NLP大火的prompt能用到其他領域嗎?清華孫茂松組的CPT了解一下
從 GPT-3 開始,一種新的范式開始引起大家的關注:prompt。這段時間,我們可以看到大量有關 prompt 的論文出現,但多數還是以 NLP 為主。那么,除了 NLP,prompt 還能用到其他領域嗎?對此,清華大學計算機系副教授劉知遠給出的答案是:當然可以。

圖源:https://www.zhihu.com/question/487096135/answer/2143082483?utm

論文鏈接:https://arxiv.org/pdf/2109.11797.pdf
在細粒度圖像區域,定位自然語言對于各種視覺語言任務至關重要,如機器人導航、視覺問答、視覺對話、視覺常識推理等。最近,預訓練視覺語言模型(VL-PTM)在視覺定位任務上表現出了巨大的潛力。通常來講,一般的跨模態表示首先以自監督的方式在大規模 image-caption 數據上進行預訓練,然后進行微調以適應下游任務。VL-PTM 這種先預訓練再微調的范式使得很多跨模態任務的 SOTA 被不斷刷新。
但盡管如此,清華大學、新加坡國立大學的研究者還是注意到,VL-PTM 的預訓練與微調的 objective form 之間存在顯著差異。如下圖 1 所示,在預訓練期間,多數 VL-PTM 都是基于掩碼語言建模目標進行優化,試圖從跨模態上下文恢復 masked token。然而,在微調期間,下游任務通常通過將 unmasked token 表示歸為語義標簽來執行,這里通常會引入針對特定任務的參數。這種差異降低了 VL-PTM 對下游任務的適應能力。因此,激發 VL-PTM 在下游任務中的視覺定位能力需要大量標記數據。
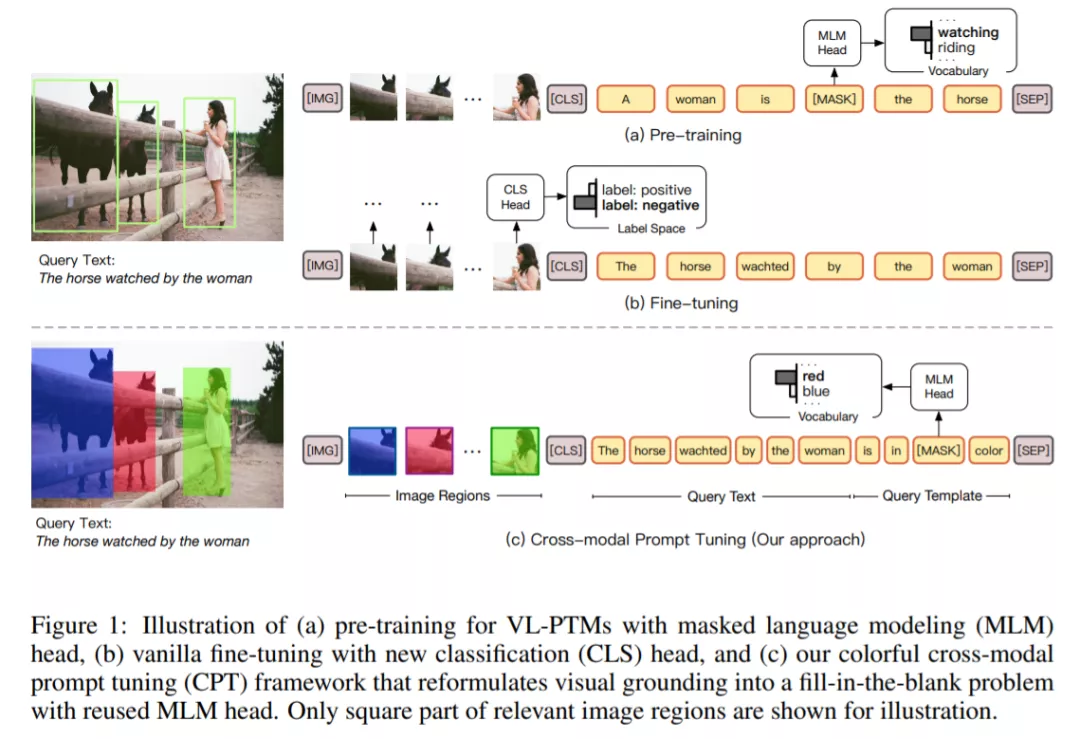
在這篇論文中,受到自然語言處理領域的預訓練語言模型進展啟發,研究者提出了一種調整 VL-PTM 的新范式——CPT( Cross-modal Prompt Tuning 或 Colorful Prompt Tuning)。其中的核心要點是:通過在圖像和文字中添加基于色彩的共指標記(co-referential marker),視覺定位可以被重新表述成一個填空題,從而盡可能縮小預訓練和微調之間的差異。
如圖 1 所示,為了在圖像數據中定位自然語言表達,CPT 由兩部分構成:一是用色塊對圖像區域進行唯一標記的視覺 sub-prompt;二是將查詢文本放入基于色彩的查詢模板的一個文本 sub-prompt。針對目標圖像區域的顯式定位可以通過從查詢模板中的 masked token 中恢復對應顏色文本來實現。
通過縮小預訓練和微調之間的差距,本文提出的 prompt tuning 方法使得 VL-PTM 具備了強大的 few-shot 甚至 zero-shot 視覺定位能力。實驗結果表明,prompted VL-PTMs 顯著超越了它們的 fine-tuned 競爭對手。
