站點可靠性工程(SRE)的優(yōu)秀實踐
譯文【51CTO.com快譯】如果管理者計劃在組織內(nèi)部或項目中采用SRE文化,那么需要了解如何更好地培訓其SRE團隊并遵循優(yōu)秀實踐。
什么是站點可靠性工程(SRE)?
站點可靠性工程(SRE)這一概念起源于谷歌公司,SRE是一種IT運營方法,與DevOps密切相關(guān)。SRE團隊使用該軟件來管理系統(tǒng)、解決問題和自動化操作任務(wù)。
SRE團隊承擔IT運營團隊完成的人工任務(wù),并將其交給使用工具和自動化解決問題和管理生產(chǎn)系統(tǒng)的工程師或運營團隊。
在創(chuàng)建可擴展且高度可靠的軟件系統(tǒng)時,這是一種更具價值的實踐。SRE團隊通過代碼幫助組織管理龐大的基礎(chǔ)設(shè)施,這對于管理大量機器的系統(tǒng)管理員來說更具可擴展性和可持續(xù)性。
為什么SRE很重要?如何構(gòu)建優(yōu)秀的SRE團隊?
SRE就像是溝通軟件工程團隊和IT運營團隊之間的橋梁,填補了兩者之間的空白。幾乎在任何地方,SRE隨時隨地都在為生產(chǎn)系統(tǒng)中的故障做好準備時發(fā)揮作用。它確保組織的系統(tǒng)具有可擴展性、可靠性、可預測性和自動化。
SRE還設(shè)置了服務(wù)水平指標(SLI)、服務(wù)水平目標(SLO)、服務(wù)水平協(xié)議(SLA) ,其中定義了性能的真實數(shù)字、團隊滿足該協(xié)議必須達到的目標,以及系統(tǒng)對最終用戶的可靠性要求。SRE的主要目標是提高性能和運營效率。
因此,SRE人員不僅僅是“編寫代碼的運營人員”,也應該是開發(fā)團隊的成員,并且擁有不同的技能,尤其是在部署、配置管理、監(jiān)控、指標等方面。SRE團隊需要負責這些領(lǐng)域,正如開發(fā)工程師必須知道如何從數(shù)據(jù)存儲中提取數(shù)據(jù)一樣。而SRE團隊需要通力合作,交付易于更新、管理和監(jiān)控的產(chǎn)品。當企業(yè)正在實現(xiàn)DevOps項目,但意識到他們對開發(fā)人員的要求太高,并且需要專家來處理運營團隊過去處理的事情時,就自然會產(chǎn)生對SRE人員的需求。
在了解SRE以及SRE團隊如何與開發(fā)團隊合作之前,需要了解SRE如何在DevOps模式中發(fā)揮作用。
SRE團隊如何與DevOps團隊協(xié)同工作?
從本質(zhì)上來說,SRE是DevOps模式的實現(xiàn)。正如持續(xù)集成和持續(xù)交付是DevOps原則在軟件發(fā)布中的應用程序一樣,SRE是這些原則在軟件可靠性中的應用。
定義DevOps的方法有很多種。盡管如此,傳統(tǒng)模式是將開發(fā)(“Dev”)團隊和運營(“Ops”)團隊分開,這導致編寫代碼的團隊在客戶開始使用代碼時不負責代碼的工作方式,而會將這些代碼直接交給運維團隊安裝和支持。
根據(jù)谷歌公司的方法,組織可以使用SRE在其內(nèi)部更好地采用DevOps原則并衡量實施是否成功。
為了更好將這兩者結(jié)合起來,需要考慮以下原則:
- 減少組織孤島:SRE通過在開發(fā)人員和運營團隊之間共享所有權(quán)來提供幫助。這是DevOps的主要原則之一。當SRE團隊專注于改進問題檢測和應用程序性能時,運營人員可以專注于管理基礎(chǔ)設(shè)施,而開發(fā)人員可以專注于功能改進。
- 接受失敗:與DevOps團隊一樣,SRE團隊不會將故障和生產(chǎn)事件的責任推給IT團隊。無責任事后分析是一種SRE優(yōu)秀實踐,可以確保所有事件都被作為一種學習機會。當接受失敗正常化時,團隊可以承擔更大的風險,從而有可能帶來更大的創(chuàng)新,而不必擔心過多的挫折或阻礙。
