













5300億!巨型語言模型參數(shù)每年暴漲10倍,新「摩爾定律」要來了?
前不久,微軟和英偉達(dá)推出包含5300億參數(shù)的語言模型MT-NLG,這是一種基于transformer的模型,被譽(yù)為「世界上最強(qiáng),最大的語言生成模型」。
不過,這真的是一件值得歡欣鼓舞的事情嗎?
大腦的深度學(xué)習(xí)研究人員估計(jì),人類大腦平均包含860億個(gè)神經(jīng)元和100萬億個(gè)突觸。但不是所有的都用于語言。有趣的是,GPT-4預(yù)計(jì)將有大約100萬億個(gè)參數(shù)。
兩個(gè)「100萬億」。
這會(huì)是一個(gè)巧合嗎?我們不禁思考,建立與人腦大小差不多的語言模型是否是一個(gè)長(zhǎng)期可行的方法?
當(dāng)然了,經(jīng)過數(shù)百萬年的進(jìn)化,我們的大腦已經(jīng)成為了一個(gè)非常了不起的設(shè)備,而深度學(xué)習(xí)模型才發(fā)展了幾十年。誠然,我們的直覺告訴我們,有些東西不能夠通過計(jì)算來衡量的。
是深度學(xué)習(xí),還是「深度錢包」?在龐大的文本數(shù)據(jù)集上訓(xùn)練一個(gè)5300億個(gè)參數(shù)模型,無疑需要龐大的基礎(chǔ)設(shè)施。
事實(shí)上,微軟和英偉達(dá)使用數(shù)百臺(tái)DGX-A100的GPU服務(wù)器,每臺(tái)售價(jià)高達(dá)19.9萬美元,再加上網(wǎng)絡(luò)設(shè)備、主機(jī)等成本,任何想要重復(fù)這個(gè)實(shí)驗(yàn)的人都必須花費(fèi)大約1億美元。

嚴(yán)謹(jǐn)?shù)貋砜矗男┕居袠I(yè)務(wù)例子可以證明在深度學(xué)習(xí)基礎(chǔ)設(shè)備上花費(fèi)1億美元是合理的?或者1000萬美元?如果設(shè)計(jì)出來,那這些模型是為誰而設(shè)計(jì)的呢?
GPU集群:散熱、環(huán)保都成問題實(shí)際上,在GPU上訓(xùn)練深度學(xué)習(xí)模型是一項(xiàng)十分費(fèi)力的事情。
據(jù)英偉達(dá)服務(wù)器參數(shù)表顯示,每臺(tái)英偉達(dá) DGX A100服務(wù)器最高能耗為6.5千瓦。當(dāng)然,數(shù)據(jù)中心(或者服務(wù)器)也至少需要同樣多的散熱設(shè)備。

