準確率可提升50%以上,Facebook用遷移學習改進代碼自動補全
代碼自動補全功能(應用程序預測文本輸入中的下一項)已成為消息傳遞等任務中便捷且廣泛使用的工具,也是用于計算機編程所需的集成開發環境(IDE)最重要功能之一。
最近的研究表明,代碼自動補全可以通過深度學習來實現,訓練數據來自程序員使用 IDE 編碼行為的真實數據,使軟件語言模型能夠獲得顯著的準確率提升。然而,對于不太流行的編程語言來說,經常會遇到一個問題,即可用的 IDE 數據集可能不足以訓練出一個模型。
近日,來自 Facebook 的研究團隊在論文《Improving Code Autocompletion with Transfer Learning》中展示了遷移學習如何在自動補全預測任務上進行微調之前,實現在非 IDE、非自動補全和不同語言示例代碼序列上的預訓練。實驗結果表明,該方法在非常小的微調數據集上提高了超過 50% 準確率,在 50k 標記示例上提高了超過 10% 準確率。

論文鏈接:https://arxiv.org/pdf/2105.05991.pdf
本文的貢獻主要包括以下幾個方面:
- 該研究從版本控制提交獲得的源代碼文件,預訓練了兩個 transformer 軟件語言模型 GPT-2 和 BART,結果顯示它們在自動補全預測方面的性能,比直接使用實際 IDE 代碼序列的微調提高了 2.18%;
- GPT-2 模型在兩個真實數據集上進行了訓練:IDE 編寫程序期間和代碼補全選擇期間記錄的代碼序列。預訓練和針對特定任務的微調相結合能夠使模型性能更好,高出基準模型 3.29%;
- 該研究顯示,與僅對 Python 實例進行訓練的模型相比,與在 Hack 實例上進行了預訓練并在 10k Python 實例上進行了微調的模型進行比較,在不同編程語言上進行預訓練可將準確率提高 13.1%;
- 通過在線 A/B 測試,該研究證明了在三個遷移學習維度(任務、領域和語言)上的改進,自動補全工具的使用率分別提高了 3.86%、6.63% 和 4.64%。