本文的貢獻主要體現在兩個方面:
1. 提出了一種用于 VL-PTM 的跨模態 prompt tuning 新范式。研究者表示,據他們所知,這是 VL-PTM 跨模態 prompt tuning+ zero-shot、few-shot 視覺定位的首次嘗試;
2. 進行了全面的實驗,證明了所提方法的有效性。
CPT 框架細節
視覺定位的關鍵是建立圖像區域和文本表達之間的聯系。因此,一個優秀的跨模態 prompt tuning 框架應該充分利用圖像和文本的共指標記,并盡可能縮小預訓練和微調之間的差距。
為此,CPT 將視覺定位重新構建為一個填空問題。具體來說,CPT 框架由兩部分構成:一是用色塊對圖像區域進行唯一標記的視覺 sub-prompt;二是將查詢文本放入基于色彩的查詢模板的一個文本 sub-prompt。有了 CPT,VL-PTM 可以直接通過用目標圖像區域的彩色文本填充 masked token 來定位查詢文本,目標圖像區域的 objective form 與預訓練相同。
視覺 sub-prompt
給定一個圖像 I 以及它的區域候選 R = {v_1, v_2, . . . , v_n},視覺 sub-prompt 旨在用自然視覺標記對圖像區域進行獨特標記。有趣的是,研究者注意到,在文獻中,彩色邊界框被廣泛用于對圖像中的對象進行獨特標記,以實現可視化。受此啟發,研究者通過一組顏色 C 來關聯圖像區域和文本表達,其中每種顏色
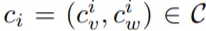
是由它的視覺外觀
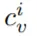
(如 RGB (255, 0, 0))和顏色文本
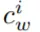
(如:red)來定義的。然后他們用一種獨特的顏色
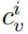
標記圖像中的每個區域候選 v_i,以此來定位,這會產生一組彩色圖像候選Ψ(R; C),其中 Ψ(·) 表示視覺 sub-prompt。
在實驗中,研究者發現,用實心塊給目標著色比用邊界框效果更好,因為純色目標在現實世界的圖像中更為常見(如紅色 T 恤、藍色車)。由于視覺 sub-prompt 被添加到原始圖像中,因此 VL-PTM 的架構或參數不會發生變化。
文本 sub-prompt
文本 sub-prompt 旨在提示 VL-PTM 建立查詢文本與被視覺 sub-prompt 標記的圖像區域的聯系。具體來說,此處用一個如下所示的模板 T (·) 將查詢文本 q(如「the horse watched by the woman」)轉換為填空查詢:
