10 月 11 日 - 10 月 17 日,原定于加拿大蒙特利爾舉辦的計算機視覺領域三大頂會之一——ICCV 2021,正在線上舉行。今天,大會全部獎項已經公布。
6 月中旬,ICCV 2021 官方公布了論文評審結果。據統計,大會共接收了 6236 篇有效論文投稿,在首輪 desk reject 之后還有 6152 篇。

7 月下旬,大會放出了接收論文列表,共有 1617 篇被接收,其中包括 210 篇 Oral 和 1412 篇 Poster 論文,接收率約為 25.9%。相較于 2019 年的 25%,ICCV 2021 的接收率略有上升。
在所有被接收的論文中,來自中國的論文數量占比最高,達到了 43.2%,約為第二位美國(23.6%)的兩倍。
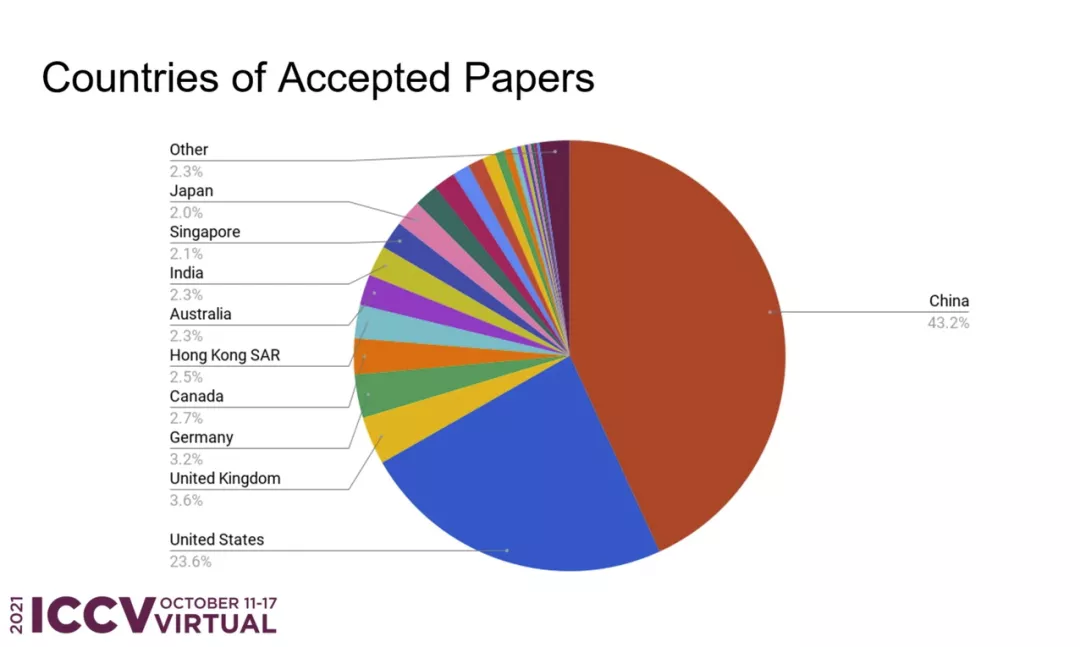
從接收論文的主題領域分布來看,前三位分別是:遷移 / 小樣本 / 無監督學習、圖像與視頻合成、識別與分類。
