深度強化學習探索算法最新綜述,近200篇文獻揭示挑戰和未來方向
當前,強化學習(包括深度強化學習DRL和多智能體強化學習MARL)在游戲、機器⼈等領域有⾮常出⾊的表現,但盡管如此,在達到相同⽔平的情況下,強化學習所需的樣本量(交互次數)還是遠遠超過⼈類的。這種對⼤量交互樣本的需求,嚴重阻礙了強化學習在現實場景下的應⽤。為了提升對樣本的利⽤效率,智能體需要⾼效率地探索未知的環境,然后收集⼀些有利于智能體達到最優策略的交互數據,以便促進智能體的學習。近年來,研究⼈員從不同的⻆度研究RL中的探索策略,取得了許多進展,但尚⽆⼀個全⾯的,對RL中的探索策略進⾏深度分析的綜述。
 最新綜述,近200篇文獻揭示挑戰和未來方向">
最新綜述,近200篇文獻揭示挑戰和未來方向">論文地址:https://arxiv.org/pdf/2109.06668.pdf
本⽂介紹深度強化學習領域第⼀篇系統性的綜述⽂章Exploration in Deep Reinforcement Learning: A Comprehensive Survey。該綜述⼀共調研了將近200篇⽂獻,涵蓋了深度強化學習和多智能體深度強化學習兩⼤領域近100種探索算法。總的來說,該綜述的貢獻主要可以總結為以下四⽅⾯:
- 三類探索算法。該綜述⾸次提出基于⽅法性質的分類⽅法,根據⽅法性質把探索算法主要分為基于不確定性的探索、基于內在激勵的探索和其他三⼤類,并從單智能體深度強化學習和多智能體深度強化學習兩⽅⾯系統性地梳理了探索策略。
- 四⼤挑戰。除了對探索算法的總結,綜述的另⼀⼤特點是對探索挑戰的分析。綜述中⾸先分析了探索過程中主要的挑戰,同時,針對各類⽅法,綜述中也詳細分析了其解決各類挑戰的能⼒。
- 三個典型benchmark。該綜述在三個典型的探索benchmark中提供了具有代表性的DRL探索⽅法的全⾯統⼀的性能⽐較。
- 五點開放問題。該綜述分析了現在尚存的亟需解決和進⼀步提升的挑戰,揭⽰了強化學習探索領域的未來研究⽅向。
接下來,本⽂從綜述的四⼤貢獻⽅⾯展開介紹。
三類探索算法
 最新綜述,近200篇文獻揭示挑戰和未來方向">
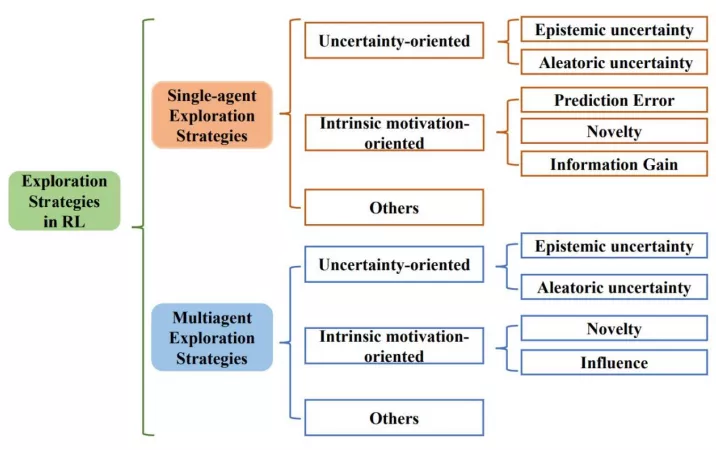
最新綜述,近200篇文獻揭示挑戰和未來方向">上圖展⽰了綜述所遵循的分類⽅法。綜述從單智能體深度強化學習算法中的探索策略、多智能體深度強化學習算法中的探索策略兩⼤⽅向系統性地梳理了相關⼯作,并分別分成三個⼦類:⾯向不確定性的(Uncertainty-oriented)探索策略、⾯向內在激勵的(Intrinsic motivation oriented)探索策略、以及其他策略。
