攜程分布式圖數(shù)據(jù)庫(kù)Nebula Graph運(yùn)維治理實(shí)踐
作者簡(jiǎn)介
Patrick Yu,攜程云原生研發(fā)專家,關(guān)注非關(guān)系型分布式數(shù)據(jù)存儲(chǔ)及相關(guān)技術(shù)。
一、背景
隨著互聯(lián)網(wǎng)世界產(chǎn)生的數(shù)據(jù)越來(lái)越多,數(shù)據(jù)之間的聯(lián)系越來(lái)越復(fù)雜層次越來(lái)越深,人們希望從這些紛亂復(fù)雜的數(shù)據(jù)中探索各種關(guān)聯(lián)的需求也在與日遞增。為了更有效地應(yīng)對(duì)這類(lèi)場(chǎng)景,圖技術(shù)受到了越來(lái)越多的關(guān)注及運(yùn)用。
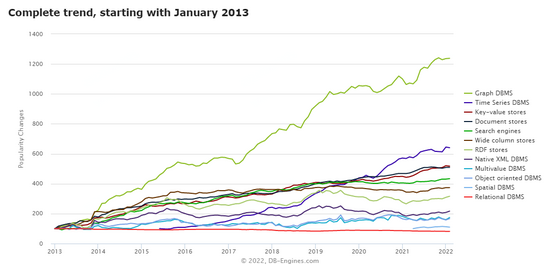
DB-ENGINES 趨勢(shì)報(bào)告顯示圖數(shù)據(jù)庫(kù)趨勢(shì)增長(zhǎng)遙遙領(lǐng)先
在攜程,很早就有一些業(yè)務(wù)嘗試了圖技術(shù),并將其運(yùn)用到生產(chǎn)中,以Neo4j和JanusGraph為主。2021年開(kāi)始,我們對(duì)圖數(shù)據(jù)庫(kù)進(jìn)行集中的運(yùn)維治理,期望規(guī)范業(yè)務(wù)的使用,并適配攜程已有的各種系統(tǒng),更好地服務(wù)業(yè)務(wù)方。經(jīng)過(guò)調(diào)研,我們選擇分布式圖數(shù)據(jù)庫(kù)Nebula Graph作為管理的對(duì)象,主要基于以下幾個(gè)因素考慮:
1)Nebula Graph開(kāi)源版本即擁有橫向擴(kuò)展能力,為大規(guī)模部署提供了基本條件;
2)使用自研的原生存儲(chǔ)層,相比JanusGraph這類(lèi)構(gòu)建在第三方存儲(chǔ)系統(tǒng)上的圖數(shù)據(jù)庫(kù),性能和資源使用效率上具有優(yōu)勢(shì);
3)支持兩種語(yǔ)言,尤其是兼容主流的圖技術(shù)語(yǔ)言Cypher,有助于用戶從其他使用Cypher語(yǔ)言的圖數(shù)據(jù)庫(kù)(例如Neo4j)中遷移;
4)擁有后發(fā)優(yōu)勢(shì)(2019起開(kāi)源),社區(qū)活躍,且主流的互聯(lián)網(wǎng)公司都有參與(騰訊,快手,美團(tuán),網(wǎng)易等);
5)使用技術(shù)主流,代碼清晰,技術(shù)債較少,適合二次開(kāi)發(fā);
二、Nebula Graph架構(gòu)及集群部署
Nebula Graph是一個(gè)分布式的計(jì)算存儲(chǔ)分離架構(gòu),如下圖:
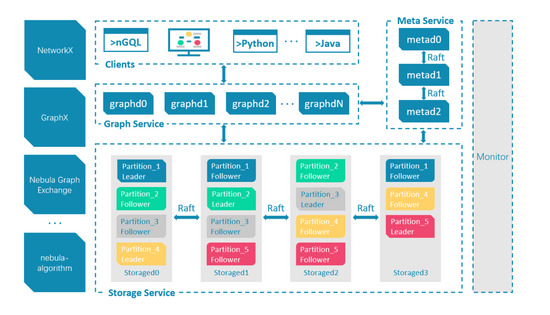
其主要由Graphd,Metad和Storaged三部分服務(wù)組成,分別負(fù)責(zé)計(jì)算,元數(shù)據(jù)存取,圖數(shù)據(jù)(點(diǎn),邊,標(biāo)簽等數(shù)據(jù))的存取。在攜程的網(wǎng)絡(luò)環(huán)境中,我們提供了三種部署方式來(lái)支撐業(yè)務(wù):
2.1 三機(jī)房部署
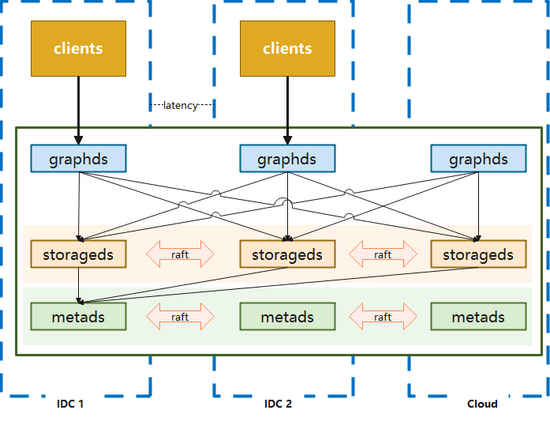
用于滿足一致性和容災(zāi)的要求,優(yōu)點(diǎn)是任意一個(gè)機(jī)房發(fā)生機(jī)房級(jí)別故障,集群仍然可以使用,適用于核心應(yīng)用。但缺點(diǎn)也是比較明顯的,數(shù)據(jù)通過(guò)raft協(xié)議進(jìn)行同步的時(shí)候,會(huì)遇到跨機(jī)房問(wèn)題,性能會(huì)受到影響。
2.2 單機(jī)房部署
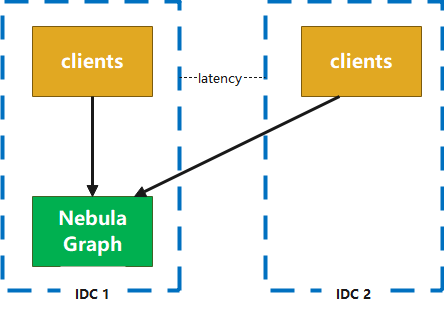
集群所有節(jié)點(diǎn)都在一個(gè)機(jī)房中,節(jié)點(diǎn)之間通訊可以避免跨機(jī)房問(wèn)題(應(yīng)用端與服務(wù)端之間仍然會(huì)存在跨機(jī)房調(diào)用),由于機(jī)房整體出現(xiàn)問(wèn)題時(shí)該部署模式的系統(tǒng)將無(wú)法使用,所以適用于非核心應(yīng)用進(jìn)行訪問(wèn)。
2.3 藍(lán)綠雙活部署