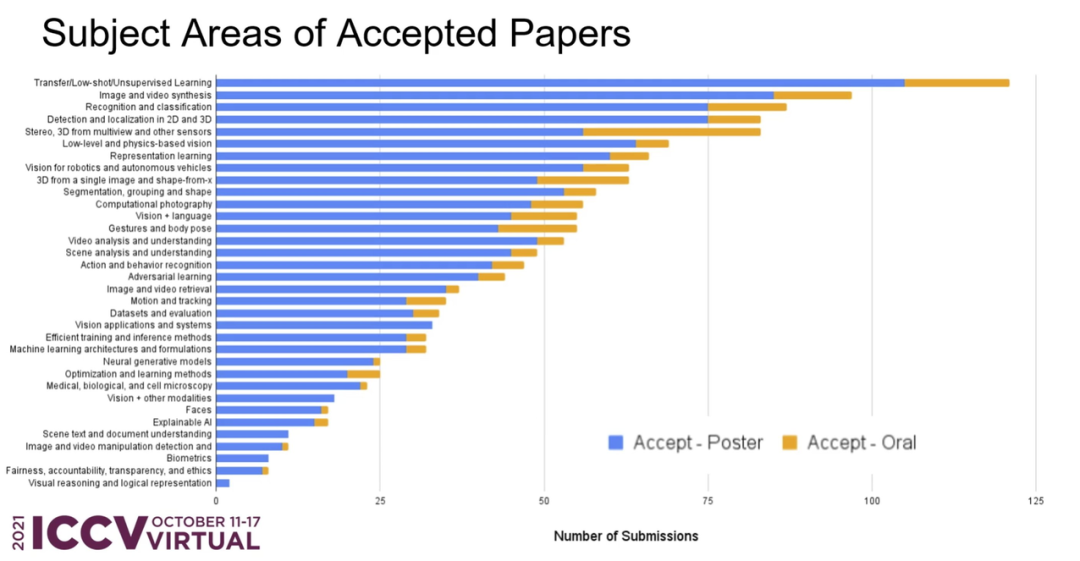
在所有投稿中,各個主題領域的接收率如何?ICCV 官方也進行了詳細的統計:
接下來,介紹一下本屆大會的獲獎信息。
最佳論文 - 馬爾獎
來自微軟亞洲研究院的研究者獲得 ICCV 2021 馬爾獎(最佳論文)。論文作者主要包括來自中國科學技術大學的劉澤、西安交通大學的林宇桐、微軟的曹越等人。
在 Swin Transformer 論文公開沒多久之后,微軟官方就在 GitHub 上開源了代碼和預訓練模型,涵蓋圖像分類、目標檢測以及語義分割任務。目前,該項目已收獲 4600 星。
- 獲獎論文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 作者機構:微軟亞洲研究院
- 論文地址:https://arxiv.org/pdf/2103.14030.pdf
- 項目地址:https://github.com/microsoft/Swin-Transformer