實驗設置
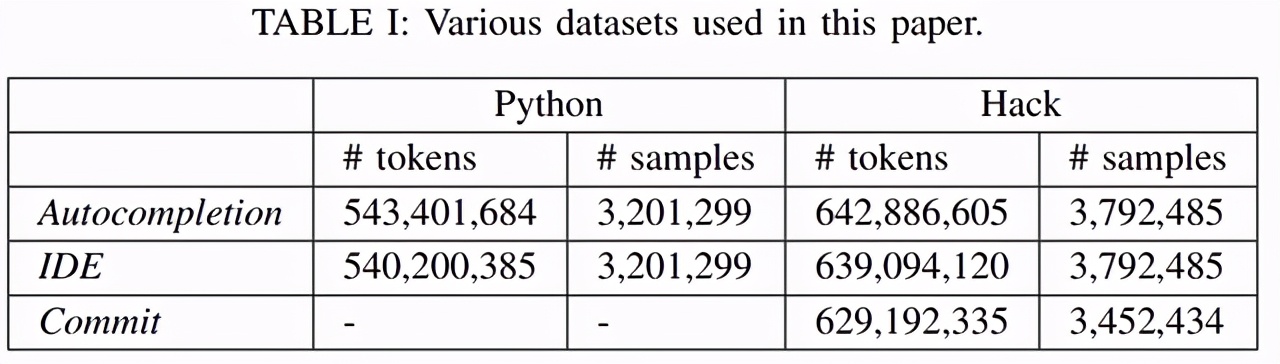
該研究的數據集(如下表 1 所示)來源于 Facebook 的真實開發者活動。研究者專注于兩種開發語言 Hack 和 Python,這兩種語言在 Facebook 擁有大量的開發者群體。
在本文中,研究者使用兩種模型(都結合了 Transformer 架構)評估遷移學習的效果。由于本文的重點是研究遷移學習的影響,因此實驗將重點集中在了這兩種模型上,并且沒有與其他 SOTA 模型進行比較。實驗用到的模型包括:
- GPT-2:一種解碼器 transformer 模型,由于 transformer 具有同時觀察所有序列元素及其自注意力塊的能力,因此在代碼預測中達到了 SOTA 性能;
- PLBART:一種雙向模型,該模型利用編碼器對代碼完成點周圍的上下文進行編碼,并使用類似 GPT-2 的解碼器進行自動回歸生成。
每個軟件語言模型分兩個階段進行訓練,分別是預訓練階段和微調階段。所有模型都使用 Nvidia Tesla V100 GPU、20 epoch 進行訓練(在融合時提前終止)。預訓練以及微調前學習率分別設置為 5^−4 和 5^−6。
研究者通過離線和在線的方式評估模型性能。
離線評估:研究者使用 10% 的 HackAutocompletion、PythonAutocompletion 作為測試數據集。HackAutocompletion 示例平均有 99.5 條候選建議可供選擇,pythonautomplection 示例平均有 26.3 條。候選建議列表允許將評估作為一個排名問題。對于每個離線測量,研究者報告 top-1 和 top-3 的準確率以及 k=3 的平均倒數排名(MRR@)。MRR 定義為:
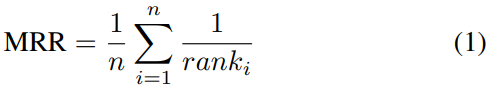
