













Python騷操作,讓圖片人物動起來!
引言:近段時間,一個讓夢娜麗莎圖像動起來的項目火遍了朋友圈。而今天我們就將實現讓圖片中的人物隨著視頻人物一起產生動作。
其中通過在靜止圖像中動畫對象產生視頻有無數的應用跨越的領域興趣,包括電影制作、攝影和電子商務。更準確地說,是圖像動畫指將提取的視頻外觀結合起來自動合成視頻的任務一種源圖像與運動模式派生的視頻。
近年來,深度生成模型作為一種有效的圖像動畫技術出現了視頻重定向。特別是,可生成的對抗網絡(GANS)和變分自動編碼器(VAES)已被用于在視頻中人類受試者之間轉換面部表情或運動模式。

根據論文FirstOrder Motion Model for Image Animation可知,在姿態遷移的大任務當中,Monkey-Net首先嘗試了通過自監督范式預測關鍵點來表征姿態信息,測試階段估計驅動視頻的姿態關鍵點完成遷移工作。在此基礎上,FOMM使用了相鄰關鍵點的局部仿射變換來模擬物體運動,還額外考慮了遮擋的部分,遮擋的部分可以使用image inpainting生成。
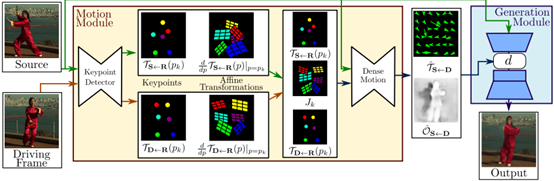
而今天我們就將借助論文所分享的源代碼,構建模型創建自己需要的人物運動。具體流程如下。
實驗前的準備
首先我們使用的python版本是3.6.5所用到的模塊如下:
- imageio模塊用來控制圖像的輸入輸出等。
- Matplotlib模塊用來繪圖。
- numpy模塊用來處理矩陣運算。
- Pillow庫用來加載數據處理。
- pytorch模塊用來創建模型和模型訓練等。
- 完整模塊需求參見requirements.txt文件。
模型的加載和調用
通過定義命令行參數來達到加載模型,圖片等目的。
(1)首先是訓練模型的讀取,包括模型加載方式:
- def load_checkpoints(config_path, checkpoint_path, cpu=False):
- with open(config_path) as f:
- config = yaml.load(f)
- generator = OcclusionAwareGenerator(**config[ model_params ][ generator_params ],
- **config[ model_params ][ common_params ])
- if not cpu:
- generator.cuda()
- kp_detector = KPDetector(**config[ model_params ][ kp_detector_params ],
- **config[ model_params ][ common_params ])
- if not cpu:
- kp_detector.cuda()
- if cpu:
- checkpoint = torch.load(checkpoint_path, map_location=torch.device( cpu ))
- else:
- checkpoint = torch.load(checkpoint_path)
- generator.load_state_dict(checkpoint[ generator ])
- kp_detector.load_state_dict(checkpoint[ kp_detector ])
- if not cpu:
- generator = DataParallelWithCallback(generator)
- kp_detector = DataParallelWithCallback(kp_detector)
- generator.eval()
- kp_detector.eval()
- return generator, kp_detector
(2)然后是利用模型創建產生的虛擬圖像,找到最佳的臉部特征:
- def make_animation(source_image, driving_video, generator, kp_detector, relative=True, adapt_movement_scale=True, cpu=False):
- with torch.no_grad():
- predictions = []
- source = torch.tensor(source_image[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)
- if not cpu:
- sourcesource = source.cuda()
- driving = torch.tensor(np.array(driving_video)[np.newaxis].astype(np.float32)).permute(0, 4, 1, 2, 3)
- kp_source = kp_detector(source)
- kp_driving_initial = kp_detector(driving[:, :, 0])
- for frame_idx in tqdm(range(driving.shape[2])):
- drivingdriving_frame = driving[:, :, frame_idx]
- if not cpu:
- driving_framedriving_frame = driving_frame.cuda()
- kp_driving = kp_detector(driving_frame)
- kp_norm = normalize_kp(kp_sourcekp_source=kp_source, kp_drivingkp_driving=kp_driving,
- kp_driving_initialkp_driving_initial=kp_driving_initial, use_relative_movement=relative,
- use_relative_jacobian=relative, adapt_movement_scaleadapt_movement_scale=adapt_movement_scale)
- out = generator(source, kp_sourcekp_source=kp_source, kp_driving=kp_norm) predictions.append(np.transpose(out[ prediction ].data.cpu().numpy(), [0, 2, 3, 1])[0])
- return predictions
- def find_best_frame(source, driving, cpu=False):
- import face_alignment
- def normalize_kp(kp):
- kpkp = kp - kp.mean(axis=0, keepdims=True)
- area = ConvexHull(kp[:, :2]).volume
- area = np.sqrt(area)
- kp[:, :2] = kp[:, :2] / area
- return kp
- fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=True,
- device= cpu if cpu else cuda )
- kp_source = fa.get_landmarks(255 * source)[0]
