谷歌、MIT「迭代共同認(rèn)證」視頻問(wèn)答模型:SOTA性能,算力少用80%
視頻是一種無(wú)處不在的媒體內(nèi)容源,涉及到人們?nèi)粘I畹脑S多方面。越來(lái)越多的現(xiàn)實(shí)世界的視頻應(yīng)用,如視頻字幕、內(nèi)容分析和視頻問(wèn)答(VideoQA),都依賴(lài)于能夠?qū)⒁曨l內(nèi)容與文本或自然語(yǔ)言聯(lián)系起來(lái)的模型。
其中,視頻問(wèn)答模型尤其具有挑戰(zhàn)性,因?yàn)樗枰瑫r(shí)掌握語(yǔ)義信息,比如場(chǎng)景中的目標(biāo),以及時(shí)間信息,比如事物如何移動(dòng)和互動(dòng)。這兩種信息都必須在擁有特定意圖的自然語(yǔ)言問(wèn)題的背景下進(jìn)行。 此外,由于視頻有許多幀,處理全部的幀來(lái)學(xué)習(xí)時(shí)空信息,可能在計(jì)算上成本過(guò)高。

論文鏈接:https://arxiv.org/pdf/2208.00934.pdf 為了解決這個(gè)問(wèn)題,在「Video Question Answering with Iterative Video-Text Co-Tokenization」一文中,谷歌和MIT的研究人員介紹了一種視頻-文本學(xué)習(xí)的新方法,稱(chēng)為「迭代共同標(biāo)記」,能夠有效地融合空間、時(shí)間和語(yǔ)言信息,用于視頻問(wèn)答的信息處理。

這種方法是多流的,用獨(dú)立的骨干模型處理不同規(guī)模的視頻,產(chǎn)生捕捉不同特征的視頻表示,例如高空間分辨率或長(zhǎng)時(shí)間的視頻。 模型應(yīng)用「共同認(rèn)證」模塊,從視頻流與文本的融合中學(xué)習(xí)有效表示。模型計(jì)算效率很高,只需67GFLOPs,比以前的方法至少低了50%,同時(shí)比其他SOTA的模型有更好的性能。
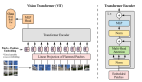
視頻-文本迭代
該模型的主要目標(biāo)是從視頻和文本(即用戶(hù)問(wèn)題)中產(chǎn)生特征,共同允許它們的相應(yīng)輸入進(jìn)行互動(dòng)。第二個(gè)目標(biāo)是以有效的方式做到這一點(diǎn),這對(duì)視頻來(lái)說(shuō)非常重要,因?yàn)樗鼈儼瑤资綆装賻妮斎搿?/span>
? 該模型學(xué)會(huì)了將視頻-語(yǔ)言的聯(lián)合輸入標(biāo)記為較小的標(biāo)記集,以聯(lián)合和有效地代表兩種模式。在標(biāo)記化時(shí),研究人員使用兩種模式來(lái)產(chǎn)生一個(gè)聯(lián)合的緊湊表示,該表示被送入一個(gè)轉(zhuǎn)換層以產(chǎn)生下一級(jí)的表示。
這里的一個(gè)挑戰(zhàn),也是跨模態(tài)學(xué)習(xí)中的典型問(wèn)題,就是視頻幀往往并不直接對(duì)應(yīng)于相關(guān)的文本。研究人員通過(guò)增加兩個(gè)可學(xué)習(xí)的線性層來(lái)解決這個(gè)問(wèn)題,在標(biāo)記化之前,統(tǒng)一視覺(jué)和文本特征維度。這樣一來(lái),研究人員就可以讓視頻和文本都能制約視頻標(biāo)記的學(xué)習(xí)方式。
此外,單一的標(biāo)記化步驟不允許兩種模式之間的進(jìn)一步互動(dòng)。為此,研究人員使用這個(gè)新的特征表示與視頻輸入特征互動(dòng),并產(chǎn)生另一組標(biāo)記化的特征,然后將其送入下一個(gè)轉(zhuǎn)化器層。 這個(gè)迭代過(guò)程中會(huì)創(chuàng)建新的特征或標(biāo)記,表示對(duì)兩種模式的聯(lián)合表示的不斷完善。最后,這些特征被輸入到生成文本輸出的解碼器中。

