在DevOps席卷軟件工程領域之前,一旦他們的應用程序啟動并開始運行,應用程序便如黑盒一般,開發人員無從知曉。工程師往往等到客戶或者相關使用者抱怨“網站訪問緩慢”或者503頁面過多時,才會發現系統何時發生了中斷。
不幸的是,這導致相同的錯誤反復發生,因為開發人員缺乏對應用程序性能的洞察力,并且一旦出現故障,不知道從哪里開始調試他們的代碼。
那解決方案呢?現在廣泛采用的DevOps概念是一種新方法,它要求在軟件部署和開發過程中開發人員 (Dev) 和運維團隊 (Ops)之間進行協作和持續迭代。
到了2015年左右,Netflix、Uber 和 Airbnb等大型數據導向的公司已經采用持續集成/持續部署 (CI/CD) 原則,甚至構建開源工具來促進數據團隊的成長,于是DataOps誕生了。事實上,如果不管數據工程師有沒有意識到這一點,他都可能已經將DataOps流程和技術應用到堆棧中了。在過去的幾年里, DataOps作為一個框架在各種規模的數據團隊中越來越受歡迎,它支持快速部署數據流水線,同時仍然提供可靠的、值得信賴的、隨時可用的數據。DataOps可以使任何企業受益,這就是為什么我們要整理一份指南,來幫助大家消除對有關方面的誤解。
在本指南中,我們將解釋下面幾個問題。
什么是DataOps?
DataOps是一門融合數據工程和數據科學團隊以滿足企業在數據方面的需求的方法論,類似于DevOps幫助擴展軟件工程的方式。與 DevOps將 CI/CD 應用于軟件開發和運維的方式類似,DataOps需要一種類似于CI/CD、自動化優先的方法來構建和擴展數據產品。同時, DataOps使數據工程團隊更容易為分析師和其他下游使用人員提供可靠的數據來驅動決策。
DataOps與DevOps
雖然DataOps與DevOps有許多相似之處,但兩者之間也有重要區別。
其中關鍵區別是DevOps是一種將開發和運維團隊聚集在一起,以提高軟件開發和交付效率的方法,而DataOps專注于打破數據生產者和數據消費者之間的孤島,使數據更加可靠和更有價值。
多年來,DevOps團隊已成為大多數科技企業不可或缺的一部分,消除了軟件開發人員和IT人員之間的隔閡,促進了軟件無縫且可靠地發布到產品中。隨著DevOps在企業中越來越受歡迎,支持它們的技術棧開始變得越來越復雜。為了保持系統整體處于健康狀況,DevOps工程師利用可觀察性來監控、跟蹤和分類事件,以防止應用程序停機。
軟件可觀察性包括三個支柱。
- 日志:記錄給定時間戳發生的事件,同時為發生的特定事件提供上下文。
- 指標:用數字表示一段時間內測量的數據。
- 跟蹤:表示分布式環境中相互關聯的事件。
總之,可觀察性的三個支柱使DevOps團隊能夠預測未來的行為并信任他們的應用程序。
類似地,DataOps原則可幫助團隊消除隔閡并更有效地工作,從而在整個企業內交付高質量的數據產品。隨著公司開始從各種來源獲取大量數據,DataOps專業人員還利用可觀察性來減少停機時間。數據可觀察性是企業充分了解其系統中數據健康狀況的能力。它通過對在數天、數周甚至數月內未被檢測到的事件進行監控和告警,從而降低數據停機時間的頻率和影響(數據不完整、錯誤、丟失或其他不準確的時間段)。與軟件可觀察性一樣,數據可觀察性包括自己的一組支柱。
- 新鮮度:數據是最新的嗎?最后一次更新是什么時候?
- 分布:數據是否在可接受的范圍內?是否符合預期的格式嗎?
- 卷:所有數據都到了嗎?表中是否有重復或刪除的數據?
- 架構:架構是什么,它有變化嗎?對架構的更改是主動進行的嗎?
- 沿襲:哪些上游和下游的相關性連接到給定的數據資產?誰依賴這些數據進行決策,這些數據在哪些表中?
