何Python代碼。如果您使用的是Mac并安裝了Homebrew的話,只需運(yùn)行如下命令:
brew install llm如果您使用的是Windows系統(tǒng),請安裝Python庫,并輸入:
pip install llmLLM默認(rèn)會使用OpenAI模型,但是您可以使用插件在本地運(yùn)行其他模型。例如,如果您安裝了GPT4All插件,就可以訪問GPT4All中的其他本地模型。此外,llama還有MLC項(xiàng)目、MPT-30B、以及其他遠(yuǎn)程模型的插件。
請使用llm install model-name的格式,在命令行安裝插件。例如:
llm install llm-gpt4all接著,您可以使用命令llm models list,查看所有可用的遠(yuǎn)程或已安裝的模型。如下列表所示,其中還包含了每個型號的簡要信息。
您可以通過使用以下語法,向本地LLM發(fā)送查詢請求:
llm -m the-model-name "Your query"接著,我向它提出了一個類似ChatGPT的問題,但并沒有發(fā)出單獨(dú)的命令來下載模型:
llm -m ggml-model-gpt4all-falcon-q4_0 "Tell me a joke about computer programming"值得一提的是,如果本地系統(tǒng)中不存在GPT4All模型的話,LLM工具會在運(yùn)行查詢之前,自動為您下載。而且,在下載模型的過程中,您會在終端上看到如下的進(jìn)度條。

模型給出的笑話是:“程序員為什么要關(guān)掉電腦?因?yàn)樗肟纯措娔X是否還在工作!”這證明交互已成功進(jìn)行。如果您覺得該結(jié)果不盡如人意的話,那是因?yàn)槟P捅旧怼⒒蚴怯脩籼崾拘畔⒉蛔悖⒎?/span>LLM工具。
同時,您也可以在LLM中為模型設(shè)置別名,以便用更簡短的名稱來對其進(jìn)行引用:
llm aliases set falconggml-model-gpt4all-falcon-q4_0完成后,您可以通過輸入:llm aliases,來查看所有可用的別名。
相比之下,用于Meta Llama模型的LLM插件需要比GPT4All更多的設(shè)置。您可以通過鏈接https://github.com/simonw/llm-llama-cpp,在LLM插件的GitHub庫閱讀詳情。值得注意的是,通用的llama-2-7b-chat雖然能夠在我的Mac上運(yùn)行,但是它與GPT4All模型相比,運(yùn)行更慢。
當(dāng)然,LLM還具有其他功能,例如:參數(shù)標(biāo)志可以讓您從之前的聊天處繼續(xù)進(jìn)行,以及在Python腳本中使用。9月初,該應(yīng)用獲得了生成式文本嵌入工具,即文本含義的數(shù)字表示,可用于相關(guān)文檔的搜索。您可以通過訪問LLM網(wǎng)站,了解更多相關(guān)信息。
3.Mac上的Llama模型:Ollama
Ollama是一種比LLM更容易下載和運(yùn)行模型的方法,但它的局限性也更大。目前,它有macOS和Linux版本,其Windows版本即將被推出。
如上圖所示,通過幾步點(diǎn)擊即可完成安裝。雖然Ollama是一個命令行工具,但它也只有一個語法命令:ollama run model-name。與LLM類似,如果系統(tǒng)中還沒有所需的模型,它將自動進(jìn)行下載。
您可以在https://ollama.ai/library網(wǎng)站上,查看到可用模型的列表。截至本文撰寫之時,其中已包含了:通用Llama 2、Code Llama、DeepSE針對某些編程任務(wù)進(jìn)行過微調(diào)的CodeUp,以及針對醫(yī)學(xué)問答進(jìn)行過微調(diào)的medllama2等,多個基于Llama的模型版本。
Ollama在GitHub代碼庫中的 README列出了各種型號與規(guī)格,并建議“若要運(yùn)行3B型號,至少需要8GB內(nèi)存;若要運(yùn)行7B型號,至少需要16GB內(nèi)存;若要運(yùn)行13B型號,至少需要32GB內(nèi)存”。在我的16GB內(nèi)存Mac上,7B Code Llama的運(yùn)行速度就特別快。在專業(yè)方面,它可以回答有關(guān)bash/zshshell命令,以及Python和JavaScript等編程語言的問題。
