













不會(huì)一致性 Hash 算法,勸你簡(jiǎn)歷別寫搞過負(fù)載均衡

本文轉(zhuǎn)載自微信公眾號(hào)「程序員內(nèi)點(diǎn)事」,作者程序員內(nèi)點(diǎn)事。轉(zhuǎn)載本文請(qǐng)聯(lián)系程序員內(nèi)點(diǎn)事公眾號(hào)。
這兩天看到技術(shù)群里,有小伙伴在討論一致性hash算法的問題,正愁沒啥寫的題目就來(lái)了,那就簡(jiǎn)單介紹下它的原理。下邊我們以分布式緩存中經(jīng)典場(chǎng)景舉例,面試中也是經(jīng)常提及的一些話題,看看什么是一致性hash算法以及它有那些過人之處。
構(gòu)建場(chǎng)景
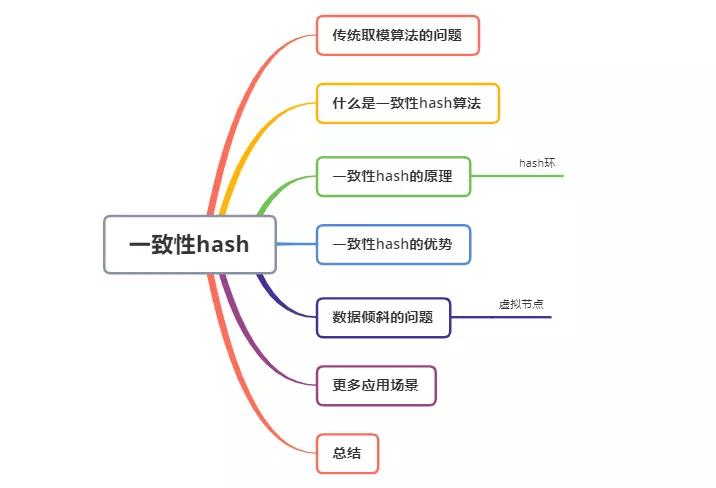
假如我們有三臺(tái)緩存服務(wù)器編號(hào)node0、node1、node2,現(xiàn)在有3000萬(wàn)個(gè)key,希望可以將這些個(gè)key均勻的緩存到三臺(tái)機(jī)器上,你會(huì)想到什么方案呢?
我們可能首先想到的方案,是取模算法hash(key)% N,對(duì)key進(jìn)行hash運(yùn)算后取模,N是機(jī)器的數(shù)量。key進(jìn)行hash后的結(jié)果對(duì)3取模,得到的結(jié)果一定是0、1或者2,正好對(duì)應(yīng)服務(wù)器node0、node1、node2,存取數(shù)據(jù)直接找對(duì)應(yīng)的服務(wù)器即可,簡(jiǎn)單粗暴,完全可以解決上述的問題。
