













訪問數據庫總超時?這份避坑指南請收好

本文轉載自微信公眾號「數倉寶貝庫」,作者李玥 。轉載本文請聯系數倉寶貝庫公眾號。
01事故排查過程
電商公司大都希望做社交引流,社交公司大都希望做電商,從而將流量變現,所以社交電商一直是熱門的創業方向。這個真實的案例來自某家做社交電商的創業公司。下面就來一起看下這個典型的數據庫超時案例。
從圣誕節平安夜開始,每天晚上固定十點到十一點這個時間段,該公司的系統會癱瘓一個小時左右的時間,過了這個時間段,系統就會自動恢復正常。系統癱瘓時,網頁和App都打不開,數據庫服務請求超時。
如圖1所示,該公司的系統架構是一個非常典型的小型創業公司的微服務架構。
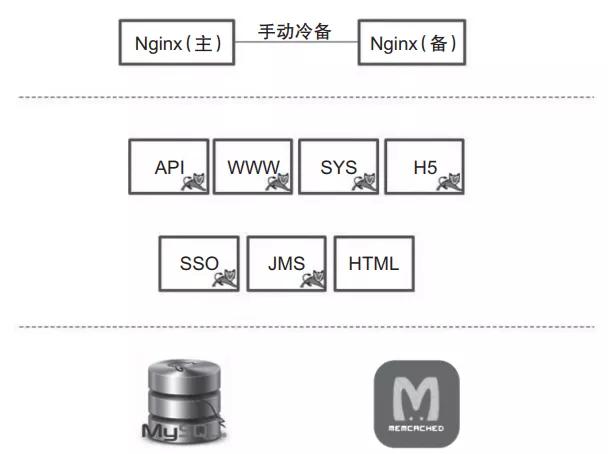
圖1 典型的小型創業公司系統架構
該公司將整個系統托管在公有云上,Nginx作為前置網關承接前端的所有請求。后端根據業務,劃分了若干個微服務分別進行部署。數據保存在MySQL數據庫中,部分數據用Memcached做了前置緩存。數據并沒有按照微服務最佳實踐的要求,進行嚴格的劃分和隔離,而是為了方便,存放在了一起。
這種存儲設計方式,對于一個業務變化極快的創業公司來說是比較合理的。因為它的每個微服務,隨時都在隨著業務需求的變化而發生改變,如果做了嚴格的數據隔離,反而不利于應對需求的變化。
開始分析這個案例時,我首先注意到的一個關鍵現象是,每天晚上十點到十一點這個時間段,是絕大多數內容類App訪問量的高峰期。因為這個時間段很多人都會躺在床上玩手機,因此我初步判斷,這個故障可能與訪問量有關。圖2所示的是該系統每天各個時間段的訪問量趨勢圖,正好可以印證我的初步判斷。
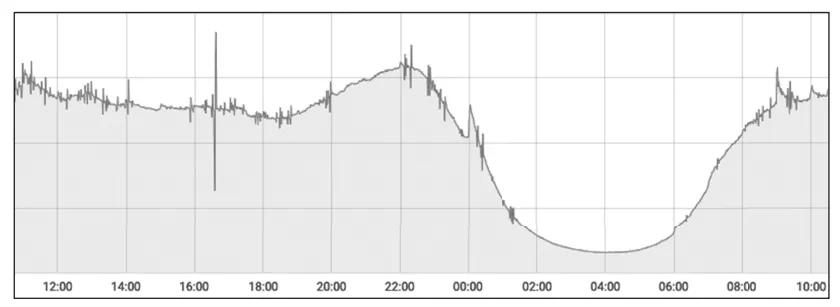
圖2 系統訪問量
基于這個判斷,排查問題的重點應該放在那些服務于用戶訪問的功能上,比如,首頁、商品列表頁、內容推薦等功能。
