刷新ImageNet最高分!谷歌大腦華人研究員發(fā)布超強(qiáng)Transformer
近日,谷歌大腦團(tuán)隊公布了Vision Transformer(ViT)進(jìn)階版ViT-G/14,參數(shù)高達(dá)20億的CV模型,經(jīng)過30億張圖片的訓(xùn)練,刷新了ImageNet上最高準(zhǔn)確率記錄——90.45%,此前的ViT取得的最高準(zhǔn)確率記錄是 88.36%,不僅如此,ViT-G/14還超過之前谷歌提出的Meta Pseduo Labels模型。
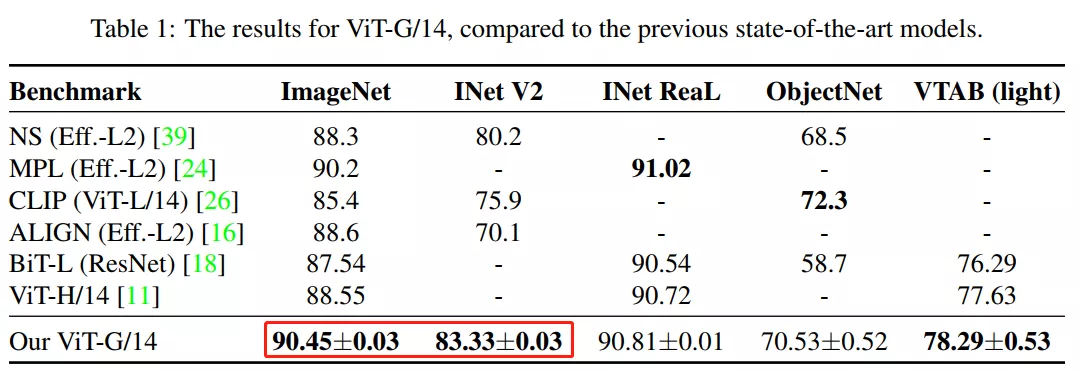
Vision Transformer模型的縮放規(guī)律
在多項基準(zhǔn)測試中,ImageNet, ImageNet-v2和VTAB-1k,ViT-G/14的表現(xiàn)都刷新了記錄。
例如,在幾張照片的識別挑戰(zhàn)中,準(zhǔn)確率提高了五個百分點以上。研究人員隨后訓(xùn)練了多個更微型的模型版本,以尋找架構(gòu)的縮放規(guī)律(scaling law),結(jié)果觀察到性能遵循冪律函數(shù)(power-law function),類似于用于NLP的Transformer模型。
2017年由谷歌首次引入的 Transformer 架構(gòu)迅速成為最受歡迎的NLP深度學(xué)習(xí)模型設(shè)計,其中 OpenAI的GPT-3是最著名的。OpenAI 去年發(fā)布的一項研究描述了這些模型的縮放規(guī)則(Scaling rules)。
OpenAI 通過訓(xùn)練幾個不同規(guī)模的可比模型,改變訓(xùn)練數(shù)據(jù)的數(shù)量和處理能力,開發(fā)了一個用于評估模型準(zhǔn)確性的冪律函數(shù)。此外,OpenAI 發(fā)現(xiàn)更大的模型不僅性能更好,而且計算效率也更高。
與 NLP 模型不同,大多數(shù)SOTA的 CV 深度學(xué)習(xí)模型,采用的是卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)(CNN)。2012年, 一個CNN模型贏得了ImageNet競賽,CNN因此聲名鵲起。
隨著Transformer最近在 NLP 領(lǐng)域的成功,研究人員已經(jīng)開始關(guān)注它在視覺問題上的表現(xiàn); 例如,OpenAI 已經(jīng)構(gòu)建了一個基于 GPT-3的圖像生成系統(tǒng)。
谷歌在這個領(lǐng)域一直非常活躍,在2020年年底使用他們專有的 JFT-300M 數(shù)據(jù)集訓(xùn)練了一個600m 參數(shù)的 ViT 模型。

△ 去年10月,谷歌大腦團(tuán)隊發(fā)布了Vision Transformer(ViT)