除非你是史塔克家族的人,需要拯救臨冬城,否則散熱將成為一大難題。
而且,隨著公眾對(duì)氣候和社會(huì)責(zé)任問題的意識(shí)增強(qiáng),公司還需要考慮他們的碳足跡問題。
馬薩諸塞大學(xué)2019年的一項(xiàng)研究「用GPU訓(xùn)練BERT,其碳足跡大致相當(dāng)于進(jìn)行一次橫跨美國的飛行」。
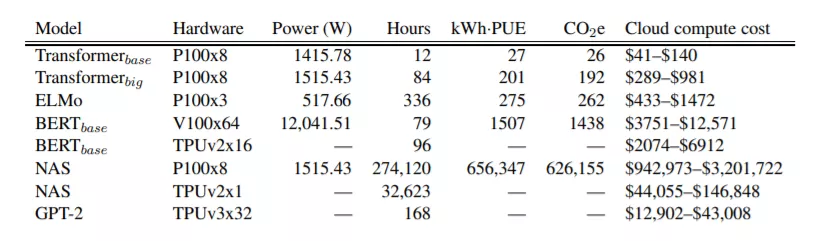
而BERT-Large的參數(shù)數(shù)量更是高達(dá)3.4億,訓(xùn)練起來的碳足跡究竟有多大?恐怕只是想想都害怕。
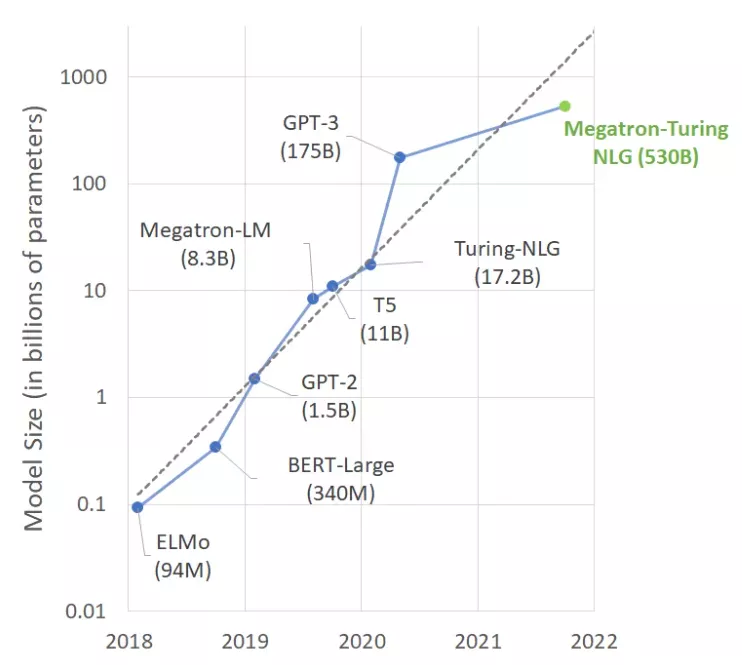
所以,我們真的應(yīng)該為MT-NLG模型的5300億個(gè)參數(shù)感到興奮嗎?。用這么多參數(shù)和算力換來的基準(zhǔn)測(cè)試性能改進(jìn),值得付出這些成本、復(fù)雜度和碳足跡嗎?
大力推廣這些巨型模型,真的有助于公司和個(gè)人理解和擁抱機(jī)器學(xué)習(xí)嗎?
而如果,我們把重點(diǎn)放在可操作性更高的技術(shù)上,就可以用來構(gòu)建高質(zhì)量的機(jī)器學(xué)習(xí)解決方案。比如下面這些技術(shù):
使用預(yù)訓(xùn)練模型絕大多數(shù)情況下,并不需要定制模型體系結(jié)構(gòu)。
一個(gè)好的起點(diǎn)是尋找那些已經(jīng)為能為你解決問題的(比如,總結(jié)英語文本)預(yù)訓(xùn)練模型。
然后,快速嘗試幾個(gè)模型來預(yù)測(cè)數(shù)據(jù)。如果參數(shù)表明,某個(gè)參數(shù)良好,那么就完全可以了。
如果需要更準(zhǔn)確的參數(shù),那就嘗試微調(diào)模型 (下面會(huì)有詳細(xì)介紹)。
使用小模型
在評(píng)估模型時(shí),應(yīng)該盡量選擇能夠提供所需精度的最小模型。這樣做預(yù)測(cè)速度更快,訓(xùn)練和推理所需要的硬件資源也更少。
算力昂貴,能省就省。
實(shí)際上,現(xiàn)在的機(jī)器學(xué)習(xí)模型越來越小,也早已不是什么新鮮事了。熟悉計(jì)算機(jī)視覺的人都會(huì)記得 2017年SqueezeNet 的問世,與 AlexNet 相比,SqueezeNet的規(guī)模縮小了98%,同時(shí)在精度表現(xiàn)上與AlexNet不相上下。
