













面試又被問(wèn)到一致性 Hash 算法?這樣回答秒殺面試官!
數(shù)據(jù)分片
先讓我們看一個(gè)例子吧
我們經(jīng)常會(huì)用 Redis 做緩存,把一些數(shù)據(jù)放在上面,以減少數(shù)據(jù)的壓力。
當(dāng)數(shù)據(jù)量少,訪問(wèn)壓力不大的時(shí)候,通常一臺(tái)Redis就能搞定,為了高可用,弄個(gè)主從也就足夠了;
當(dāng)數(shù)據(jù)量變大,并發(fā)量也增加的時(shí)候,把全部的緩存數(shù)據(jù)放在一臺(tái)機(jī)器上就有些吃力了,畢竟一臺(tái)機(jī)器的資源是有限的,通常我們會(huì)搭建集群環(huán)境,讓數(shù)據(jù)盡量平均的放到每一臺(tái) Redis 中,比如我們的集群中有 4 臺(tái)Redis。
那么如何把數(shù)據(jù)盡量平均地放到這 4 臺(tái)Redis中呢?最簡(jiǎn)單的就是取模算法:
hash( key ) % N,N 為 Redis 的數(shù)量,在這里 N = 4 ;
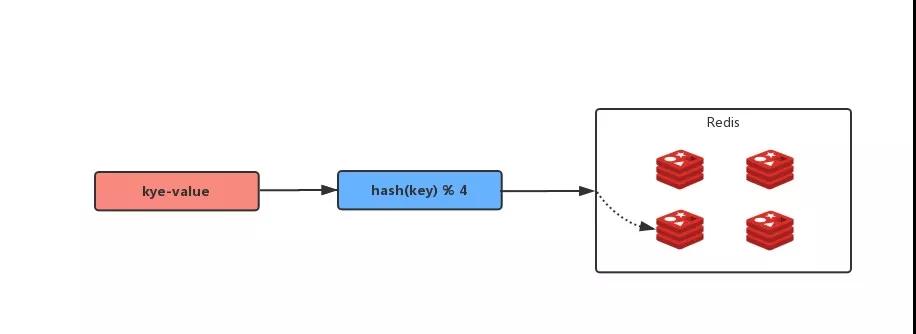
看起來(lái)非常得美好,因?yàn)橐揽窟@樣的方法,我們可以讓數(shù)據(jù)平均存儲(chǔ)到 4 臺(tái) Redis 中,當(dāng)有新的請(qǐng)求過(guò)來(lái)的時(shí)候,我們也可以定位數(shù)據(jù)會(huì)在哪臺(tái) Redis 中,這樣可以精確地查詢到緩存數(shù)據(jù)。