而新的ViT-G/14模型使用 JFT-3B 預(yù)先訓(xùn)練,JFT-3B是升級版數(shù)據(jù)集,包含大約30億張圖片。
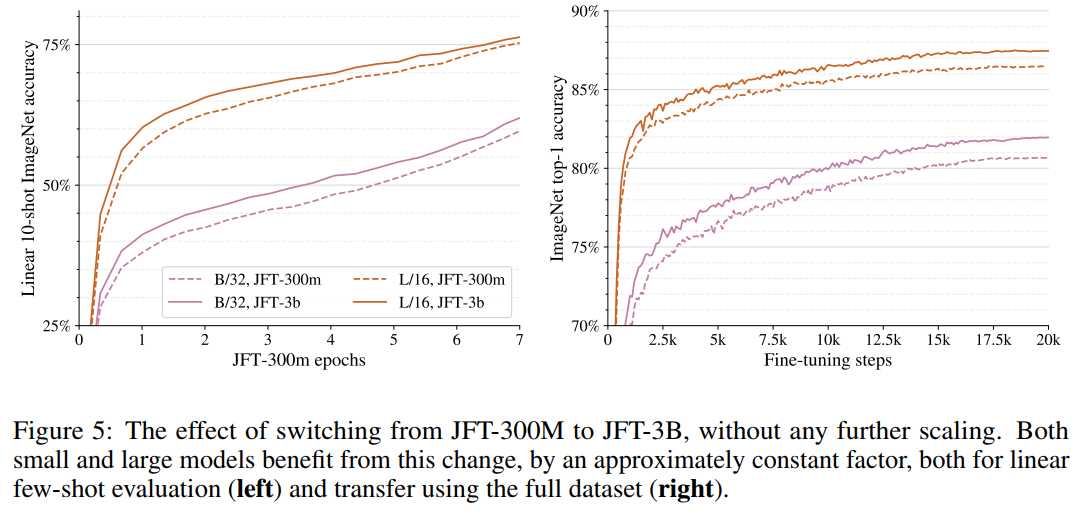
研究團(tuán)隊改進(jìn)了 ViT 架構(gòu),增加了內(nèi)存使用,使模型能夠適應(yīng)單個 TPUv3核心。研究人員在預(yù)先訓(xùn)練的模型上使用少量和微調(diào)的遷移學(xué)習(xí)來評估 ViT-G/14和其他較小模型的性能。這些發(fā)現(xiàn)被用來創(chuàng)建縮放規(guī)則,類似于 NLP 規(guī)則:
根據(jù)冪律函數(shù),縮放更多的計算、模型和數(shù)據(jù)可以提高準(zhǔn)確性;
在較小的模型中,準(zhǔn)確性可能是一個障礙;
大型數(shù)據(jù)集有助于大型模型。
目前,ViT-G/14得分在 ImageNet 排行榜上排名第一。下面的八個得分最高的模型同樣是由谷歌的研究人員創(chuàng)建的,而第十個模型來自Facebook。
作者團(tuán)隊

本次論文團(tuán)隊成員是此前發(fā)布ViT模型的4名成員,其中,第一作者是Xiaohua Zhai (翟曉華)。
https://sites.google.com/site/xzhai89/home
翟曉華目前是谷歌大腦研究員。研究領(lǐng)域為深度學(xué)習(xí)和計算機(jī)視覺。興趣范圍包括表征學(xué)習(xí)、遷移學(xué)習(xí)、自監(jiān)督學(xué)習(xí)、生成模型、跨模態(tài)感知。
根據(jù)他的個人網(wǎng)站提供的信息,2009年,翟曉華本科畢業(yè)于南京大學(xué),2014年取得北京大學(xué)計算機(jī)科學(xué)博士學(xué)位。
另外,論文作者Alexander Kolesnikov,同為谷歌大腦研究員,研究領(lǐng)域包括人工智能、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)和計算機(jī)視覺。
畢業(yè)于奧地利Institute of Science and Technology Austria (IST Austria),博士論文為Weakly-Supervised Segmentation and Unsupervised Modeling of Natural Images(自然圖像的弱監(jiān)督分割和無監(jiān)督建模)。
另一名作者Neil Houlsby,研究領(lǐng)域為機(jī)器學(xué)習(xí)、人工智能、計算機(jī)視覺和自然語言處理。
第四名作者Lucas Beyer,是一名自學(xué)成才的黑客、研究科學(xué)家,致力于幫助機(jī)器人了解世界、幫助人類了解深度學(xué)習(xí)。