ChatGPT能力退化惹爭議 AIGC應用還值得信任嗎?

斯坦福大學和加州大學伯克利分校(UCLA)研究人員的一項新研究提供了一些證據,證明這些大型語言模型(LLM)的行為已經具有“實質性的漂移”——但并不一定等于能力退化。
這一發現對用戶在ChatGPT等黑盒人工智能系統上構建應用的風險提出了警告,即隨著時間的推移,這些應用可能會產生不一致或不可預測的結果。背后原因在于:GPT等模型的訓練和更新方式缺乏透明度,因此無法預測或解釋其性能的變化。
用戶抱怨ChatGPT性能退化
早在今年5月,就有用戶就在OpenAI論壇上抱怨GPT-4很難做到它以前做得很好的事情。一些用戶不僅對性能下降感到不滿,而且對OpenAI缺乏響應和解釋感到不滿。
據《商業內幕》在7月12日報道,與之前的推理能力和其他輸出相比,用戶認為GPT-4變得“更懶”或“更笨”。在OpenAI沒有做出回應的情況下,行業專家開始猜測或探索GPT-4性能下降的原因。
一些人認為OpenAI在API背后使用了更小的模型,以降低運行ChatGPT的成本。其他人推測,該公司正在運行一種混合專家(MOE)方法,采用幾個小型的專業模型取代一個通用的LLM。
面對種種質疑,OpenAI否認了故意讓GPT-4變笨的說法。OpenAI產品副總裁Peter Welinder在推特上寫道:“恰恰相反:我們讓每一個新版本都比之前的版本更加智能。目前的假設是:當你大量使用它時,你就會開始注意到以前沒有看到的問題。”
頂級大學測試ChatGPT表現
為了驗證ChatGPT的行為如何隨著時間的推移而變化,斯坦福大學和UCLA的研究人員分別在2023年3月和6月測試了兩個版本的GPT-3.5和GPT-4。
他們在四個常見的基準任務上評估了這些模型:數學問題、回答敏感問題、代碼生成和視覺推理。這些是評估LLM經常使用的多樣化任務,而且它們相對客觀,因此易于評估。
研究人員使用了兩組指標來評估這兩個模型的性能。主要的指標特定于任務(例如,數學的準確性以及編碼的直接執行)。他們還跟蹤了冗長度(輸出的長度)和重疊度(兩個LLM版本的答案之間的相似程度)。
3-6月ChatGPT表現確實在下滑
對于數學問題,研究人員使用了“思維鏈”提示,通常用于激發LLM的推理能力。他們的發現顯示了模型性能的顯著變化:從3月到6月,GPT-4的準確率從97.6%下降到2.4%,而其響應冗長度下降了90%以上。GPT-3.5表現出相反的趨勢,準確率從7.4%上升到86.8%,冗長度增加了40%。
研究人員指出,“這一有趣的現象表明,由于LLM的性能漂移,采用相同的提示方法,即使是那些被廣泛采用的方法(例如思維鏈),也可能導致顯著不同的性能。”
在回答敏感問題時,對LLM進行評估的標準是它們回答有爭議問題的頻率。從3月到6月,GPT-4的直接回答率從21%下降到5%,這表明這個模型變得更加保守。與此同時,GPT-3.5的直接回答率從2%上升到8%。與3月的版本相比,這兩種模型在6月份拒絕不恰當的問題時提供的解釋也更少。
研究人員寫道:“這些LLM服務可能變得更加保守,但也減少了拒絕回答某些問題的理由。”
在代碼生成過程中,研究人員通過將LLM的輸出提交給運行和評估代碼的在線裁判來測試它們是否可直接執行。結果發現,在3月,5 0%以上的GPT-4輸出是可直接執行的,但在6月只有10%。對于ChatGPT 3.5,可執行輸出從3月的22%下降到6月的2%。6月的版本經常在代碼片段周圍添加不可執行的序列。
研究人員警告說:“當LLM生成的代碼在更大的軟件管道中使用時,要確定這一點尤其具有挑戰性。”
對于視覺推理,研究人員對來自抽象推理語料庫(ARC)數據集的示例子集的模型進行了評估。ARC是一個視覺謎題的集合,用于測試模型推斷抽象規則的能力。他們注意到GPT-4和GPT-3.5的性能都有輕微的改善。但總體性能仍然較低,GPT-4為27.4%,GPT-3.5為12.2%。然而,6月版本的GPT-4在3月正確回答的一些問題上出現了錯誤。
研究人員寫道:“這凸顯了細粒度漂移監測的必要性,特別是在關鍵應用中。”
ChatGPT性能退化可能存在誤解
在這篇論文發表之后,普林斯頓大學的計算機科學家、教授Arvind Narayanan和計算機科學家Sayash Kapoor認為,一些媒體誤解了這一論文的結果,他們認為GPT-4已經變得更糟。
兩人在一篇文章中指出,“不幸的是,這是媒體對于論文結果的過度簡化。雖然研究結果很有趣,但其中一些方法值得懷疑。”
例如,評估中使用的所有500個數學問題都是“數字X是質數嗎?”而數據集中的所有的數字都是質數。3月版本的GPT-4幾乎總是猜測這個數是質數,而6月的版本幾乎總是猜測它是合數。
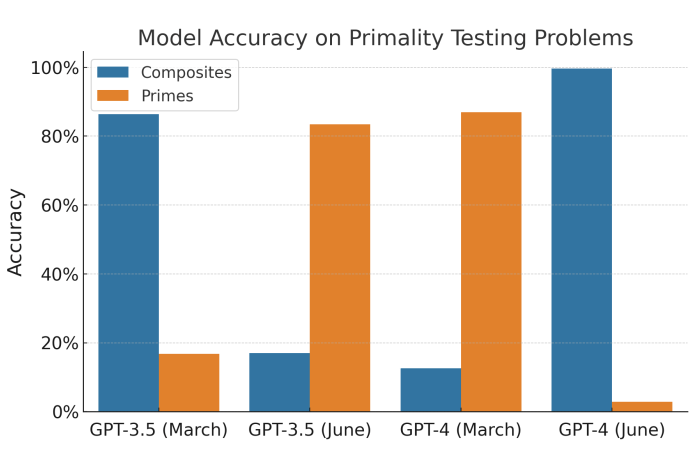
Narayanan和Kapoor在文中寫道:“論文的作者將這種情況解釋為性能的大幅下降,因為他們只測試了質數。當GPT-4在500個合數進行測試時,這種性能的下降就消失了。”
總而言之,Narayanan和Kapoor認為,ChatGPT的行為會改變,但這并不一定意味著它的能力下降了。
ChatGPT類AI應用還能信任嗎?
雖然這篇論文的發現并不一定表明這些模型變得更糟,但確實證實了它們的行為已經改變。
研究人員據此得出結論,GPT-3.5和GPT-4行為的變化凸顯了持續評估和評估LLM在生產應用中的行為的必要性。當我們構建使用LLM作為組件的軟件系統時,需要開發新的開發實踐和工作流程來確保可靠性和責任。
通過公共API使用LLM需要新的軟件開發實踐和工作流程。對于使用LLM服務作為其持續工作流程組成部分的用戶和公司,研究人員建議他們應該實施持續的監控分析。
這一研究結果還強調,在訓練和調整LLM的數據和方法方面需要提高透明度。如果沒有這樣的透明性,在它們之上構建穩定的應用就會變得非常困難。