- kp_source = normalize_kp(kp_source)
- norm = float( inf )
- frame_num = 0
- for i, image in tqdm(enumerate(driving)):
- kp_driving = fa.get_landmarks(255 * image)[0]
- kp_driving = normalize_kp(kp_driving)
- new_norm = (np.abs(kp_source - kp_driving) ** 2).sum()
- if new_norm < norm:
- norm = new_norm
- frame_num = i
- return frame_num
(3) 接著定義命令行調用參數加載圖片、視頻等方式:
- parser = ArgumentParser()
- parser.add_argument("--config", required=True, help="path to config")
- parser.add_argument("--checkpoint", default= vox-cpk.pth.tar , help="path to checkpoint to restore")
- parser.add_argument("--source_image", default= sup-mat/source.png , help="path to source image")
- parser.add_argument("--driving_video", default= sup-mat/source.png , help="path to driving video")
- parser.add_argument("--result_video", default= result.mp4 , help="path to output")
- parser.add_argument("--relative", dest="relative", action="store_true", help="use relative or absolute keypoint coordinates")
- parser.add_argument("--adapt_scale", dest="adapt_scale", action="store_true", help="adapt movement scale based on convex hull of keypoints")
- parser.add_argument("--find_best_frame", dest="find_best_frame", action="store_true",
- help="Generate from the frame that is the most alligned with source. (Only for faces, requires face_aligment lib)")
- parser.add_argument("--best_frame", dest="best_frame", type=int, default=None,
- help="Set frame to start from.")
- parser.add_argument("--cpu", dest="cpu", action="store_true", help="cpu mode.")
- parser.set_defaults(relative=False)
- parser.set_defaults(adapt_scale=False)
- opt = parser.parse_args()
- source_image = imageio.imread(opt.source_image)
- reader = imageio.get_reader(opt.driving_video)
- fps = reader.get_meta_data()[ fps ]
- driving_video = []
- try:
- for im in reader:
- driving_video.append(im)
- except RuntimeError:
- pass
- reader.close()
- source_image = resize(source_image, (256, 256))[..., :3]
- driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video]
- generator, kp_detector = load_checkpoints(config_path=opt.config, checkpoint_path=opt.checkpoint, cpu=opt.cpu)
- if opt.find_best_frame or opt.best_frame is not None:
- i = opt.best_frame if opt.best_frame is not None else find_best_frame(source_image, driving_video, cpu=opt.cpu)
- print ("Best frame: " + str(i))
- driving_forward = driving_video[i:]
- driving_backward = driving_video[:(i+1)][::-1]
- predictions_forward = make_animation(source_image, driving_forward, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
- predictions_backward = make_animation(source_image, driving_backward, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
- predictions = predictions_backward[::-1] + predictions_forward[1:]
- else:
- predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
- imageio.mimsave(opt.result_video, [img_as_ubyte(frame) for frame in predictions], fpsfps=fps)
模型的搭建
整個模型訓練過程是圖像重建的過程,輸入是源圖像和驅動圖像,輸出是保留源圖像物體信息的含有驅動圖像姿態的新圖像,其中輸入的兩張圖像來源于同一個視頻,即同一個物體信息,那么整個訓練過程就是驅動圖像的重建過程。大體上來說分成兩個模塊,一個是motion estimation module,另一個是imagegeneration module。
(1)其中通過定義VGG19模型建立網絡層作為perceptual損失。
其中手動輸入數據進行預測需要設置更多的GUI按鈕,其中代碼如下:
- class Vgg19(torch.nn.Module):
- """
- Vgg19 network for perceptual loss. See Sec 3.3.