在線評估:該研究旨在提高開發者 IDE 體驗。雖然離線評估速度更快、成本更低,但必須使用真實用戶測試改進。在線評估中,對來自 Facebook 的數千名 Hack 開發者進行了多次實時 A/B 實驗。在每個實驗中,開發者被隨機分配到一個實驗組或控制組,測量每個用戶的每日完成量(DCPU)。使用這個指標,A/B 測試觀察值是指其中一個組(實驗組或控制組)中給定開發者在給定日期使用自動補全的次數。研究人員對每個組進行實驗,直到達到至少 95% 的統計數據。
實驗結果
離線評估:在標記數據上進行微調的自動補全模型在離線和在線評估中的性能優于沒有特定任務微調的模型。在離線評估中,下表 III 顯示微調使得 top-1 的準確率從 39.73% 提高到 41.91%。將標記樣本加入預訓練(HackAll)后,top1 的準確率從 40.25% 上升到 41.6%。在訓練 Python 自動補全模型時也觀察到了同樣的趨勢(表 IV)。
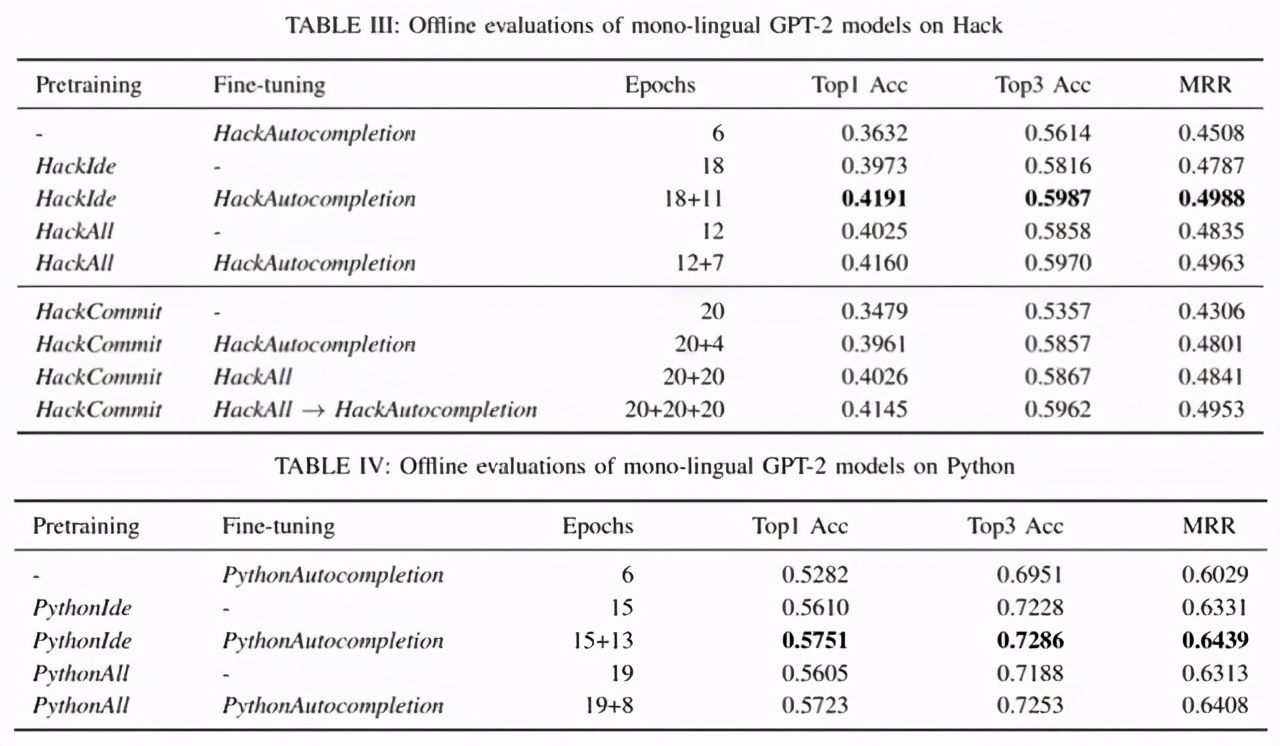
在線評估:在 HackIde 上訓練了一個自動補全模型。實驗變量在 HackAutocompletion 上進行微調,而控制變量沒有進行微調。下表 II 中的實驗 1 表明,在 p=0.0238 時,實驗組的每位用戶每日完成量(daily completions per user, DCPU)增加了 3.86%。
研究者進行了第二個 A/B 實驗,比較了前一個實驗(HackIde 的預訓練和 HackAutocompletion 的微調)中更好的模型和沒有預訓練的 HackAutocompletion 訓練模型。實驗 2 顯示沒有進行預訓練模型的巨大改進,實驗組的 DCPU 在 p=0.017 時,增加了 6.63%。
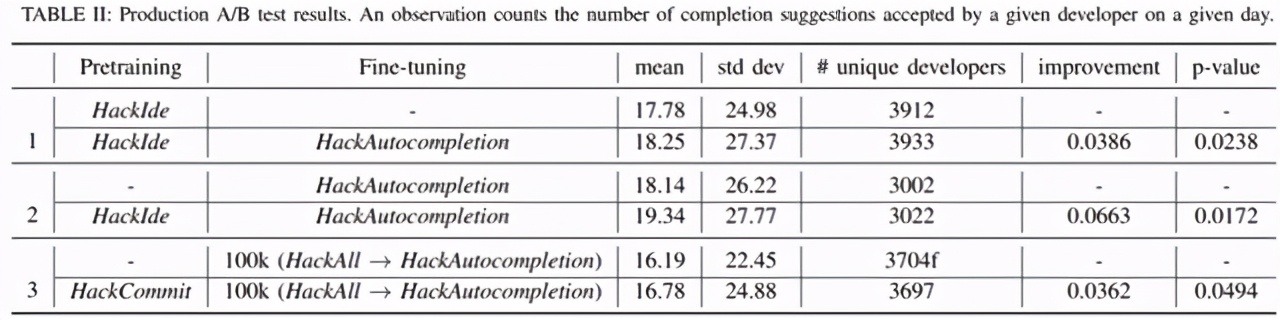
