拆雖不易,合則更難!持續集成是微服務化的“基石”
在很多微服務化的文章中,很少會把持續集成放在***篇,因為大多數的文章都會講如何拆的問題,例如拆的粒度,拆的時機,拆的方式。
持續集成對于微服務的意義:拆之前要先解決合的問題
為什么需要拆呢?因為這是人類處理問題的本質方式:將一個大的復雜問題,變成很多個小問題解決。
所以當一個系統復雜到一定程度,當維護一個系統的人數多到一定程度,解決問題的難度和溝通成本大大提高,因而需要拆成很多個工程,拆成很多個團隊,分而治之。
然而當每個子團隊將子問題解決了,整個系統的問題就解決了么?你可以想象你將一輛整車拆成零件,然后再組裝起來的過程,你就可以想象拆雖然不容易,合則更難,需要各種標準,各種流水線,才能將零件組裝成為車。
我們先來回顧一下拆的過程。
最初的應用大多數是一個單體應用。

一個 Java 后端,后面跟一個數據庫,基本上就搞定了。
隨著系統復雜度的增加,首先 Java 程序需要做的是縱向的拆分。
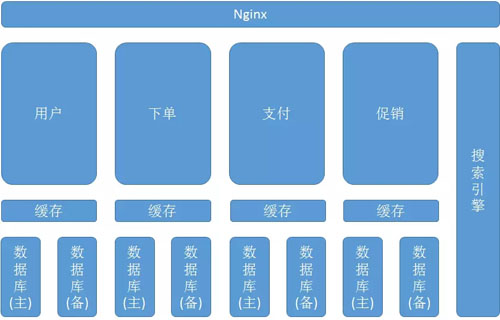
首先最外面是一個負載均衡,接著是接入的 Nginx,做不同服務的路由。
不同的服務拆成獨立的進程,獨立部署,每個服務使用自己的數據庫和緩存,解決數據庫和緩存的單點瓶頸。
數據庫使用一主多從的模式,進行讀寫分離,主要針對讀多寫少的場景。
為了承載更多的請求,設置緩存層,將數據緩存到 Memcached 或者 Redis 中,增加***率。
當然還有些跨服務的查詢,或者非結構化數據的查詢,引入搜索引擎,比關系型數據庫的查詢速度快很多。
在高并發情況下,僅僅縱向拆分還不夠,因而需要做真正的服務化。
一個服務化的架構如下圖所示:
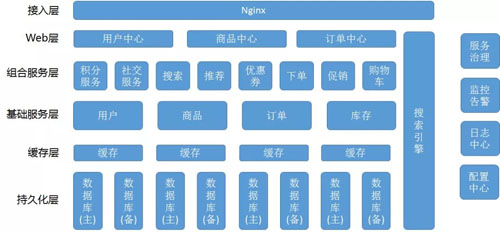
首先是接入層,這一層主要實現 API 網關和動態資源和靜態資源的分離及緩存,并且可以在這一層做整個系統的限流。
接下來是 Web 層,也就是 controller,提供最外層的 API,是對外提供服務的一層。
下面是組合服務層,有時候被稱為編排層,Compose 層,是實現復雜邏輯的一層。
下面是基礎服務層,是提供原子性的基本的邏輯的一層,它下面是緩存,數據庫。
服務之間需要治理,需要相互發現,所以一般會有 Dubbo 或者 Spring Cloud 一樣的框架。
對所有的服務,都應該有監控告警,及時發現異常,并自動修復或者告警運維手動修復。
對于所有的服務的日志,應該有相同的格式,收集到一起,稱為日志中心,方便發現錯誤的時候,在統一的一個地方可以 Debug。
對于所有的服務的配置,有統一的管理的地方,稱為配置中心,可以通過修改配置中心,下發配置,對于整個集群進行配置的修改,例如打開熔斷或者降級開關等。
通過簡單的描述,大家可以發現,從一個簡單的單體應用,變成如此復雜的微服務架構,除了關心怎么拆的問題,還必須關注:
- 如何控制拆的風險
- 如何保證代碼質量
- 如何保證功能不變,不引入新的 Bug
答案當然就是集成,從一開始就集成,并且不斷的集成,反復的將拆分的模塊重新組合,看看是否能夠順利組合起來,并且保證功能的不變。
要是不沒事兒就組合一下,天知道幾個月以后還能不能合的起來。
別忘了程序是人寫的,你和你媳婦長時間不溝通都談不上默契,別說兩個程序員了。
