在數據統計分析面前,R語言是“王者”,Python只能當“小弟”
我們從下圖可以看出 R 的 TIOBE 指數,在2018年1月達到峰值后,該語言開始出現顯著下降。然而,自3月份以來,指數明顯回升。
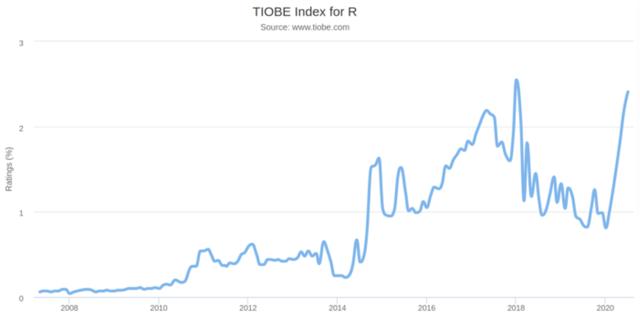
這是什么原因?
很明顯是因為新冠病毒在全球爆發,而引發了大家對統計數據的興趣。
因此,如果一個人想快速進行有效的統計分析,就應該尋求一個直觀的統計環境來計算數據。而 R 在數據的統計分析中占主導地位。
下面是我對 R 如何優于 Python 的經驗:
1.在分析時間序列數據時,R 可以優于 Python
如果你從事過時間序列分析,那么你可能很熟悉所謂的 ARIMA(自回歸綜合移動平均線)模型。
這是一個可以用來根據時間序列的結構進行預測的模型。ARIMA 模型由坐標(p、d、q)組成:
- p 代表自回歸項的數量,即用于預測未來值的過去時間值的觀察數。例如,如果 p 的值是2,那么這意味著序列中前兩次時間觀測值被用來預測未來的趨勢。
- d 表示使時間序列平穩所需的差異數(即具有恒定均值、方差和自相關的差分)。例如,如果d=1,則意味著必須獲得級數的第一個差分才能將其轉換為平穩差。
- q 代表模型中先前預測誤差的移動平均值,或誤差項的滯后值。例如,如果 q 的值為1,那么這意味著我們在模型中有一個誤差項的滯后值。
但是,R 和 Python 都允許基于最佳擬合自動選擇這些坐標。可以使用 R 中的 auto.arima 和Python中的 pyramid 來完成。金字塔中的 auto-arima 函數是在原有的 R 函數的基礎上發展起來的,即 R 是第一個能夠自動選擇 p、d、q 坐標的語言。
2.回歸分析
對于回歸分析,在某些情況下,與 Python 相比,R 可以使用更少的代碼行來運行分析。
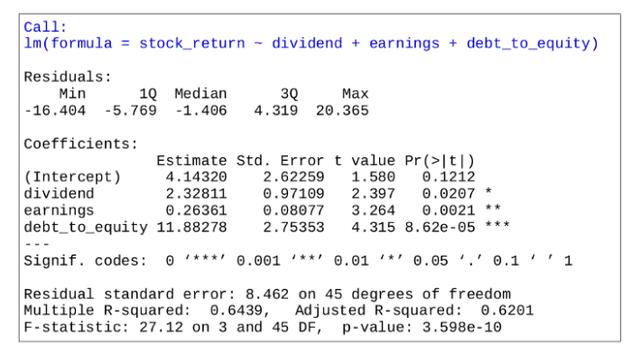
讓我們舉個例子。假設我們正在運行回歸以基于各種因素來預測股票收益,例如公司股息、收益和債轉股。
現在,假設我們希望測試多重共線性,即測試是否有任何自變量彼此顯著相關,從而導致結果的偏差。 回歸(reg1)運行如下:
現在,我們需要計算方差膨脹因子。 計算方法如下:
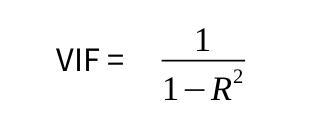
但是,我們不需要在 R 中手動計算該值。相反,可以使用 car 庫,按如下所示調用 VIF 函數:

VIF 統計數據處于常用閾值5和10之下,這表明模型中不存在多重共線性。
但是,使用 Python 的過程要復雜一些。
使用 sklearn 時,我們將分別獲得每個變量的 VIF。例如,讓我們試著找到股息變量的 VIF 值。

在上述示例中,必須首先手動計算 R 平方統計,然后僅計算一個變量的 VIF 統計:

我們已經得到了這個變量的 VIF,但是為了達到這個目的還需要采取更多的步驟。此外,要找到其他兩個變量的 VIF 值,必須對每個變量重復此過程。
從這個角度來看,R 仍然可以證明在快速生成統計信息時更直觀。
3.直觀的統計分析
Python中的 pyplot 和 seaborn 等庫在生成統計圖時已經變得非常流行。
但是,除了 shinny 的交互式可視化功能之外,R 的快速生成統計信息能力更加強大。
這是一個在 Shiny 中生成的累積二項式概率圖的示例,可以通過操縱左側的滑塊(單個概率)來計算某個事件在指定次數的試驗中發生的累積概率。
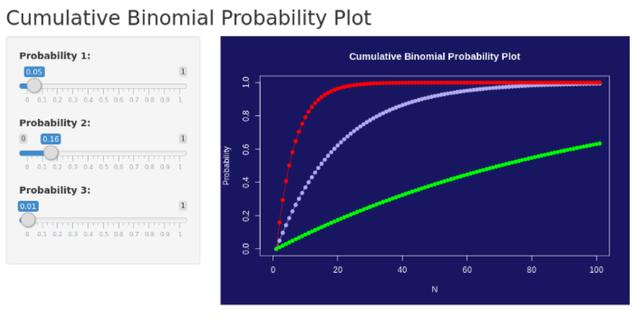
對于那些可能不擅長編寫代碼,但正在尋找一種有效的方式來操縱統計信息并快速產生洞察力的人來說,這種工具具有巨大的價值。 而且,Shiny 本身就是一個非常直觀的 R 語言庫,并不難學!
你可以直接在以下 GitHub 庫中使用Shiny Web App:
- https://github.com/MGCodesandStats/shiny-web-apps/tree/master/probability
要運行該應用程序,只需:
- 下載資料庫
- 單擊 Shiny Web App 文件夾,然后在 RStudio 中打開 ui.R 和 server.R 文件。
- 完成此操作后,只需選擇“運行應用程序”按鈕,上面的應用程序就會顯示:
總結
Python在機器學習方面表現出色,并且在通用編程方面將繼續主導R。
從技術上講,R 不是編程語言,而是一種統計環境。
但是,統計學作為一個領域將因為 R 語言而繼續存在。