1、⾯向不確定性的探索策略
通常遵循“樂觀對待不確定性”的指導原則(OFU Principle)「1」。這類做法認為智能體對某區域更⾼的不確定性(Uncertainty)往往是因為對該區域不充分的探索導致的,因此樂觀地對待不確定性,也即引導智能體去探索不確定性⾼的地⽅,可以實現⾼效探索的⽬的。
強化學習中⼀般考慮兩類不確定性,其中引導往認知不確定性⾼的區域探索可以促進智能體的學習,但訪問環境不確定性⾼的區域不但不會促進智能體學習過程,反⽽由于環境不確定性的⼲擾會影響到正常學習過程。因此,更合理的做法是在樂觀對待認知不確定性引導探索的同時,盡可能地避免訪問環境不確定性更⾼的區域。基于此,根據是否在探索中考慮了環境不確定性,綜述中將這類基于不確定性的探索策略分為兩個⼩類。
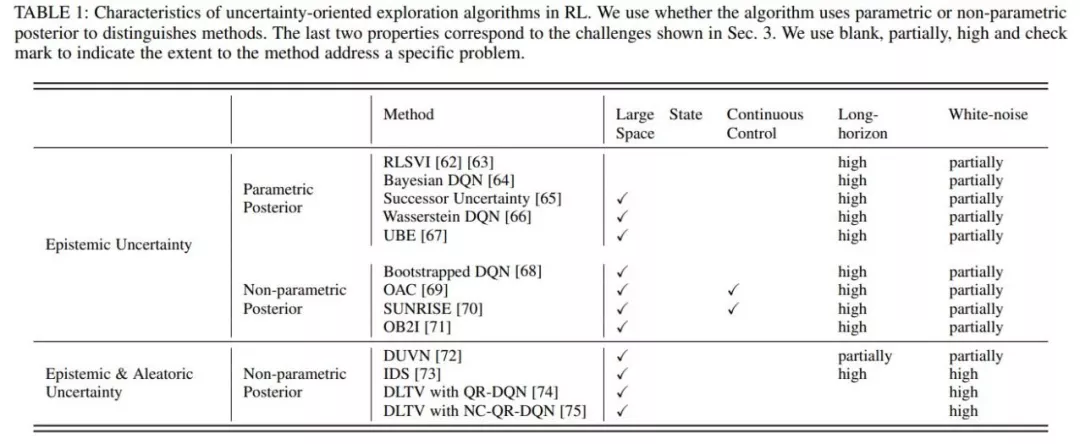
第⼀類只考慮在認知不確定性的引導下樂觀探索,典型⼯作有RLSVI「2」、Bootstrapped DQN「3」、OAC「4」、OB2I「5」等;第⼆類在樂觀探索的同時考慮避免環境不確定性的影響,典型⼯作有IDS「6」、DLTV「7」等。
2、⾯向內在激勵信號的探索策略
⼈類通常會通過不同⽅式的⾃我激勵,積極主動地與世界交互并獲得成就感。受此啟發,內在激勵信號導向的探索⽅法通常通過設計內在獎勵來創造智能體的成就感。從設計內在激勵信號所使⽤的技術,單智能體⽅法中⾯向內在激勵信號的探索策略可分為三類,也即估計環境動⼒學預測誤差的⽅法、狀態新穎性估計⽅法和基于信息增益的⽅法。⽽在多智能體問題中,⽬前的探索策略主要通過狀態新穎性和社會影響兩個⻆度考慮設計內在激勵信號。
估計環境動⼒學預測誤差的⽅法主要是基于預測誤差,⿎勵智能體探索具有更⾼預測誤差的狀態,典型⼯作有ICM「8」、EMI「9」等。
狀態新穎性⽅法不局限于預測誤差,⽽是直接通過衡量狀態的新穎性(Novelty),將其作為內在激勵信號引導智能體探索更新穎的狀態,典型⼯作有RND「10」、Novelty Search「11」、LIIR「12」等。
基于信息增益的⽅法則將信息獲取作為內在獎勵,旨在引導智能體探索未知領域,同時防⽌智能體過于關注隨機領域,典型⼯作有VIME「13」等。
而在多智能體強化學習中,有⼀類特別的探索策略通過衡量“社會影響”,也即衡量智能體對其他智能體的影響作⽤,指導作為內在激勵信號,典型⼯作有EITI和 EDTI「14」等。
3、其他
除了上述兩⼤類主流的探索算法,綜述⾥還調研了其他⼀些分⽀的⽅法,從其他⻆度進⾏有效的探索。這些⽅法為如何在DRL中實現通⽤和有效的探索提供了不同的見解。