持續集成就是不斷的嘗試在一起
集成就是在一起,如下圖:
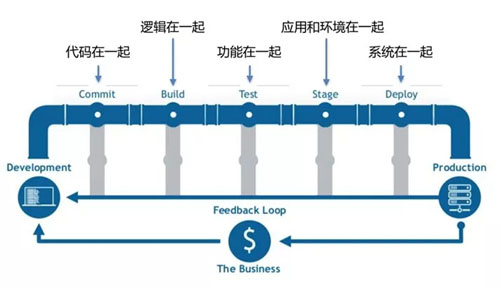
為什么需要一個統一的代碼倉庫 Git 來做代碼管理呢?是為了代碼集成在一起。
為什么需要進行構建 build 呢?就是代碼邏輯需要集成在一起,編譯不出錯。
為什么要單元測試呢?一個模塊的功能集成在一起能夠正確工作。
為什么需要聯調測試 Staging 環境呢?需要將不同模塊之間集成在一起,在一個類生產的環境中進行測試。
最終才是部署到生產環境中,將所有人分開做的工作才算真正的合在了一起。
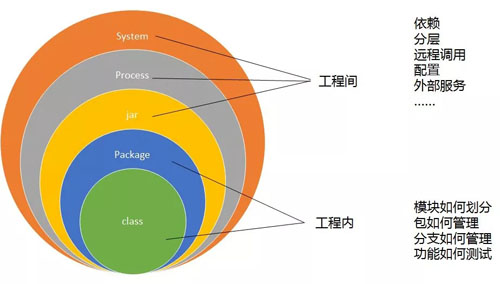
持續集成就是制定一系列流程,或者一個系列規則,將需要在一起的各個層次規范起來,方便大家在一起,強迫大家在一起。
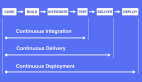
持續集成、持續交付、持續部署、敏捷開發、DevOps 都有啥關系?
這些概念都容易混淆,他們之間是什么關系呢?如下圖:
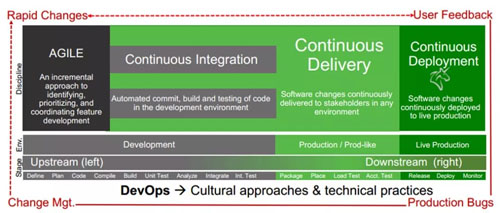
敏捷開發 Agile 是一種開發流程,是一種快速迭代的開發流程,每個開發流程非常短,長到一個月,短到兩個星期,就會是一個周期,在這個周期中,每天都要開會同步,每天都要集成。
正是因為周期短,才需要持續的做這件事情,如果一個開發周期長達幾個月,則不需要持續的集成。
***留幾個星期的集成時間一起做也是可以的,但是這樣就不能達到互聯網公司的快速迭代,也是我們常常看到傳統公司的做法。
持續集成往往指對代碼的提交,構建,測試的過程,也就是上述的在一起的過程。
持續交付是指將集成好的交付物,例如 war、jar 或者容器鏡像,部署在聯調環境,或者預發環境的過程。
持續部署是指將交付物持續部署在生產環境的過程。
我們常說 CI/CD,CD 有時候指的是 Delivery 交付,有的是指 Deployment 部署,對于非生產環境,自動部署是沒有問題的,對于生產環境,往往還是需要有專人來進行更為嚴肅的部署過程,不會完全的自動化。
接下來就是 DevOps,DevOps 不只是 CI/CD,除了技術和流程,還包含文化。
例如容器化帶來的一個巨大的轉變是,原來只有運維關心環境的部署,無論是測試環境,還是生產環境,都是運維搞定的,而容器化之后,需要開發自己寫 Dockerfile,自己關心環境的部署。
因為微服務之后,模塊太多了,讓少數的運維能夠很好的管理所有的服務,壓力大,易出錯,然而開發往往分成很多的團隊,每個模塊自己關心自己的部署,則不易出錯。
這就需要運維一部分的工作讓研發來做,需要研發和運維的打通,如果公司沒有這個文化,研發的老大說我們不寫 Dockerfile,則 DevOps 是搞不定的。
從一個持續集成的日常,看上述的幾個概念如何實踐
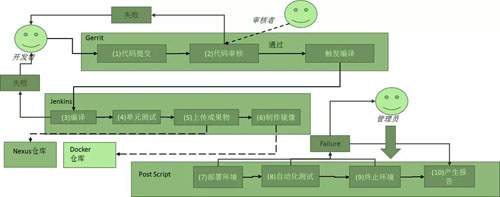
如上圖,這是一個持續集成的流程,但是運行起來更加的復雜。
首先,項目開發的流程使用的是 Agile,用常見的 scrum 為例子。
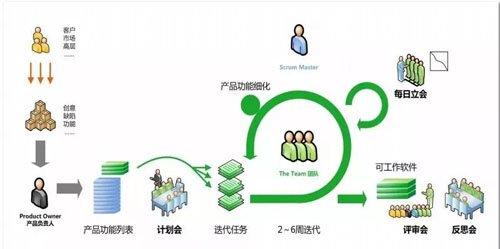
每天早上***件事情,就是開站會 standup meeting,為什么要站著呢?
