













作者 | 臨在、岑鳴、熊兮
一、導(dǎo)讀
隨著BERT、Megatron、GPT-3等預(yù)訓(xùn)練模型在NLP領(lǐng)域取得矚目的成果,越來越多團(tuán)隊(duì)投身到超大規(guī)模訓(xùn)練中,這使得訓(xùn)練模型的規(guī)模從億級別發(fā)展到了千億甚至萬億的規(guī)模。然而,這類超大規(guī)模的模型運(yùn)用于實(shí)際場景中仍然有一些挑戰(zhàn)。首先,模型參數(shù)量過大使得訓(xùn)練和推理速度過慢且部署成本極高;其次在很多實(shí)際場景中數(shù)據(jù)量不足的問題仍然制約著大模型在小樣本場景中的應(yīng)用,提高預(yù)訓(xùn)練模型在小樣本場景的泛化性依然存在挑戰(zhàn)。為了應(yīng)對以上問題,PAI團(tuán)隊(duì)推出了EasyNLP中文NLP算法框架,助力大模型快速且高效的落地。
EasyNLP背后的技術(shù)框架如何設(shè)計(jì)?未來有哪些規(guī)劃?今天一起來深入了解。
二、EasyNLP簡介
EasyNLP是PAI算法團(tuán)隊(duì)基于PyTorch開發(fā)的易用且豐富的中文NLP算法框架,支持常用的中文預(yù)訓(xùn)練模型和大模型落地技術(shù),并且提供了從訓(xùn)練到部署的一站式NLP開發(fā)體驗(yàn)。EasyNLP提供了簡潔的接口供用戶開發(fā)NLP模型,包括NLP應(yīng)用AppZoo和預(yù)訓(xùn)練ModelZoo,同時(shí)提供技術(shù)幫助用戶高效的落地超大預(yù)訓(xùn)練模型到業(yè)務(wù)。除此之外EasyNLP框架借助PAI團(tuán)隊(duì)在通信優(yōu)化、資源調(diào)度方面的深厚積累,可以為用戶提供大規(guī)模、魯棒的訓(xùn)練能力,同時(shí)可以無縫對接PAI系列產(chǎn)品,例如PAI-DLC、PAI-DSW、PAI-Designer和PAI-EAS,給用戶帶來高效的從訓(xùn)練到落地的完整體驗(yàn)。
EasyNLP已經(jīng)在阿里巴巴內(nèi)部支持10多個(gè)BU的業(yè)務(wù),同時(shí)在阿里云上提供了NLP解決方案和ModelHub模型幫助用戶解決業(yè)務(wù)問題,也提供用戶自定義模型服務(wù)方便用戶打造自研模型。在經(jīng)過內(nèi)部業(yè)務(wù)打磨之后,我們將EasyNLP推向開源社區(qū),希望能夠服務(wù)更多的NLP算法開發(fā)者和研究者,也希望和社區(qū)一起推動NLP技術(shù)特別是中文NLP的快速發(fā)展和業(yè)務(wù)落地。
EasyNLP is a Comprehensive and Easy-to-use NLP Toolkit[1]
EasyNLP主要特性如下:
- 易用且兼容開源:EasyNLP支持常用的中文NLP數(shù)據(jù)和模型,方便用戶評測中文NLP技術(shù)。除了提供易用簡潔的PAI命令形式對前沿NLP算法進(jìn)行調(diào)用以外,EasyNLP還抽象了一定的自定義模塊如AppZoo和ModelZoo,降低NLP應(yīng)用的門檻,同時(shí)ModelZoo里面常見的預(yù)訓(xùn)練模型和PAI自研的模型,包括知識預(yù)訓(xùn)練模型等。EasyNLP可以無縫接入huggingface/ transformers的模型,也兼容EasyTransfer模型,并且可以借助框架自帶的分布式訓(xùn)練框架(基于Torch-Accerator)提升訓(xùn)練效率。
- 大模型小樣本落地技術(shù):EasyNLP框架集成了多種經(jīng)典的小樣本學(xué)習(xí)算法,例如PET、P-Tuning等,實(shí)現(xiàn)基于大模型的小樣本數(shù)據(jù)調(diào)優(yōu),從而解決大模型與小訓(xùn)練集不相匹配的問題。此外,PAI團(tuán)隊(duì)結(jié)合經(jīng)典小樣本學(xué)習(xí)算法和對比學(xué)習(xí)的思路,提出了一種不增添任何新的參數(shù)與任何人工設(shè)置模版與標(biāo)簽詞的方案Contrastive Prompt Tuning,在FewCLUE小樣本學(xué)習(xí)榜單取得第一名,相比Finetune有超過10%的提升。
- 大模型知識蒸餾技術(shù):鑒于大模型參數(shù)大難以落地的問題,EasyNLP提供知識蒸餾功能幫助蒸餾大模型從而得到高效的小模型來滿足線上部署服務(wù)的需求。同時(shí)EasyNLP提供MetaKD算法,支持元知識蒸餾,提升學(xué)生模型的效果,在很多領(lǐng)域上甚至可以跟教師模型的效果持平。同時(shí),EasyNLP支持?jǐn)?shù)據(jù)增強(qiáng),通過預(yù)訓(xùn)練模型來增強(qiáng)目標(biāo)領(lǐng)域的數(shù)據(jù),可以有效的提升知識蒸餾的效果。
三、EasyNLP框架特點(diǎn)
1.整體架構(gòu)
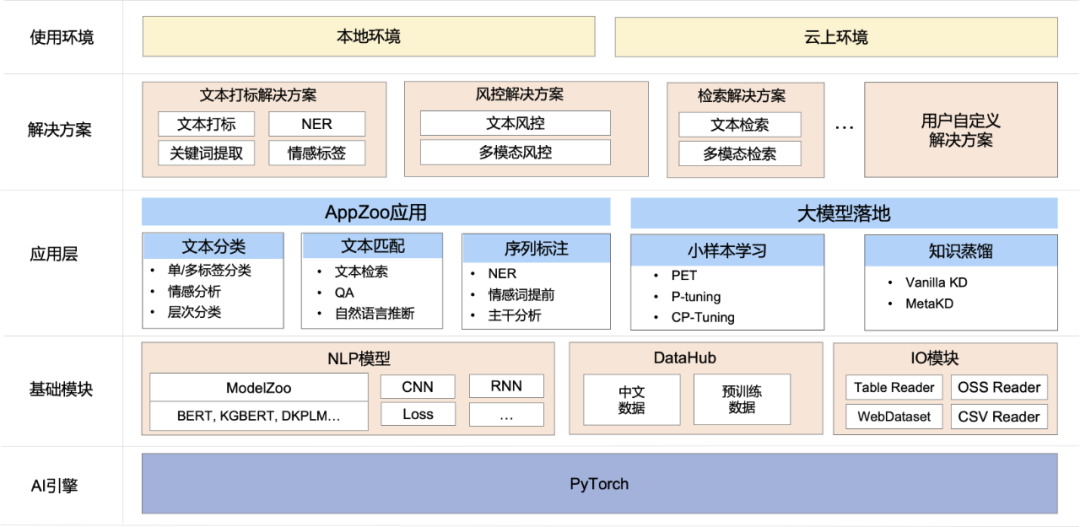
如圖所示,EasyNLP架構(gòu)主要有如下幾個(gè)核心模塊:
- 基礎(chǔ)模塊:提供了預(yù)訓(xùn)練模型庫ModelZoo,支持常用的中文預(yù)訓(xùn)練模型,包括BERT,MacBERT,WOBERT等;也提供常用的NN模塊,方便用戶自定義模型;
- 應(yīng)用層:AppZoo支持常見的NLP應(yīng)用比方說文本分類,文本匹配等;EasyNLP支持預(yù)訓(xùn)練模型落地工具,包括小樣本學(xué)習(xí)和知識蒸餾,助力大模型快速落地,這里也集成了多個(gè)PAI團(tuán)隊(duì)自研的算法;
- NLP應(yīng)用和解決方案:提供了多個(gè)NLP解決方案和ModelHub模型幫助用戶解決業(yè)務(wù)問題;
- 工具層:可以支持本地拉起服務(wù),也可以在阿里云產(chǎn)品上部署和調(diào)用,比方說PAI-DLC、PAI-DSW、PAI-Designer和PAI-EAS,給用戶帶來高效的從訓(xùn)練到落地的完整體驗(yàn)。
2.大模型知識蒸餾技術(shù)