在實(shí)際使用中,以上兩種常規(guī)部署方式并不能滿足一些業(yè)務(wù)方的需求,比如性能要求較高的核心應(yīng)用,三機(jī)房的部署方式所帶來(lái)的網(wǎng)絡(luò)損耗可能會(huì)超出預(yù)期。根據(jù)攜程酒店某個(gè)業(yè)務(wù)場(chǎng)景真實(shí)測(cè)試數(shù)據(jù)來(lái)看,本地三機(jī)房的部署方式延遲要比單機(jī)房高50%+,但單機(jī)房部署無(wú)法抵抗單個(gè)IDC故障,此外還有用戶希望能存在類(lèi)似數(shù)據(jù)回滾的能力,以應(yīng)對(duì)應(yīng)用發(fā)布,集群版本升級(jí)可能導(dǎo)致的錯(cuò)誤。
考慮到使用圖數(shù)據(jù)庫(kù)的業(yè)務(wù)大多數(shù)據(jù)來(lái)自離線系統(tǒng),通過(guò)離線作業(yè)將數(shù)據(jù)導(dǎo)入到圖數(shù)據(jù)庫(kù)中,數(shù)據(jù)一致的要求并不高,在這種條件下使用藍(lán)綠部署能夠在災(zāi)備和性能上得到很好的滿足。
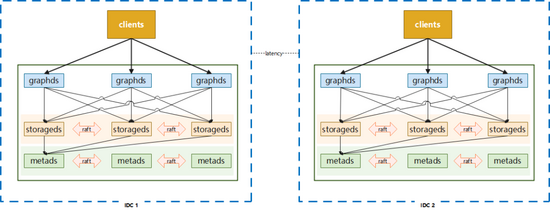
與此同時(shí)我們還增加了一些配套的輔助功能,比如:
分流:可以按比例分配機(jī)房的訪問(wèn),也可以主動(dòng)切斷對(duì)某個(gè)機(jī)房的流量訪問(wèn)
災(zāi)備:在發(fā)生機(jī)房級(jí)故障時(shí),可自動(dòng)切換讀訪問(wèn)的流量,寫(xiě)訪問(wèn)的流量切換則通過(guò)人工進(jìn)行操作
藍(lán)綠雙活方式是在性能、可用性、一致性上的一個(gè)折中的選擇,使用此方案時(shí)應(yīng)用端架構(gòu)也需要有更多的調(diào)整以配合數(shù)據(jù)的存取。
生產(chǎn)上的一個(gè)例子:

三機(jī)房情況

藍(lán)綠部署
三、中間件及運(yùn)維管理
我們基于k8s crd和operator來(lái)進(jìn)行Nebula Graph的部署,同時(shí)通過(guò)服務(wù)集成到現(xiàn)有的部署配置頁(yè)面和運(yùn)維管理頁(yè)面,來(lái)獲得對(duì)pod的執(zhí)行和遷移的控制能力。基于sidecar模式監(jiān)控收集Nebula Graph的核心指標(biāo)并通過(guò)telegraf發(fā)送到攜程自研的Hickwall集中展示,并設(shè)置告警等一系列相關(guān)工作。
此外我們集成了跨機(jī)房的域名分配功能,為節(jié)點(diǎn)自動(dòng)分配域名用于內(nèi)部訪問(wèn)(域名只用于集群內(nèi)部,集群與外部連通是通過(guò)ip直連的),這樣做是為了避免節(jié)點(diǎn)漂移造成ip變更,影響集群的可用性。
在客戶端上,相比原生客戶端,我們主要做了以下幾個(gè)改進(jìn)和優(yōu)化:
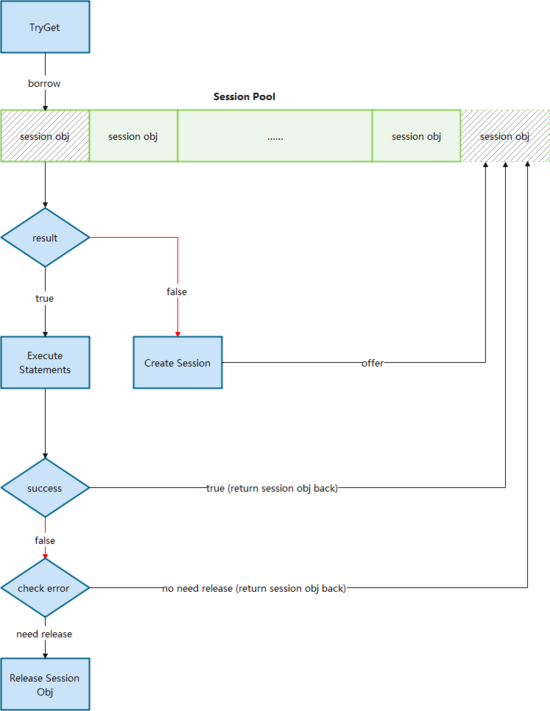
3.1 Session管理功能
原生客戶端Session管理比較弱,尤其是2.x早期幾個(gè)版本,多線程訪問(wèn)Session并不是線程安全的,Session過(guò)期或者失效都需要調(diào)用方來(lái)處理,不適合大規(guī)模使用。同時(shí)雖然官方客戶端創(chuàng)建的Session是可以復(fù)用的,并不需要release,官方也鼓勵(lì)用戶復(fù)用,但是卻沒(méi)有提供統(tǒng)一的Session管理功能來(lái)幫助用戶復(fù)用,因此我們?cè)黾恿薙ession Pool的概念來(lái)實(shí)現(xiàn)復(fù)用。
其本質(zhì)上是管理一個(gè)或多個(gè)Session Object Queue,通過(guò)borrow-and-return的方式(下圖),確保了一個(gè)Session在同一時(shí)間只會(huì)由一個(gè)執(zhí)行器在使用,避免了共用Session產(chǎn)生的問(wèn)題。同時(shí)通過(guò)對(duì)隊(duì)列的管理,我們可以進(jìn)行Session數(shù)量和版本的管理,比如預(yù)生成一定量的Session,或者在管理中心發(fā)出消息之后變更Session的數(shù)量或者訪問(wèn)的路由。
3.2 藍(lán)綠部署(包括讀寫(xiě)分離)
上面章節(jié)中介紹了藍(lán)綠部署,相應(yīng)的客戶端也需要改造以支持訪問(wèn)2個(gè)集群。由于生產(chǎn)中,讀和寫(xiě)的邏輯往往不同,比如讀操作希望可以由2個(gè)集群共同提供數(shù)據(jù),而寫(xiě)的時(shí)候只希望影響單邊,所以我們?cè)谶M(jìn)行藍(lán)綠處理的時(shí)候也增加了讀寫(xiě)分離(下圖)。
3.3 流量分配
如果要考慮到單邊切換以及讀寫(xiě)不同的路由策略,就需要增加流量分配功能。我們沒(méi)有采用攜程內(nèi)廣泛使用的Virtual IP作為訪問(wèn)路由,希望有更為強(qiáng)大的定制管理能力及更好的性能。