按照視頻質(zhì)量評(píng)估的慣例,在對(duì)個(gè)別視頻質(zhì)量評(píng)估數(shù)據(jù)集進(jìn)行微調(diào)之前,研究人員對(duì)模型進(jìn)行預(yù)訓(xùn)練。 在這項(xiàng)工作中,研究人員使用基于語(yǔ)音識(shí)別的文本自動(dòng)注釋的視頻,使用HowTo100M數(shù)據(jù)集,而不是在大型VideoQA數(shù)據(jù)集上預(yù)訓(xùn)練。這種較弱的預(yù)訓(xùn)練數(shù)據(jù)仍然使研究人員的模型能夠?qū)W習(xí)視頻-文本特征。
高效視頻問(wèn)答的實(shí)現(xiàn)
研究人員將視頻語(yǔ)言迭代共同認(rèn)證算法應(yīng)用于三個(gè)主要的VideoQA基準(zhǔn),MSRVTT-QA、MSVD-QA和IVQA,并證明這種方法比其他最先進(jìn)的模型取得了更好的結(jié)果,同時(shí)模型不至于過(guò)大。另外,迭代式共同標(biāo)記學(xué)習(xí)在視頻-文本學(xué)習(xí)任務(wù)上對(duì)算力的需求也更低。

該模型只用67GFLOPS算力,是3D-ResNet視頻模型和文本時(shí)所需算力(360GFLOP)的六分之一,是X3D模型效率的兩倍多。并且生成了高度準(zhǔn)確的結(jié)果,精度超過(guò)了最先進(jìn)的方法。
多流視頻輸入
對(duì)于VideoQA或其他一些涉及視頻輸入的任務(wù),研究人員發(fā)現(xiàn),多流輸入對(duì)于更準(zhǔn)確地回答有關(guān)空間和時(shí)間關(guān)系的問(wèn)題很重要。
研究人員利用三個(gè)不同分辨率和幀率的視頻流:一個(gè)低分辨率、高幀率的輸入視頻流(每秒32幀,空間分辨率64x64,記作32x64x64);一個(gè)高分辨率、低幀率的視頻(8x224x224);以及一個(gè)介于兩者之間的(16x112x112)。
盡管有三個(gè)數(shù)據(jù)流需要處理的信息顯然更多,但由于采用了迭代共同標(biāo)記方法,獲得了非常高效的模型。同時(shí),這些額外的數(shù)據(jù)流允許提取最相關(guān)的信息。
例如,如下圖所示,與特定活動(dòng)相關(guān)的問(wèn)題在分辨率較低但幀率較高的視頻輸入中會(huì)產(chǎn)生較高的激活,而與一般活動(dòng)相關(guān)的問(wèn)題可以從幀數(shù)很少的高分辨率輸入中得到答案。

這種算法的另一個(gè)好處是,標(biāo)記化會(huì)根據(jù)所問(wèn)問(wèn)題的不同而改變。
結(jié)論
研究人員提出了一種新的視頻語(yǔ)言學(xué)習(xí)方法,它側(cè)重于跨視頻-文本模式的聯(lián)合學(xué)習(xí)。研究人員解決了視頻問(wèn)題回答這一重要而具有挑戰(zhàn)性的任務(wù)。研究人員的方法既高效又準(zhǔn)確,盡管效率更高,但卻優(yōu)于目前最先進(jìn)的模型。
谷歌研究人員的方法模型規(guī)模適度,可以通過(guò)更大的模型和數(shù)據(jù)獲得進(jìn)一步的性能改進(jìn)。研究人員希望,這項(xiàng)工作能引發(fā)視覺(jué)語(yǔ)言學(xué)習(xí)方面的更多研究,以實(shí)現(xiàn)與基于視覺(jué)的媒體的更多無(wú)縫互動(dòng)。