hash的問題
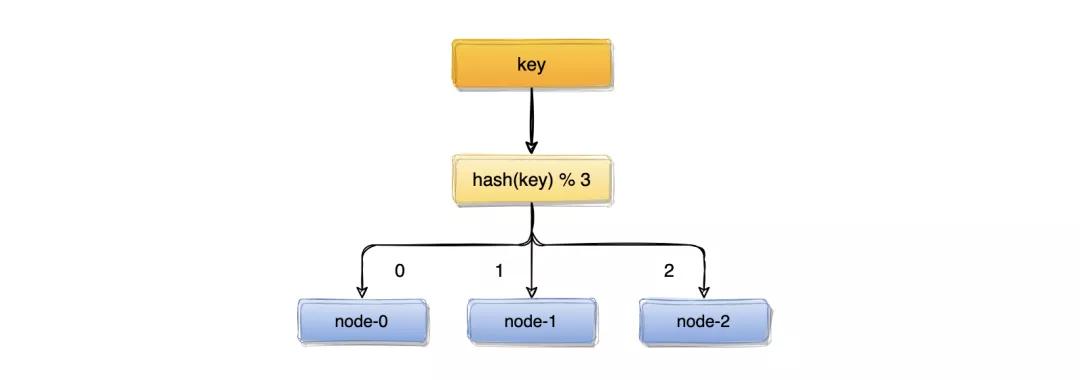
取模算法雖然使用簡(jiǎn)單,但對(duì)機(jī)器數(shù)量取模,在集群擴(kuò)容和收縮時(shí)卻有一定的局限性,因?yàn)樵谏a(chǎn)環(huán)境中根據(jù)業(yè)務(wù)量的大小,調(diào)整服務(wù)器數(shù)量是常有的事;而服務(wù)器數(shù)量N發(fā)生變化后hash(key)% N計(jì)算的結(jié)果也會(huì)隨之變化。
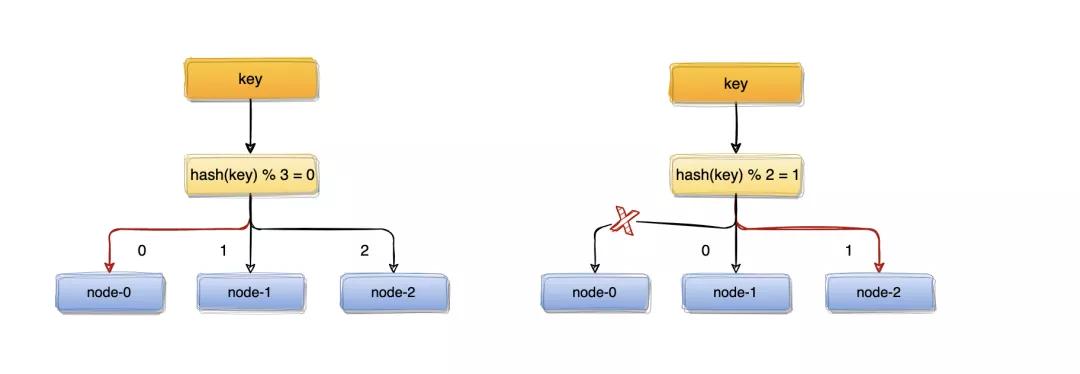
比如:一個(gè)服務(wù)器節(jié)點(diǎn)掛了,計(jì)算公式從hash(key)% 3變成了hash(key)% 2,結(jié)果會(huì)發(fā)生變化,此時(shí)想要訪問一個(gè)key,這個(gè)key的緩存位置大概率會(huì)發(fā)生改變,那么之前緩存key的數(shù)據(jù)也會(huì)失去作用與意義。
大量緩存在同一時(shí)間失效,造成緩存的雪崩,進(jìn)而導(dǎo)致整個(gè)緩存系統(tǒng)的不可用,這基本上是不能接受的,為了解決優(yōu)化上述情況,一致性hash算法應(yīng)運(yùn)而生。
那么,一致性哈希算法又是如何解決上述問題的?
一致性hash
一致性hash算法本質(zhì)上也是一種取模算法,不過,不同于上邊按服務(wù)器數(shù)量取模,一致性hash是對(duì)固定值2^32取模。