a)通過(guò)直連而不是Virtual IP中轉(zhuǎn)可以減少一次轉(zhuǎn)發(fā)的損耗
b)在維持長(zhǎng)連接的同時(shí)也能實(shí)現(xiàn)每次請(qǐng)求使用不同的鏈路,平攤graphd的訪問(wèn)壓力
c)完全自主控制路由,可以實(shí)現(xiàn)更為靈活的路由方案
d)當(dāng)存在節(jié)點(diǎn)無(wú)法訪問(wèn)的時(shí)候,客戶端可以自動(dòng)臨時(shí)排除有問(wèn)題的IP,在短時(shí)間內(nèi)避免再次使用。而如果使用Virtual IP的話,由于一個(gè)Virtual IP會(huì)對(duì)應(yīng)多個(gè)物理IP,就沒(méi)有辦法直接這樣操作。
通過(guò)構(gòu)造面向不同idc的Session Pool,并根據(jù)配置進(jìn)行權(quán)重輪詢,就可以達(dá)到按比例分配訪問(wèn)流量的目的(下圖)。
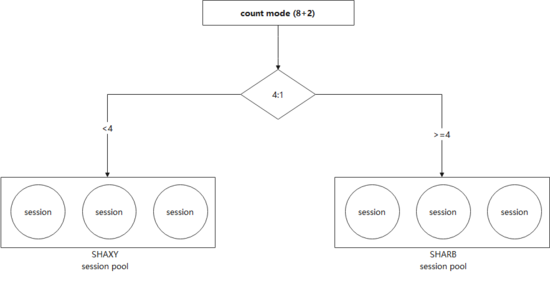
將流量分配集成進(jìn)藍(lán)綠模式,就基本實(shí)現(xiàn)了基本的客戶端改造(下圖)。
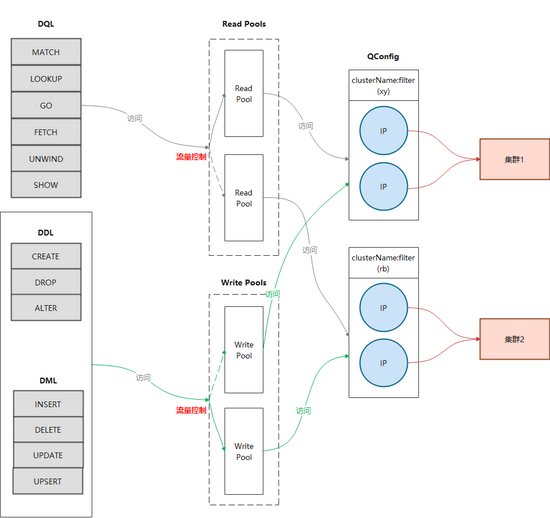
3.4 結(jié)構(gòu)化語(yǔ)句查詢
圖DSL目前主流的有兩種,Gremlin和Cypher,前者是過(guò)程式語(yǔ)言而后者是聲明式語(yǔ)言。Nebula Graph支持了openCypher(Cypher的開(kāi)源項(xiàng)目)語(yǔ)法和自己設(shè)計(jì)的nGQL原生語(yǔ)法,這兩種都是聲明式語(yǔ)言,在風(fēng)格上比較類(lèi)似SQL。盡管如此,對(duì)于一些較為簡(jiǎn)單的語(yǔ)句,類(lèi)似Gremlin風(fēng)格的過(guò)程式語(yǔ)法對(duì)用戶會(huì)更為友好,并且有利用監(jiān)控埋點(diǎn)。基于這個(gè)原因,我們封裝了一個(gè)過(guò)程式的語(yǔ)句生成器。
例如:
Cypher風(fēng)格 | MATCH (v:user{name:"XXX"})-[e:follow|:serve]->(v2) RETURN v2 AS Friends; |
新增的過(guò)程式風(fēng)格 | Builder.match() .vertex("v") .hasTag("user") .property("name", "XXX", DataType.String()) .edge("e", Direction.OUTGOING) .type("follow") .type("serve") .vertex("v2") .ret("v2", "Friends") |
四、系統(tǒng)調(diào)優(yōu)實(shí)踐
由于建模,使用場(chǎng)景,業(yè)務(wù)需求的差異,使用Nebula Graph的過(guò)程中所遇到的問(wèn)題很可能會(huì)完全不同,以下以攜程酒店信息圖譜線上具體的例子進(jìn)行說(shuō)明,在整個(gè)落地過(guò)程我們遇到的問(wèn)題及處理過(guò)程(文中以下內(nèi)容是基于Nebula Graph 2.6.1進(jìn)行的)。
關(guān)于酒店該業(yè)務(wù)的更多細(xì)節(jié),可以閱讀《 信息圖譜在攜程酒店的應(yīng)用 》這篇文章。
4.1 酒店集群不穩(wěn)定
起因是酒店應(yīng)用上線后發(fā)生了一次故障,大量的訪問(wèn)超時(shí),并伴隨著“The leader has changed”這樣的錯(cuò)誤信息。稍加排查,我們發(fā)現(xiàn)metad集群有問(wèn)題,metad0的local ip和metad_server_address的配置不一致,所以metad0實(shí)際上一直沒(méi)有工作。
但這本身并不會(huì)導(dǎo)致系統(tǒng)問(wèn)題,因?yàn)?節(jié)點(diǎn)部署,只需要2個(gè)節(jié)點(diǎn)工作即可,后來(lái)metad1容器又意外被漂移了,導(dǎo)致ip變更,這個(gè)時(shí)候?qū)嶋H上metad集群已經(jīng)無(wú)法工作(下圖),導(dǎo)致整個(gè)集群都受到了影響。

在處理完以上故障并重啟之后,整個(gè)系統(tǒng)卻并沒(méi)有恢復(fù)正常,cpu的使用率很高。此時(shí)外部應(yīng)用并沒(méi)有將流量接入進(jìn)來(lái),但整個(gè)metad集群內(nèi)部網(wǎng)絡(luò)流量卻很大,如下圖所示:
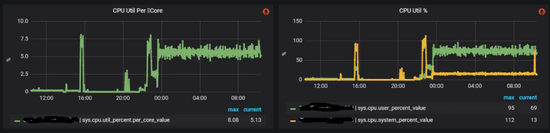
