深2.5至4倍,參數(shù)和計(jì)算量更少,DeLighT怎么做到的?
深度學(xué)習(xí)的參數(shù)太多、模型太大、部署不方便、消耗的計(jì)算資源過(guò)多,種種原因加大了深度學(xué)習(xí)愛(ài)好者的「貧富差距」。然而算法優(yōu)化一直在路上……
Google 團(tuán)隊(duì)提出的 NLP 經(jīng)典之作 Transformer 由 Ashish Vaswani 等人在 2017 年發(fā)表的論文《Attention Is All You Need》 中提出。但由于模型參數(shù)量過(guò)大,該模型訓(xùn)練困難、部署不方便,研究人員一直在探究如何優(yōu)化 Transformer。近日,來(lái)自華盛頓大學(xué)和 FAIR 的 Sachin Mehta 等人提出了一個(gè)網(wǎng)絡(luò)結(jié)構(gòu)較深但輕量級(jí)的 Transformer——DeLighT。

論文鏈接:https://arxiv.org/abs/2008.00623
代碼鏈接:https://github.com/sacmehta/delight
論文簡(jiǎn)介
在這篇文章中,作者提出了一個(gè)網(wǎng)絡(luò)較深但輕量級(jí)的 Transformer——DeLighT,與之前基于 transformer 的模型相比,它的參數(shù)更少,但性能相當(dāng)甚至更好。
DeLighT 能夠更高效地分配參數(shù),主要表現(xiàn)在:1)每個(gè) Transformer 塊使用結(jié)構(gòu)較深但參數(shù)較少的 DExTra;2)在所有塊上使用逐塊縮放(block-wise scaling),使靠近輸入的 DeLighT 塊比較淺且窄,靠近輸出的 DeLighT 塊比較寬且深。總的來(lái)說(shuō),DeLighT 的網(wǎng)絡(luò)深度是標(biāo)準(zhǔn) transformer 模型的 2.5 到 4 倍,但參數(shù)量和計(jì)算量都更少。
DeLighT 的核心是 DExTra 變換(DExTra transformation),該變換使用組線性變換和擴(kuò)展 - 縮小(expand-reduce)策略來(lái)有效地改變 DeLighT 塊的寬度和深度。由于這些變換本質(zhì)上是局部的,因此 DExTra 利用特征 shuffling(類似于卷積網(wǎng)絡(luò)中的通道 shuffling)在不同組之間共享信息。這種寬且深的表示有助于用單頭注意力和輕量級(jí)前饋層替換 transformer 中的多頭注意力和前饋層,從而減少網(wǎng)絡(luò)參數(shù)量。重要的是,與 transformer 不同,DExTra 模塊可以獨(dú)立于輸入大小進(jìn)行縮放。通過(guò)使用靠近輸入的較淺和窄的 DeLighT 塊以及靠近輸出的較深和寬的 DeLighT 塊,在各個(gè)塊之間更高效地分配參數(shù)。
DeLighT 三大特點(diǎn)