因為時間不能太長,微服務的一個模塊,大概需要 5-9 人的團隊規模,如果團隊規模太大了,說明服務應該進行拆分了,這個團隊規模,是能夠保證比較短的時間之內過完昨天的狀態的。
一定要大家一起開,而不要線下去更新 Jira,雖然看起來一樣,但是執行起來完全不一樣。
只有大家一起開,一起看燃盡圖,一起說我昨天做了什么,今天打算做什么,有什么阻礙,才能夠讓大家都了解情況,不要期望大家會去看別人的 Jira,經驗告訴你,不會的。
而且這個站會對于開發是比較大的壓力,例如你的一個功能 block 了依賴方的開發,在會議上會暴露出來,大家都知道這件事情了,一天 block,兩天 block,第三天你都不好意思去說了,這會強迫你將大任務細化。
比如原來寫 1 周干一件什么事情,寫成小時級別,這樣每天你都有的說,昨天完成了一個 task,而不是周會只在那里說干同樣一件事情。
而且一旦有了 block,team lead 會知道這件事情,會幫你趕緊解決這個事情,推進整個項目的進展。
讓一個技術人員在團隊面前承認這件事情我嘗試了幾天,的確搞不定了,也是一種壓力。
站會中的內容其實在前一天晚上就要開始準備了。
持續集成要求每天都提交代碼,這樣才能降低代碼集成的風險,不能埋頭寫一周一起提交,這樣往往集成不成功。
怎么樣才能鼓勵團隊成員每天都提交代碼呢?一個就是第二天的站會,你這個功能代碼提交了,單元測試通過了,第二天才能說做完了,否則不算,這就逼得你,將大任務拆成小任務,每天都多次提交。
而且 Git 的提交方式,是后提交者有責任去 merge,保證代碼的編譯通過和測試通過,你會發現,如果你不及時提交,等你改了一大片代碼,別人都提交完了,這一大片的沖突都是你來 merge,測試用例不通過的你來 fix。
所以逼的你有一個小的功能的改動,就盡早提交,pull 一下發現沒有人提交,就趕緊提交。
提交不是馬上進入主庫,而是需要代碼審核,這是把控代碼質量的重要環節。
代碼質量的控制往往每個公司都有文檔,甚至你可以從網上下載一篇很長很長的 Java 代碼規范。
但是我們常常看到的例子是,規范是有,但是虱子多了不咬人,規范太多的,誰也記不住,等于沒有規范。
所以建議將復雜的規范通過項目組內部的討論,簡化為簡單的 10 幾條軍規,深入人心,大家都容易記住,并且容易執行。
代碼審核往往需要注意下面的幾方面:
- 代碼結構:整個項目組應該規定統一的代碼組織結構,使得每個開發拿到另一個人的代碼,都能看到熟悉的面孔。
這也是 Scrum 中提倡的每個開發之間是可替代的,當一個模塊有了阻礙,其他人是可以幫上忙的。至于核心的邏輯,估計審核人員也來不及細看,這不要緊,核心邏輯是否通過,不能靠眼睛,要靠測試。
- 有沒有注釋,尤其是對外的接口,應該有完善的注釋,方便自動生成接口文檔。
- 異常的處理,是否拋出太過寬泛的異常,是否吞掉異常,是否吞掉異常的日志等。
- 對于 pom 是否有修改,引入了新的 jar。
- 對于配置文件是否有修改,對外訪問是否設置超時。
- 對于數據庫是否有修改,是否經過 DBA 審核。
- 接口實現是否冪等,因為 Dubbo 和 Spring Cloud 都會重試接口。接口是否會升級,是否帶版本號。
- 是否有單元測試。
當然還有一些不容易一眼看出來的,可以通過一段時間通過統一的代碼 review,來修改這些問題:
- 某個類代碼長度過長
- 設計是否合理,高內聚低耦合
- 數據庫設計是否合理
- 數據庫事務是否使用合理
- 代碼是否有明顯的阻塞
代碼審核完畢提交上去之后,一個是要通過靜態代碼審查,可以發現一些可能帶來代碼風險的問題,例如異常過于寬泛等。
再就是要通過單元測試。我們應該要求每個類都要有單元測試,并且單元測試覆蓋率要達到一定的指標。單元測試要有帶 Mock 的模塊內的集成測試。
在編譯過程中會觸發單元測試,單元測試不通過,以及代碼覆蓋率,都會統計后發郵件,抄送所有的人,這對于研發來講又是一個壓力。
當有一天你的提交 break 掉了測試,或者代碼覆蓋率很低,則就像通報批評一樣,你需要趕緊去修改。
單元測試完畢之后,就會上傳成果物,或者是 war 或者是 jar,一般會用 nexus。
因為有版本號,有 md5,可以保證安裝在環境中的就是某個版本的某個包,我們還遇到過有使用 FTP 的,這樣很難保證版本號的維護,升級和回滾也比較難弄。
另一個是沒有 md5,很可能包不完整都有可能的,而且一旦發生,很難發現。
如果使用了容器,則還需要編譯 Dockerfile,使用 Docker 鏡像作為交付,能夠實現更好的環境一致性,保證原子的升級和回滾。
每天下班前,當天的代碼需要提交到庫中去,晚上會做一次統一的環境部署和集成測試。
每天晚上凌晨,會有自動化的腳本將 Docker 鏡像通過編排部署一個完整的環境,然后跑集成測試用例,集成測試用例應該是基于 API 的,很多的公司是基于 UI 的。
這樣由于 UI 變化太快,還有 UI 不能覆蓋所有的場景,所以還是建議 UI 和 API 分離。
通過 API 進行集成測試,有了每天的測試,才能保證每天晚上的版本都是可以交付的版本,也保證我們微服務拆分的時候,盡管改了很多,不會因為新的修改,破壞掉原來能夠通過的測試用例,保證不會有了新的,壞了舊的。
這個集成測試或者叫回歸測試每天晚上都做,都是在一個全新的環境中,這就是持續部署和持續交付。
如果某一天測試不通過,則會發出郵件來,是因為當天誰的哪個提交,導致測試不通過,抄送所有人,這是另一個壓力。
所以第二天的站會上,昨天你完成了哪些功能,是否提交了,是否完成了單元測試,是否通過了集成測試,就都知道了,你需要給大家一個解釋,然后進入到新一天的開發。
到了兩周,一個周期完畢,可以上線到生產環境了,可以通知有權限的運維進行操作,但是也是通過自動化的腳本進行部署的。
這就是整個過程,層層保證質量,從中可以看到,敏捷開發,持續集成,持續交付,持續部署,DevOps 是互相聯系的,少了哪個,流程都玩不轉。
有關代碼結構
代碼結構往往包括:
- API 接口包
- 訪問外部服務包
- 數據庫 DTO
- 訪問數據庫包
- 服務與商務邏輯
- 外部服務
如果使用 Dubbo RPC,則 API 接口往往在一個單獨的 jar 里面,被服務端和客戶端共同依賴。
但是使用了 Spring Cloud 的 restful 方式就不用了,只要在各自的代碼里面定義就可以了,會變成 json 的方式傳遞。
這樣的好處是當 jar 有多個版本依賴,需要升級的時候,關系非常復雜,難以維護,而 json 的方式比較好的解決了這個問題。