02數(shù)據(jù)分片會(huì)遇到的問(wèn)題
但是 4 臺(tái) Redis 不夠了,需要再增加 4 臺(tái) Redis ;
那么這個(gè)求余算法就會(huì)變成:hash( key ) % 8 ;
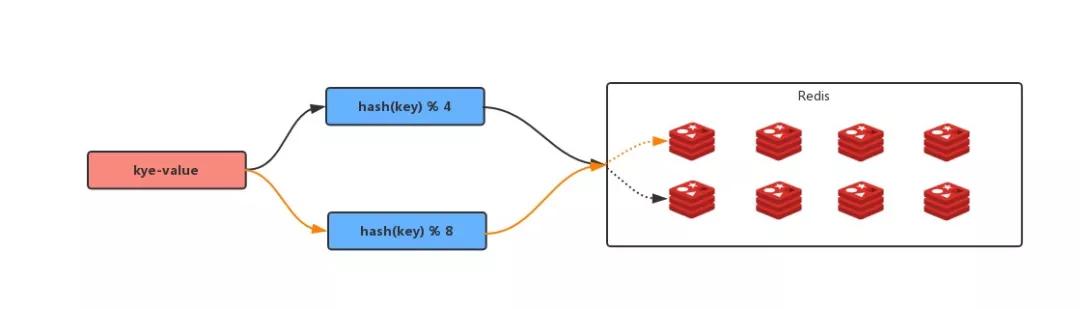
那么可以想象一下,當(dāng)前大部分緩存的位置都會(huì)是錯(cuò)誤的,極端情況下,就會(huì)造成 緩存雪崩。
03一致性 Hash 算法
一致性 Hash 算法可以很好地解決這個(gè)問(wèn)題,它的大概過(guò)程是這樣的:
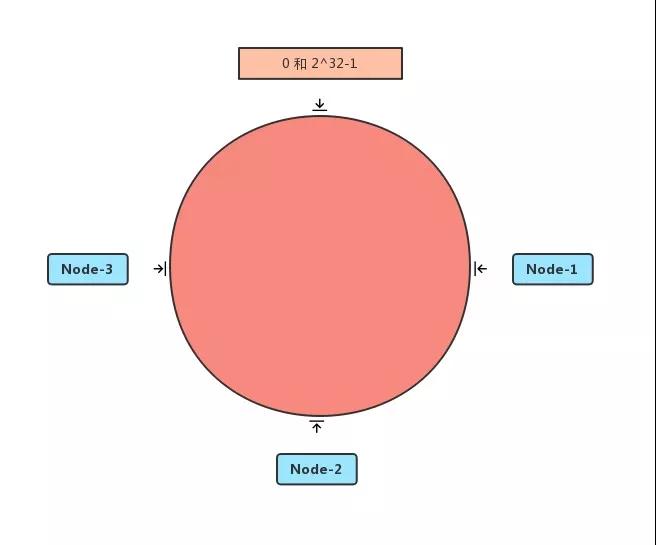
把 0 作為起點(diǎn),2^32-1 作為終點(diǎn),畫一條直線,再把起點(diǎn)和終點(diǎn)重合,直線變成一個(gè)圓,方向是順時(shí)針從小到大。0 的右側(cè)第一個(gè)點(diǎn)是 1 ,然后是 2 ,以此類推。
對(duì)三臺(tái)服務(wù)器的 IP 或其他關(guān)鍵字進(jìn)行 hash 后對(duì) 2^32 取模,這樣勢(shì)必能落在這個(gè)圈上的某個(gè)位置,記為 Node1、Node2、Node3。