在訪問量達到峰值的時候,請求全部超時。而隨著訪問量的減少,系統又能自動恢復,因此基本上可以排除后臺服務被大量請求沖垮,進程僵死或退出的可能性。因為如果進程出現這種情況,一般是不會自動恢復的。排查問題的重點應該放在MySQL上。
觀察圖3所示的MySQL服務器各時段的CPU利用率監控圖,我們可以發現其中的問題。從監控圖上可以看出,故障時段MySQL的CPU利用率一直是100%。這種情況下,MySQL基本上處于不可用的狀態,執行所有的SQL都會超時。在MySQL中,這種CPU利用率高的現象,絕大多數情況下都是由慢SQL導致的,所以需要優先排查慢SQL。MySQL和各大云廠商提供的RDS(關系型數據庫服務)都能提供慢SQL日志,分析慢SQL日志,是查找造成類似問題的原因最有效的方法。
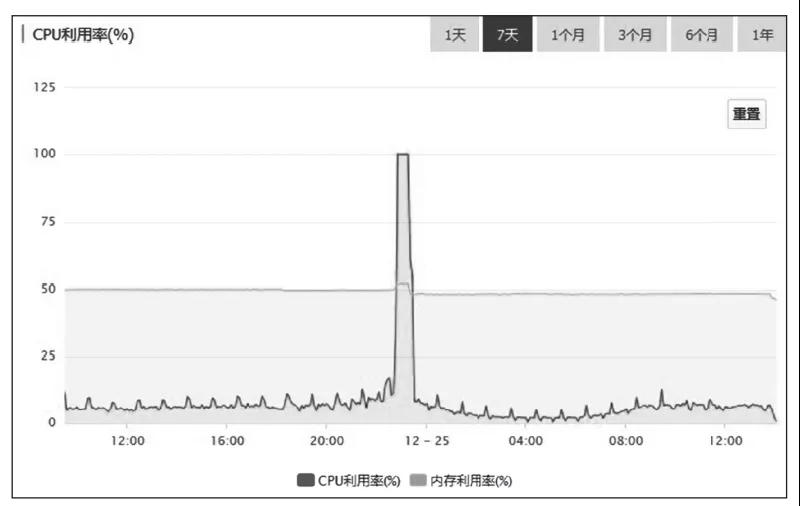
圖3 MySQL服務器各時段的CPU利用率監控圖
一般來說,慢SQL日志中,會包含這樣一些信息:SQL語句、執行次數、執行時長。通過分析慢SQL查找問題,并沒有什么標準的方法,主要還是依靠經驗。
首先,我們需要知道的一點是,當數據庫非常忙的時候,任何一個SQL的執行都會很慢。所以并不是說,慢SQL日志中記錄的這些慢SQL都是有問題的SQL。大部分情況下,導致問題的SQL只是其中的一條或幾條,不能簡單地依據執行次數和執行時長進行判斷。但是,單次執行時間特別長的SQL,仍然是應該重點排查的對象。
通過分析這個系統的慢SQL日志,我首先找到了一條特別慢的SQL。以下代碼是這條SQL的完整語句:
- 1select fo.FollowId as vid, count(fo.id) as vcounts
- 2
- 3from follow fo, user_info ui
- 4
- 5where fo.userid = ui.userid
- 6
- 7and fo.CreateTime between