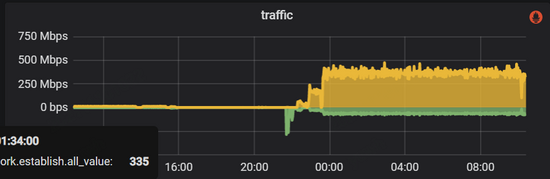
監(jiān)控顯示metad磁盤(pán)空間使用量很大,檢查下來(lái)WAL在不斷增加,說(shuō)明這些流量主要是數(shù)據(jù)的寫(xiě)入操作。我們打開(kāi)WAL數(shù)據(jù)的某幾個(gè)文件,其大部分都是Session的元數(shù)據(jù),因?yàn)镾ession信息是會(huì)在Nebula集群內(nèi)持久化的,所以考慮問(wèn)題可能出在這里。閱讀源碼我們注意到,graphd會(huì)從metad中同步所有的session信息,并在修改之后將數(shù)據(jù)再全部回寫(xiě)到metad中,所以如果流量都是session信息的話,那么問(wèn)題就可能:
a)Session沒(méi)有過(guò)期
b)創(chuàng)建了太多的Session
檢查發(fā)現(xiàn)該集群沒(méi)有配置超時(shí)時(shí)間, 所以我們修改以下配置來(lái)處理 這個(gè)問(wèn)題:
類(lèi)型 | 配置項(xiàng) | 原始值 | 修改值 | 說(shuō)明 |
Graphd | session_idle_timeout_secs | 默認(rèn)(0) | 86400 | 此配置控制session的過(guò)期,由于初始我們沒(méi)有設(shè)置這個(gè)參數(shù),這意味著session永遠(yuǎn)不會(huì)過(guò)期,這會(huì)導(dǎo)致過(guò)去訪問(wèn)過(guò)該graphd的session會(huì)永遠(yuǎn)存在于metad存儲(chǔ)層,造成session元數(shù)據(jù)累積。 |
session_reclaim_interval_secs | 默認(rèn)(10) | 30 | 原設(shè)置說(shuō)明每10s graphd會(huì)將session信息發(fā)送給metad持久化。這也會(huì)導(dǎo)致寫(xiě)入數(shù)據(jù)量過(guò)多。考慮到即使down機(jī)也只是損失部分的Session元數(shù)據(jù)更新,這些損失帶來(lái)的危害比較小,所以我們改成了30s以減少于metad之間同步元數(shù)據(jù)的次數(shù)。 | |
Metad | wal_ttl | 默認(rèn)(14400) | 3600 | wal用于記錄修改操作的,一般來(lái)說(shuō)是不需要保留太久的,況且nebula graph為了安全,都至少會(huì)為每個(gè)分片保留最后2個(gè)wal文件,所以減少ttl加快wal淘汰,將空間節(jié)約出來(lái) |
修改之后,metad的磁盤(pán)空間占用下降,同時(shí)通信流量和磁盤(pán)讀寫(xiě)也明顯下降(下圖):
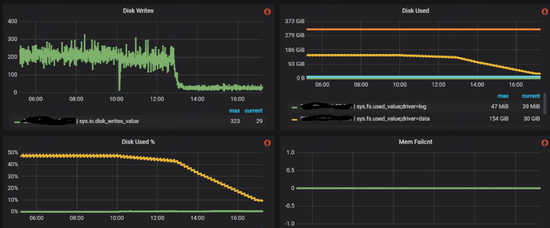
系統(tǒng)逐步恢復(fù)正常,但是還有一個(gè)問(wèn)題沒(méi)有解決,就是為什么有如此之多的session數(shù)據(jù)?查看應(yīng)用端日志,我們注意到session創(chuàng)建次數(shù)超乎尋常,如下圖所示:

通過(guò)日志發(fā)現(xiàn)是我們自己開(kāi)發(fā)的客戶端中的bug造成的。我們會(huì)在報(bào)錯(cuò)時(shí)讓客戶端釋放對(duì)應(yīng)的session,并重新創(chuàng)建,但由于系統(tǒng)抖動(dòng),這個(gè)行為造成了比較多的超時(shí),導(dǎo)致更多的session被釋放并重建,引起了惡性循環(huán)。針對(duì)這個(gè)問(wèn)題,對(duì)客戶端進(jìn)行了如下優(yōu)化:
修改 | |
1 | 將創(chuàng)建session行為由并發(fā)改為串行,每次只允許一個(gè)線程進(jìn)行創(chuàng)建工作,不參與創(chuàng)建的線程監(jiān)聽(tīng)session pool |
2 | 進(jìn)一步增強(qiáng)session的復(fù)用,當(dāng)session執(zhí)行失敗的時(shí)候,根據(jù)失敗原因來(lái)決定是否需要release。 原有的邏輯是一旦執(zhí)行失敗就release當(dāng)前session,但有些時(shí)候并非是session本身的問(wèn)題,比如超時(shí)時(shí)間過(guò)短,nGQL有錯(cuò)誤這些應(yīng)用層的情況也會(huì)導(dǎo)致執(zhí)行失敗,這個(gè)時(shí)候如果直接release,會(huì)導(dǎo)致session數(shù)量大幅度下降從而造成大量session創(chuàng)建。根據(jù)問(wèn)題合理的劃分錯(cuò)誤情況來(lái)進(jìn)行處理,可以最大程度保持session狀況的穩(wěn)定 |
