微服務(wù)難點(diǎn)剖析 | 服務(wù)拆的挺爽,問題是日志該怎么串聯(lián)起來(lái)呢?

本文轉(zhuǎn)載自微信公眾號(hào)「網(wǎng)管叨bi叨」,作者KevinYan11。轉(zhuǎn)載本文請(qǐng)聯(lián)系網(wǎng)管叨bi叨公眾號(hào)。
現(xiàn)在微服務(wù)架構(gòu)盛行,很多以前的單體應(yīng)用服務(wù)都被拆成了多個(gè)分布式的微服務(wù),以解決應(yīng)用系統(tǒng)發(fā)展壯大后的開發(fā)周期長(zhǎng)、難以擴(kuò)展、故障隔離等挑戰(zhàn)。
不過技術(shù)領(lǐng)域有個(gè)諺語(yǔ)叫--沒有銀彈,這句話的意思其實(shí)跟現(xiàn)實(shí)生活中任何事都有利和弊兩面一樣,意思是告訴我們不要寄希望于用一個(gè)解決方案解決所有問題,引入新方案解決舊問題的同時(shí),勢(shì)必會(huì)引入新的問題。典型的比如,原本在單體應(yīng)用里可以靠本地?cái)?shù)據(jù)庫(kù)的ACID 事務(wù)來(lái)保證數(shù)據(jù)一致性。但是微服務(wù)拆分后,就沒那么簡(jiǎn)單了。
同理拆分成為服務(wù)后,一個(gè)業(yè)務(wù)邏輯的完成一般需要多個(gè)服務(wù)的協(xié)作才能完成,每個(gè)服務(wù)都會(huì)有自己的業(yè)務(wù)日志,那怎么把各個(gè)服務(wù)的業(yè)務(wù)日志串聯(lián)起來(lái),也會(huì)變難,今天我們就聊一下微服務(wù)的日志串聯(lián)的方案。
在早前的文章分布式鏈路跟蹤中的traceid和spanid代表什么? 這里我給大家介紹過 TraceId 和 SpanId 的概念。
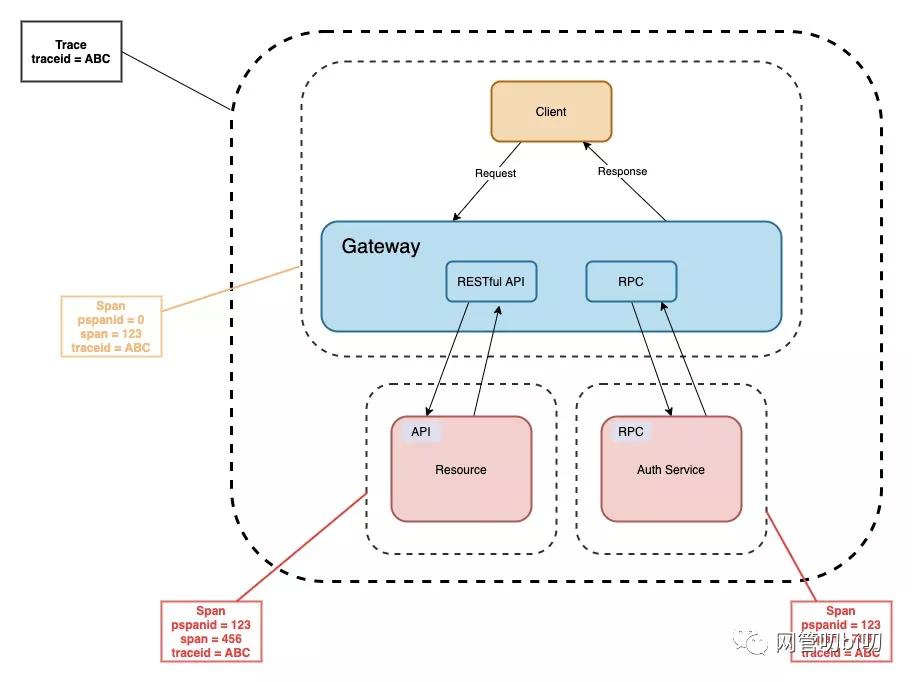
- trace 是請(qǐng)求在分布式系統(tǒng)中的整個(gè)鏈路視圖
- span 則代表整個(gè)鏈路中不同服務(wù)內(nèi)部的視圖,span 組合在一起就是整個(gè) trace 的視圖
在微服務(wù)的日志串聯(lián)里,我們同樣能使用這兩個(gè)概念,通過 trace 串聯(lián)出一個(gè)業(yè)務(wù)邏輯的所有業(yè)務(wù)日志,span 串聯(lián)出在單個(gè)服務(wù)里的業(yè)務(wù)日志。
而單個(gè)微服務(wù)的日志串聯(lián)的時(shí)候還有個(gè)挑戰(zhàn)是怎么把數(shù)據(jù)庫(kù)執(zhí)行過程的一些日志也注入這些 traceid 和 spanid 打到業(yè)務(wù)日志里。下面我們就分別通過
- HTTP 服務(wù)間的日志追蹤參數(shù)傳遞
- HTTP 和 RPC 服務(wù)間的追蹤參數(shù)傳遞
- ORM 的日志中注入追蹤參數(shù)
來(lái)簡(jiǎn)述一下微服務(wù)業(yè)務(wù)日志串聯(lián)的思路。提前聲明本文中給出的解決方案更多是 Go 技術(shù)棧的,其他語(yǔ)言的技術(shù)棧有些方案實(shí)現(xiàn)跟這里列舉的稍有不同,尤其是 Java 一些開源庫(kù)上比較容易實(shí)現(xiàn)的東西在 Go 這里并不簡(jiǎn)單。
其實(shí)如果使用 APM 的話,是有比較統(tǒng)一的解決方案的,比如接入 Skywalking 就可以,不過還是有額外的學(xué)習(xí)成本以及需要引入外部系統(tǒng)組件的。
HTTP 服務(wù)間的日志追蹤參數(shù)傳遞
HTTP 服務(wù)間的追蹤參數(shù)傳遞,主要是靠在全局的路由中間件來(lái)搞,我們可以在請(qǐng)求頭里指定 TraceId 和 SpanId。當(dāng)然如果是請(qǐng)求到達(dá)的第一個(gè)服務(wù),則生成 TraceId 和 SpanId,加到Header 里往下傳。