除了計(jì)算機(jī)視覺領(lǐng)域,NLP社區(qū)也在努力縮小模型的規(guī)模,其中大量使用了知識(shí)蒸餾等遷移學(xué)習(xí)技術(shù)。其中最出名的可能就是對(duì)谷歌BERT模型的改進(jìn)型DistilBERT。
與原始 BERT 模型相比,DistilBERT保留了97%的語言理解能力,同時(shí)模型體積縮小了 40%,速度提高了60%。相同的方法已應(yīng)用于其他模型,比如 Facebook 的 BART。
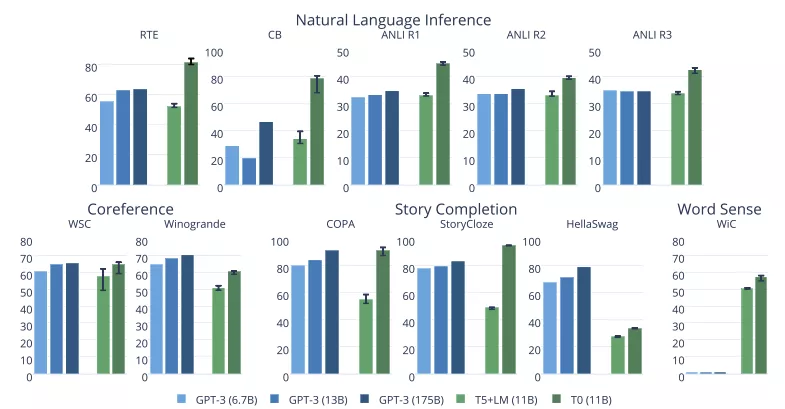
最近來自「Big Science」項(xiàng)目的最新模型也令人印象深刻。如下圖所示,這些項(xiàng)目中的 T0 模型在許多任務(wù)上都優(yōu)于 GPT-3的性能,但模型大小只有GPT-3的1/16。
微調(diào)模型
如果需要在一個(gè)高度專門化領(lǐng)域使用模型,大可不必從頭開始訓(xùn)練模型,這時(shí)應(yīng)該對(duì)模型進(jìn)行微調(diào),也就是說,僅在自己的數(shù)據(jù)集上訓(xùn)練幾個(gè)時(shí)期。
實(shí)際上,微調(diào)模型也是遷移學(xué)習(xí)的一種方式,目的還是節(jié)約資源,能省就省!
使用遷移學(xué)習(xí)的好處不少,比如:
- 需要收集、存儲(chǔ)、清理和注釋的數(shù)據(jù)更少
- 實(shí)驗(yàn)和數(shù)據(jù)迭代的速度更快
- 獲得產(chǎn)出所需的資源更少
換句話說就是:省時(shí)、省錢、省資源!
使用云基礎(chǔ)設(shè)施
云計(jì)算企業(yè)知道如何構(gòu)建高效的基礎(chǔ)設(shè)施。研究表明,基于云的基礎(chǔ)設(shè)施往往比替代方案能效更高、碳足跡更淺。Earth.org 表示,雖然云基礎(chǔ)設(shè)施目前并不完美,但仍然比替代方案更節(jié)能,可以促進(jìn)對(duì)環(huán)境有益的服務(wù),推動(dòng)經(jīng)濟(jì)增長(zhǎng)。”
確實(shí),在易用性、靈活性和「即用即付」方面,云當(dāng)然有很多優(yōu)勢(shì)。如果實(shí)在負(fù)擔(dān)不起自購 GPU,何不嘗試在 Amazon SageMaker(AWS 的機(jī)器學(xué)習(xí)托管服務(wù))上微調(diào)模型呢?