IPv4的地址是4組8位2進(jìn)制數(shù)組成,所以用2^32可以保證每個(gè)IP地址會(huì)有唯一的映射。
hash環(huán)
我們可以將這2^32個(gè)值抽象成一個(gè)圓環(huán)??(不得意圓的,自己想個(gè)形狀,好理解就行),圓環(huán)的正上方的點(diǎn)代表0,順時(shí)針排列,以此類推,1、2、3、4、5、6……直到2^32-1,而這個(gè)由2的32次方個(gè)點(diǎn)組成的圓環(huán)統(tǒng)稱為hash環(huán)。
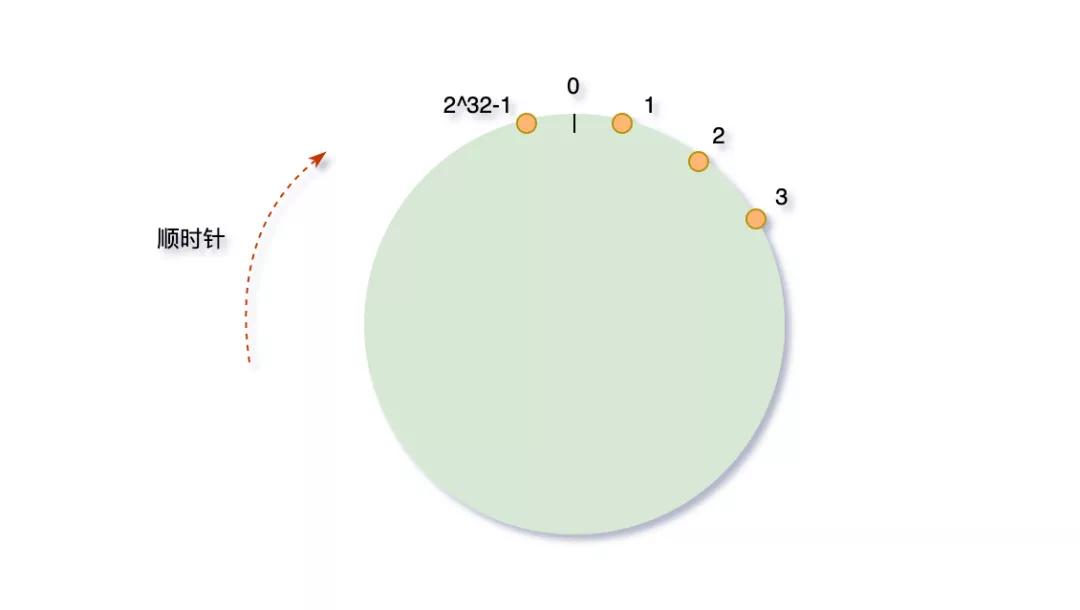
那么這個(gè)hash環(huán)和一致性hash算法又有什么關(guān)系嘞?我們還是以上邊的場(chǎng)景為例,三臺(tái)緩存服務(wù)器編號(hào)node0、node1、node2,3000萬(wàn)個(gè)key。
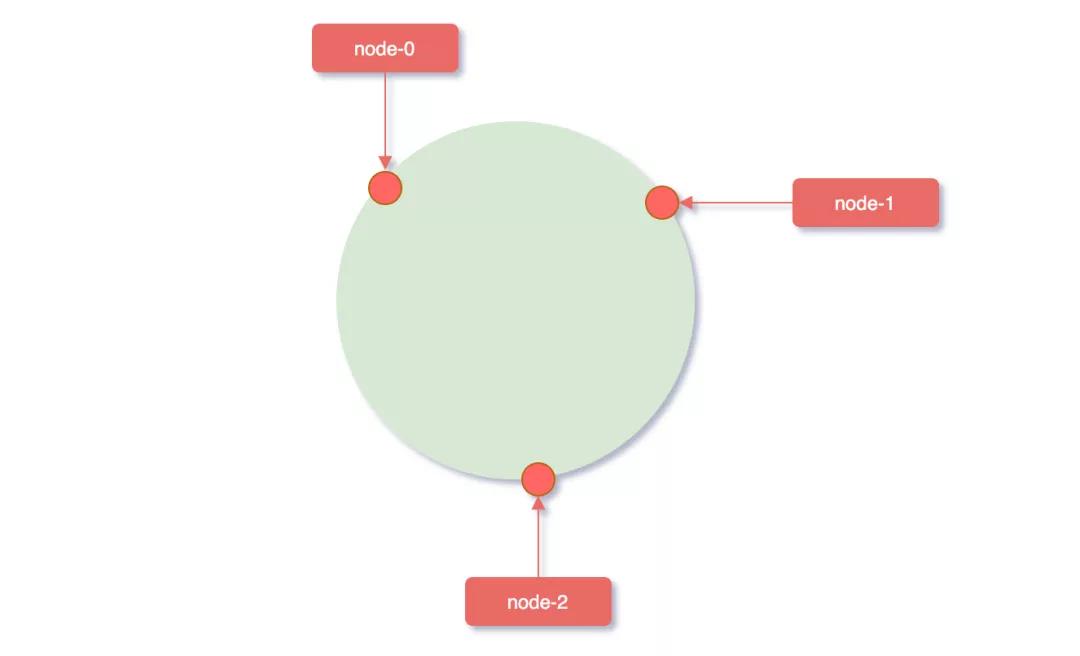
服務(wù)器映射到hash環(huán)
這個(gè)時(shí)候計(jì)算公式就從hash(key)% N 變成了hash(服務(wù)器ip)% 2^32,使用服務(wù)器IP地址進(jìn)行hash計(jì)算,用哈希后的結(jié)果對(duì)2^32取模,結(jié)果一定是一個(gè)0到2^32-1之間的整數(shù),而這個(gè)整數(shù)映射在hash環(huán)上的位置代表了一個(gè)服務(wù)器,依次將node0、node1、node2三個(gè)緩存服務(wù)器映射到hash環(huán)上。
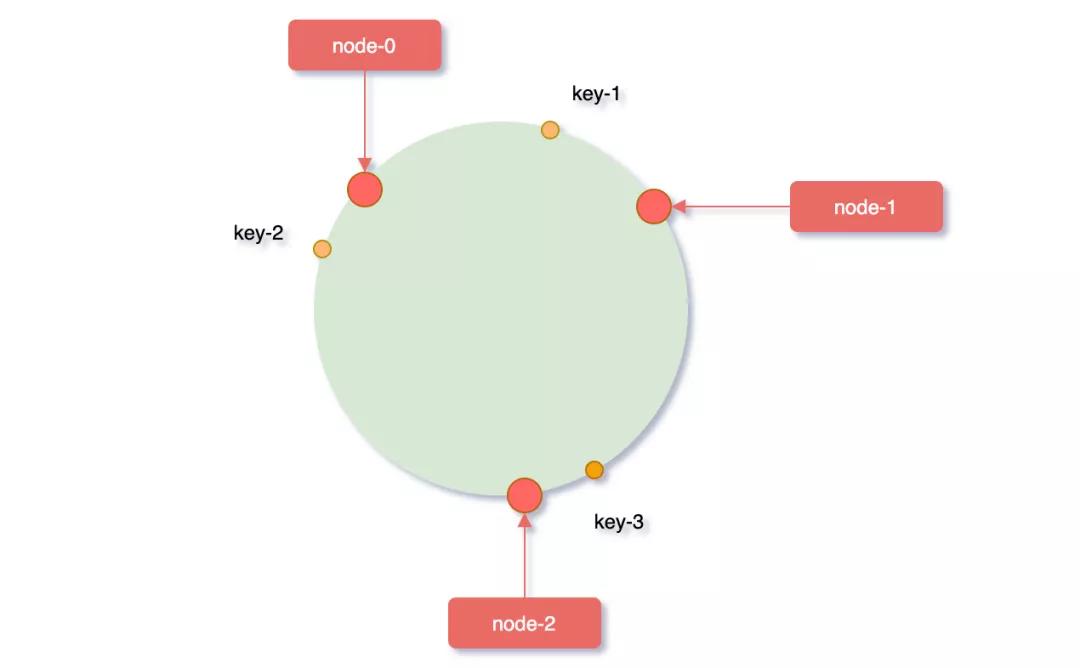