在線評估:研究者進行了 A / B 實驗,以探討預訓練對代碼提交的現實影響。上表 II 中的實驗 3 表明,在 p = 0.049 時,預訓練模型可提高 3.62%的 DCPU。
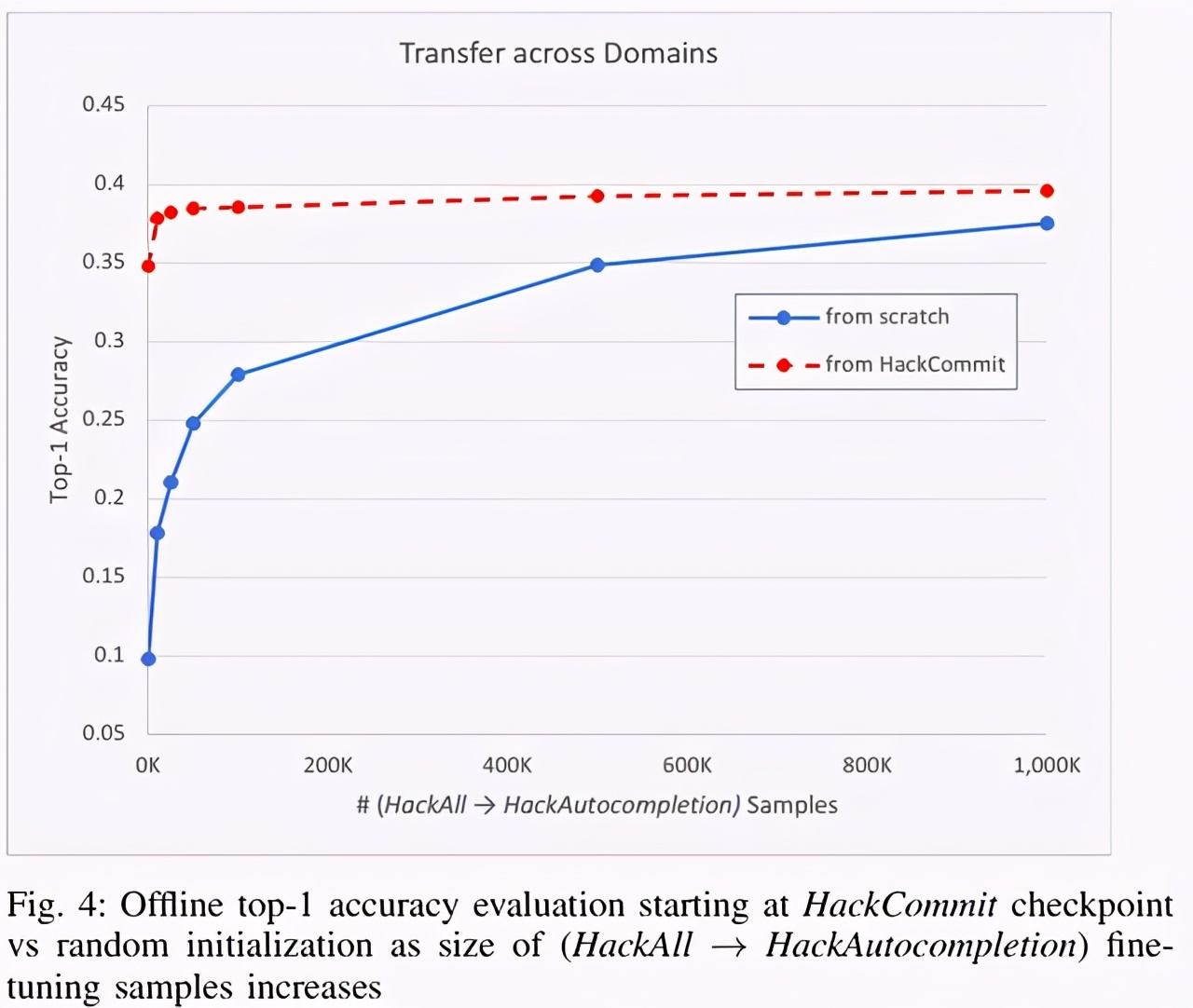
下圖 4 顯示了在 HackAll 上預訓練模型具有更好的性能,這與在微調中使用的 PythonAll 示例的數量無關。當將模型限制為僅 10k (top1 準確率 13.1%,37.11% vs. 24.01%)和 25k (top1 準確率 12.6%,41.26% vs. 28.66%)時,邊際影響最大。
這表明在自動補全中跨編程語言的知識遷移的明顯證據。在 HackAll 上預訓練并使用 25k 和 50k PythonAll 示例進行微調的模型的性能與使用 50k 和 100k PythonAll 示例從頭訓練的性能相似。這表明,在使用其他語言的數據集進行預訓練后,所需的樣本數量只有原來的一半。
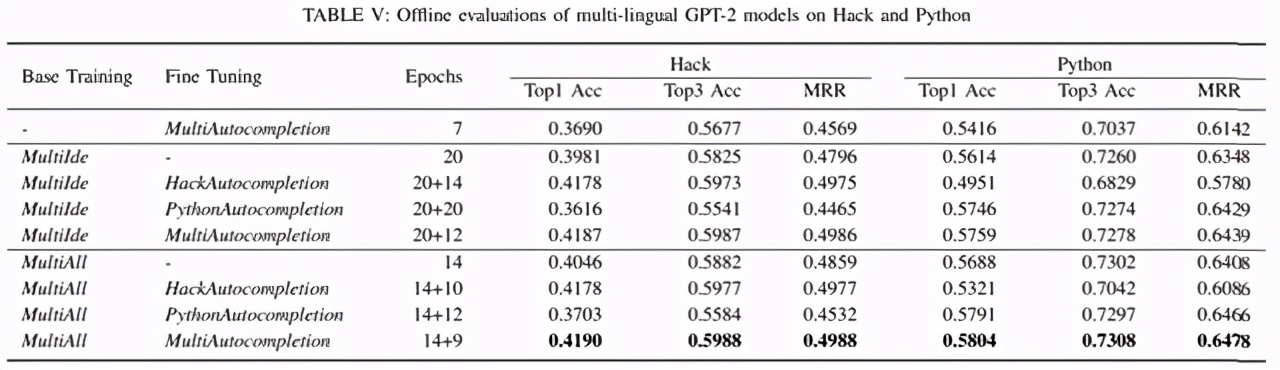
下表 V 展示了對 HackAutocompletion 、PythonAutocompletion 微調后,性能分別提高了 0.5%、1.34%。然而,與最好的單一語言模型相比,多語言模型沒有表現出這種顯著改進。最優的多語言模型的 top-1 準確率比最優的 Python 模型高 0.53%,但比最優的 Hack 模型低 0.02%。結合其他研究結果并假設,隨著每種語言中可用示例數量的增加,跨語言組合編程語言示例的邊際效益(marginal benefit)遞減。
上表 III 顯示,使用 HackAutocompletion 微調進行的 HackCommit 預訓練的性能優于 HackAutocompletion,提高 3.29%top-1 準確率(39.61%VS36.32%)。PLBART 的 top-1 準確率提高幅度更大(表 VI):6.52%(51.06%VS44.54%)。