3 | 增加預(yù)熱功能,根據(jù)配置提前創(chuàng)建好指定數(shù)量的session,以避免啟動(dòng)時(shí)集中創(chuàng)建session導(dǎo)致超時(shí) |
4.2 酒店集群存儲(chǔ)服務(wù)CPU使用率過(guò)高
酒店業(yè)務(wù)方在增加訪問(wèn)量的時(shí)候,每次到80%的時(shí)候集群中就有少數(shù)storaged不穩(wěn)定,cpu使用率突然暴漲,導(dǎo)致整個(gè)集群響應(yīng)增加,從而應(yīng)用端產(chǎn)生大量超時(shí)報(bào)錯(cuò),如下圖所示:
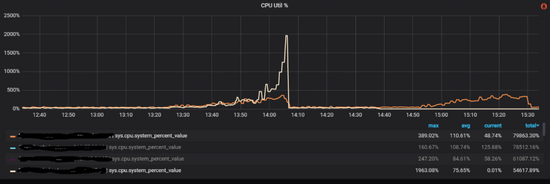
和酒店方排查下來(lái)初步懷疑是存在稠密點(diǎn)問(wèn)題(在圖論中,稠密點(diǎn)是指一個(gè)點(diǎn)有著極多的相鄰邊,相鄰邊可以是出邊或者是入邊),部分storaged被集中訪問(wèn)引起系統(tǒng)不穩(wěn)定。由于業(yè)務(wù)方強(qiáng)調(diào)稠密點(diǎn)是其業(yè)務(wù)場(chǎng)景難以避免的情況,我們決定采取一些調(diào)優(yōu)手段來(lái)緩解這個(gè)問(wèn)題。
1)嘗試通過(guò)Balance來(lái)分?jǐn)傇L問(wèn)壓力
回憶之前的官方架構(gòu)圖,數(shù)據(jù)在storaged中是分片的,且raft協(xié)議中只有l(wèi)eader才會(huì)處理請(qǐng)求,所以重新進(jìn)行數(shù)據(jù)平衡操作,是有可能將多個(gè)稠密點(diǎn)分?jǐn)偟讲煌姆?wù)上意減輕單一服務(wù)的壓力。同時(shí)我們對(duì)整個(gè)集群進(jìn)行compaction操作(由于Storaged內(nèi)部使用了RocksDB作為存儲(chǔ)引擎,數(shù)據(jù)是通過(guò)追加來(lái)進(jìn)行修改的,Compaction可以清楚過(guò)時(shí)的數(shù)據(jù),提高訪問(wèn)效率)。
操作之后集群的整體cpu是有一定的下降,同時(shí)服務(wù)的響應(yīng)速度也有小幅的提升,如下圖。
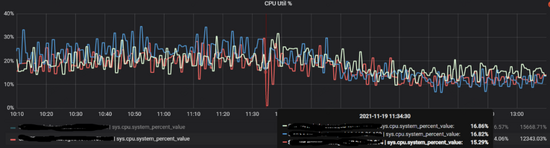
但在運(yùn)行一段時(shí)間之后仍然遇到了cpu突然增加的情況,稠密點(diǎn)顯然沒(méi)有被平衡掉,也說(shuō)明在分片這個(gè)層面是沒(méi)法緩解稠密點(diǎn)帶來(lái)的訪問(wèn)壓力的 。
2)嘗試通過(guò)配置緩解鎖競(jìng)爭(zhēng)
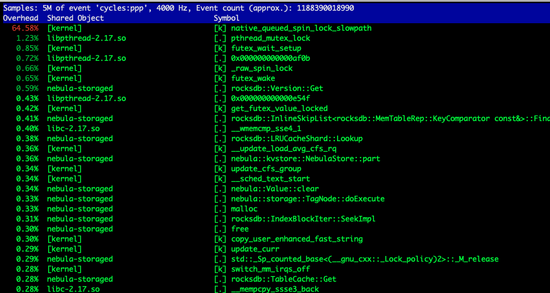
進(jìn)一步調(diào)研出現(xiàn)問(wèn)題的storaged的cpu的使用率,可以看到當(dāng)流量增加的時(shí)候,內(nèi)核占用的cpu非常高,如下圖所示:
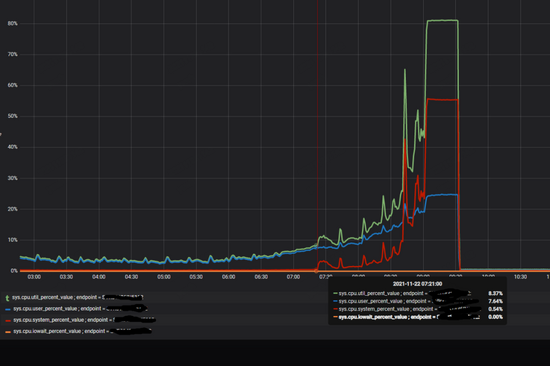
抓取perf看到,鎖競(jìng)爭(zhēng)比較激烈,即使在“正常”情況下,鎖的占比也很大,而在競(jìng)爭(zhēng)激烈的時(shí)候,出問(wèn)題的storaged服務(wù)上這個(gè)比例超過(guò)了50%。如下圖所示:
所以我們從減少?zèng)_突入手,對(duì)nebula graph集群主要做了如下改動(dòng):
類(lèi)型 | 配置項(xiàng) | 原始值 | 修改值 | 說(shuō)明 |
Storaged | rocksdb_block_cache | 默認(rèn)(4) | 8192 | block cache用緩存解壓縮之后的數(shù)據(jù),cache越大,數(shù)據(jù)淘汰情況越低,這樣就越可能更快的命中數(shù)據(jù),減少反復(fù)從page cache加載及depress的操作 |
enable_rocksdb_prefix_filtering | false | true | 在內(nèi)存足夠的情況下,我們打開(kāi)prefix過(guò)濾,是希望通過(guò)其通過(guò)前綴更快的定位到數(shù)據(jù),減少查詢非必要的數(shù)據(jù),減少數(shù)據(jù)競(jìng)爭(zhēng) | |
RocksDB | disable_auto_compactions | 默認(rèn) | false | 打開(kāi)自動(dòng)compaction,緩解因?yàn)閿?shù)據(jù)碎片造成的查詢cpu升高 |