改進(jìn) transformer:與之前的工作不同,該論文展示了對(duì)每個(gè) Transformer 塊使用 DExTra 以及基于所有塊使用逐塊縮放時(shí),能夠?qū)崿F(xiàn)參數(shù)的高效分配。結(jié)果顯示,DeLighT 在參數(shù)更少的情況下,能達(dá)到相同的效果甚至更好。
模型壓縮:為了進(jìn)一步提高序列模型的性能,該研究引入了逐塊縮放,允許每個(gè)塊有不同的尺寸,以及更高效地進(jìn)行參數(shù)分配。
改進(jìn)序列模型:與 DeLighT 最接近的工作是 DeFINE 單元,它使用擴(kuò)展 - 縮減策略學(xué)習(xí)模型表示。DeFINE 單元(圖 1a)和 DExTra(圖 1b)之間的關(guān)鍵區(qū)別是,DExTra 能更高效地在擴(kuò)展 - 縮減層中分配參數(shù)。DeFINE 在組線性變換中使用較少的組來(lái)學(xué)習(xí)更寬的表示,而 DExTra 使用較多的組和較少的參數(shù)來(lái)學(xué)習(xí)更寬的表示。
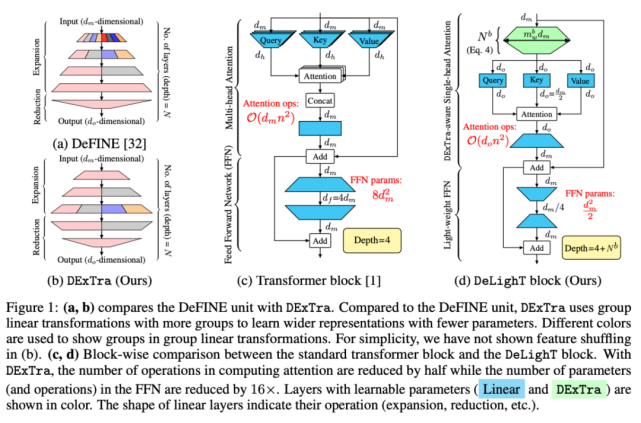
圖 1:(a, b) DeFINE 單元和 DExTra 之間的對(duì)比。(c, d) 標(biāo)準(zhǔn) transformer 模塊與 DeLighT 模塊中的 block-wise 對(duì)比。
DeLighT:網(wǎng)絡(luò)很深但參數(shù)較少的 Transformer
DExTra
DExTra 變換由五個(gè)配置參數(shù)控制:1)深度 N,2)寬度乘數(shù) m_w,3)輸入維數(shù) d_m,4)輸出維數(shù) d_o,5)組線性變換中的最大組 g_max。
在擴(kuò)展階段,DExTra 使用「N/2」層線性地將 d_m 維輸入投影到高維空間,d_max = m_wd_m。在縮減階段,DExTra 使用剩余的 N − 「N/2」層,將 d_max 維向量投影到 d_o 維空間。在數(shù)學(xué)上,每一層 l 的輸出 Y 可定義為:
每一層 l 的組數(shù)則按照以下公式計(jì)算:
DeLighT 模塊
Transformer 塊:標(biāo)準(zhǔn) transformer 塊(圖 1c)由多頭注意力組成,使用查詢 - 鍵 - 值(query-key-value)分解來(lái)建模序列 token 之間的關(guān)系,并使用前饋網(wǎng)絡(luò)(FFN)來(lái)學(xué)習(xí)更寬的表示。
DeLighT 塊:圖 1d 展示了如何將 DExTra 集成到 transformer 塊中以提高效率。首先將 d_m 維輸入饋入 DExTra 變換,產(chǎn)生 d_o 維輸出,其中 d_o < d_m。然后將這些 d_o 維輸出饋送至單頭注意力,緊接著使用輕量級(jí) FFN 來(lái)建模它們的關(guān)系。
DExTra 單頭注意力:假設(shè)輸入序列有 n 個(gè) token,每個(gè) token 的維數(shù)為 d_m。首先將這 n 個(gè) d_m 維輸入饋送到 DExTra 變換,以生成 n 個(gè) d_o 維輸出,其中 d_o