對(duì)象key映射到hash環(huán)
接著在將需要緩存的key對(duì)象也映射到hash環(huán)上,hash(key)% 2^32,服務(wù)器節(jié)點(diǎn)和要緩存的key對(duì)象都映射到了hash環(huán),那對(duì)象key具體應(yīng)該緩存到哪個(gè)服務(wù)器上呢?
對(duì)象key映射到服務(wù)器
“從緩存對(duì)象key的位置開始,沿順時(shí)針方向遇到的第一個(gè)服務(wù)器,便是當(dāng)前對(duì)象將要緩存到的服務(wù)器。
因?yàn)楸痪彺鎸?duì)象與服務(wù)器hash后的值是固定的,所以,在服務(wù)器不變的條件下,對(duì)象key必定會(huì)被緩存到固定的服務(wù)器上。根據(jù)上邊的規(guī)則,下圖中的映射關(guān)系:
- key-1 -> node-1
- key-3 -> node-2
- key-4 -> node-2
- key-5 -> node-2
- key-2 -> node-0
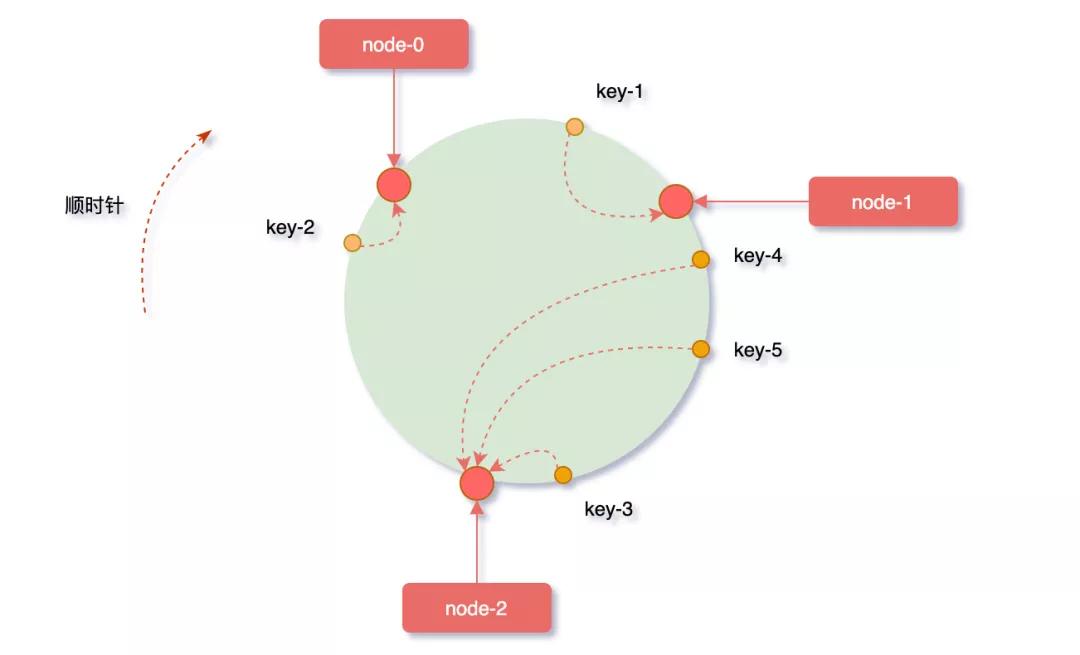
如果想要訪問某個(gè)key,只要使用相同的計(jì)算方式,即可得知這個(gè)key被緩存在哪個(gè)服務(wù)器上了。
一致性hash的優(yōu)勢(shì)
我們簡(jiǎn)單了解了一致性hash的原理,那它又是如何優(yōu)化集群中添加節(jié)點(diǎn)和縮減節(jié)點(diǎn),普通取模算法導(dǎo)致的緩存服務(wù),大面積不可用的問題呢?