write_buffer_size | 默認(rèn) | 134217728 | 將memtable設(shè)置為128MB,減少其flush的次數(shù) | |
max_background_compactions | 默認(rèn) | 4 | 控制后臺(tái)compactions的線程數(shù) |
重新上線之后,整個(gè)集群服務(wù)變得比較平滑,cpu的負(fù)載也比較低,正常情況下鎖競(jìng)爭(zhēng)也下降不少(下圖),酒店也成功的將流量推送到了100%。
但運(yùn)行了一段時(shí)間之后,我們?nèi)匀挥龅搅朔?wù)響應(yīng)突然變慢的情況,熱點(diǎn)訪問(wèn)帶來(lái)的壓力 的確超過(guò)了優(yōu)化帶來(lái)的提升。
3)嘗試減小鎖的顆粒度
考慮到在分片級(jí)別的balance不起作用,而cpu的上升主要是因?yàn)殒i競(jìng)爭(zhēng)造成的,那我們想到如果減小鎖的顆粒度,是不是就可以盡可能減小競(jìng)爭(zhēng)?RocksDB的LRUCache允許調(diào)整shared數(shù)量,我們對(duì)此進(jìn)行了修改:
版本 | LRUCache默認(rèn)分片數(shù) | 方式 |
2.5.0 | 2 8 | 修改代碼,將分片改成2 10 |
2.6.1及以上 | 2 8 | 通過(guò)配置cache_bucket_exp = 10,將分片數(shù)改為2 10 |
觀察下來(lái)效果不明顯,無(wú)法解決熱點(diǎn)競(jìng)爭(zhēng)導(dǎo)致的雪崩問(wèn)題。其本質(zhì)同balance操作一樣,只是粒度的大小的區(qū)別,在熱點(diǎn)非常集中的情況下,在數(shù)據(jù)層面進(jìn)行處理是走不通的。
4)嘗試使用ClockCache
競(jìng)爭(zhēng)的鎖來(lái)源是block cache造成的。nebula storaged使用rocksdb作為存儲(chǔ),其使用的是LRUCache作為block cache等一系列cache的存儲(chǔ)模塊,LRUCache在任何類(lèi)型的訪問(wèn)的時(shí)候需要需要加鎖操作,以進(jìn)行一些LRU信息的更新,排序的調(diào)整及數(shù)據(jù)的淘汰,存在吞吐量的限制。
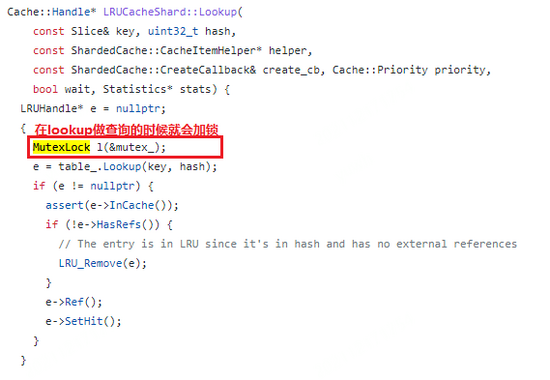
由于我們主要面臨的就是鎖競(jìng)爭(zhēng),在業(yè)務(wù)數(shù)據(jù)沒(méi)法變更的情況下,我們希望其他cache模塊來(lái)提升訪問(wèn)的吞吐。按照rocksdb官方介紹,其還支持一種cache類(lèi)型ClockCache,特點(diǎn)是在查詢時(shí)不需要加鎖,只有在插入時(shí)才需要加鎖,會(huì)有更大的訪問(wèn)吞吐,考慮到我們主要是讀操作,看起來(lái)ClockCache會(huì)比較合適。
LRU cache和Clock cache的區(qū)別: https://rocksdb.org.cn/doc/Block-Cache.html
經(jīng)過(guò)修改源碼和重新編譯,我們將緩存模塊改成了ClockCache,如下圖所示:
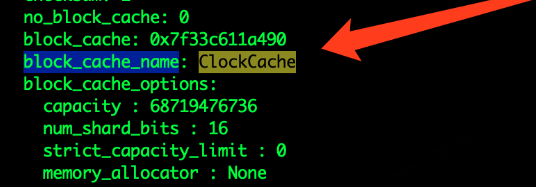
但集群使用時(shí)沒(méi)幾分鐘就core, 查找資料我們發(fā)現(xiàn)目前ClockCache支持還存在問(wèn)題( https://github.com/facebook/rocksdb/pull/8261) , 此方案目前無(wú)法使用。
5)限制線程使用
可以看到整個(gè)系統(tǒng)在當(dāng)前配置下,是存在非常多的線程的,如下圖所示。
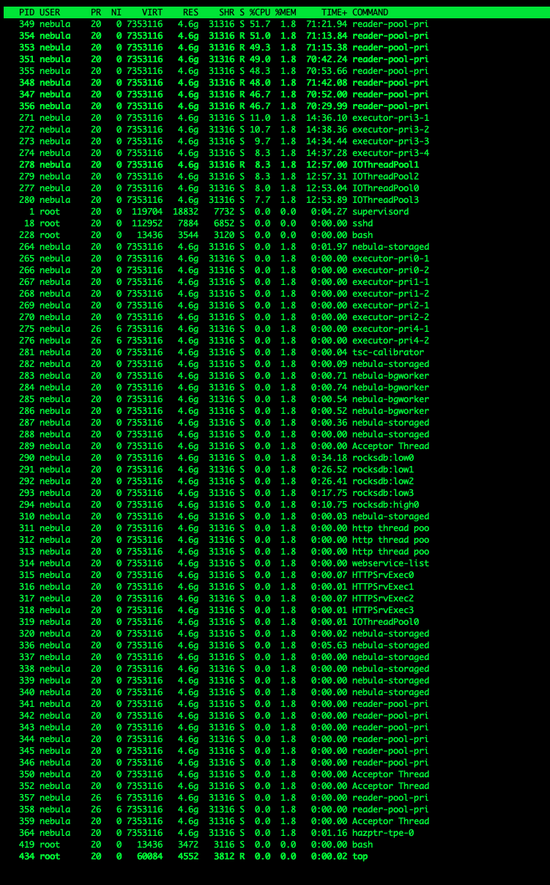
如果是單線程,就必然不會(huì)存在鎖競(jìng)爭(zhēng)。但作為一個(gè)圖服務(wù),每次訪問(wèn)幾乎會(huì)解析成多個(gè)執(zhí)行器來(lái)并發(fā)訪問(wèn),強(qiáng)行改為單線程必然會(huì)造成訪問(wèn)堆積。
所以我們考慮將原有的線程池中的進(jìn)程調(diào)小,以避免太多的線程進(jìn)行同步等待帶來(lái)的線程切換,以減小系統(tǒng)對(duì)cpu的占用。
類(lèi)型 | 配置項(xiàng) | 原始值 | 修改值 | 說(shuō)明 |
Storaged | num_io_threads | 默認(rèn)(16) | 4或者8 | |
num_worker_threads | 默認(rèn)(32) | 4或者8 | ||