- type Middleware func(http.HandlerFunc) http.HandlerFunc
- func withTrace() Middleware {
- // 創(chuàng)建中間件
- return func(f http.HandlerFunc) http.HandlerFunc {
- return func(w http.ResponseWriter, r *http.Request) {
- traceID := r.Header.Get("xx-tranceid")
- parentSpanID := r.Header.Get("xx-spanid")
- spanID := genSpanID(r.RemoteAddr)
- if traceID == "" {// traceID為空,證明是初始調(diào)用,讓root span id == trace id
- traceId = spanID
- }
- // 把 追蹤參數(shù)通過 Context 在服務(wù)內(nèi)部處理中傳遞
- ctx := context.WithValue(r.Context(), "trace-id", traceID)
- ctx := context.WithValue(ctx, "pspan-id", parentSpanID)
- ctx := context.WithValue(ctx, "span-id", parentSpanID)
- r.WithContext(ctx)
- // 調(diào)用下一個(gè)中間件或者最終的handler處理程序
- f(w, r)
- }
- }
- }
上面主要通過在中間件程序,獲取 Header 頭里存儲(chǔ)的追蹤參數(shù),把參數(shù)保存到請(qǐng)求的 Context 中在服務(wù)內(nèi)部傳遞。上面的程序有幾點(diǎn)需要說(shuō)明:
- genSpanID 是根據(jù)遠(yuǎn)程客戶端IP 生成唯一 spanId 的方法,生成方法只要保證哈希串唯一就行。
- 如果服務(wù)是請(qǐng)求的開始,在生成spanId 的時(shí)候,我們把它也設(shè)置成 traceId,這樣就能通過 spanId == traceId 判斷出當(dāng)前的 Span 是請(qǐng)求的開端、即 root span。
接下來(lái)往下游服務(wù)發(fā)起請(qǐng)求的時(shí)候,我們需要在把 Context 里存放的追蹤參數(shù),放到 Header 里接著往下個(gè) HTTP 服務(wù)傳。
- func HttpGet(ctx context.Context url string, data string, timeout int64) (code int, content string, err error) {
- req, _ := http.NewRequest("GET", url, strings.NewReader(data))
- defer req.Body.Close()
- req.Header.Add("xx-trace-tid", ctx.Value("trace-id").(string))
- req.Header.Add("xx-trace-tid", ctx.Value("span-id").(string))
- client := &http.Client{Timeout: time.Duration(timeout) * time.Second}
- resp, error := client.Do(req)
- }
HTTP 和 RPC 服務(wù)間的追蹤參數(shù)傳遞
上面咱們說(shuō)的上下游服務(wù)都是 HTTP 服務(wù)的追蹤參數(shù)傳遞,那如果是 HTTP 服務(wù)的下游是 RPC 服務(wù)呢?