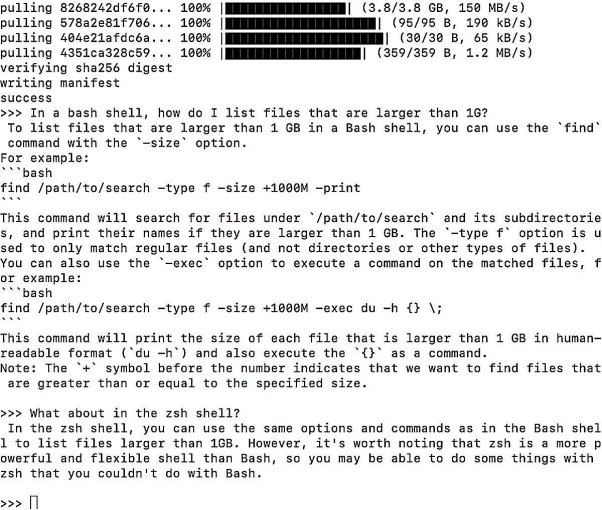
上圖展示了在Ollama終端窗口中運(yùn)行Code Llama的效果。例如,對于一個R代碼問題:“請為一個ggplot2條形圖編寫 R 代碼,其中條形圖的顏色為鋼藍(lán)色"。許多較大的模型都無法完整回答,而Code Llama雖然是該系列中最小的模型,但是其回答相當(dāng)出色。其交付出的代碼基本正確,只是其中有兩行代碼中多了兩個小括號,這在集成開發(fā)環(huán)境(IDE)中很容易被發(fā)現(xiàn)。
Ollama還有一些附加功能,包括:與LangChain的集成(https://www.infoworld.com/article/3705097/a-brief-guide-to-langchain-for-software-developers.html)和與PrivateGPT一起運(yùn)行的功能。當(dāng)然,如果您不去查看其GitHub軟件庫的教程頁面(https://github.com/jmorganca/ollama/blob/main/docs/tutorials.md)的話,這些功能可能并不明顯。
4.與自己的文件聊天:h2oGPT
深耕自動化機(jī)器學(xué)習(xí)領(lǐng)域多年的H2O.ai,已進(jìn)入了聊天LLM賽道。其h2oGPT聊天桌面應(yīng)用測試版,非常易于新手的安裝與使用。
為了熟悉其界面,您可以訪問https://gpt.h2o.ai/網(wǎng)站上的演示版本(注意,并非本地系統(tǒng)的LLM)。而為了獲取其本地版本,您需要克隆其GitHub庫,創(chuàng)建并激活Python虛擬環(huán)境,然后運(yùn)行README文件中的五行代碼。根據(jù)文檔的相關(guān)介紹,運(yùn)行結(jié)果會給您提供“有限的文檔Q/A功能”和Meta的Llama模型。
在運(yùn)行了如下代碼后,您就可以在http://localhost:7860處下載Llama模型版本和應(yīng)用了。
python generate.py --base_model='llama' --prompt_type=llama2無需添加自己的文件,您就可以將該應(yīng)用當(dāng)作普通聊天機(jī)器人使用。當(dāng)然,您也可以上傳一些文件,根據(jù)文件內(nèi)容進(jìn)行提問。其兼容的文件格式包括:PDF、Excel、CSV、Word、text、以及markdown等。上圖展示的是本地LLaMa模型根據(jù)VS Code文檔,來回答問題的截圖。
h2oGPT測試程序在我的16GB Mac上運(yùn)行良好,不過它不如帶有付費(fèi)GPT-4的ChatGPT。此外,如下圖所示,h2oGPT的用戶界面也提供了一個專家(Expert)選項(xiàng)卡,為專業(yè)用戶提供了大量配置、以及改進(jìn)結(jié)果的選項(xiàng)。
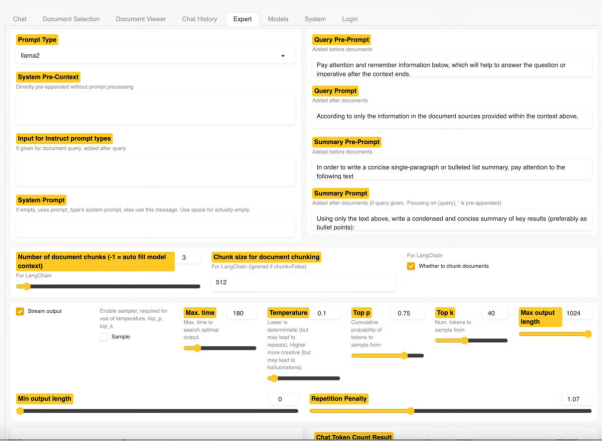
如果您希望對應(yīng)用有更多的控制,并能夠選擇更多的模型,那么可以下載完整版的應(yīng)用。其README提供了在Windows、macOS和Linux上安裝的不同說明。當(dāng)然,您也要顧及有限的硬件。事實(shí)證明,我現(xiàn)有的GPU,不足以運(yùn)行一個相當(dāng)大的模型。
5.能與數(shù)據(jù)進(jìn)行簡單但緩慢聊天的PrivateGPT
PrivateGPT可以讓您使用自然語言查詢自己的文檔,并獲得生成式AI的響應(yīng)。該應(yīng)用的文檔可以包括幾十種不同的格式。其README能夠保證“100%的私密,任何數(shù)據(jù)都不會離開您的運(yùn)行環(huán)境。您可以在沒有互聯(lián)網(wǎng)連接的情況下,輸入文檔并提出問題。”
PrivateGPT會通過腳本來接收數(shù)據(jù)文件,將其分割成不同的塊,以創(chuàng)建“嵌入”(即:文本含義的數(shù)字表示),并將這些嵌入存儲在本地的Chrome向量中。當(dāng)您提出問題時,應(yīng)用就會搜索相關(guān)文檔,將其發(fā)送給LLM,以生成答案。