這個模塊提供了哪些接口,只要到 API 接口這個 package 下面找就可以了。因為無論是 Dubbo 還是 Spring Cloud,接口的調用都會重試,因而接口需要實現冪等。
訪問外部服務的包,將所有對外的訪問獨立出來,有三個好處:
- 可以抽象出來,在服務拆分的時候,可能會用到,例如原來支付的邏輯在下單的模塊中,要將支付獨立出來,則會有一個抽象層,涉及到老的支付方式,還是調用本模塊中的邏輯,涉及到新接入的支付方式使用遠程調用,有了這一層方便的多。
- 可以實現熔斷,當被調用的服務不正常的時候,在這里可以返回托底數據。
- 可以實現 Mock,這樣對于單元測試來講非常好,不用依賴于其他服務,就可以自己進行測試。
DTO 和訪問數據庫的包,看到了這些數據結構,會幫助程序員快速掌握代碼邏輯。
不知道大家有沒有這個體驗,你去看一個開源軟件的代碼,首先要看的是它的數據結構,數據結構和關系看懂了,代碼邏輯就比較容易懂了,如果數據結構沒看懂,光看邏輯,就容易云里霧里。
還有就是核心的代碼邏輯和對接口的實現。在這里面是軟件代碼設計的內功所在,但是卻不是流程能夠控制的。
有關接口設計規范
上面也說過了,Dubbo 和 Spring Cloud 會對接口進行重試,因而接口需要保持冪等。
也即多次調用,應該產生一致的結果,例如轉賬 1 元,因為調用失敗或者超時重試的時候,最終結果還應該是轉賬 1 元,而非調用兩次變成轉賬 2 元。
冪等判斷盡量提前,可以使用 ID 作為判斷條件。
接口的實現應該盡量避免阻塞,可以使用異步方式提升性能。
接口應該包括能夠區分不同情況的異常,而非拋出寬泛的 Exception,不能吞掉異常。
接口的實現要有足夠的容錯性,以及對不同版本的兼容性。當要引入新接口的時候,使用先添加,后刪除的方式。
接口應該有良好的注釋。
有關代碼設計
對于代碼的設計,這里常說的就是 SOLID 原則:
- S 是單一責任原則,如果你的代碼中有一個類行數太長,可能你需要重新審視一下,是不是這個類承擔了過多的責任。
- O 是開放關閉原則,比較拗口,對擴展開放,對修改關閉。思想是對于代碼的直接修改是非常危險的事情,因為你不知道這段代碼原來被誰用了,而且到用的時候,面臨的情況都是怎樣的。
因而不要貿然修改一段代碼,而是選擇用接口進行調用,用實現進行擴展的方式進行。
當你要實現一段新的功能的時候,不要改原來的代碼,也不要 if-else,而是應該擴展一種實現,讓原來的調用的代碼邏輯還是原來的,在新的情況下使用新實現的代碼邏輯。
- L 是里氏替換原則,如果基于接口進行編程,則子類一定要能夠擴展父類的功能,如果不能,說明不應該繼承于這個接口。
例如你在實現的時候,發現接口中有一個方法在你這里實在對應不到實現,不是接口設計的問題,就是你不應該繼承這個接口,絕不能出現 not implemented 類似之類的實現方法。
- I 是接口隔離原則,接口不應該設計的大而全,一個接口暴露出所有的功能,從而使得客戶端依賴了自己不需要的接口或者接口的方法。
而是應該將接口進行細分和提取,而不應該將太過靈活的參數和變量混雜在一個接口中。
- D 是依賴倒置原則,A 模塊依賴于 B 模塊,B 模塊有了修改,反而要改 A,就是依賴的過于緊密的問題。
這就是我們常說的,你變了,我沒變,為啥我要改。如果基于抽象的接口編程,將修改隱藏在后面,則能夠實現依賴的解耦。