- 實施漸進式變革:與DevOps團隊一樣,SRE團隊也鼓勵通過變革進行持續(xù)改進。SRE要求小而頻繁的更改。因此,任何負面影響的影響都會很小,并且可以輕松測試和實施低風險的增強功能。
- 利用工具和自動化:雖然DevOps團隊鼓勵自動化和技術(shù)采用,但SRE團隊專注于在IT團隊中采用一致的技術(shù)和信息訪問。這樣可以更輕松地管理和運營,并減少因技術(shù)不兼容而產(chǎn)生問題的機會。這種標準化還有助于確保團隊的成員可以更好地協(xié)作,因為工具是統(tǒng)一的,并且不太可能需要一些成員不具備的專業(yè)技能。
- 衡量一切:SRE將指標與反饋循環(huán)相結(jié)合,以衡量運營并確定改進機會。它還根據(jù)需要為風險和人工操作建立冗余性,使其通過衡量更具可預測性。通過應用指標數(shù)據(jù),團隊可以設(shè)定適當?shù)哪繕耍瑫r保持合理的績效預期。
現(xiàn)在知道SRE很重要的原因,以下繼續(xù)討論在接受SRE文化時必須遵循的SRE優(yōu)秀實踐。
SRE的優(yōu)秀實踐
在實施SRE時,組織可能需要一些時間來完善其策略并定制實踐以滿足運營需求。為了幫助加快這一過程,需要考慮以下SRE原則和優(yōu)秀實踐。
(1)錯誤預算
簡而言之,錯誤預算是在用戶開始不滿意之前,組織的服務(wù)在一段時間內(nèi)可以累積的錯誤量。可以將其視為用戶的痛苦容忍度,但適用于服務(wù)的可用性和延遲等特定維度。為了計算誤差預算,必須使用SLI方程:
SLI=[良好事件/有效事件]×100
在這個公式中的百分比表示為SLI,一旦組織為每個SLI定義了一個目標,這就是其服務(wù)水平目標(SLO),而錯誤預算就是剩余部分,最高可以達到100。
例如,假設(shè)組織正在衡量網(wǎng)站主頁的可用性。可用性是通過響應錯誤的請求數(shù)除以主頁收到的所有有效請求數(shù)量來衡量的(以百分比)表示。如果決定該可用性的目標是99.9%,則錯誤預算為0.1%。組織最多可以出現(xiàn)0.1%的錯誤(最好略低于0.1%),用戶會很樂意繼續(xù)使用該服務(wù)。
以下這個表格表明百分比如何轉(zhuǎn)換為出現(xiàn)錯誤的時間:
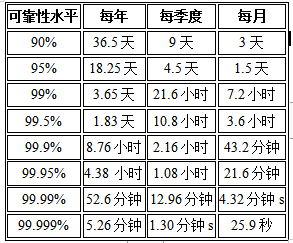
乍一看,錯誤預算似乎并不那么重要。它們只是IT團隊和DevOps團隊需要跟蹤以確保一切順利運行的一個指標。這種說法是錯誤的。錯誤預算不僅僅是確保組織履行合同承諾的便捷方式。如果團隊用盡了某一季度的錯誤預算,則新的預算通常會被凍結(jié)。它們也是開發(fā)團隊創(chuàng)新和冒險的機會。
(2)像用戶一樣定義服務(wù)水平目標(SLO)
服務(wù)水平目標(SLO)用來衡量對最終用戶很重要的可用性和性能。SLO是所有SRE的基礎(chǔ),而沒有SLO,組織就無法制定錯誤預算、確定開發(fā)工作的優(yōu)先級或進行及時有效的事件管理。SLO應該指定它們的衡量方式以及有效的條件。
①服務(wù)水平指標(SLI):
對所提供服務(wù)水平的某些方面(例如吞吐量、延遲)進行的定量度量。通過SLI:
- 用戶可以直接測量和觀察。
- 可以代表用戶的體驗,簡單來說就是了解用戶到底要衡量什么。
②服務(wù)水平目標(SLO):
SLI測量的服務(wù)級別的目標值或值范圍。通過SLO:
- 從用戶的角度定義服務(wù)應該如何執(zhí)行(通過SLI衡量)。簡單來說,提供服務(wù)應該有多好,以及需要改進服務(wù)的閾值。
- 是用戶可以考慮打開支持票證的時間點。
- 受業(yè)務(wù)需求驅(qū)動,而不僅僅是當前性能。
③服務(wù)水平協(xié)議(SLA):
如果服務(wù)未達到預期,則向客戶提供某種形式的補償?shù)纳虡I(yè)合同。簡單來說,SLA 就是SLO+后果。
(3)監(jiān)控錯誤和可用性
為了識別性能錯誤并保持服務(wù)可用性,SRE團隊需要了解他們的系統(tǒng)中發(fā)生了什么。需要監(jiān)控以驗證應用程序/系統(tǒng)是否按預期運行,這意味著服務(wù)、滿足特定目標以及了解更改時會發(fā)生什么。而且要在客戶之前知道這些。
(4)高效規(guī)劃能力
組織需要為業(yè)務(wù)的有機增長(可能是產(chǎn)品采用率的增加)和無機增長(由于功能發(fā)布、營銷活動等導致需求的突然增長)等進行規(guī)劃。這些活動將消耗更多資源(如黑色星期五導致的停機)。為準備這些活動,組織需要預測需求并規(guī)劃采購時間。
容量規(guī)劃的重要方面包括定期負載測試和資源調(diào)配。定期負載測試可讓組織了解系統(tǒng)在日常用戶的平均壓力下如何運行。此外,以任何形式增加容量都可能成本昂貴,因此組織了解在何處需要額外資源是關(guān)鍵。
(5)注重變革管理
在許多組織中,大多數(shù)停機都是由對活動系統(tǒng)的更改引起的,無論是新的二進制推送還是新的配置推送。每一個微小的變化都會影響業(yè)務(wù)。因此,需要分析每個變更所帶來的風險,并且應該受到監(jiān)督。組織需要通過查看大局來考慮長期變化的影響,而不僅僅是它們?nèi)绾斡绊懏斀竦南到y(tǒng)。
為確保在變更期間不會發(fā)生任何意外,必須由執(zhí)行推出階段的工程師或最好是一個可證明可靠的監(jiān)控系統(tǒng)對其進行監(jiān)控。如果檢測到意外行為,首先進行回滾,然后進行診斷,以最大限度地縮短平均恢復時間 (MTTR)。
(6)無責任的事后分析
無責任的事后分析有助于在組織中建立更可靠的系統(tǒng)。事后分析應該是無可指責的,并且應該關(guān)注流程和技術(shù),而不是人員的責任。
假設(shè)事件中涉及的人員根據(jù)他們當時可用的信息做出最好的選擇。將事件歸咎于某人或某個團隊會適得其反。因為這將會帶來人們不敢冒險、不敢創(chuàng)新、不敢解決問題的氛圍和環(huán)境。
失敗總是會發(fā)生的,這是沒有辦法的事情。但是,通過良好的事件解決方案和回顧性實踐,經(jīng)歷失敗也可能是有益的。它揭示了需要關(guān)注的領(lǐng)域以提高彈性。只要人們從事件中吸取教訓,就會取得進步。
(7)勞動管理
SRE的主要關(guān)注點之一是自動化。一些重復性勞動對于開發(fā)人員來說是一種時間的浪費,通過SRE創(chuàng)建框架、流程、內(nèi)部工具/構(gòu)建工具來消除這些重復性勞動,將會讓工程師專注于技術(shù)創(chuàng)新。
結(jié)論
本文試圖涵蓋建立成功的SRE團隊所需的基本概念和實踐。如果管理者計劃在項目和組織內(nèi)部采用 SRE文化,需要培訓團隊、遵循優(yōu)秀實踐并信任該過程。雖然不可能達到 100% 的完美,但是會讓事情變得更加精簡并盡可能接近完美。
原文標題:Site Reliability Engineering (SRE) Best Practices,作者:Rayan Das
【51CTO譯稿,合作站點轉(zhuǎn)載請注明原文譯者和出處為51CTO.com】