隨著BERT等預(yù)訓(xùn)練語言模型在各項(xiàng)任務(wù)上都取得SOTA效果,大規(guī)模預(yù)訓(xùn)練模型已經(jīng)成為 NLP學(xué)習(xí)管道中的重要組成部分,但是這類模型的參數(shù)量太大,而且訓(xùn)練和推理速度慢,嚴(yán)重影響到了需要較高QPS的線上場景,部署成本非常高。EasyNLP框架集成了經(jīng)典的數(shù)據(jù)增強(qiáng)和知識蒸餾算法,使得訓(xùn)練出的小模型在相應(yīng)任務(wù)行為上能夠逼近大模型的效果。
由于現(xiàn)有大部分的知識蒸餾工作都聚焦在同領(lǐng)域模型的蒸餾,而忽略了跨領(lǐng)域模型對目標(biāo)蒸餾任務(wù)效果的提升。PAI團(tuán)隊(duì)進(jìn)一步提出了元知識蒸餾算法MetaKD(Meta Knowledge Distillation),將跨領(lǐng)域的可遷移知識學(xué)出,在蒸餾階段額外對可遷移的知識進(jìn)行蒸餾。MetaKD算法使得學(xué)習(xí)到的學(xué)生模型在相應(yīng)的領(lǐng)域的效果顯著提升,逼近教師模型的效果。這一算法的核心框架圖如下所示:
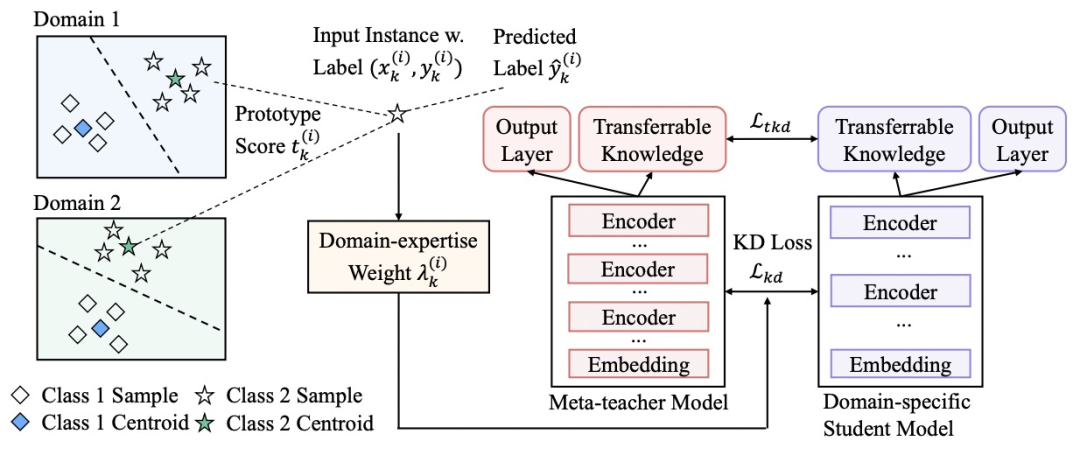
其中,MetaKD算法包括兩個(gè)階段。第一個(gè)階段為元教師模型學(xué)習(xí)(Meta-teacher Learning)階段,算法從多個(gè)領(lǐng)域的訓(xùn)練數(shù)據(jù)協(xié)同學(xué)習(xí)元教師模型,它對每個(gè)領(lǐng)域的樣本都計(jì)算其典型得分(Prototype Score),使更具有跨領(lǐng)域典型性的樣本在學(xué)習(xí)階段有更大的權(quán)重。第二個(gè)階段為元蒸餾(Meta-distillation)階段,將元教師模型選擇性地蒸餾到特定領(lǐng)域的學(xué)習(xí)任務(wù)上。由于元教師模型可能無法做到在所有領(lǐng)域上都有精確的預(yù)測效果,我們額外引入了領(lǐng)域?qū)I(yè)性權(quán)重(Domain-expertise Weight),使元教師模型只將置信度最高的知識遷移到學(xué)生模型,避免學(xué)生模型對元教師模型的過擬合。
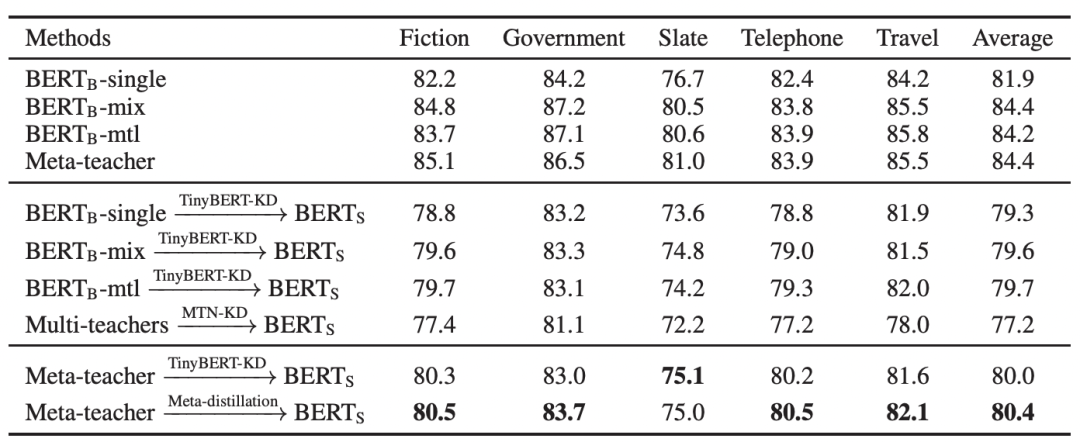
下圖展示了MetaKD算法在MNLI的5個(gè)領(lǐng)域數(shù)據(jù)集的跨任務(wù)蒸餾效果。由結(jié)果可見,MetaKD蒸餾出的BERT-Small模型的和原始BERT模型相比,在保持模型精度值平均只下降1.5%的前提下參數(shù)減少了87%,大大減少了部署的壓力。
目前,MetaKD算法也已經(jīng)集成到EasyNLP框架中開源。
知識蒸餾實(shí)踐詳見[2]。
3.大模型小樣本學(xué)習(xí)技術(shù)