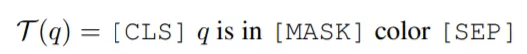
如此一來,VL-PTM 會被提示決定哪個區域的顏色更適合填充掩碼(如紅色或黃色),如下所示:
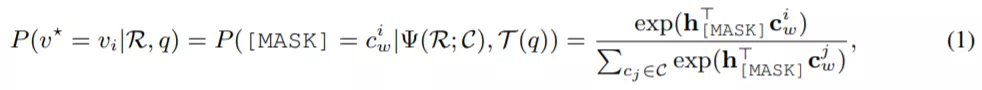
其中,v^* 表示目標區域,
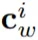
是
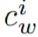
在預訓練 MLM head 中的嵌入。需要注意的是,這個過程并沒有引入任何新的參數,而且還縮小了預訓練和微調之間的差距,因此提高了 VL-PTM 微調的數據效率。
實驗結果
在實驗部分,研究者對 CPT 的能力進行了評估,設置了 zero-shot、few-shot 和全監督等多種情況,主要結果如下表 1 所示:
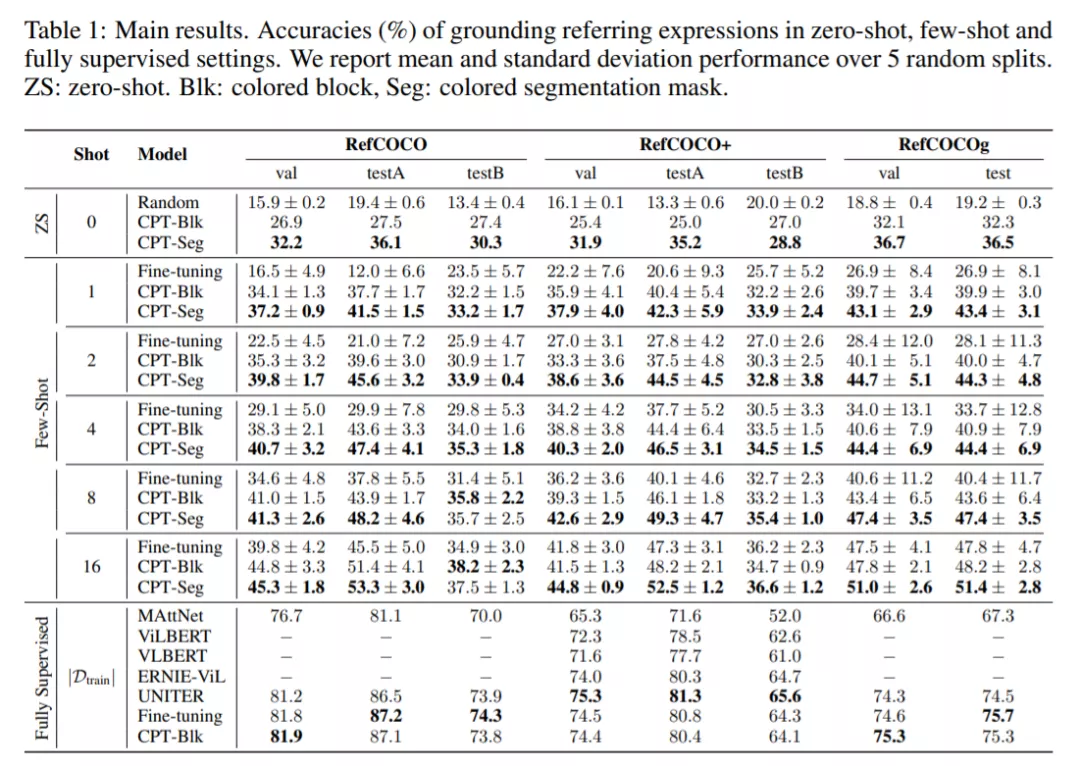
從表中可以看出:
1. 在 zero-shot 和 few-shot 設置中,CPT 的性能大大優于隨機基線和強微調基線。例如,使用色塊作為視覺 sub-prompt,在 RefCOCO one shot 中,CPT 絕對準確率提高了 17.3%,相對標準差平均降低了 73.8%。這表明 CPT 可以有效地提高 VL-PTM 微調的數據效率,并激發 VL-PTM 的視覺定位潛力。
2. 在視覺 sub-prompts 中用分割掩碼給目標著色(CPT-Seg)獲得了比塊(CPT-Blk)更好的結果。這是因為適合物體輪廓的純色在現實世界的圖像中更常見,這使得 CPT-Seg 成為更自然的視覺 sub-prompt(盡管需要更強的注釋來訓練分割工具)。
3. 值得注意的是,CPT 實現的標準差明顯小于微調。例如,在 RefCOCO 評估中,CPT-Blk one-shot 相對標準差平均降低了 73.8%。這表明,來自預訓練的連貫微調方法可以帶來更穩定的 few-shot 訓練,這是評估 few-shot 學習模型的關鍵因素。
4. 在 RefCOCO + 評估中,CPT-Blk 在 shot 數為 16 時比微調表現略差。原因是 RefCOCO + 有更多的基于顏色的表達(比如穿紅色襯衫、戴藍色帽子的人),這會干擾基于顏色的 CPT。然而,這個問題可以通過在全監督場景中使用更多的微調實例來緩解,在這種場景中,模型能夠學習如何更好地區分查詢文本和 promp 模板中的顏色。
5. 在全監督的設置下,CPT 實現了與強微調 VL-PTM 相當的性能。這表明,即使在全監督的場景中,CPT 也是 VL-PTM 的一種有競爭力的調優方法。
綜上所述,與普通的微調方法相比,CPT 在 zero-shot、few-shot 和全監督的視覺定位任務中都實現了與之相當或更優越、更穩定的性能。
更多細節請參見論文。