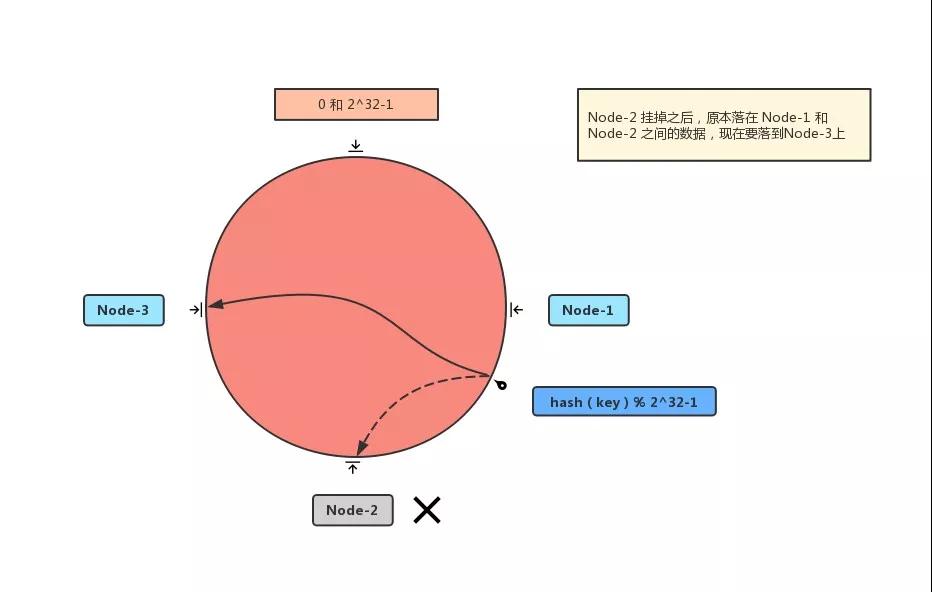
然后對(duì)數(shù)據(jù) key 進(jìn)行相同的操作,勢(shì)必也會(huì)落在圈上的某個(gè)位置;然后順時(shí)針行走,可以找到某一個(gè) Node,這就是這個(gè) key 要儲(chǔ)存的服務(wù)器。
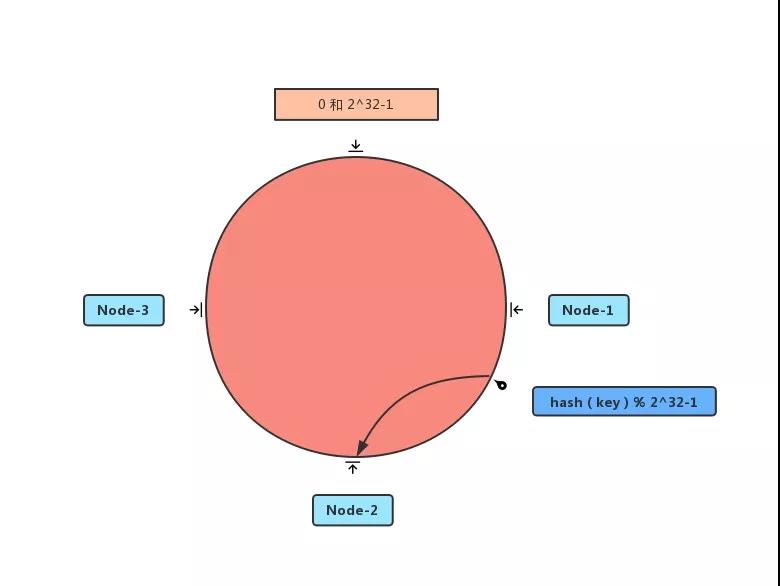
如果增加一臺(tái)服務(wù)器或者刪除一臺(tái)服務(wù)器,只會(huì)影響 部分?jǐn)?shù)據(jù)。
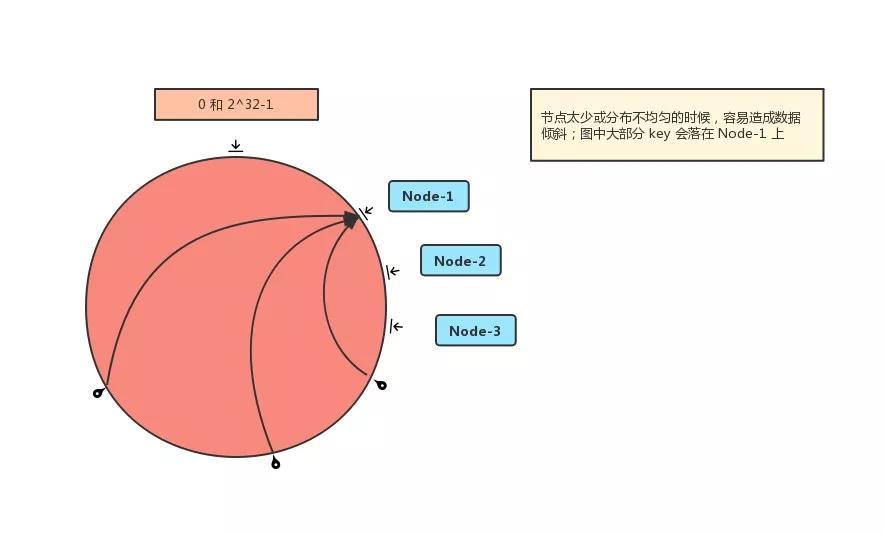
但如果節(jié)點(diǎn)太少或分布不均勻的時(shí)候,容易造成 數(shù)據(jù)傾斜,也就是大部分?jǐn)?shù)據(jù)會(huì)集中在某一臺(tái)服務(wù)器上。
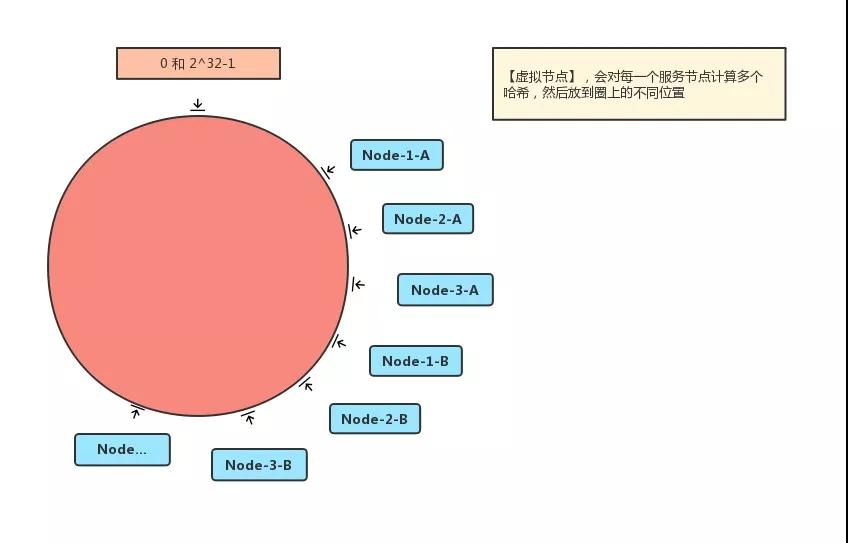
為了解決數(shù)據(jù)傾斜問(wèn)題,一致性 Hash 算法提出了【虛擬節(jié)點(diǎn)】,會(huì)對(duì)每一個(gè)服務(wù)節(jié)點(diǎn)計(jì)算多個(gè)哈希,然后放到圈上的不同位置。
當(dāng)然我們也可以發(fā)現(xiàn),一致性 Hash 算法,也只是解決大部分?jǐn)?shù)據(jù)的問(wèn)題。






