預(yù)訓(xùn)練語言模型規(guī)模的擴(kuò)大,使得這一類模型在自然語言理解等相關(guān)任務(wù)效果不斷提升。然而,這些模型的參數(shù)空間比較大,如果在下游任務(wù)上直接對這些模型進(jìn)行微調(diào),為了達(dá)到較好的模型泛化性,需要較多的訓(xùn)練數(shù)據(jù)。在實(shí)際業(yè)務(wù)場景中,特別是垂直領(lǐng)域、特定行業(yè)中,訓(xùn)練樣本數(shù)量不足的問題廣泛存在,極大地影響這些模型在下游任務(wù)的準(zhǔn)確度。為了解決這一問題,EasyNLP框架集成了多種經(jīng)典的小樣本學(xué)習(xí)算法,例如PET、P-Tuning等,實(shí)現(xiàn)基于預(yù)訓(xùn)練語言模型的小樣本數(shù)據(jù)調(diào)優(yōu),從而解決大模型與小訓(xùn)練集不相匹配的問題。
此外,PAI團(tuán)隊(duì)結(jié)合經(jīng)典小樣本學(xué)習(xí)算法和對比學(xué)習(xí)的思路,提出了一種不增添任何新的參數(shù)與任何人工設(shè)置模版與標(biāo)簽詞的方案Contrastive Prompt Tuning (CP-Tuning)。這一算法的核心框架圖如下所示:
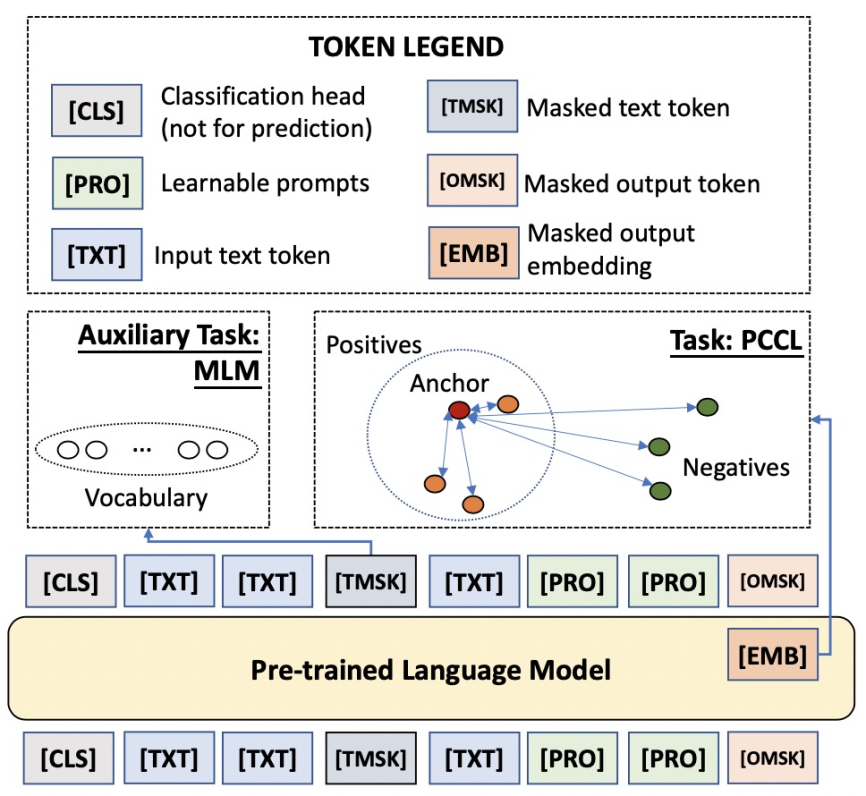
如上圖,CP-Tuning算法放棄了經(jīng)典算法中以“[MASK]”字符對應(yīng)預(yù)訓(xùn)練模型MLM Head的預(yù)測輸出作為分類依據(jù),而是參考對比學(xué)習(xí)的思路,將句子通過預(yù)訓(xùn)練模型后,以“[MASK]”字符通過預(yù)訓(xùn)練模型后的連續(xù)化表征作為features。在小樣本任務(wù)的訓(xùn)練階段,訓(xùn)練目標(biāo)為最小化同類樣本features的組內(nèi)距離,最大化非同類樣本的組間距離。在上圖中,[OMSK]即為我們所用于分類的“[MASK]”字符,其優(yōu)化的features表示為[EMB]。因此,CP-Tuning算法不需要定義分類的標(biāo)簽詞。在輸入側(cè),除了輸入文本和[OMSK],我們還加入了模版的字符[PRO]。與經(jīng)典算法不同,由于CP-Tuning不需要學(xué)習(xí)模版和標(biāo)簽詞之間的對應(yīng),我們直接將[PRO]初始化為任務(wù)無關(guān)的模版,例如“it is”。在模型訓(xùn)練過程中,[PRO]的表示可以在反向傳播過程中自動更新。除此之外,CP-Tuning還引入了輸入文本的Mask,表示為[TMSK],用于同時(shí)優(yōu)化輔助的MLM任務(wù),提升模型在小樣本學(xué)習(xí)場景下的泛化性。CP-Tuning算法的損失函數(shù)由兩部分組成:
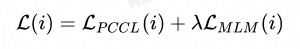
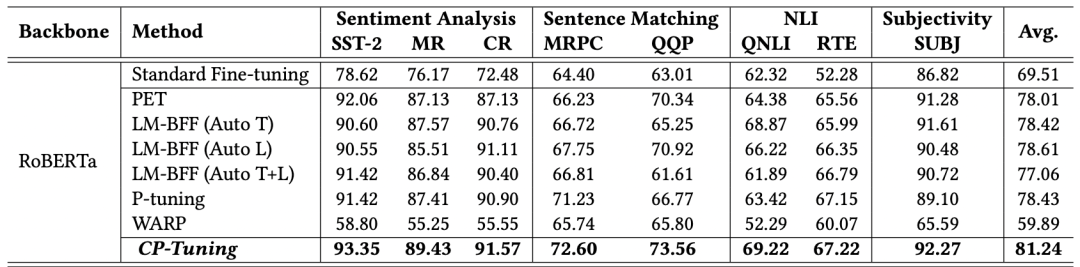
如上所示,兩個(gè)部分分別為Pair-wise Cost-sensitive Contrastive Loss(PCCL)和輔助的MLM損失。我們在多個(gè)GLUE小樣本數(shù)據(jù)集上進(jìn)行了驗(yàn)證,其中訓(xùn)練集中每個(gè)類別限制只有16個(gè)標(biāo)注樣本。從下述結(jié)果可以看出,CP-Tuning的精確度超越了經(jīng)典的小樣本學(xué)習(xí)算法,也比標(biāo)準(zhǔn)Fine-tuning算法的精確度高10%以上。