- """
- def __init__(self, requires_grad=False):
- super(Vgg19, self).__init__()
- vgg_pretrained_features = models.vgg19(pretrained=True).features
- self.slice1 = torch.nn.Sequential()
- self.slice2 = torch.nn.Sequential()
- self.slice3 = torch.nn.Sequential()
- self.slice4 = torch.nn.Sequential()
- self.slice5 = torch.nn.Sequential()
- for x in range(2):
- self.slice1.add_module(str(x), vgg_pretrained_features[x])
- for x in range(2, 7):
- self.slice2.add_module(str(x), vgg_pretrained_features[x])
- for x in range(7, 12):
- self.slice3.add_module(str(x), vgg_pretrained_features[x])
- for x in range(12, 21):
- self.slice4.add_module(str(x), vgg_pretrained_features[x])
- for x in range(21, 30):
- self.slice5.add_module(str(x), vgg_pretrained_features[x])
- self.mean = torch.nn.Parameter(data=torch.Tensor(np.array([0.485, 0.456, 0.406]).reshape((1, 3, 1, 1))),
- requires_grad=False)
- self.std = torch.nn.Parameter(data=torch.Tensor(np.array([0.229, 0.224, 0.225]).reshape((1, 3, 1, 1))),
- requires_grad=False)
- if not requires_grad:
- for param in self.parameters():
- param.requires_grad = False
- def forward(self, X):
- X = (X - self.mean) / self.std
- h_relu1 = self.slice1(X)
- h_relu2 = self.slice2(h_relu1)
- h_relu3 = self.slice3(h_relu2)
- h_relu4 = self.slice4(h_relu3)
- h_relu5 = self.slice5(h_relu4)
- out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
- return out
(2)創建圖像金字塔計算金字塔感知損失:
- class ImagePyramide(torch.nn.Module):
- """
- Create image pyramide for computing pyramide perceptual loss. See Sec 3.3
- """
- def __init__(self, scales, num_channels):
- super(ImagePyramide, self).__init__()
- downs = {}
- for scale in scales:
- downs[str(scale).replace( . , - )] = AntiAliasInterpolation2d(num_channels, scale)
- self.downs = nn.ModuleDict(downs)
- def forward(self, x):
- out_dict = {}
- for scale, down_module in self.downs.items():
- out_dict[ prediction_ + str(scale).replace( - , . )] = down_module(x)
- return out_dict
(3)等方差約束的隨機tps變換
- class Transform:
- """
- Random tps transformation for equivariance constraints. See Sec 3.3
- """
- def __init__(self, bs, **kwargs):
- noise = torch.normal(mean=0, std=kwargs[ sigma_affine ] * torch.ones([bs, 2, 3]))
- self.theta = noise + torch.eye(2, 3).view(1, 2, 3)
- self.bs = bs
- if ( sigma_tps in kwargs) and ( points_tps in kwargs):
- self.tps = True
- self.control_points = make_coordinate_grid((kwargs[ points_tps ], kwargs[ points_tps ]), type=noise.type())
- selfself.control_points = self.control_points.unsqueeze(0)
- self.control_params = torch.normal(mean=0,
- std=kwargs[ sigma_tps ] * torch.ones([bs, 1, kwargs[ points_tps ] ** 2]))
- else:
- self.tps = False
- def transform_frame(self, frame):
- grid = make_coordinate_grid(frame.shape[2:], type=frame.type()).unsqueeze(0)
- gridgrid = grid.view(1, frame.shape[2] * frame.shape[3], 2)
- grid = self.warp_coordinates(grid).view(self.bs, frame.shape[2], frame.shape[3], 2)
- return F.grid_sample(frame, grid, padding_mode="reflection")
- def warp_coordinates(self, coordinates):
- theta = self.theta.type(coordinates.type())
- thetatheta = theta.unsqueeze(1)
- transformed = torch.matmul(theta[:, :, :, :2], coordinates.unsqueeze(-1)) + theta[:, :, :, 2:]
- transformedtransformed = transformed.squeeze(-1)
- if self.tps:
- control_points = self.control_points.type(coordinates.type())
- control_params = self.control_params.type(coordinates.type())
- distances = coordinates.view(coordinates.shape[0], -1, 1, 2) - control_points.view(1, 1, -1, 2)
- distances = torch.abs(distances).sum(-1)
- result = distances ** 2
- resultresult = result * torch.log(distances + 1e-6)