DeLighT 塊通過(guò) DExTra 學(xué)習(xí)到較寬的輸入表示,這就使得單頭注意力能夠代替多頭注意力。標(biāo)準(zhǔn) transformer 以及 DeLighT 塊中注意力的計(jì)算成本分別為 O(d_mn^2 )、O(d_on^2 ),d_o
輕量級(jí) FFN:與 transformer 中的 FFN 相似,該模塊也由兩個(gè)線性層組成。由于 DeLighT 塊已經(jīng)使用 DExTra 變換集成了較寬的表示,因此我們可以反轉(zhuǎn) transformer 中 FFN 層的功能。第一層將輸入的維數(shù)從 d_m 減小到 d_m / r,第二層將輸入維數(shù)從 d_m / r 擴(kuò)展到 d_m,其中 r 是減小因子(見(jiàn)圖 1d)。該研究提出的輕量級(jí) FFN 將 FFN 中的參數(shù)和計(jì)算量減少到原來(lái)的 rd_f / d_m。在標(biāo)準(zhǔn) transformer 中,F(xiàn)FN 維度擴(kuò)大了 3 倍。而在該研究實(shí)驗(yàn)中,維度縮小了 3 倍。因此,輕量級(jí) FFN 將 FFN 中的參數(shù)量減少到了原來(lái)的 1/16。
逐塊縮放
改善序列模型性能的標(biāo)準(zhǔn)方法包括增加模型維度(寬度縮放)、堆疊更多塊(深度縮放),或兩者兼具。為了創(chuàng)建非常深且寬的網(wǎng)絡(luò),該研究將模型縮放擴(kuò)展至塊級(jí)別。下圖 2 比較了均勻縮放與逐塊縮放:
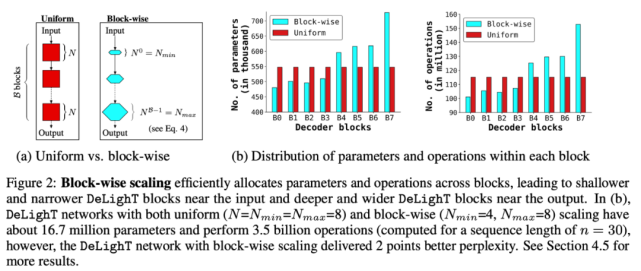
縮放 DeLighT 塊:DeLighT 塊使用 DExTra 學(xué)習(xí)深且寬的表示,DExTra 的深度和寬度由兩個(gè)配置參數(shù)控制:組變換層數(shù) N 和寬度乘數(shù) m_w(圖 2a)。這些配置參數(shù)能夠在獨(dú)立于輸入 d_m 和輸出 d_o 維度的情況下,增加 DeLighT 塊內(nèi)的可學(xué)習(xí)參數(shù)數(shù)量。此處,該論文使用逐塊縮放來(lái)創(chuàng)建具有可變大小的 DeLighT 塊網(wǎng)絡(luò),在輸入附近分配較淺且窄的 DeLighT 塊,在輸出附近分配更深且寬的 DeLighT 塊。
為此,該研究提出兩個(gè)配置參數(shù):DeLighT 網(wǎng)絡(luò)中 DExTra 的最小深度 N_min 和最大深度 N_max。然后,使用線性縮放(公式 4)計(jì)算每個(gè) DeLighT 塊 b 中 DExTra 的深度 N^b 和寬度乘數(shù) m^b_w。通過(guò)這種縮放,每個(gè) DeLighT 塊 b 都有不同的深度和寬度(圖 2a)。
實(shí)驗(yàn)結(jié)果
該論文在兩個(gè)常見(jiàn)的序列建模任務(wù)(機(jī)器翻譯和語(yǔ)言建模)上進(jìn)行了性能比較。
機(jī)器翻譯
