Google X華人博士發布機器人模擬器SimGAN,ICLR2021已發表
工科的同學想必離不開各種各樣的模擬器,模擬器使各種工程學科能夠用最少的人力快速制作原型。
在機器人技術領域,物理模擬為機器人提供了一個安全而廉價的虛擬操場,機器人可以利用深強化學習(DRL)等技術獲得物理技能。
然而,由于仿真中的手工衍生物理并不完全匹配真實世界,完全在仿真中訓練的控制策略在真實硬件上測試時可能失敗ーー這是一個被稱為仿真到真實(sim-to-real)或域適應的問題。
基于知覺的任務(如抓取)的模擬與真實的差距已經用 RL-cycleGAN 和 RetinaGAN 解決了,但是由于機器人系統的動態性仍然存在差距。
RL-cycleGAN和RetinaGAN在新智元之前的推送《Google X教你用模擬器訓練機器人,準確率超93%,ICRA2021已發表》中有介紹。
這讓我們不禁要問,我們能從一些真實的機器人軌跡中學到更精確的物理模擬器嗎?如果是這樣,這樣一個改進的模擬器可以用標準的 DRL 訓練來改進機器人控制器,使其在現實世界中成功。
基于這個想法,Google 和 X 團隊共同在ICRA2021上發表了一篇論文《SimGAN: 混合模擬器識別領域適應通過對抗性的強化學習》,文中提出把物理模擬器作為一個可學的組件,由 DRL 訓練具有特殊的獎勵功能,懲罰在模擬中產生的軌跡(即,隨著時間的推移機器人的運動),少量軌跡之間的差異,收集真實的機器人運動軌跡。

本文作者超半數為華人,第一作者Yifeng Jiang,是斯坦福大學計算機科學專業的二年級博士生,由C. Karen Liu博士指導。
