基于信息論的校準技術,CML讓多模態機器學習更可靠
多模態機器學習在各種場景下都取得了令人矚目的進展。然而,多模態學習模型的可靠性尚缺乏深入研究。「信息是消除的不確定性」,多模態機器學習的初衷與這是一致的——增加的模態可以使得預測更為準確和可靠。然而,最近發表于 ICML2023 的論文《Calibrating Multimodal Learning》發現當前多模態學習方法違法了這一可靠性假設,并做出了詳細分析和矯正。
 圖片
圖片
- 論文 Arxiv:https://arxiv.org/abs/2306.01265
- 代碼 GitHub:https://github.com/QingyangZhang/CML
當前的多模態分類方法存在不可靠的置信度,即當部分模態被移除時,模型可能產生更高的置信度,違反了信息論中 「信息是消除的不確定性」這一基本原理。針對此問題,本文提出校準多模態學習(Calibrating Multimodal Learning)方法。該方法可以部署到不同的多模態學習范式中,提升多模態學習模型的合理性和可信性。
 圖片
圖片
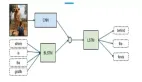
該工作指出,當前多模態學習方法存在不可靠的預測置信度問題,現有多模態機器學習模型傾向于依賴部分模態來估計置信度。特別地,研究發現,當前模型估計的置信度在某些模態被損壞時反而會增加。為了解決這個不合理問題,作者提出了一個直觀的多模態學習原則:當移除模態時,模型預測置信度不應增加。但是,當前的模型卻傾向于相信部分模態,容易受到這個模態的影響,而不是公平地考慮所有模態。這進一步影響了模型的魯棒性,即當某些模態被損壞時,模型很容易受到影響。

為了解決上述問題,目前一些方法采用了現有的不確定性校準方法,例如 Temperature Scaling 或貝葉斯學習方法。這些方法可以構建比傳統訓練 / 推理方式更準確的置信度估計。但是,這些方法只是使最終融合結果的信心估計與正確率匹配,并沒有明確考慮模態信息量與信心之間的關系,因此,無法本質上提升多模態學習模型的可信性。
作者提出了一個新的正則化技術,稱為 “Calibrating Multimodal Learning (CML)”。該技術通過添加一項懲罰項來強制模型預測信心與信息量的匹配關系,以實現預測置信度和信息量之間的一致性。該技術基于一種自然的直覺,即當移除一個模態時,預測置信度應該降低(至少不應該增加),這可以內在地提高置信度校準。具體來說,提出了一種簡單的正則化項,通過對那些當移除一個模態時預測置信度會增加的樣本添加懲罰,來強制模型學習直觀的次序關系:


上面的約束為正則損失,當模態信息移除信心上升時作為懲罰出現。
實驗結果表明,CML 正則化可以顯著提高現有多模態學習方法的預測置信度的可靠性。此外,CML 還可以提高分類精度,并提高模型的魯棒性。

多模態機器學習在各種情境中取得了顯著的進展,但是多模態機器學習模型的可靠性仍然是一個需要解決的問題。本文通過廣泛的實證研究發現,當前多模態分類方法存在預測置信度不可靠的問題,違反了信息論原則。針對這一問題,研究人員提出了 CML 正則化技術,該技術可以靈活地部署到現有的模型,并在置信度校準、分類精度和模型魯棒性方面提高性能。相信這個新技術將在未來的多模態學習中發揮重要作用,提高機器學習的可靠性和實用性。