目前,除了我們自研的CP-Tuning算法之外,EasyNLP框架中集成了多種經(jīng)典小樣本學(xué)習(xí)算法例如PET、P-tuning等。
小樣本學(xué)習(xí)實(shí)踐詳見[3]。
4.大模型落地實(shí)踐
下面我們給出一個(gè)示例,將一個(gè)大的預(yù)訓(xùn)練模型(hfl/macbert-large-zh)在小樣本場景上落地,并且蒸餾到僅有1/100參數(shù)的小模型上。如下圖所示,一個(gè)大模型(3億參數(shù))在一個(gè)小樣本場景上原始的Accuracy為83.8%,通過小樣本學(xué)習(xí)可以提升7%,達(dá)到90.6%。同時(shí),如果用一個(gè)小模型(3百萬參數(shù))跑這個(gè)場景的話,效果僅有54.4%,可以把效果提升到71%(提升約17%),inference的時(shí)間相比大模型提升了10倍,模型參數(shù)僅為原來的1/100。
模型 | 參數(shù)量 | Dev Set指標(biāo)(Accuracy) | Batch Inference時(shí)間 | |
標(biāo)準(zhǔn)Finetune | hfl/macbert-large-zh | 325 Million | 0.8375 | 0.54s |
標(biāo)準(zhǔn)Finetune | alibaba-pai/pai-bert-tiny-zh | 3 Million | 0.54375 | 0.06s |
知識蒸餾Finetune | alibaba-pai/pai-bert-tiny-zh | 3 Million | 0.7125 | 0.06s |
小樣本Finetune | hfl/macbert-large-zh | 325 Million | 0.90625 | 0.53s |
代碼詳見[4]。
四、應(yīng)用案例
EasyNLP支撐了阿里巴巴集團(tuán)內(nèi)10個(gè)BU20多個(gè)業(yè)務(wù),同時(shí)過PAI的產(chǎn)品例如PAI-DLC、PAI-DSW、PAI Designer和PAI-EAS,給集團(tuán)用戶帶來高效的從訓(xùn)練到落地的完整體驗(yàn),同時(shí)也支持了云上客戶自定定制化模型和解決業(yè)務(wù)問題的需求。針對公有云用戶,對于入門級用戶PAI-Designer組件來通過簡單調(diào)參就可以完成NLP模型訓(xùn)練,對于高級開發(fā)者,可以使用AppZoo訓(xùn)練NLP模型,或者使用預(yù)置的預(yù)訓(xùn)練模型ModelZoo進(jìn)行finetune,對于資深開發(fā)者,提供豐富的API接口,支持用戶使用框架進(jìn)行定制化算法開發(fā),可以使用我們自帶的Trainer來提升訓(xùn)練效率,也可以自定義新的Trainer。
下面列舉幾個(gè)典型的案例:
- PAI團(tuán)隊(duì)和達(dá)摩院NLP團(tuán)隊(duì)[5]合作共建落地超大預(yù)訓(xùn)練模型(百億參數(shù)),推出自研小樣本學(xué)習(xí)算法CP-Tuning和模型稀疏化算法CAP。其中,這一自研CP-Tuning算法與AliceMind平臺集成, 實(shí)現(xiàn)了超大預(yù)訓(xùn)練模型的小樣本學(xué)習(xí),在在小樣本場景下,比標(biāo)準(zhǔn)Fine-tune精準(zhǔn)度提升10%以上;
- PAI團(tuán)隊(duì)和達(dá)摩院合作在FewCLUE小樣本學(xué)習(xí)榜單上獲得冠軍,甚至一個(gè)小樣本學(xué)習(xí)任務(wù)上的精準(zhǔn)度超過了人類。同時(shí),阿里巴巴某BU使用ToB客戶服務(wù)場景下的業(yè)務(wù)數(shù)據(jù)在EasyNLP框架下進(jìn)行小樣本學(xué)習(xí)算法學(xué)習(xí),在業(yè)務(wù)數(shù)據(jù)上相比Baseline,提升實(shí)體識別的準(zhǔn)確度2%以上,提升屬性識別的準(zhǔn)確度5%以上;
- 針對公有云客戶對文本分類功能的小模型、高QPS需求,基于EasyNLP框架的知識蒸餾功能,采用某預(yù)訓(xùn)練模型作為教師模型(參數(shù)量3億)、PAI-BERT中文小預(yù)訓(xùn)練模型作為學(xué)生模型(參數(shù)量4百萬),蒸餾得到這一小模型上線,參數(shù)量約為原有模型的百分之一,精度損失在10%以內(nèi);基于此,我們集成了知識蒸餾功能,助力大模型在實(shí)際業(yè)務(wù)場景下落地;
- 在風(fēng)控場景,我們收集了約一億的中文預(yù)訓(xùn)練數(shù)據(jù),基于EasyNLP預(yù)訓(xùn)練了一個(gè)PAI-BERT中文模型,在風(fēng)控?cái)?shù)據(jù)上取得了非常不錯(cuò)的效果,提升了10%以上的準(zhǔn)確率和召回率;基于此,我們在公有云上也推出了文本風(fēng)控解決方案[6],在多個(gè)客戶場景里落地并取得不錯(cuò)的效果;
- 隨著UGC等用戶生成內(nèi)容不斷涌現(xiàn),對從文本提取標(biāo)簽用于細(xì)粒度分析的需求不斷涌現(xiàn);采用基于EasyNLP預(yù)訓(xùn)練中文模型,在新聞數(shù)據(jù)的超過300個(gè)類別的文本標(biāo)簽預(yù)測準(zhǔn)確率超過80%;基于此,我們集成了文本標(biāo)簽預(yù)測,關(guān)鍵詞抽取,和實(shí)體詞提取等功能,在公有云上推出了通用文本打標(biāo)解決方案[7],并且在多個(gè)典型客戶場景里成功落地,服務(wù)于智能推薦等應(yīng)用場景。
五、RoadMap
- 基于EasyNLP的中文CLUE/FewCLUE等的Benchmark
- 知識預(yù)訓(xùn)練技術(shù): 發(fā)布一系列知識預(yù)訓(xùn)練模型,致力于提升預(yù)訓(xùn)練模型的常識性和知識性
- 中文預(yù)訓(xùn)練模型:發(fā)布針對中文的SOTA的預(yù)訓(xùn)練模型,降低中文預(yù)訓(xùn)練技術(shù)門檻
- 多模態(tài)預(yù)訓(xùn)練:發(fā)布針對中文的多模態(tài)預(yù)訓(xùn)練模型