他在佐治亞理工學院獲得了電子與計算機工程學士學位。在進入研究生院之前,在上海交通大學獲得了學士學位,是密歇根大學上海交通大學聯合研究所的成員。他的研究興趣是機器人應用的計算機動畫和物理模擬,以及統計技術如何在這些領域中發揮作用,除此之外對數值優化,人類認知和運動學習也很感興趣。
文中使用生成對抗性網絡(GANs)來提供這種獎勵,并制定了一個混合模擬器,它結合了可學習的神經網絡和分析物理方程,來平衡模型的表達性和物理正確性。在機器人運動任務上,該方法優于多個強基線,包括領域隨機化。
一個可學習的混合模擬器傳統的物理模擬器是一個程序,用來解決微分方程,在虛擬世界中模擬運動或相互作用的物體。
對于這項工作,有必要建立不同的物理模型來代表不同的環境——如果一個機器人在床墊上行走,床墊的變形需要考慮在內(例如,與有限元分析一起)。
然而,由于機器人在現實世界中可能遇到的場景的多樣性,這種特定環境的建模技術將是冗長的(甚至是不可能的) ,這就是為什么采用基于機器學習的方法是有用的。
雖然模擬器可以完全從數據中學習,但如果訓練數據不包括足夠廣泛的各種情況,那么學習的模擬器如果需要模擬未經訓練的情況,就可能違反物理定律(即偏離現實世界的動力學)。
因此,在如此有限的模擬器中訓練的機器人在現實世界中更有可能失敗。
為了克服這一復雜性,文中構造了一個混合模擬器,結合了可學習的神經網絡和物理方程。
具體地說,研究人員使用一個可學習的仿真參數函數來代替通常由人工定義的模擬器參數ーー接觸參數(如摩擦系數和恢復系數)和電機參數(如電機增益) ,因為接觸的未建模細節和電機動態是產生仿真間隙的主要原因。
與傳統的模擬器將這些參數視為常數不同,在混合模擬器中,這些參數是狀態相關的ーー它們可以根據機器人的狀態而改變。
例如,電機在較高的速度下會變得較弱。這些典型的未建模物理現象可以使用與狀態相關的模擬參數函數來捕獲。