- 8
- 9str_to_date(?, '%Y-%m-%d %H:%i:%s')
- 10
- 11and str_to_date(?, '%Y-%m-%d %H:%i:%s')
- 12
- 13and fo.IsDel = 0
- 14
- 15and ui.UserState = 0
- 16
- 17group by vid
- 18
- 19order by vcounts desc
- 20
- 21limit 0,10
這條SQL支撐的功能是一個“網紅”排行榜,用于排列出“粉絲”數最多的前10名“網紅”。
請注意,這種排行榜的查詢,一定要做緩存。在上述案例中,排行榜是新上線的功能,由于沒有做緩存,導致訪問量高峰時間段服務卡死,因此增加緩存應該可以有效解決上述問題。
為排行榜增加緩存后,新版本立即上線。本以為問題就此可以得到解決,結果到了晚高峰時間段,系統仍然出現了各種請求超時,頁面打不開的問題。
再次分析慢SQL日志,我發現排行榜的慢SQL不見了,說明緩存生效了。日志中的其他慢SQL,查詢次數和查詢時長的分布都很均勻,找不到明顯有問題的SQL。
于是,我再次查看MySQL服務器各時段的CPU利用率監控圖,如圖4所示。
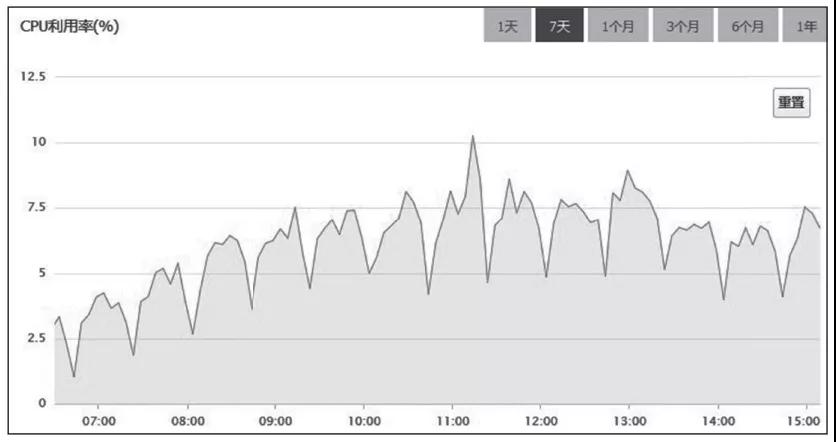
圖4 系統增加緩存后,MySQL服務器各時段的CPU利用率
把圖放大后,我又從中發現了如下兩點規律。
1)CPU利用率,以20分鐘為周期,非常有規律地進行波動。
2)總體的趨勢與訪問量正相關。
那么,我們是不是可以猜測一下,如圖5所示,MySQL服務器的CPU利用率監控圖的波形主要由兩個部分構成:參考線以下的部分,是正常處理日常訪問請求的部分,它與訪問量是正相關的;參考線以上的部分,來自某個以20分鐘為周期的定時任務,與訪問量關系不大。
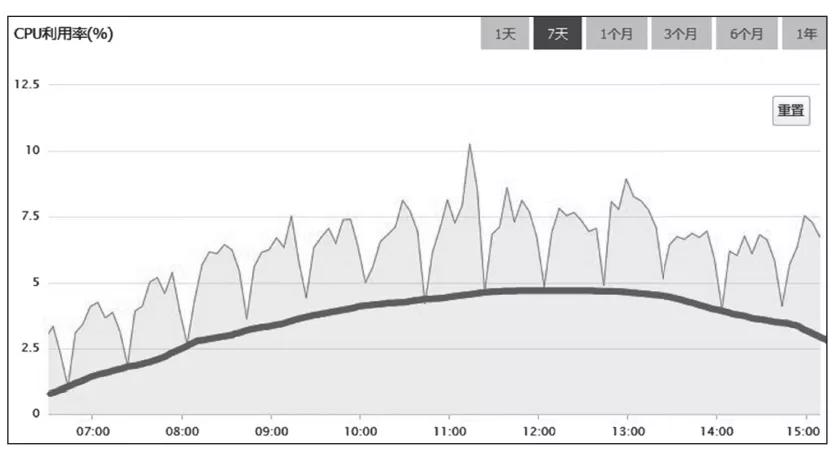