先來(lái)看看擴(kuò)容的場(chǎng)景,假如業(yè)務(wù)量激增,系統(tǒng)需要進(jìn)行擴(kuò)容增加一臺(tái)服務(wù)器node-4,剛好node-4被映射到node-1和node-2之間,沿順時(shí)針方向?qū)ο笥成涔?jié)點(diǎn),發(fā)現(xiàn)原本緩存在node-2上的對(duì)象key-4、key-5被重新映射到了node-4上,而整個(gè)擴(kuò)容過程中受影響的只有node-4和node-1節(jié)點(diǎn)之間的一小部分?jǐn)?shù)據(jù)。
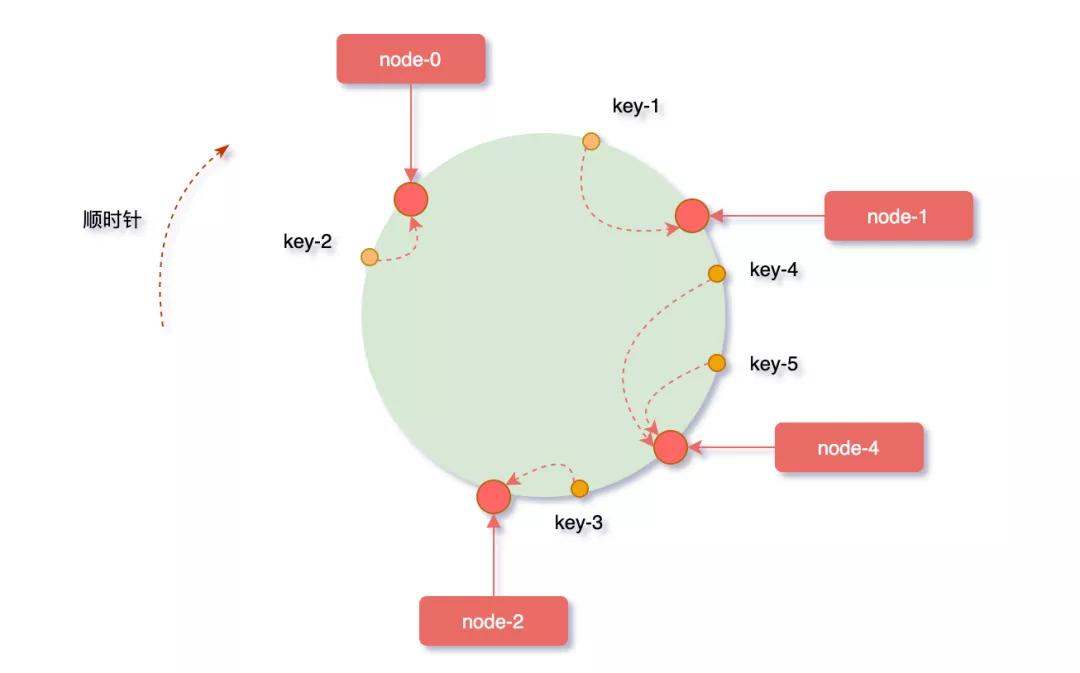
反之,假如node-1節(jié)點(diǎn)宕機(jī),沿順時(shí)針方向?qū)ο笥成涔?jié)點(diǎn),緩存在node-1上的對(duì)象key-1被重新映射到了node-4上,此時(shí)受影響的數(shù)據(jù)只有node-0和node-1之間的一小部分?jǐn)?shù)據(jù)。
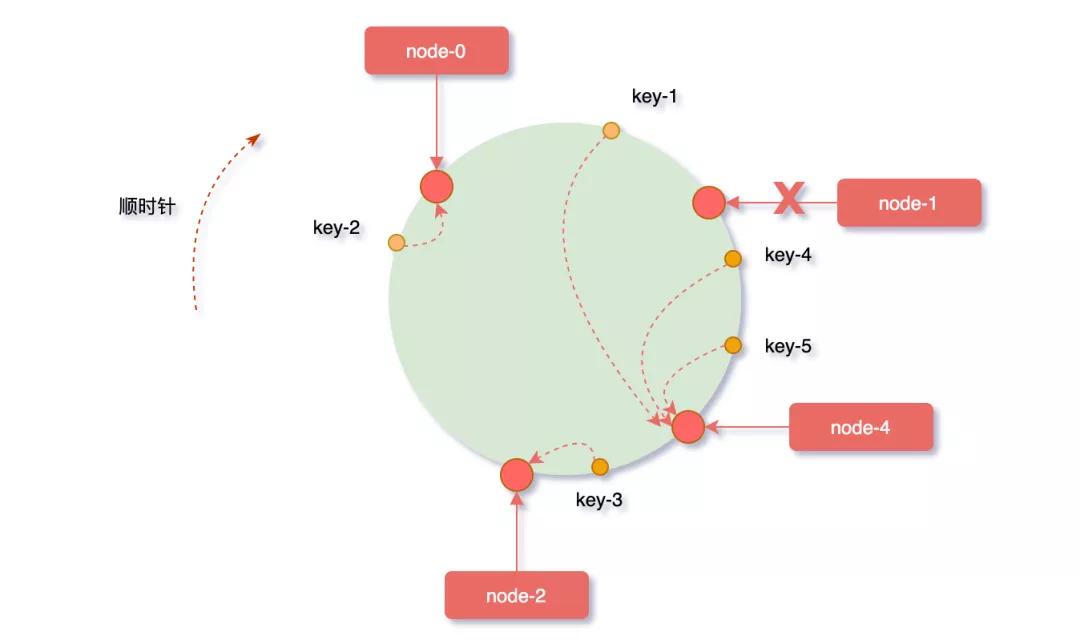
從上邊的兩種情況發(fā)現(xiàn),當(dāng)集群中服務(wù)器的數(shù)量發(fā)生改變時(shí),一致性hash算只會(huì)影響少部分的數(shù)據(jù),保證了緩存系統(tǒng)整體還可以對(duì)外提供服務(wù)的。
數(shù)據(jù)偏斜問題
前邊為了便于理解原理,畫圖中的node節(jié)點(diǎn)都很理想化的相對(duì)均勻分布,但理想和實(shí)際的場(chǎng)景往往差別很大,就比如辦了個(gè)健身年卡的我,只去過健身房?jī)纱危€只是洗了個(gè)澡。