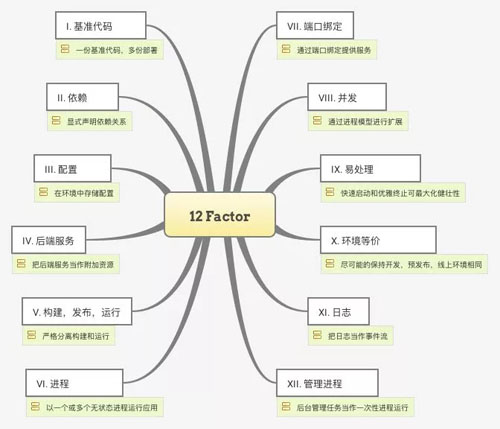
以上是模塊內部常見的設計原則,對于模塊之間,則是對于云原生應用常說的十二原則。
有關配置文件
在代碼倉庫中,還需要管理的是配置文件,往往在 src/main/resource 下面。
配置的管理原來多使用 profile 進行管理,對于 dev、test、production 使用不同的配置文件。
當配置非常多的時候,比較的痛苦,而且配置不斷的修改,每次上線各種配置需要仔細的核對,眼睛都花了,才敢上線。
我們可以將配置分為下面的三類:
- 內部配置項(啟動后不變,改變需要重啟)
- 集中配置項(配置中心,可動態下發)
- 外部配置項(外部依賴,和環境相關)
在梳理配置的時候,可以按著三類歸類,分門別類管理。
在使用了容器之后,很多的內部配置項可固化在配置文件中,放在容器鏡像中,需要啟動的時候修改的,則通過環境變量,在啟動容器的時候,在編排文件中進行修改。
依賴的內部服務的地址,在容器平臺 Kubernetes 里面,可以通過配置服務名進行服務發現,僅僅在配置文件中配置名稱就可以了,不用配置真實的地址。
Kubernetes 可以根據不同的環境,不同的 namespace 自動關聯好,大大簡化了配置。當然也可以用服務中心 Dubbo 和 Spring Cloud 做內部服務的相互發現。
依賴的外部服務的地址,例如 MySQL、Redis 等,往往不同的環境,也可以通過配置 Kubernetes 外部服務名的方式進行,而不用一一核對,擔心測試環境連上了生產環境的 IP 地址。
還有一些集中配置項,需要動態修改的,例如限流,降級的開關等,需要通過統一的配置中心進行管理。
有關數據庫版本
代碼可以很好的版本化,應用也可以用鏡像進行原子化的升級和回滾。
唯一比較難做到的就是數據庫如何版本化管理。有一個工具 Flyway 可以比較好的做這件事情。
在代碼中,Flyway 需要有以下的結構:
- 在 src/db/migration 中有 SQL 文件,命名規則,如:V1__2017_4_13.sql ,V 開頭+版本號+雙下劃線+描述,后綴為 sql。
- 增加 Flyway 的 Java 類,實現 migration 方法。
在數據庫中,Flyway 會自動增加 SCHEME_VERSION 表。
當服務啟動的時候,Java 類的 migration 方法會被調用,它會按照指定路徑中 sql 語句的版本號進行排序并且按照這個排序去執行,當每一個 SQL 文件被執行后,元數據的表就會按照格式進行更新。
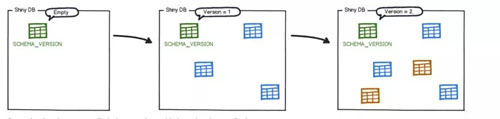
當服務重啟的時候,Flyway 再次掃描 SQL 的時候,它就會檢查元數據表中遷移版本,如果要執行的遷移腳本的版本小于或者等于當前版本,Flyway 將會忽略,不再重復執行。
但是 Flyway 從來不解決數據庫升級和回滾的代碼兼容性問題。
太多的人問這個問題了,代碼可以灰度發布,數據庫咋灰度?代碼升級了,發現不對可以回滾,數據庫咋回滾。
如果可以停服的話,自然是使用數據庫快照備份的方式進行回滾了。
如果不可以停服,沒辦法,只有在代碼層面做兼容性。每次涉及數據庫升級的都是大事情,代碼當然應該有個開關,保證隨時可以切回原來的邏輯。