如果您熟悉Python、以及如何建立Python項(xiàng)目的話,您可以通過鏈接--https://github.com/imartinez/privateGPT,克隆一套完整的PrivateGPT庫,并在本地運(yùn)行之。當(dāng)然,如果您對Python不甚了解,則可以參考Iván Martínez在一次研討會上建立的簡化版項(xiàng)目,它的設(shè)置要簡單得多。其README 文件包含了詳細(xì)的說明。雖然該庫自帶的source_documents文件夾中包含了大量Penpot(譯者注:一款面向跨域團(tuán)隊(duì)的開源設(shè)計和原型制作工具)文檔,但是您完全可以將其刪除掉,并添加自己的文檔。
不過,PrivateGPT的文檔也警告道,它并不適合用于生產(chǎn)環(huán)境。畢竟一旦它在本地運(yùn)行時,速度相對較慢。
6.本地LLM的更多途徑
其實(shí),在本地運(yùn)行LLM的方法不止上述五種。不過其他桌面級應(yīng)用往往需要從頭開始編寫腳本,并存在著不同程度的設(shè)置復(fù)雜性。
例如:PrivateGPT的衍生產(chǎn)品--LocalGPT就包含了更多的型號選項(xiàng),并提供了詳細(xì)說明和操作視頻。雖然人們對其安裝和設(shè)置的簡單程度眾說紛紜,但是它與PrivateGPT一樣,在對應(yīng)的文檔中也警告了“僅在CPU環(huán)境中運(yùn)行速度會很慢”。
我試用過的另一款桌面應(yīng)用是LM Studio。它不但提供了簡單易用的聊天界面,而且給用戶更多的模型選擇自主權(quán)。其中,Hugging Face Hub是LM Studio中模型的主要來源,它擁有大量可供下載的模型。
如下圖所示,LM Studio會提供一個漂亮、簡潔的界面。不過截至本文撰寫時,其用戶界面尚不能提供LLM的內(nèi)置選項(xiàng),以運(yùn)行用戶自己的數(shù)據(jù)。
正如其參考文檔提到的,它帶有一個內(nèi)置的服務(wù)器,可以“作為OpenAI API的直接替代”,因此那些通過API調(diào)用OpenAI模型所編寫出的代碼,將能夠在您所選擇的本地模型上運(yùn)行。
由于LM Studio的代碼并非由GitHub所提供,因此它也會與h2oGPT一樣,在Windows上安裝時,會彈出:“這是一款未經(jīng)驗(yàn)證的應(yīng)用”的警告。
除了通過h2oGPT等應(yīng)用,利用預(yù)建模(pre-built model)的下載界面,您也可以直接從Hugging Face處下載并運(yùn)行各種模型。這是一個人工智能平臺和社區(qū),其中包含了許多 LLM。此外,Hugging Face還提供了一些關(guān)于如何在本地安裝和運(yùn)行可用模型的文檔,具體請參考--https://huggingface.co/docs/transformers/installation。
而另一種流行的方法是在LangChain中下載并在本地使用LLM。這是一個用于創(chuàng)建端到端生成式AI應(yīng)用的框架。您既可以通過鏈接--https://www.infoworld.com/article/3705097/a-brief-guide-to-langchain-for-software-developers.html,了解LangChain的基礎(chǔ)知識;又可以通過https://python.langchain.com/docs/integrations/llms/huggingface_pipelines,查看有關(guān)Hugging Face本地管道的相關(guān)內(nèi)容。
此外,OpenLLM也是另一個強(qiáng)大的獨(dú)立平臺,可以幫助開發(fā)者將基于LLM的應(yīng)用部署到生產(chǎn)環(huán)境中。
譯者介紹
陳峻(Julian Chen),51CTO社區(qū)編輯,具有十多年的IT項(xiàng)目實(shí)施經(jīng)驗(yàn),善于對內(nèi)外部資源與風(fēng)險實(shí)施管控,專注傳播網(wǎng)絡(luò)與信息安全知識與經(jīng)驗(yàn)。
原文標(biāo)題:5 easy ways to run an LLM locally,作者:Sharon Machlis



