想要健身的你
在服務(wù)器節(jié)點(diǎn)數(shù)量太少的情況下,很容易因?yàn)楣?jié)點(diǎn)分布不均勻而造成數(shù)據(jù)傾斜問題,如下圖被緩存的對(duì)象大部分緩存在node-4服務(wù)器上,導(dǎo)致其他節(jié)點(diǎn)資源浪費(fèi),系統(tǒng)壓力大部分集中在node-4節(jié)點(diǎn)上,這樣的集群是非常不健康的。
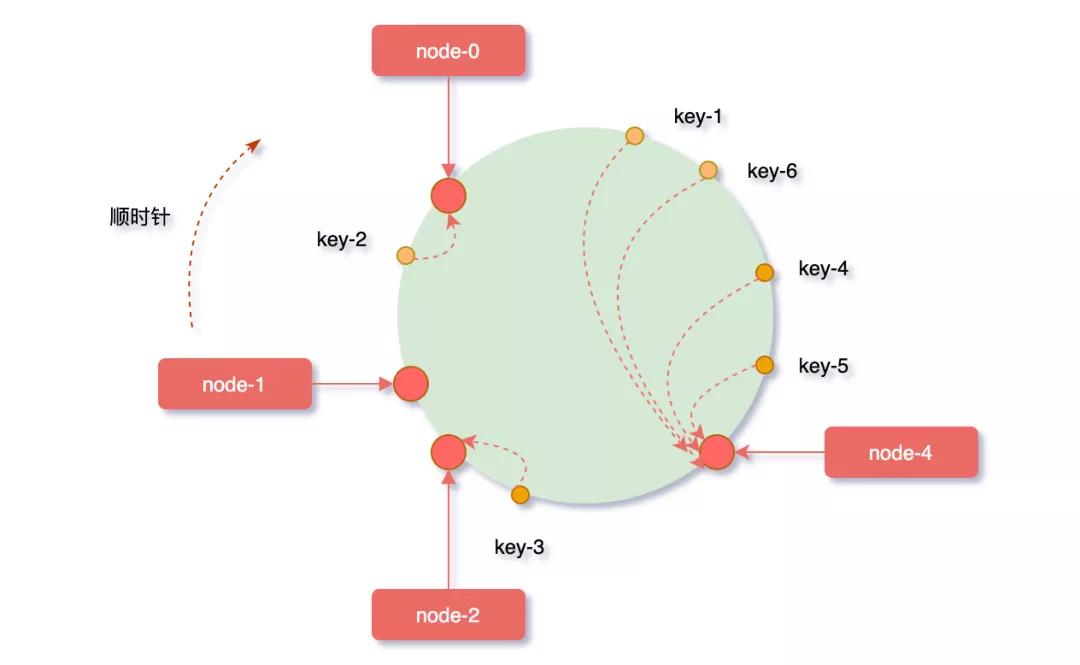
解決數(shù)據(jù)傾斜的辦法也簡(jiǎn)單,我們就要想辦法讓節(jié)點(diǎn)映射到hash環(huán)上時(shí),相對(duì)分布均勻一點(diǎn)。
一致性Hash算法引入了一個(gè)虛擬節(jié)點(diǎn)機(jī)制,即對(duì)每個(gè)服務(wù)器節(jié)點(diǎn)計(jì)算出多個(gè)hash值,它們都會(huì)映射到hash環(huán)上,映射到這些虛擬節(jié)點(diǎn)的對(duì)象key,最終會(huì)緩存在真實(shí)的節(jié)點(diǎn)上。
虛擬節(jié)點(diǎn)的hash計(jì)算通常可以采用,對(duì)應(yīng)節(jié)點(diǎn)的IP地址加數(shù)字編號(hào)后綴 hash(10.24.23.227#1) 的方式,舉個(gè)例子,node-1節(jié)點(diǎn)IP為10.24.23.227,正常計(jì)算node-1的hash值。
- hash(10.24.23.227#1)% 2^32