這主要包括以下三類,⼀是基于分布式的探索算法,也即使⽤具有不同探索行為的異構actor,以不同的⽅式探索環境,典型⼯作包括Ape-x「15」、R2D2「16」等。⼆是基于參數空間噪聲的探索,不同于對策略輸出增加噪聲,采⽤噪聲對策略參數進⾏擾動,可以使得探索更加多樣化,同時保持⼀致性,典型⼯作包括NoisyNet「17」等。除了以上兩類,綜述還介紹了其他⼏種不同思路的探索⽅法,包括Go-Explore「18」,MAVEN「19」等。
四大挑戰
綜述重點總結了⾼效的探索策略主要⾯臨的四⼤挑戰。
- ⼤規模狀態動作空間。狀態動作空間的增加意味著智能體需要探索的空間變⼤,就⽆疑導致了探索難度的增加。
- 稀疏、延遲獎勵信號。稀疏、延遲的獎勵信號會使得智能體的學習⾮常困難,⽽探索機制合理與否直接影響了學習效率。
- 觀測中的⽩噪聲。現實世界的環境通常具有很⾼的隨機性,即狀態或動作空間中通常會出現不可預測的內容,在探索過程中避免⽩噪聲的影響也是提升效率的重要因素。
- 多智能體探索挑戰。多智能體任務下,除了上述挑戰,指數級增長的狀態動作空間、智能體間協同探索、局部探索和全局探索的權衡都是影響多智能體探索效率的重要因素。
綜述中總結了這些挑戰產⽣的原因,及可能的解決⽅法,同時在詳細介紹⽅法的部分,針對現有⽅法對這些挑戰的應對能⼒進⾏了詳細的分析。如下圖就分析了單智能體強化學習中基于不確定性的探索⽅法解決這些挑戰的能⼒。
 最新綜述,近200篇文獻揭示挑戰和未來方向">
最新綜述,近200篇文獻揭示挑戰和未來方向">三個經典的benchmark
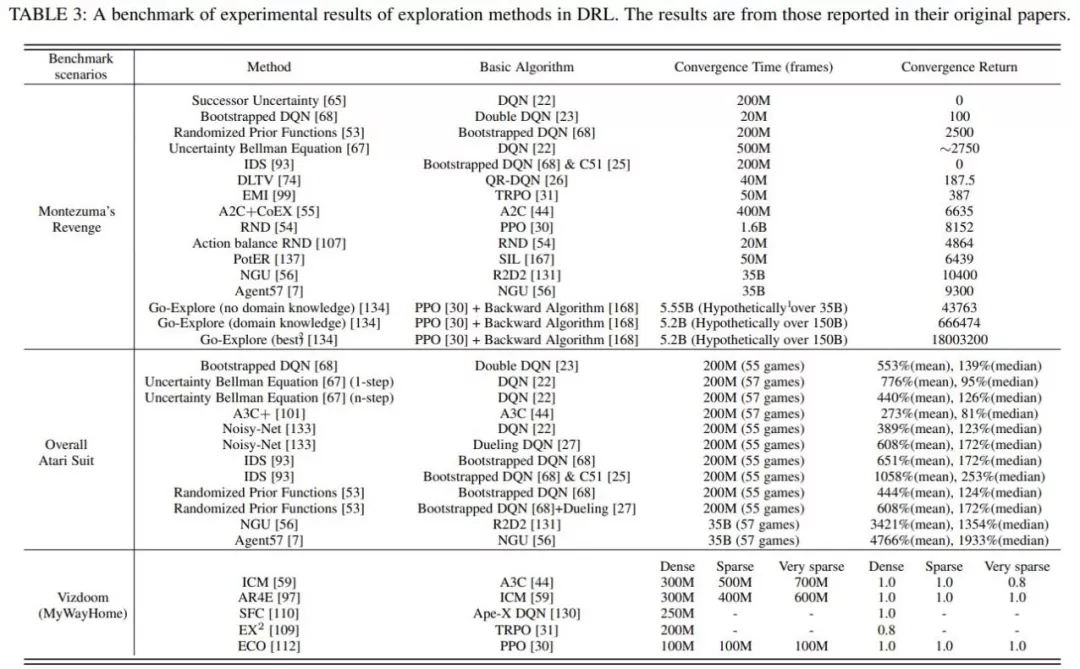
為了對不同的探索⽅法進⾏統⼀的實驗評價,綜述總結了上述⼏種有代表性的⽅法在三個代表性 benchmark上的實驗結果: 《蒙特祖瑪的復仇》,雅達利和Vizdoom。
蒙特祖瑪的復仇由于其稀疏、延遲的獎勵成為⼀個較難解決的任務,需要RL智能體具有較強的探索能⼒才能獲得正反饋;⽽穿越多個房間并獲得⾼分則進⼀步需要⼈類⽔平的記憶和對環境中事件的控制。
整個雅達利系列側重于對提⾼RL 智能體學習性能的探索⽅法進⾏更全⾯的評估。
Vizdoom是另⼀個具有多種獎勵配置(從密集到⾮常稀疏)的代表性任務。與前兩個任務不同的是,Vizdoom是⼀款帶有第⼀⼈稱視⻆的導航(和射擊)游戲。這模擬了⼀個具有嚴重的局部可觀測性和潛在空間結構的學習環境,更類似于⼈類⾯對的現實世界的學習環境。
 最新綜述,近200篇文獻揭示挑戰和未來方向">