該研究對(duì)比了 DeLighT 和當(dāng)前最優(yōu)方法(標(biāo)準(zhǔn) transformer [1]、動(dòng)態(tài)卷積 [21] 和 lite transformer [22])在機(jī)器翻譯語(yǔ)料庫(kù)上的性能,如下圖 3 所示。圖 3c 表明,DeLighT 提供了最優(yōu)的性能,在參數(shù)和計(jì)算量較少的情況下性能優(yōu)于其他模型。
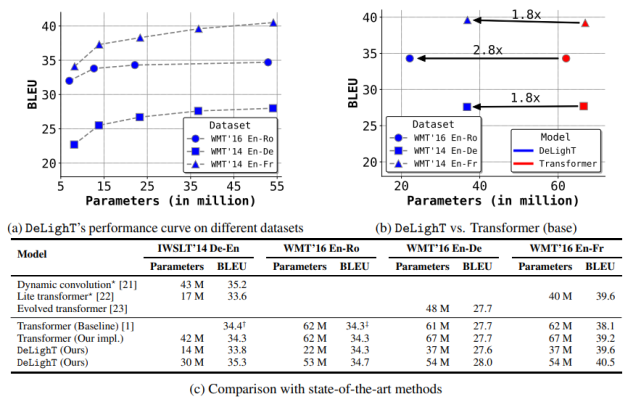
圖 3:模型在機(jī)器翻譯語(yǔ)料庫(kù)上的結(jié)果。與標(biāo)準(zhǔn) transformers 相比,DeLighT 模型用更少的參數(shù)就能達(dá)到類似的性能。圖中 † 和 ‡ 分別表示來(lái)自 [21] 和 [48] 的最優(yōu) transformer 基線。
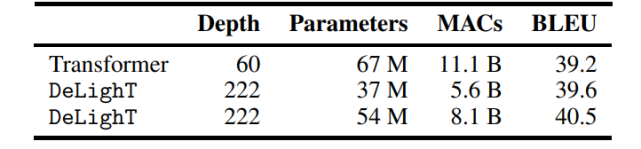
表 1:在 WMT’14 En-Fr 數(shù)據(jù)集上,機(jī)器翻譯模型在網(wǎng)絡(luò)深度、網(wǎng)絡(luò)參數(shù)、MAC 數(shù)量和 BLEU 值方面的對(duì)比結(jié)果。DeLighT 表現(xiàn)最優(yōu)異,在網(wǎng)絡(luò)深度較深的情況下,參數(shù)量和運(yùn)算量都更少。
語(yǔ)言建模
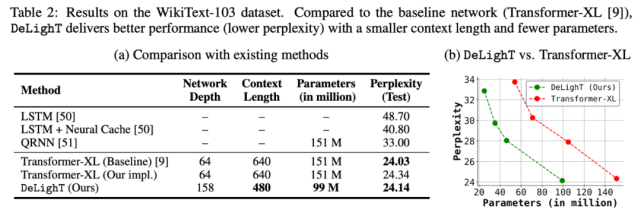
該研究在 WikiText-103 數(shù)據(jù)集上,對(duì) DeLighT 和其他方法的性能進(jìn)行了對(duì)比(如表 2a 所示)。表 2b 則繪制了 DeLighT 和 Transformer-XL [9] 的困惑度隨參數(shù)量的變化情況。這兩個(gè)表都表明,DeLighT 優(yōu)于當(dāng)前最優(yōu)的方法(包括 Transformer-XL),而且它使用更小的上下文長(zhǎng)度和更少的參數(shù)實(shí)現(xiàn)了這一點(diǎn),這表明使用 DeLighT 學(xué)得的更深且寬的表示有助于建模強(qiáng)大的上下文關(guān)系。
控制變量研究
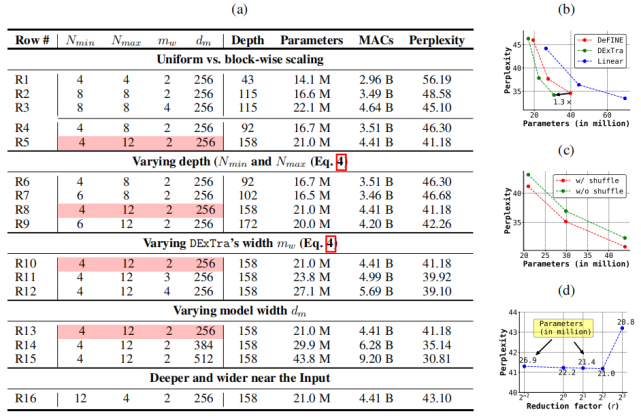
表 3a 研究了 DeLighT 塊參數(shù)的影響,這些參數(shù)分別是網(wǎng)絡(luò)最小深度 N_min、最大深度 N_max、寬度乘法 m_w 和模型維度 d_m(見(jiàn)圖 1d)。表 3b-d 分別展示了 DExTra 變換、特征 shuffling 和輕量級(jí) FFN 的影響。
總結(jié)
該研究提出了一種非常輕巧但深度較大的 transformer 框架——DeLighT,該框架可在 DeLighT 塊內(nèi)以及對(duì)所有 DeLighT 塊高效分配參數(shù)。與當(dāng)前最優(yōu)的 Transformer 模型相比,DeLighT 模型具備以下優(yōu)點(diǎn):1)非常深且輕量級(jí);2)提供相似或更好的性能。