假設(shè)我們給node-1設(shè)置三個(gè)虛擬節(jié)點(diǎn),node-1#1、node-1#2、node-1#3,對(duì)它們進(jìn)行hash后取模。
- hash(10.24.23.227#1)% 2^32
- hash(10.24.23.227#2)% 2^32
- hash(10.24.23.227#3)% 2^32
下圖加入虛擬節(jié)點(diǎn)后,原有節(jié)點(diǎn)在hash環(huán)上分布的就相對(duì)均勻了,其余節(jié)點(diǎn)壓力得到了分?jǐn)偂?/p>
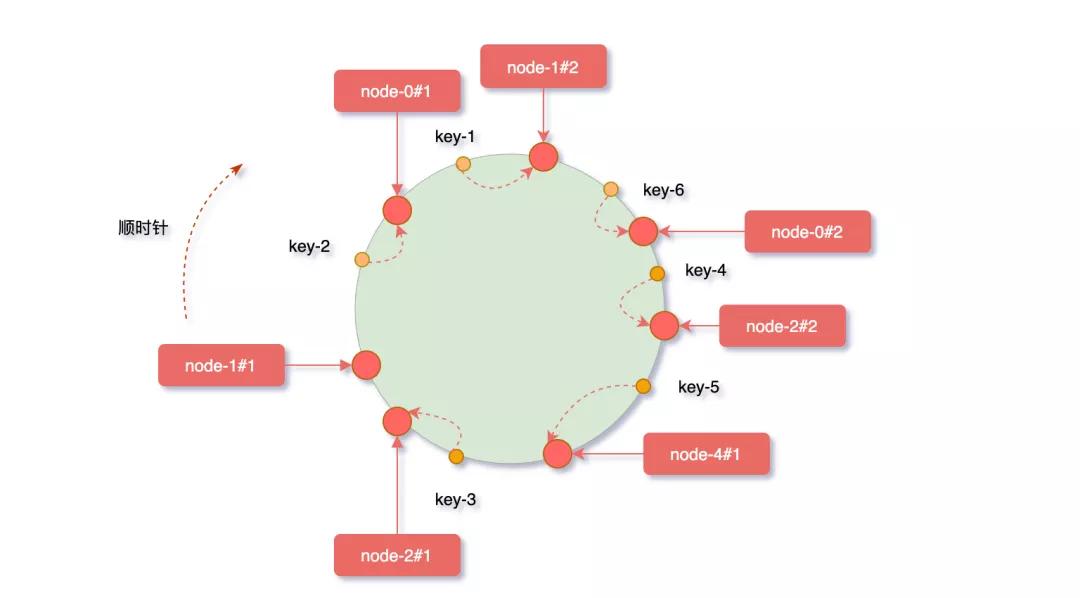
“但需要注意一點(diǎn),分配的虛擬節(jié)點(diǎn)個(gè)數(shù)越多,映射在hash環(huán)上才會(huì)越趨于均勻,節(jié)點(diǎn)太少的話很難看出效果。
引入虛擬節(jié)點(diǎn)的同時(shí)也增加了新的問題,要做虛擬節(jié)點(diǎn)和真實(shí)節(jié)點(diǎn)間的映射,對(duì)象key->虛擬節(jié)點(diǎn)->實(shí)際節(jié)點(diǎn)之間的轉(zhuǎn)換。
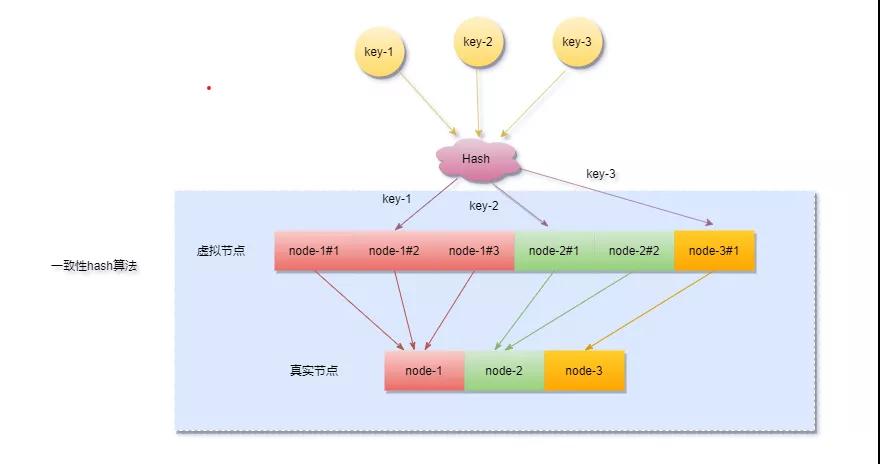
一致性hash的應(yīng)用場(chǎng)景
一致性hash在分布式系統(tǒng)中應(yīng)該是實(shí)現(xiàn)負(fù)載均衡的首選算法,它的實(shí)現(xiàn)比較靈活,既可以在客戶端實(shí)現(xiàn),也可以在中間件上實(shí)現(xiàn),比如日常使用較多的緩存中間件memcached和redis集群都有用到它。