圖5 系統增加緩存后,MySQL服務器各時段的CPU利用率(附帶參考線)
排查整個系統,并未發現有以20分鐘為周期的定時任務,繼續擴大排查范圍,排查周期小于20分鐘的定時任務,最后終于定位到了問題所在。
該公司App的首頁聚合了大量的內容,比如,精選商品、標題圖、排行榜、編輯推薦,等等。這些內容會涉及大量的數據庫查詢操作。該系統在設計之初,為首頁做了一個整體的緩存,緩存的過期時間是10分鐘。但是隨著需求的不斷變化,首頁上需要查詢的內容越來越多,導致查詢首頁的全部內容變得越來越慢。
通過檢查日志可以發現,刷新一次緩存的時間竟然長達15分鐘。緩存是每隔10分鐘整點刷新一次,因為10分鐘內刷不完,所以下次刷新就推遲到了20分鐘之后,這就導致了圖5中,參考線以上每20分鐘一個周期的規律波形。由于緩存的刷新比較慢,導致很多請求無法命中緩存,因此大量請求只能穿透緩存直接查詢數據庫。圖9-5中參考線以下的部分,包含了很多這類請求占用的CPU利用率。
找到了問題的原因所在,下面就來進行針對性的優化,問題很快就得到了解決。新版本上線之后,再也沒有出現過“午夜宕機”的問題。如
圖6所示,對比優化前后MySQL服務器的CPU利用率,可以看出,優化的效果非常明顯。
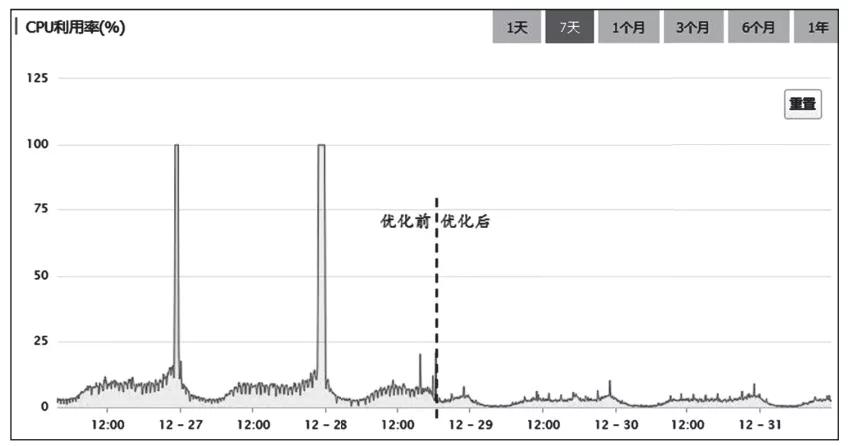
圖6 優化前后MySQL服務器的CPU利用率對比
02如何避免悲劇重演
至此,導致問題的原因找到了,問題也得到了圓滿解決。單從這個案例來看,問題的原因在于,開發人員在編寫SQL時,沒有考慮數據量和執行時間,緩存的使用也不合理。最終導致在訪問高峰期時,MySQL服務器被大量的查詢請求卡死,而無法提供服務。
作為系統的開發人員,對于上述問題,我們可以總結出如下兩點經驗。
第一,在編寫SQL的時候,一定要小心謹慎、仔細評估,首先思考如下三個問題。
- SQL所涉及的表,其數據規模是多少?
- SQL可能會遍歷的數據量是多少?
- 如何盡量避免寫出慢SQL?