本文提出了一種新的 vision Transformer,即 Swin Transformer,它可以作為計算機視覺的通用骨干。相比之前的 ViT 模型,Swin Transformer 做出了以下兩點改進:
其一,引入 CNN 中常用的層次化構建方式構建分層 Transformer;
其二,引入局部性(locality)思想,對無重合的窗口區域內進行自注意力計算。
首先來看 Swin Transformer 的整體工作流,下圖 3a 為 Swin Transformer 的整體架構,圖 3b 為兩個連續的 Swin Transformer 塊。
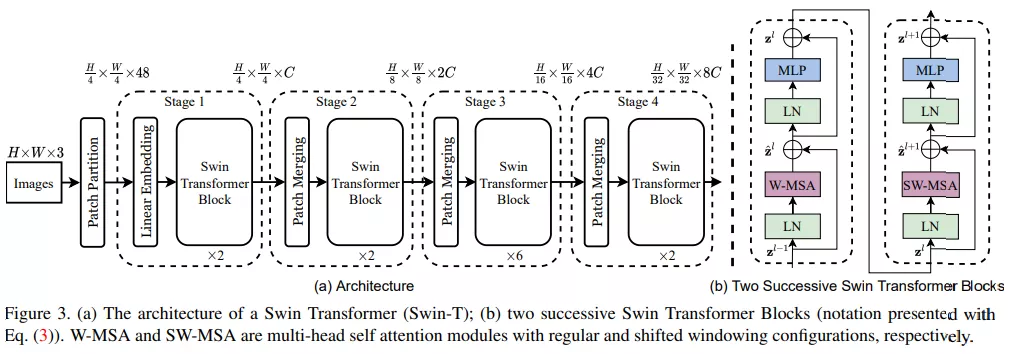
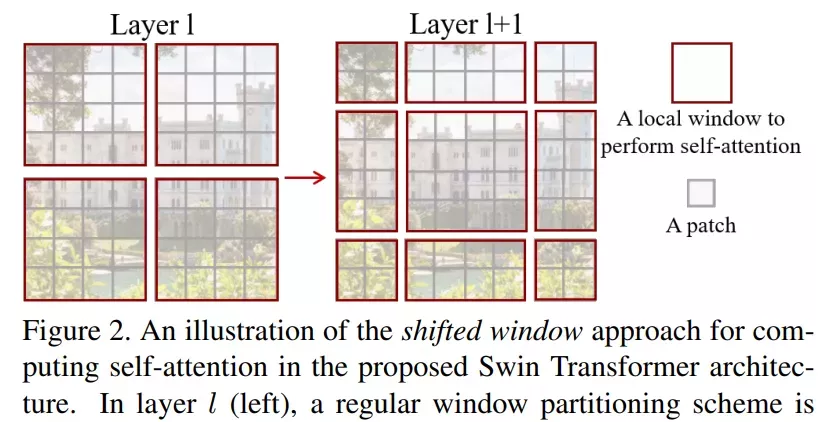
該研究的亮點在于利用移動窗口對分層 Transformer 的表征進行計算。通過將自注意力計算限制在不重疊的局部串口,同時允許跨窗口連接。這種分層結構可以靈活地在不同尺度上建模,并具有圖像大小的線性計算復雜度。下圖 2 為在 Swin Transformer 架構中利用移動窗口計算自注意力的工作流:
模型本身具有的特性使其在一系列視覺任務上都實現了頗具競爭力的性能表現。其中,在 ImageNet-1K 數據集上實現了 86.4% 的圖像分類準確率、在 COCO test-dev 數據集上實現了 58.7% 的目標檢測 box AP 和 51.1% 的 mask AP。目前在 COCO minival 和 COCO test-dev 兩個數據集上,Swin-L(Swin Transformer 的變體)在目標檢測和實例分割任務中均實現了 SOTA。