此外,雖然接觸和電機參數通常難以識別和易于變化,由于磨損,我們的混合模擬器可以自動學習他們從數據。例如,模擬器不再需要手動指定機器人腳的參數,而是從訓練數據中學習這些參數。
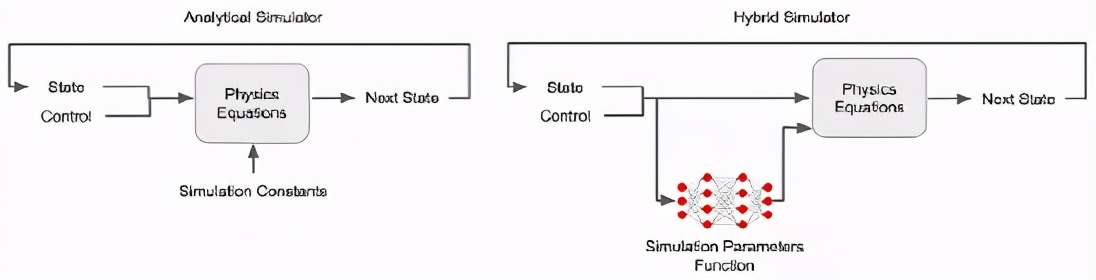
混合模擬器的另一部分由物理方程組成,確保模擬遵循物理學的基本定律,如能量守恒,使其更接近真實世界,從而減少模擬與真實世界的差距。
在之前的床墊例子中,可學習的混合模擬器能夠模擬床墊的接觸力。由于學習的接觸參數是狀態相關的,模擬器可以根據機器人腳相對于床墊的距離和速度來調節接觸力,模擬可變形表面的剛度和阻尼的影響。
因此,我們不需要為可變形的表面專門設計一個解析的模型。
使用GAN模擬器學習成功地學習上面討論的模擬參數函數將導致一個混合模擬器,可以產生類似真正的機器人的軌跡。
使這種學習成為可能的關鍵是為軌跡之間的相似性定義一個度量標準。
GAN最初設計用于生成具有相同分布或風格(style)的合成圖像,只有少量真實圖像,可用于生成與真實圖像無法區分的合成軌跡。
GAN有兩個主要部分,一個是學習生成新實例的生成器,另一個是判別器,評估新實例與訓練數據的相似程度。
在這種情況下,可學習的混合模擬器作為 GAN 生成器,而 GAN 鑒別器提供相似性評分。
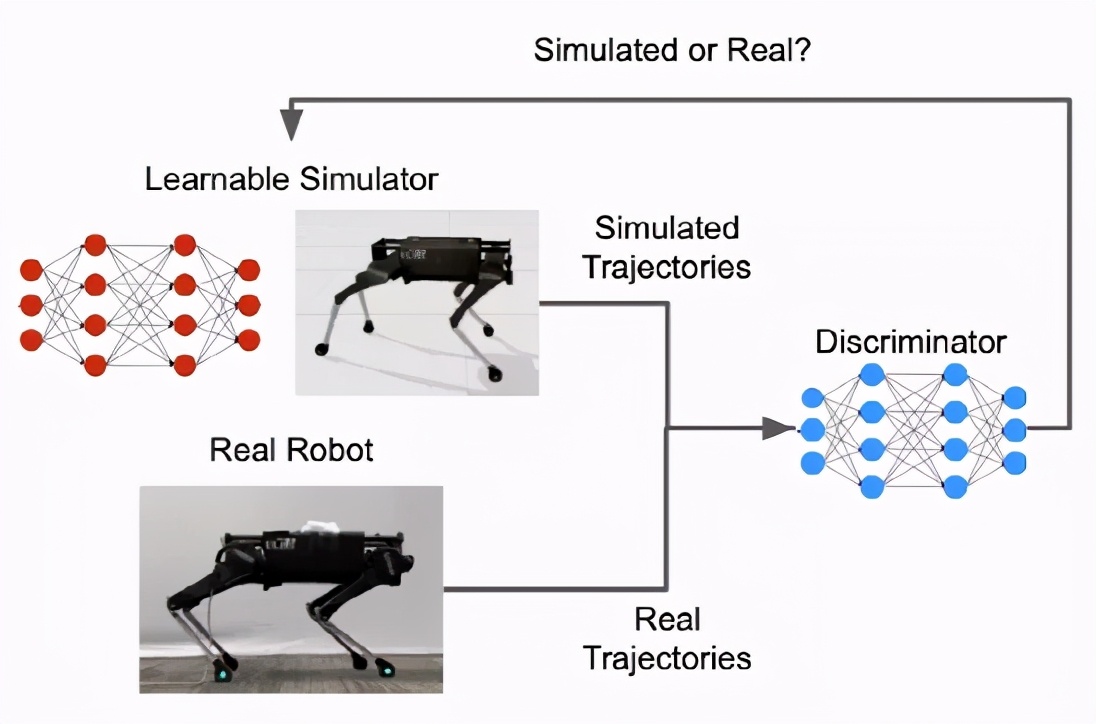
將模擬模型的參數與現實世界中收集到的數據進行擬合,這一過程稱為系統辨識過程(SysID) ,已經成為許多工程領域中的常見做法。
例如,可變形表面的剛度參數可以通過測量表面在不同壓力下的位移來確定。這個過程通常是手動的和繁瑣的,但是使用 GANs 可以更有效率。例如,SysID 經常需要一個手工制作的度量標準來衡量模擬軌跡和真實軌跡之間的差異。對于 GANs,這樣的度量是由鑒別器自動學習的。此外,為了計算差異度量,傳統的 SysID 需要將每個模擬軌跡配對到使用相同控制策略生成的對應實際軌跡。