- resultresult = result * control_params
- resultresult = result.sum(dim=2).view(self.bs, coordinates.shape[1], 1)
- transformedtransformed = transformed + result
- return transformed
- def jacobian(self, coordinates):
- new_coordinates = self.warp_coordinates(coordinates)
- gradgrad_x = grad(new_coordinates[..., 0].sum(), coordinates, create_graph=True)
- gradgrad_y = grad(new_coordinates[..., 1].sum(), coordinates, create_graph=True)
- jacobian = torch.cat([grad_x[0].unsqueeze(-2), grad_y[0].unsqueeze(-2)], dim=-2)
- return jacobian

(4)生成器的定義:生成器,給定的源圖像和和關鍵點嘗試轉換圖像根據運動軌跡引起要點。部分代碼如下:
- class OcclusionAwareGenerator(nn.Module):
- def __init__(self, num_channels, num_kp, block_expansion, max_features, num_down_blocks,
- num_bottleneck_blocks, estimate_occlusion_map=False, dense_motion_params=None, estimate_jacobian=False):
- super(OcclusionAwareGenerator, self).__init__()
- if dense_motion_params is not None:
- self.dense_motion_network = DenseMotionNetwork(num_kpnum_kp=num_kp, num_channelsnum_channels=num_channels,
- estimate_occlusion_mapestimate_occlusion_map=estimate_occlusion_map,
- **dense_motion_params)
- else:
- self.dense_motion_network = None
- self.first = SameBlock2d(num_channels, block_expansion, kernel_size=(7, 7), padding=(3, 3))
- down_blocks = []
- for i in range(num_down_blocks):
- in_features = min(max_features, block_expansion * (2 ** i))
- out_features = min(max_features, block_expansion * (2 ** (i + 1)))
- down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.down_blocks = nn.ModuleList(down_blocks)
- up_blocks = []
- for i in range(num_down_blocks):
- in_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i)))
- out_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i - 1)))
- up_blocks.append(UpBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.up_blocks = nn.ModuleList(up_blocks)
- self.bottleneck = torch.nn.Sequential()
- in_features = min(max_features, block_expansion * (2 ** num_down_blocks))
- for i in range(num_bottleneck_blocks):
- self.bottleneck.add_module( r + str(i), ResBlock2d(in_features, kernel_size=(3, 3), padding=(1, 1)))
- self.final = nn.Conv2d(block_expansion, num_channels, kernel_size=(7, 7), padding=(3, 3))
- self.estimate_occlusion_map = estimate_occlusion_map
- self.num_channels = num_channels
(5)判別器類似于Pix2PixGenerator。
- def __init__(self, num_channels=3, block_expansion=64, num_blocks=4, max_features=512,
- sn=False, use_kp=False, num_kp=10, kp_variance=0.01, **kwargs):
- super(Discriminator, self).__init__()
- down_blocks = []
- for i in range(num_blocks):
- down_blocks.append(
- DownBlock2d(num_channels + num_kp * use_kp if i == 0 else min(max_features, block_expansion * (2 ** i)),
- min(max_features, block_expansion * (2 ** (i + 1))),
- norm=(i != 0), kernel_size=4, pool=(i != num_blocks - 1), snsn=sn))
- self.down_blocks = nn.ModuleList(down_blocks)
- self.conv = nn.Conv2d(self.down_blocks[-1].conv.out_channels, out_channels=1, kernel_size=1)
- if sn:
- self.conv = nn.utils.spectral_norm(self.conv)
- self.use_kp = use_kp
- self.kp_variance = kp_variance
- def forward(self, x, kp=None):
- feature_maps = []
- out = x
- if self.use_kp:
- heatmap = kp2gaussian(kp, x.shape[2:], self.kp_variance)
- out = torch.cat([out, heatmap], dim=1)
- for down_block in self.down_blocks:
- feature_maps.append(down_block(out))
- out = feature_maps[-1]
- prediction_map = self.conv(out)
- return feature_maps, prediction_map
最終通過以下代碼調用模型訓練“python demo.py--config config/vox-adv-256.yaml --driving_video path/to/driving/1.mp4--source_image path/to/source/7.jpg --checkpointpath/to/checkpoint/vox-adv-cpk.pth.tar --relative --adapt_scale”
效果如下:
