此外,在 ADE20K val 和 ADE20K 數據集上,Swin-L 也在語義分割任務中實現了 SOTA。
最佳學生論文獎
- 獲獎論文:Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
- 作者機構:蘇黎世聯邦理工學院、微軟
- 論文地址:https://arxiv.org/pdf/2108.08291.pdf
- 項目地址:github.com/cvg/pixel-perfect-sfm (http://github.com/cvg/pixel-perfect-sfm)

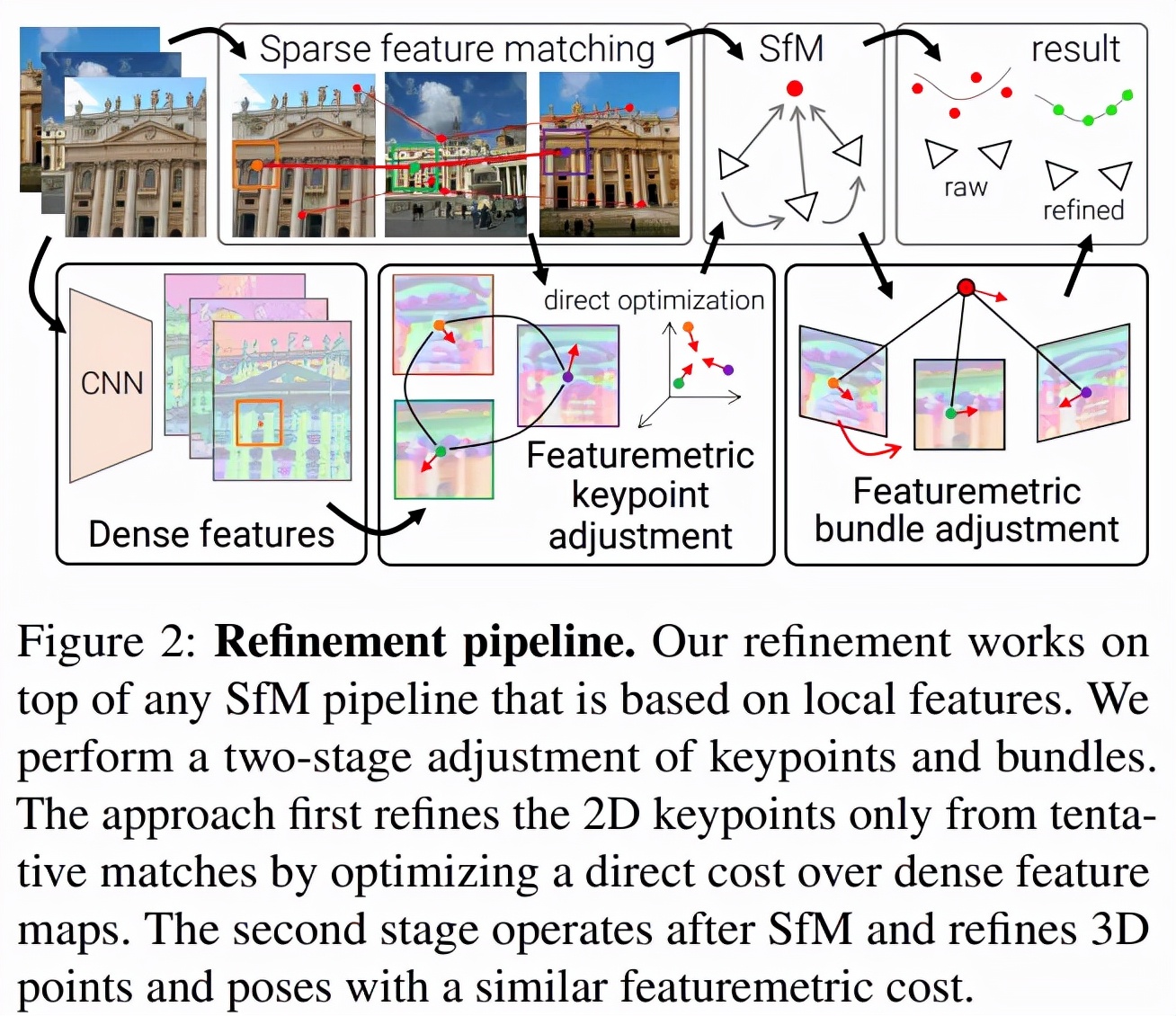
論文摘要:在多個視圖中尋找可重復的局部特征是稀疏 3D 重建的基礎。經典的圖像匹配范式一次性檢測每個圖像的全部關鍵點(keypoint),這可能會產生定位不佳的特征,使得最終生成的幾何形狀出現較大錯誤。研究者通過直接對齊來自多個視圖的低級圖像信息來細化運動恢復結構(structure-from-motion,SFM)的兩個關鍵步驟:首先在任何幾何估計之前調整初始關鍵點位置,然后細化點和相機姿態作為一個后處理。這種改進對大的檢測噪聲和外觀變化具有穩健性,因為它基于神經網絡預測的密集特征優化了特征度量誤差。這顯著提高了相機姿態和場景幾何的準確性,并適用于各種關鍵點檢測器、具有挑戰性的觀看條件和現成的(off-the-shelf)深度特征。該系統可以輕松擴展到大型圖像集合,從而實現像素完美的大規模眾包定位。該方法現已封裝為 SfM 軟件 COLMAP 的附加組件。
細化幾何原本是一種局部操作,但該研究表明局部密集像素可以起到較大的作用。SfM 通常盡可能早地丟棄圖像信息,該研究借助直接對齊用幾個步驟替代了 SfM。下圖 2 是該方法的概覽:
最佳論文榮譽提名獎
今年有四篇論文獲得 ICCV 2021 最佳論文榮譽提名獎。
- 論文 1:Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
- 作者機構:谷歌、加州大學伯克利分校
- 論文地址:https://arxiv.org/pdf/2103.13415.pdf