DataOps框架
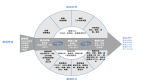
為了更快、更可靠地洞察數據, DataOps團隊應用了一個持續的反饋循環,也稱為DataOps生命周期。DataOps生命周期是從DevOps生命周期中汲取靈感,但考慮到數據不斷變化的特性,它融合了不同的技術和流程。DataOps生命周期允許數據團隊和業務團隊協同工作,為企業提供更可靠的數據和分析。以下是實際的DataOps生命周期。
- 規劃:與產品、工程和業務團隊合作,為數據的質量和可用性設置KPI、SLA和SLI。
- 開發:構建數據產品和機器學習模型,為數據應用程序提供生產力。
- 集成:將代碼和數據產品(或其中之一)集成到現有的技術和數據棧中(或其中之一),例如,將DBT模型與Airflow集成,以便DBT模塊可以自動運行。
- 測試:測試數據以確保其符合業務邏輯并滿足基本操作閾值(例如數據的唯一性或無空值)。
- 發布:將數據發布到測試環境中。
- 部署:將數據合并到生產環境中。
- 操作:將數據運行到應用程序中,例如為機器學習模型提供數據的Looker或Tableau儀表板和數據加載器。
- 監控:持續監控數據中的任何異常并發出警報。
這個循環會不斷重復。通過將DevOps的類似原則應用于數據流水線,數據團隊可以更好地協作,從而一開始就識別、解決甚至防止數據質量問題的發生。
DataOps的五個最佳實踐
與我們在軟件開發領域的朋友類似,數據團隊也開始效仿,將數據視為產品。
數據是企業決策過程的關鍵部分,將產品管理思維應用到如何構建、監控和測量數據產品,有助于確保這些決策能基于準確、可靠的信息。在過去幾年與數百個數據團隊交談后,我們總結了五個關鍵的DataOps最佳實踐,可以幫助您更好地適應這種“數據即產品”的方法。
1、盡早讓有關人員在KPI上達成一致,并定期重新審視它們
既然企業將數據視為產品,那么內部有關人員就是企業的客戶。因此,盡早與數據的關鍵有關人員保持一致,并就誰使用數據、他們如何使用數據以及用于什么目的達成一致是至關重要的。為關鍵數據集制訂服務水平協議(SLA)也很重要。與有關人員就“什么樣的數據質量標準才是對的”達成一致,有助于企業避免在哪些是KPI,哪些是無關緊要的指標,以及類似的問題反復討論。
在和有關人員達成一致看法后,企業應該定期與他們核對以確保優先級仍然一致。Red Ventures的高級數據科學家Brandon Beidel每周與公司的每個業務團隊會面,討論團隊在 SLA方面的進展。
“我總是用簡單的商業術語來企業對話,并專注于誰、什么、何時、何地以及為什么”,布蘭登告訴我們。“我特別想問一些關于數據新鮮度限制的問題,我發現這對業務有關人員特別重要。”
2、盡可能多的任務自動化
DataOps的主要關注點之一是數據工程自動化。數據團隊可以將通常需要數小時才能完成的機械任務自動化,例如單元測試、硬編碼獲取管道和工作流編排。通過使用自動化解決方案,團隊可以減少人為錯誤進入數據流水線的可能性并提高可靠性,同時幫助企業做出更好、更快的基于數據的決策。
3、擁抱“交付和迭代”文化
對于大多數數據驅動的企業而言,速度至關重要。而且,數據產品并不需要百分百完美才能增加價值。我的建議就是構建一個基本的MVP,對其進行測試,評估學習成果,并根據需要進行修改。我的第一手經驗表明,通過在生產中使用實時數據進行測試和迭代,可以更快地構建成功的數據產品。團隊可以與相關人員協作,監控、測試和分析模式,以解決任何問題并改善結果。如果經常這樣做,將會有更少的錯誤并降低錯誤進入數據流水線的可能性。
4、引進自助服務工具
DataOps的一個重要好處是消除了數據在業務人員和數據工程師之間的隔閡。為了做到這一點,業務用戶需要能夠通過自助工具滿足自己的數據需求。業務人員可以在需要時訪問他們需要的數據,而不是讓數據團隊來滿足業務用戶的臨時請求(這最終會減緩決策制定的速度)。Intuit的前工程副總裁Mammad Zadeh認為,自助服務工具在跨企業啟用DataOps方面發揮至關重要的作用。“數據中心團隊應確保數據的生產者和使用者都可以使用正確的自助式基礎設施和工具,以便他們能夠輕松完成工作,”Mammad告訴我們,“為他們配備正確的工具,讓他們直接互動,不要設置任何障礙。”