reader_handlers | 默認(rèn)(32) | 8或者12 | 官方未公開(kāi)配置 |
調(diào)整之后整個(gè)系統(tǒng)cpu非常平穩(wěn),絕大部分物理機(jī)cpu在20%以內(nèi),且沒(méi)有之前遇到的突然上下大幅波動(dòng)的情況(瞬時(shí)激烈鎖競(jìng)爭(zhēng)會(huì)大幅度提升cpu的使用率),說(shuō)明這個(gè)調(diào)整對(duì)當(dāng)前業(yè)務(wù)來(lái)說(shuō)是有一定效果的。
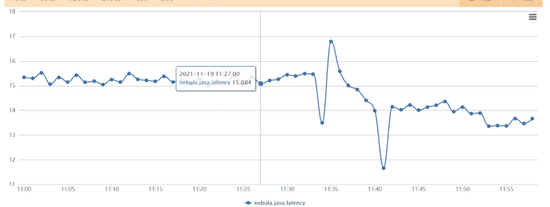
隨之又遇到了下列問(wèn)題,前端服務(wù)突然發(fā)現(xiàn)nebula的訪問(wèn)大幅度超時(shí),而從系統(tǒng)監(jiān)控的角度卻毫無(wú)波動(dòng)(下圖24,19:53系統(tǒng)其實(shí)已經(jīng)響應(yīng)出現(xiàn)問(wèn)題了,但cpu沒(méi)有任何波動(dòng))。
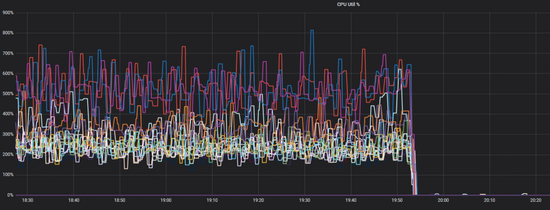
原因是在于,限制了thread 確實(shí)有效果,減少了競(jìng)爭(zhēng),但隨著壓力的正大,線程吞吐到達(dá)極限,但如果增加線程,資源的競(jìng)爭(zhēng)又會(huì)加劇,無(wú)法找到平衡點(diǎn)。
6)關(guān)閉數(shù)據(jù)壓縮,關(guān)閉block cache
在沒(méi)有特別好的方式避免鎖競(jìng)爭(zhēng)的情況,我們重新回顧了鎖競(jìng)爭(zhēng)的整個(gè)發(fā)生過(guò)程,鎖產(chǎn)生本身就是由cache自身的結(jié)構(gòu)帶來(lái)的,尤其是在讀操作的時(shí)候,我們并不希望存在什么鎖的行為。
使用block cache,是為了在合理的緩存空間中盡可能的提高緩存命中率,以提高緩存的效率。但如果緩存空間非常充足,且命中長(zhǎng)期的數(shù)據(jù)長(zhǎng)期處于特定的范圍內(nèi),實(shí)際上并沒(méi)有觀察到大量的緩存淘汰的情況,且當(dāng)前服務(wù)的緩存實(shí)際上也并沒(méi)有用滿,所以想到,是不是可以通過(guò)關(guān)閉block cache,而直接訪問(wèn)page cache來(lái)避免讀操作時(shí)的加鎖行為。
除了block cache,存儲(chǔ)端還有一大類(lèi)內(nèi)存使用是Indexes and filter blocks,與此有關(guān)的設(shè)置在RocksDB中是cache_index_and_filter_blocks。當(dāng)這個(gè)設(shè)置為true的時(shí)候,數(shù)據(jù)會(huì)緩存到block cache中,所以如果關(guān)閉了block cache,我們就需要同樣關(guān)閉cache_index_and_filter_blocks(在Nebula Graph中,通過(guò)配置項(xiàng)enable_partitioned_index_filter替代直接修改RocksDB的cache_index_and_filter_blocks)。
但僅僅修改這些并沒(méi)有解決問(wèn)題,實(shí)際上觀察perf我們?nèi)匀豢吹芥i的競(jìng)爭(zhēng)造成的阻塞(下圖):
這是因?yàn)楫?dāng)cache_index_and_filter_blocks為false的時(shí)候,并不代表index和filter數(shù)據(jù)不會(huì)被加載到內(nèi)存中,這些數(shù)據(jù)其實(shí)會(huì)被放進(jìn)table cache里,仍然需要通過(guò)LRU來(lái)維護(hù)哪些文件的信息需要淘汰,所以LRU帶來(lái)的問(wèn)題并沒(méi)有完全解決。處理的方式是將max_open_files設(shè)置為-1,以提供給系統(tǒng)無(wú)限制的table cache的使用,在這種情況下,由于沒(méi)有文件信息需要置換出去,算法邏輯被關(guān)閉。
總結(jié)下來(lái)核心修改如下表:
類(lèi)型 | 配置項(xiàng) | 原始值 | 修改值 | 說(shuō)明 |
Storaged | rocksdb_block_cache | 8192 | -1 | 關(guān)閉block cache |
rocksdb_compression_per_level | lz4 | no:no:no:no:lz4:lz4:lz4 | 在L0~L3層關(guān)閉壓縮 | |
enable_partitioned_index_filter | true | false | 避免將index和filter緩存進(jìn)block cache | |