論文摘要:NeRF(neural radiance fields)使用的渲染過程以每像素單個光線對場景進行采樣,因此當訓練或測試圖像以不同分辨率觀察場景內容時,可能會產生過度模糊的渲染。該研究提出了 mip-NeRF,它以連續值的比例表示場景。他們通過高效地渲染消除反鋸齒圓錐錐體( anti-aliased conical frustums)取代光線,mip NeRF 減少了混疊瑕疵(aliasing artifacts),并顯著提高了其表示精細細節的能力,同時比 NeRF 快 7%,而大小僅為 NeRF 的一半。
與 NeRF 相比,mip NeRF 在數據集上降低了 17% 的平均錯誤率,在具有挑戰性的多尺度變體上降低了 60% 的平均錯誤率。此外,Mip NeRF 還能夠在多尺度數據集上與超采樣 NeRF 的精度相匹配,同時速度快 22 倍。
- 論文 2:OpenGAN: Open-Set Recognition via Open Data Generation
- 作者機構:卡內基梅隆大學
- 論文地址:https://arxiv.org/pdf/2104.02939.pdf

論文摘要:真實世界的機器學習系統需要分析新的測試數據,而這些測試數據與訓練數據不同。在 K-way 分類中,這被清晰地表述為開集識別,其核心是區分 K 個閉集類之外的開集數據的能力。關于開集的鑒別,有兩種思想:1) 利用離群(outlier)數據作為開集,對開 - 閉(open-vs-closed)二進制鑒別器分別進行鑒別學習;2) 使用 GAN 對閉集數據分布進行無監督學習,并將其鑒別器作為開集似然函數。然而,前者不能很好地泛化到不同的開放測試數據,而后者由于 GAN 的訓練不穩定效果不佳。
該研究提出了 OpenGAN,它通過將每種方法與幾種技術見解相結合來解決每種方法的局限性。首先,他們展示了在一些真實的離群數據上,精心選擇的 GAN 鑒別器已經達到了 SOTA 水平。其次,該研究用對抗性合成的假數據擴充可用的真實開集示例集。第三,也是最重要的,該研究在 K-way 網絡計算的特征上可以構建鑒別器。大量實驗表明,OpenGAN 顯著優于先前的開集方法。
- 論文 3:Viewing Graph Solvability via Cycle Consistency
- 作者機構:特倫托大學等
- 論文地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Arrigoni_Viewing_Graph_Solvability_via_Cycle_Consistency_ICCV_2021_paper.pdf

論文摘要:在運動恢復結構(structure-from-motion,SFM)中,視圖圖(viewing graph)是一種頂點與相機對應、邊代表基本矩陣的圖。該研究提供了一種新的公式和算法,用于確定視圖圖是否可解(即它唯一地確定一組投影相機)。已知的理論條件要么不能完全描述所有視圖圖的可解性,要么涉及求解含大量未知數的多項式方程組而非常難以計算。該論文的主要成果是提出一種利用循環一致性來減少未知數的方法。該研究通過以下 3 種方法來進一步理解可解性:(i) 完成對最多 9 個節點的所有先前未定最小圖的分類;(ii) 將實際可解性測試擴展到具有最多 90 個節點的最小圖;(iii) 通過證明有限可解性不等于可解性明確回答了一個開放型研究問題。最后,該研究以一個真實數據的實驗表明在實際情況中出現了無解的圖。
- 論文 4:Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
- 作者機構:Facebook AI 研究院、倫敦大學學院
- 論文地址:https://arxiv.org/pdf/2109.00512.pdf

論文摘要:由于缺乏真實的以類別為中心的 3D 標注數據,傳統的 3D 物體類別學習方法,主要是在合成數據集上進行訓練和評估。該研究的主要目標是通過收集與現有合成數據類似的真實世界數據來促進該領域的進展。因此,這項工作的主要貢獻是一個名為「Common Objects in 3D」的大規模數據集,,其中含有真實的多視角物體類別圖像,并附有相機姿態和 3D 點云標注真值。該數據集包含來自近 19,000 個視頻的 150 萬幀捕獲了 50 個 MS-COCO 類別的物體,因此它在類別和物體的數量方面都比其他數據集具有明顯優勢。研究者利用這個新數據集對幾種新視圖合成和以類別為中心的 3D 重建方法進行了大規模評估。此外,該研究還貢獻了 NerFormer——一種新穎的神經渲染方法,利用強大的 Transformer 來重建僅給定少量視圖的物體。
PAMI TC 獎
今年 ICCV 上的 PAMI 獎依舊包括四大獎項,分別是 Helmholtz 獎、Everingham 獎、Azriel Rosenfeld 終身成就獎和杰出研究者獎。
PAMI 是 IEEE 旗下的期刊,是模式識別和機器學習領域最重要的學術性匯刊之一,有著很高的影響因子和排名。
Helmholtz 獎
Helmholtz 獎項名稱來源于 19 世紀的物理、生理學家 Hermann von Helmholtz,旨在獎勵對計算機視覺領域做出重要貢獻的工作,頒發對象是十年前對計算機視覺領域產生重大影響的論文。