memcached的集群比較特殊,嚴(yán)格來(lái)說(shuō)它只能算是偽集群,因?yàn)樗姆?wù)器之間不能通信,請(qǐng)求的分發(fā)路由完全靠客戶端來(lái)的計(jì)算出緩存對(duì)象應(yīng)該落在哪個(gè)服務(wù)器上,而它的路由算法用的就是一致性hash。
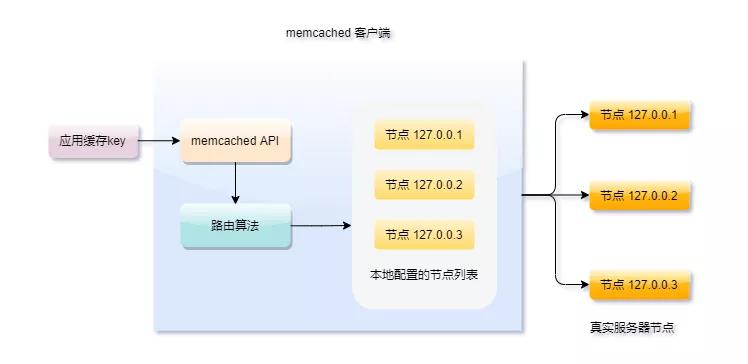
還有redis集群中hash槽的概念,雖然實(shí)現(xiàn)不盡相同,但思想萬(wàn)變不離其宗,看完本篇的一致性hash,你再去理解redis槽位就輕松多了。
其它的應(yīng)用場(chǎng)景還有很多:
- RPC框架Dubbo用來(lái)選擇服務(wù)提供者
- 分布式關(guān)系數(shù)據(jù)庫(kù)分庫(kù)分表:數(shù)據(jù)與節(jié)點(diǎn)的映射關(guān)系
- LVS負(fù)載均衡調(diào)度器
- .....................
總結(jié)
簡(jiǎn)單的闡述了下一致性hash,如果有不對(duì)的地方大家可以留言指正,任何技術(shù)都不會(huì)十全十美,一致性Hash算法也是有一些潛在隱患的,如果Hash環(huán)上的節(jié)點(diǎn)數(shù)量非常龐大或者更新頻繁時(shí),檢索性能會(huì)比較低下,而且整個(gè)分布式緩存需要一個(gè)路由服務(wù)來(lái)做負(fù)載均衡,一旦路由服務(wù)掛了,整個(gè)緩存也就不可用了,還要考慮做高可用。
不過話說(shuō)回來(lái),只要是能解決問題的都是好技術(shù),有點(diǎn)副作用還是可以忍受的。



