RocksDB | max_open_files | 4096 | -1 | 避免文件被table cache淘汰,避免文件描述符被關(guān)閉,加快文件的讀取 |
關(guān)閉了block cache后,整個(gè)系統(tǒng)進(jìn)入了一個(gè)非常穩(wěn)定的狀態(tài),線上集群在訪問(wèn)量增加一倍以上的情況下,系統(tǒng)的cpu峰值反而穩(wěn)定在30%以下,且絕大部分時(shí)間都在10%以內(nèi)(下圖)。
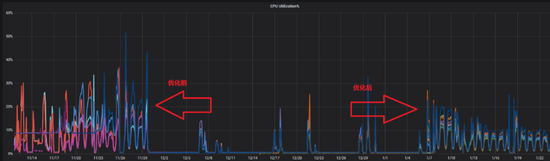
需要說(shuō)明的是,酒店場(chǎng)景中關(guān)閉block cache是一個(gè)非常有效的手段,能夠?qū)ζ涮囟ㄇ闆r下的熱點(diǎn)訪問(wèn)起到比較好的效果,但這并非是一個(gè)常規(guī)方式,我們?cè)谄渌麡I(yè)務(wù)方的nebula graph集群中并沒(méi)有關(guān)閉block cache。
4.3 數(shù)據(jù)寫(xiě)入時(shí)服務(wù)down機(jī)
起因酒店業(yè)務(wù)在全量寫(xiě)入的時(shí)候,即使量不算很大(4~5w/s),在不特定的時(shí)間就會(huì)導(dǎo)致整個(gè)graphd集群完全down機(jī),由于graphd集群都是無(wú)狀態(tài)的,且互相之間沒(méi)有關(guān)系,如此統(tǒng)一的在某個(gè)時(shí)刻集體down機(jī),我們猜測(cè)是由于訪問(wèn)請(qǐng)求造成。通過(guò)查看堆棧發(fā)現(xiàn)了明顯的異常(下圖):

可以看到上圖中的三行語(yǔ)句被反復(fù)執(zhí)行,很顯然這里存在遞歸調(diào)用,并且無(wú)法在合理的區(qū)間內(nèi)退出,猜測(cè)為堆棧已滿。在增加了堆棧大小之后,整個(gè)執(zhí)行沒(méi)有任何好轉(zhuǎn),說(shuō)明遞歸不僅層次很深,且可能存在指數(shù)級(jí)的增加的情況。同時(shí)觀察down機(jī)時(shí)的業(yè)務(wù)請(qǐng)求日志,失敗瞬間大量執(zhí)行失敗,但有一些執(zhí)行失敗顯示為null引用錯(cuò)誤,如下圖所示:
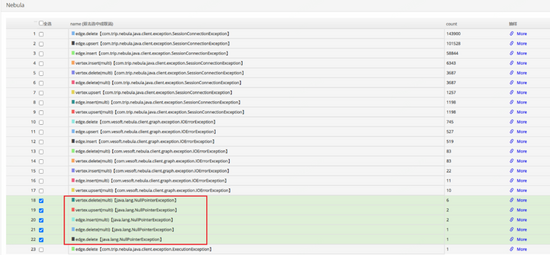
這是因?yàn)榉祷亓藞?bào)錯(cuò),但沒(méi)有error message,導(dǎo)致發(fā)生了空引用(空引用現(xiàn)象是客戶端未合理處理這種情況,也是我們客戶端的bug),但這種情況很奇怪,為什么會(huì)沒(méi)有error message,檢查其trace日志,發(fā)現(xiàn)這些請(qǐng)求執(zhí)行nebula時(shí)間都很長(zhǎng),且存在非常大段的語(yǔ)句,如下圖所示:
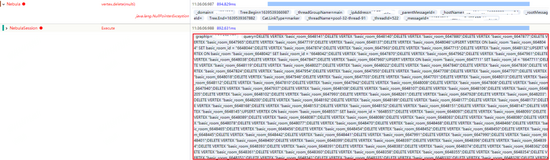
預(yù)感是這些語(yǔ)句導(dǎo)致了graphd的down機(jī),由于執(zhí)行被切斷導(dǎo)致客戶端生成了一個(gè)null值。將這些語(yǔ)句進(jìn)行重試,可以必現(xiàn)down機(jī)的場(chǎng)景。檢查這樣的請(qǐng)求發(fā)現(xiàn)其是由500條語(yǔ)句組成(業(yè)務(wù)方語(yǔ)句拼接上限500),并沒(méi)有超過(guò)配置設(shè)置的最大執(zhí)行語(yǔ)句數(shù)量(512)。
看起來(lái)這是一個(gè)nebula官方的bug,我們已經(jīng)將此問(wèn)題提交給官方。同時(shí)業(yè)務(wù)方語(yǔ)句拼接限制從500降為200后順利避免該問(wèn)題導(dǎo)致的down機(jī)。
五、Nebula Graph二次開(kāi)發(fā)
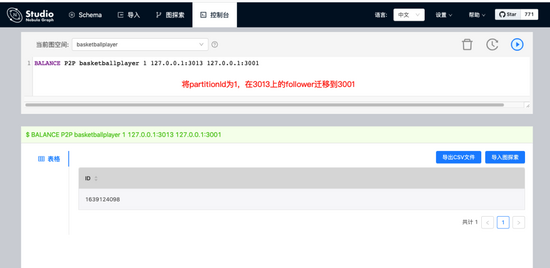
當(dāng)前我們對(duì)Nebula Graph的修改主要集中的幾個(gè)運(yùn)維相關(guān)的環(huán)節(jié)上,比如新增了命令來(lái)指定遷移Storaged中的分片,以及將leader遷移到指定的實(shí)例上(下圖)。
六、未來(lái)規(guī)劃
- 與攜程大數(shù)據(jù)平臺(tái)整合,充分利用Spark或者Flink來(lái)實(shí)現(xiàn)數(shù)據(jù)的傳輸和ETL,提高異構(gòu)集群間數(shù)據(jù)的遷移能力。
- 提供Slowlog檢查功能,抓取造成slowlog的具體語(yǔ)句。
- 參數(shù)化查詢功能,避免依賴注入。
- 增強(qiáng)可視化能力,增加定制化功能。