5、優先考慮數據質量,然后才是擴展規模
在擴展的同時保持高數據質量并非易事。因此,從最重要的數據資產開始——沒錯,就是有關人員在做出重要決策時所依賴的信息。
如果數據資產中不準確的數據可能意味著時間、資源和收入的損失,請注意這些數據以及通過數據質量功能(如測試、監控和警報)支持這些決策的實施。然后,繼續構建企業的能力以涵蓋更多數據生命周期。(回到最佳實踐第2條,請記住,大規模數據監控通常會涉及自動化。)
企業可以從DataOps中受益的四種方式
雖然DataOps的存在是為了消除數據孤島并幫助數據團隊協作,但團隊在實施DataOps時可以實現其他四個好處。
1、更好的數據質量
公司可以在其流水線中應用DataOps以提高數據質量。這包括自動化日常任務,例如測試和引入端到端可觀察性,并在數據棧的每一層(從獲取到存儲到轉換到BI工具)進行監控和警報。這種自動化和可觀察性的結合降低了人為錯誤的機會,并使數據團隊能夠快速主動地響應數據停機事件——通常是在有關人員意識到出現任何問題之前。有了這些DataOps實踐,業務人員可以獲得質量更高的數據,遇到更少的數據問題,并在整個企業內建立對基于數據的決策的信任。
2、更快樂、更高效的數據團隊
平均來說,數據工程師和科學家至少花費30%的時間來解決數據質量問題,而DataOps的一個關鍵部分是創建一個自動化且可重復的流程,這反過來為數據工程師和數據科學家節省了時間。
將繁瑣的工程任務(例如連續代碼質量檢查和異常檢測)自動化可以改善工程流程,同時減少企業內部的技術債務。
DataOps讓團隊成員更快樂,他們可以將寶貴的時間集中在改進數據產品、構建新功能和優化數據流水線上,以加快企業數據的價值實現的速度。
3、更快地獲得分析見解
DataOp可自動執行通常需要花費數小時才能完成的測試和異常檢測等工程任務。因此, DataOps為數據團隊帶來了速度,促進了數據工程和數據科學團隊之間更快的協作。更短的數據產品開發周期可以降低成本(就工程時間而言),并允許數據驅動的企業更快地實現其目標。這是可能的,因為多個團隊可以在同一個項目上并肩工作以同時交付結果。
根據我的經驗, DataOps促進不同團隊之間的協作可以帶來更準確的洞察和分析,從而改進的決策制定能力,并帶來更高的利潤。如果充分實現了DataOps,團隊就可以實時訪問數據并調整他們的決策,而不是等待數據可用或請求臨時支持。
4、降低運營和法律風險
當企業努力通過民主化訪問來增加數據的價值,道德、技術和法律方面的挑戰也將不可避免地增加。通用數據保護條例 (GDPR) 和加州消費者隱私法案 (CCPA) 等政府法規已經改變了公司處理數據的方式,并讓公司努力將數據直接交到更多團隊這個過程變得更復雜。DataOps——特別是數據可觀察性——可以通過提供更多的可見性和透明度來幫助解決這些問題,即用戶對數據的操作、數據輸入到哪些表以及誰可以訪問上游或下游的數據更清楚。
在公司實施DataOps
關于DataOps的好消息是采用現代數據棧和其他最佳實踐的公司可能已經將DataOps原則應用到他們的流水線中。例如,越來越多的公司正在招聘DataOps工程師來推動基于數據進行決策——
但這些職位描述,可能包括了已經由公司的數據工程師在處理的職責。DataOps工程師通常負責:
- 開發和維護可部署、測試和記錄的自動化設計腳本、流程和程序庫。
- 與其他部門合作,將源系統與數據湖和數據倉庫進行集成。
- 創建并實施測試數據流水線的自動化。
- 在影響下游有關人員之前主動識別和修復數據質量問題。
- 通過引進自助服務工具或為業務人員執行培訓計劃,來提高整個企業的數據意識。
- 熟悉數據轉換、測試和數據可觀察性平臺,以提高數據可靠性。
即使其他團隊成員目前正在兼管這些職能,擁有一個專門的角色負責來構建DataOps框架也能提高可靠性,并簡化采用這些最佳實踐的過程。無論團隊成員擔任什么職務,就像沒有應用可觀察性就無法擁有DevOps一樣,沒有數據可觀察性就無法擁有DataOps。數據可觀察性工具使用自動監控、警報和分類來識別和評估數據質量和可發現性問題。這會帶來更健康的流水線、更高效的團隊和更滿意的客戶。
參考鏈接:https://dzone.com/articles/is-dataops-the-future-of-the-modern-data-stackv