第二,能不能利用緩存減少數據庫查詢的次數?在使用緩存的時候,我們需要特別注意緩存命中率,應盡量避免請求因為命中不了緩存,而直接穿透到數據庫上。
不過,我們無法保證,整個團隊的所有開發人員以后都不會再犯這類錯誤。但是,這并不意味著,上述問題就無法避免了,否則大企業的服務系統會因為每天上線大量的BUG而無法正常工作。實際情況是,大企業的系統通常都是比較穩定的,基本上不會出現全站無法訪問的問題,這要歸功于其優秀的系統架構。優秀的系統架構,可以在一定程度上,減輕故障對系統的影響。
針對這次事故,我在系統架構層面,為該公司提了兩條改進的建議。
第一條建議是,上線一個定時監控和殺掉慢SQL的腳本。這個腳本每分鐘執行一次,檢測在上一分鐘內,有沒有執行時間超過一分鐘(這個閾值可以根據實際情況進行調整)的慢SQL,如果發現,就直接殺掉這個會話。
這樣可以有效地避免因為一個慢SQL而拖垮整個數據庫的悲劇。即使出現慢SQL,數據庫也可以在至多1分鐘內自動恢復,從而避免出現數據庫長時間不可用的問題。不過,這樣做也是有代價的,可能會導致某些功能,之前運行是正常的,在這個腳本上線后卻出現了問題。但是,總體來說,這個代價還是值得付出的,同時也可以反過來督促開發人員,使其更加小心謹慎,避免寫出慢SQL。
第二條建議是,將首面做成一個簡單的靜態頁面,作為降級方案,首頁上只要包含商品搜索欄、大的品類和其他頂級功能模塊入口的鏈接就可以了。在Nginx上實現一個策略,如果請求首頁數據超時,則直接返回這個靜態頁面的首頁作為替代。后續即使首頁再出現任何故障,也可以暫時降級,用靜態首頁替代,至少不會影響到用戶使用其他功能。
這兩條改進建議的實施都是非常容易的,不需要對系統進行很大的改造,而且效果也是立竿見影的。
當然,這個系統的存儲架構還有很多可以改進的地方,比如,對數據做適當的隔離,改進緩存置換策略,將數據庫升級為主從部署,把非業務請求的數據庫查詢遷移到單獨的從庫上,等等,只是這些改進都需要對系統做出比較大的改動升級,需要從長計議之后再在系統后續的迭代過程中逐步實施。
03小結
本文分析了一個由于慢SQL導致網站服務器訪問故障的案例。在“破案”的過程中,我分享了一些很有用的經驗,這些經驗對于大家在工作中遇到類似問題時會有很大的參考作用。下面再來梳理一下這些經驗。
1)根據故障時段出現在系統繁忙時這一現象,推斷出故障原因與支持用戶訪問的功能有關。
2)根據系統能在流量峰值過后自動恢復這一現象,排除后臺服務被大量請求沖垮的可能性。
3)根據服務器的CPU利用率曲線的規律變化,推斷出故障原因可能與定時任務有關。
在故障復盤階段,我們針對故障問題本身的原因,做了針對性的預防和改進,除此之外,更重要的是,在系統架構層面也進行了改進,整個系統變得更加健壯,不至于因為某個小的失誤,就導致出現全站無法訪問的問題。
我為該系統提出的第一個建議是定時自動殺死慢SQL,原因是:系統的關鍵部分要有自我保護機制,以避免因為外部的錯誤而影響到系統的關鍵部分。第二個建議是首頁降級,原因是:當關鍵系統出現故障的時候,要有臨時的降級方案,以盡量減少故障造成的不良影響。
這些架構上的改進措施,雖然不能完全避免故障,但是可以在很大程度上減小故障的影響范圍,減輕故障帶來的損失,希望大家能夠仔細體會,活學活用。
關于作者:李玥,美團基礎技術部高級技術專家,極客時間《后端存儲實戰課》《消息隊列高手課》等專欄作者。曾在當當網、京東零售等公司任職。從事互聯網電商行業基礎架構領域的架構設計和研發工作多年,曾多次參與雙十一和618電商大促。專注于分布式存儲、云原生架構下的服務治理、分布式消息和實時計算等技術領域,致力于推進基礎架構技術的創新與開源。
本文摘編自《電商存儲系統實戰:架構設計與海量數據處理》,經出版方授權發布。(ISBN:9787111697411)轉載請保留文章出處。




