- 中文數(shù)據(jù)的收集和API接口:收集常用的中文數(shù)據(jù),提供預(yù)處理和訓(xùn)練接口
- 垂直場景的SOTA中文模型整合:針對垂直業(yè)務(wù)場景,整合效果最好的中文模型
- 發(fā)布解決方案和PAI組件
項(xiàng)目開源地址:https://github.com/alibaba/EasyNLP
參考文獻(xiàn)
[AAAI 22] DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding. https://arxiv.org/abs/2112.01047
[ACL 2021] Meta-KD: A Meta Knowledge Distillation Framework for Language Model Compression across Domains. https://arxiv.org/abs/2012.01266
[arXiv] Making Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning:https://arxiv.org/pdf/2204.00166
[AAAI 22] From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression. https://arxiv.org/abs/2112.07198
[EMNLP 2021] TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification. https://aclanthology.org/2021.emnlp-main.221/
[CIKM 2021]. EasyTransfer -- A Simple and Scalable Deep Transfer Learning Platform for NLP Applications. https://github.com/alibaba/EasyTransfer
[1]https://github.com/alibaba/EasyNLP
[2]https://github.com/alibaba/EasyNLP/tree/master/examples/knowledge_distillation[3]https://github.com/alibaba/EasyNLP/tree/master/examples/fewshot_learning[4]https://github.com/alibaba/EasyNLP/tree/master/examples/landing_large_ptms[5]達(dá)摩院NLP團(tuán)隊(duì):https://github.com/alibaba/AliceMind
[6]文本風(fēng)控解決方案:https://help.aliyun.com/document_detail/311210.html[7]通用文本打標(biāo)解決方案:https://help.aliyun.com/document_detail/403700.html


