其實(shí)跟發(fā)HTTP請(qǐng)求可以配置HTTP客戶端攜帶 Header 和 Context 一樣,RPC客戶端也支持類似功能。以 gRPC 服務(wù)為例,客戶端調(diào)用RPC 方法時(shí),在可以攜帶的元數(shù)據(jù)里設(shè)置這些追蹤參數(shù)。
- traceID := ctx.Value("trace-id").(string)
- traceID := ctx.Value("trace-id").(string)
- md := metadata.Pairs("xx-traceid", traceID, "xx-spanid", spanID)
- // 新建一個(gè)有 metadata 的 context
- ctx := metadata.NewOutgoingContext(context.Background(), md)
- // 單向的 Unary RPC
- response, err := client.SomeRPCMethod(ctx, someRequest)
RPC 的服務(wù)端的處理方法里,可以再通過 metadata 把元數(shù)據(jù)里存儲(chǔ)的追蹤參數(shù)取出來(lái)。
- func (s server) SomeRPCMethod(ctx context.Context, req *xx.someRequest) (reply *xx.SomeReply, err error) {
- remote, _ := peer.FromContext(ctx)
- remoteAddr := remote.Addr.String()
- // 生成本次請(qǐng)求在當(dāng)前服務(wù)的 spanId
- spanID := utils.GenerateSpanID(remoteAddr)
- traceID, pSpanID := "", ""
- md, _ := metadata.FromIncomingContext(ctx)
- if arr := md["xx-tranceid"]; len(arr) > 0 {
- traceID = arr[0]
- }
- if arr := md["xx-spanid"]; len(arr) > 0 {
- pSpanID = arr[0]
- }
- return
- }
有一個(gè)概念我們需要注意一下,代碼里是把上游傳過來(lái)的 spanId 作為本服務(wù)的 parentSpanId 的,本服務(wù)處理請(qǐng)求時(shí)候的 spanId 是需要重新生成的,生成規(guī)則在之前我們介紹過。
除了 HTTP 網(wǎng)關(guān)調(diào)用 RPC 服務(wù)外,處理請(qǐng)求時(shí)也經(jīng)常出現(xiàn) RPC 服務(wù)間的調(diào)用,那這種情況該怎么弄呢?
RPC 服務(wù)間的追蹤參數(shù)傳遞
其實(shí)跟 HTTP 服務(wù)調(diào)用 RPC 服務(wù)情況類似,如果上游也是 RPC 服務(wù),那么則應(yīng)該在接收到的上層元數(shù)據(jù)的基礎(chǔ)上再附加的元數(shù)據(jù)。
- md := metadata.Pairs("xx-traceid", traceID, "xx-spanid", spanID)
- mdOld, _ := metadata.FromIncomingContext(ctx)
- md = metadata.Join(mdOld, md)
- ctx = metadata.NewOutgoingContext(ctx, md)
當(dāng)然如果我們每個(gè)客戶端調(diào)用和RPC 服務(wù)方法里都這么搞一遍得類似,gRPC 里也有類似全局路由中間件的概念,叫攔截器,我們可以把追蹤參數(shù)傳遞這部分邏輯封裝在客戶端和服務(wù)端的攔截器里。
gRPC 攔截器的詳細(xì)介紹請(qǐng)看我之前的文章 -- gRPC生態(tài)里的中間件
客戶端攔截器
- func UnaryClientInterceptor(ctx context.Context, ... , opts ...grpc.CallOption) error {
- md := metadata.Pairs("xx-traceid", traceID, "xx-spanid", spanID)
- mdOld, _ := metadata.FromIncomingContext(ctx)
- md = metadata.Join(mdOld, md)
- ctx = metadata.NewOutgoingContext(ctx, md)
- err := invoker(ctx, method, req, reply, cc, opts...)