最新綜述,近200篇文獻揭示挑戰和未來方向">基于上表所⽰的統⼀的實驗結果,結合所提出的探索中的主要挑戰,綜述中詳細分析了各類探索策略在這些任務上的優劣。
關于探索策略的開放問題和未來方向
盡管探索策略的研究取得了⾮常前沿的進展,但是仍然存在⼀些問題沒有被完全解決。綜述主要從以下五個⻆度討論了尚未解決的問題。
- 在⼤規模動作空間的探索。在⼤規模動作空間上,融合表征學習、動作語義等⽅法,降低探索算法的計算復雜度仍然是⼀個急需解決的問題。
- 在復雜任務(時間步較長、極度稀疏、延遲的獎勵設置)上的探索,雖然取得了一定的進展,⽐如蒙特祖瑪的復仇,但這些解決辦法代價通常較⼤,甚⾄要借助⼤量⼈類先驗知識。這其中還存在較多普遍性的問題值得探索。
- ⽩噪聲問題。現有的⼀些解決⽅案都需要額外估計動態模型或狀態表征,這⽆疑增加了計算消耗。除此之外,針對⽩噪聲問題,利⽤對抗訓練等⽅式增加探索的魯棒性也是值得研究的問題。
- 收斂性。在⾯向不確定性的探索中,線性MDP下認知不確定性是可以收斂到0的,但在深度神經⽹絡下維度爆炸使得收斂困難。對于⾯向內在激勵的探索,內在激勵往往是啟發式設計的,缺乏理論上合理性論證。
- 多智能體探索。多智能體探索的研究還處于起步階段,尚未很好地解決上述問題,如局部觀測、不穩定、協同探索等。
主要作者介紹
楊天培博⼠,現任University of Alberta博⼠后研究員。楊博⼠在2021年從天津⼤學取得博⼠學位,她的研究興趣主要包括遷移強化學習和多智能體強化學習。楊博⼠致⼒于利⽤遷移學習、層次強化學習、對⼿建模等技術提升強化學習和多智能體強化學習的學習效率和性能。⽬前已在IJCAI、AAAI、ICLR、NeurIPS等頂級會議發表論⽂⼗余篇,擔任多個會議期刊的審稿⼈。
湯宏垚博⼠,天津⼤學博⼠在讀。湯博⼠的研究興趣主要包括強化學習、表征學習,其學術成果發表在AAAI、IJCAI、NeurIPS、ICML等頂級會議期刊上。
⽩⾠甲博⼠,哈爾濱⼯業⼤學博⼠在讀,研究興趣包括探索與利⽤、離線強化學習,學術成果發表在ICML、NeurIPS等。
劉⾦毅,天津⼤學智能與計算學部碩⼠在讀,研究興趣主要包括強化學習、離線強化學習等。
郝建業博⼠,天津⼤學智能與計算學部副教授。主要研究⽅向為深度強化學習、多智能體系統。發表⼈⼯智能領域國際會議和期刊論⽂100余篇,專著2部。主持參與國家基⾦委、科技部、天津市⼈⼯智能重⼤等科研項⽬10余項,研究成果榮獲ASE2019、DAI2019、CoRL2020最佳論⽂獎等,同時在游戲AI、⼴告及推薦、⾃動駕駛、⽹絡優化等領域落地應⽤。