今年共有 3 篇論文獲得了 Helmholtz 獎,分別是:
- 論文 1:《ORB: An efficient alternative to SIFT or SURF》
- 論文鏈接:https://ieeexplore.ieee.org/document/6126544
- 論文 2:《HMDB: A large video database for human motion recognition》
- 論文鏈接:https://ieeexplore.ieee.org/document/6126543
- 論文 3:《DTAM: Dense tracking and mapping in real-time》
- 論文鏈接:https://ieeexplore.ieee.org/document/6126513
Everingham 獎
Everingham 獎的設立初衷是紀念計算機視覺領域專家 Mark Everingham 并激勵后來者在計算機視覺領域做出更多貢獻。頒獎對象包括為計算機視覺社區其他成員做出巨大貢獻的無私研究者或研究團隊。
本次獲得 Everingham 獎項的分別是 Detectron 目標檢測和分割軟件團隊和 KITTI 視覺基準團隊。

Detectron 目標檢測和分割軟件團隊成員包括 Ross Girshick, Yuxin Wu, llija Radosavovic, Alexander Kirillov, Georgia Gkioxari,Francisco Massa,Wan-Yen Lo,Piotr Dollar, 何愷明和其他開源貢獻者。

KITTI 視覺基準團隊成員包括 Andreas Geiger, Philip Lenz, Christoph Stiller, Raquel Urtasun 等。
Azriel Rosenfeld 終身成就獎
Azriel Rosenfeld 終身成就獎是為了紀念已故的計算機科學家和數學家 Azriel Rosenfeld 教授,旨在表彰在長期職業生涯中為計算機視覺領域作出突出貢獻的杰出研究者。
今年的 Azriel Rosenfeld 終身成就獎頒給了 UC 伯克利電氣工程與計算機科學系 NEC 特聘教授 Ruzena Bajcsy。

Ruzena Bajcsy 在斯坦福大學獲得了計算機科學博士學位。從 1972 年到 2001 年,Ruzena Bajcsy 是賓夕法尼亞大學計算機與信息科學系的教授,并于 1978 年建立了通用機器人、自動化、傳感和感知 (GRASP) 實驗室。28 年間,她一直從事機器人研究,包括計算機視覺、觸覺感知以及一般的系統識別問題。
在加入 UC 伯克利之前,她是美國國家科學基金會計算機與信息科學與工程理事會的負責人(1999-2001 年)。
Ruzena Bajcsy 美國國家工程院 (1997) 和美國國家醫學科學院 (1995) 的成員,以及 ACM Fellow 和 AAAI Fellow。2002 年 11 月,她被《探索》雜志評為 50 位最重要的女性之一。由于在機器人和自動化領域的貢獻,Ruzena Bajcsy 獲得了本杰明富蘭克林計算機和認知科學獎章(2009 年)和 IEEE 機器人與自動化獎(2013 年)。
杰出研究者獎
基于主要研究貢獻及對其他研究的激發影響等考量原則,杰出研究者獎旨在獎勵對計算機視覺發展作出重大貢獻的研究者。
今年的杰出研究者獎獲得者為 Pietro Perona 和 Cordelia Schmid。

Pietro Perona 是加州理工學院教授,他以計算機視覺領域的研究成果著名,同時也是加州理工學院計算機視覺小組的負責人。
Cordelia Schmid 是法國國家信息與自動化研究所(INRIA)的 THOTH 項目組負責人。她在 2012 年入選 IEEE Fellow,以表彰其在大規模圖像檢索、分類和目標檢測方面的貢獻。2020 年,Cordelia Schmid 獲得了 Milner 獎。