- return err
- }
- // 連接服務(wù)器
- conn, err := grpc.Dial(*address, grpc.WithInsecure(),grpc.WithUnaryInterceptor(UnaryClientInterceptor))
服務(wù)端攔截器
- func UnaryServerInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
- remote, _ := peer.FromContext(ctx)
- remoteAddr := remote.Addr.String()
- spanID := utils.GenerateSpanID(remoteAddr)
- // set tracing span id
- traceID, pSpanID := "", ""
- md, _ := metadata.FromIncomingContext(ctx)
- if arr := md["xx-traceid"]; len(arr) > 0 {
- traceID = arr[0]
- }
- if arr := md["xx-spanid"]; len(arr) > 0 {
- pSpanID = arr[0]
- }
- // 把 這些ID再搞到 ctx 里,其他兩個(gè)就省略了
- ctx := Context.WithValue(ctx, "traceId", traceId)
- resp, err = handler(ctx, req)
- return
- }
ORM 的日志中注入追蹤參數(shù)
其實(shí),如果你用的是 GORM 注入這個(gè)參數(shù)是最難的,如果你是 Java 程序員的話,可能會(huì)對(duì)比如阿里巴巴的 Druid 數(shù)據(jù)庫(kù)連接池加入類似 traceId 這種參數(shù)習(xí)以為常,但是 Go 的 GORM 庫(kù)確實(shí)做不到,也有可能新版本可以,我用的還是老版本,其他 Go 的 ORM 庫(kù)沒有接觸過,知道的同學(xué)可以留言給我們普及一下。
GORM做不到在日志里加入追蹤參數(shù)的原因就是這個(gè)GORM 的 logger 沒有實(shí)現(xiàn)SetContext方法,所以除非修改源碼中調(diào)用db.slog的地方,否則無(wú)能為力。
不過話也不能說(shuō)死,之前介紹過一種使用函數(shù)調(diào)用棧實(shí)現(xiàn) Goroutine Local Storage 的庫(kù) jtolds/gls ,我們可以通過它在外面封裝一層來(lái)實(shí)現(xiàn),并且還需要重新實(shí)現(xiàn) GORM Logger 的打印日志的 Print 方法。
下面大家感受一下,GLS 庫(kù)的使用,確實(shí)有點(diǎn)點(diǎn)怪,不過能過。
- func SetGls(traceID, pSpanID, spanID string, cb func()) {
- mgr.SetValues(gls.Values{traceIDKey: traceID, pSpanIDKey: pSpanID, spanIDKey: spanID}, cb)
- }
- gls.SetGls(traceID, pSpanID, spanID, func() {
- data, err = findXXX(primaryKey)
- })
重寫 Logger 的我就簡(jiǎn)單貼貼,核心思路還是在記錄SQL到日志的時(shí)候,從調(diào)用棧里把 traceId 和 spanId 取出來(lái)放一并加入到日志記錄里。
- // 對(duì)Logger 注冊(cè) Print方法
- func (l logger) Print(values ...interface{}) {
- if len(values) > 1 {
- // ...
- l.sqlLog(sql, args, duration, path.Base(source))
- } else {
- err := values[2]
- log.Error("source", source, "err", err)
- }
- }
- }
- func (l logger) sqlLog(sql string, args []interface{}, dur time.Duration, source string) {
- argsArr := make([]string, len(args))
- for k, v := range args {
- argsArr[k] = fmt.Sprintf("%v", v)
- }
- argsStr := strings.Join(argsArr, ",")
- spanId := gls.GetSpanId()
- traceId := gls.GetTraceId()
- //對(duì)于超時(shí)的,統(tǒng)一打warn日志
- if dur > (time.Millisecond * 500) {
- log.Warn("xx-traceid", traceId, "xx-spanid", spanId, "sql", sql, "args_detal", argsStr, "source", source)
- } else {
- log.Debug("xx-traceid", traceId, "xx-spanid", spanId, "sql", sql, "args_detal", argsStr, "source", source)
- }
- }
通過調(diào)用棧獲取 spanId 和 traceId 的是類似這樣的方法,由 GLS 庫(kù)提供的方法封裝實(shí)現(xiàn)。
- // Get spanID 用于Goroutine的鏈路追蹤
- func GetSpanID() (spanID string) {
- span, ok := mgr.GetValue(spanIDKey)
- if ok {
- spanID = span.(string)
- }
- return
- }
日志打印的話,也是對(duì)超過 500 毫秒的SQL執(zhí)行進(jìn)行 Warn 級(jí)別日志的打印,方便線上環(huán)境分析問題,而其他的SQL執(zhí)行記錄,因?yàn)槭褂昧?Debug 日志級(jí)別只會(huì)在測(cè)試環(huán)境上顯示。
總結(jié)
用分布式鏈路追蹤參數(shù)串聯(lián)起整個(gè)服務(wù)請(qǐng)求的業(yè)務(wù)日志,在線上的分布式環(huán)境中是非常有必要的,其實(shí)上面只是簡(jiǎn)單闡述了一些思路,只有把日志搞的足夠好,上下文信息足夠多才會(huì)能高效地定位出線上問題。感覺這部分細(xì)節(jié)太多,想用一篇文章闡述明白非常困難。
而且還有一點(diǎn)就是日志錯(cuò)誤級(jí)別的選擇也非常有講究,如果本該用Debug的地方,用了 Info 級(jí)別,那線上日志就會(huì)出現(xiàn)非常多的干擾項(xiàng)。
細(xì)節(jié)的地方怎么實(shí)現(xiàn),就屬于實(shí)踐的時(shí)候才能把控的了。希望這篇文章能給你個(gè)實(shí)現(xiàn)分布式日志追蹤的主旨思路。