優(yōu)化模型從編譯器到虛擬機(jī),軟件工程師長(zhǎng)期以來一直使用工具來自動(dòng)優(yōu)化硬件代碼。
然而,和軟件行業(yè)相比,機(jī)器學(xué)習(xí)社區(qū)仍在為這個(gè)問題苦苦掙扎,這是有原因的。最重要的是,對(duì)機(jī)器學(xué)習(xí)模型的進(jìn)行優(yōu)化是一項(xiàng)極其復(fù)雜的任務(wù),其中涉及以下技術(shù)和條件:
- 硬件:大量面向加速訓(xùn)練任務(wù)(Graphcore、Habana)和推理任務(wù)(Google TPU、AWS Inferentia)的專用硬件。
- 剪枝:刪除對(duì)預(yù)測(cè)結(jié)果影響很小或沒有影響的模型參數(shù)。
- 融合:合并模型層(比如卷積和激活)。
- 量化:以較小的值存儲(chǔ)模型參數(shù)(比如使用8位存儲(chǔ),而不是32位存儲(chǔ))
所幸,現(xiàn)在已經(jīng)開始出現(xiàn)可用的自動(dòng)化工具,如Optimum 開源庫和 Infinity,這是一種容器化解決方案,延時(shí)低至1毫秒,但精度可以與Transformer相當(dāng)。
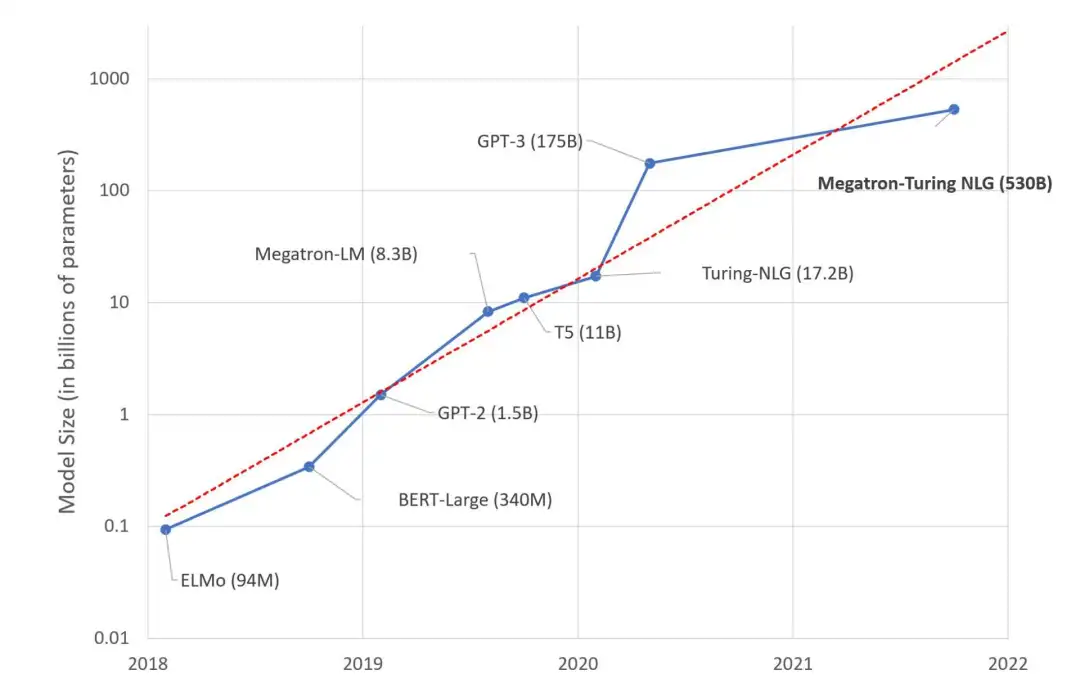
另一個(gè)「摩爾定律」要來了嗎?
在過去的幾年里,大型語言模型的規(guī)模每年都以10倍的速度增長(zhǎng)。看起來,另一個(gè)「摩爾定律」就要誕生了。
原來的摩爾定律,現(xiàn)在的命運(yùn)如何?關(guān)于「摩爾定律行將終結(jié)」的話題,早幾年就已經(jīng)甚囂塵上。

但有一點(diǎn)是確切無疑的,如果機(jī)器學(xué)習(xí)沿著「模型巨大化」的路走下去,路可能會(huì)越走越窄。收益遞減、成本增加、復(fù)雜度增加,這些可以預(yù)見的問題,可能會(huì)在不遠(yuǎn)的未來,把機(jī)器學(xué)習(xí)行業(yè)逼進(jìn)死胡同。
這就是人工智能未來的樣子嗎?
希望不是。與其追逐萬億參數(shù)的巨大模型,不如把更多精力放在構(gòu)建解決現(xiàn)實(shí)世界問題的、實(shí)用且高效的解決更好么?