由于 GAN 鑒別器只采用一個軌跡作為輸入,并計算在現實世界中chuxian的可能性,因此不需要這種一對一的配對。
使用強化學習學習模擬器和優化策略把所有的東西融合到一起,我們將模擬學習形式化為一個 RL 問題。神經網絡從少量的現實軌跡中學習狀態相關的接觸和電機參數。對神經網絡進行優化,使模擬軌跡與實際軌跡之間的誤差最小。
需要注意的是,在一段較長的時間內盡量減少這種錯誤是很重要的ー一種能夠準確預測更遠的未來的模擬將導致更好的控制政策。RL 非常適合這一點,因為它隨著時間的推移優化了累積的獎勵,而不僅僅是優化了單步獎勵。
在學習了混合模擬器并且變得更加準確之后,我們再次使用 RL 在模擬中改進機器人的控制策略。
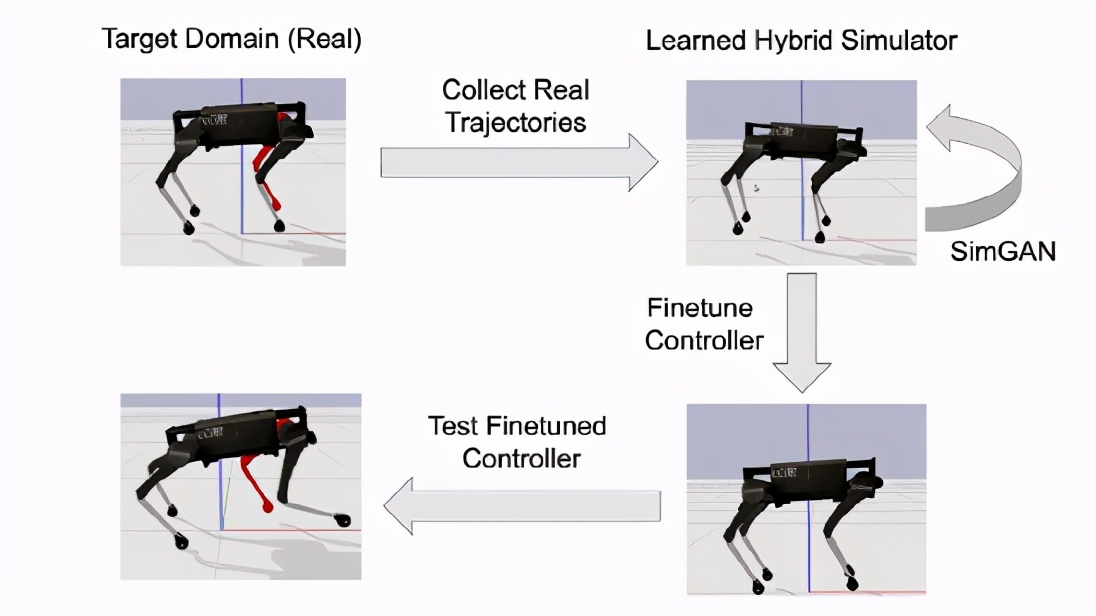
結果表明,SimGan優于多個sota模型基線,包括領域隨機化(DR)和直接細化目標域(FT)。
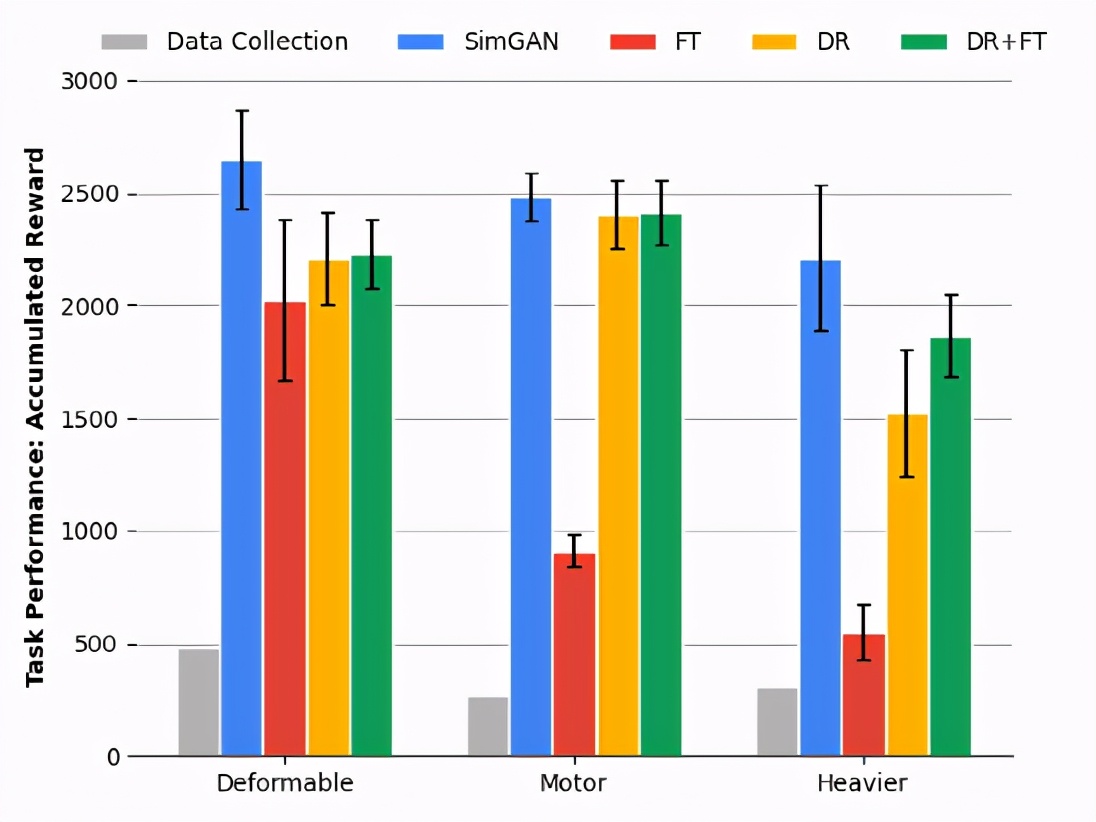
仿真與現實的差距是阻礙機器人利用強化學習能力的關鍵瓶頸之一。
通過學習一個模擬器來應對這個挑戰,這個模擬器可以更忠實地模擬真實世界的動態,同時只使用少量的真實世界數據。可以成功地部署在此模擬器中改進的控制策略。為了達到這個目的,我們在經典物理模擬器的基礎上增加了可學習的組件,并使用對抗性的強化學習語言來訓練這個混合模擬器。
到目前為止,我們已經測試了它在運動任務中的應用,我們希望通過將它應用于其他機器人學習任務,如導航和操作,來構建這個通用框架。