機(jī)器學(xué)習(xí)從業(yè)者面臨的8大挑戰(zhàn)
許多人在趕上機(jī)器學(xué)習(xí)(ML)或人工智能(AI)時想象出機(jī)器人或終結(jié)者。 但是,它們并不是電影中沒有的東西,只是優(yōu)秀的夢想。 已經(jīng)在這里了 盡管ML從業(yè)人員在從零開發(fā)應(yīng)用程序到生產(chǎn)應(yīng)用程序的過程中可能會遇到某些挑戰(zhàn),但我們正處在使用機(jī)器學(xué)習(xí)開發(fā)大量優(yōu)秀應(yīng)用程序的情況下。
這些挑戰(zhàn)是什么? 讓我們來看看!
1.數(shù)據(jù)收集
在任何用例中,數(shù)據(jù)都起著關(guān)鍵作用。 數(shù)據(jù)科學(xué)家的60%的工作在于收集數(shù)據(jù)。 為了讓初學(xué)者嘗試機(jī)器學(xué)習(xí),他們可以輕松地從Kaggle,UCI ML Repository等中查找數(shù)據(jù)。
要實(shí)現(xiàn)實(shí)際案例,您需要通過網(wǎng)絡(luò)抓取或(通過Twitter等API)收集數(shù)據(jù),或者為解決業(yè)務(wù)問題而需要從客戶端獲取數(shù)據(jù)(此處ML工程師需要與領(lǐng)域?qū)<覅f(xié)作以收集數(shù)據(jù)) 。
收集完數(shù)據(jù)后,我們需要對數(shù)據(jù)進(jìn)行結(jié)構(gòu)化并將其存儲在數(shù)據(jù)庫中。 這需要了解大數(shù)據(jù)(或數(shù)據(jù)工程師)的知識,而大數(shù)據(jù)在這里起著主要作用。
2.訓(xùn)練數(shù)據(jù)量少
收集完數(shù)據(jù)后,您需要驗(yàn)證數(shù)量是否足以滿足用例的要求(如果是時間序列數(shù)據(jù),我們至少需要3-5年的數(shù)據(jù))。
在進(jìn)行機(jī)器學(xué)習(xí)項(xiàng)目時,我們要做的兩個重要事情是選擇一種學(xué)習(xí)算法,并使用一些獲取的數(shù)據(jù)來訓(xùn)練模型。 因此,作為人類,我們自然會犯錯,結(jié)果可能會出錯。 在這里,錯誤可能是選擇了錯誤的模型或選擇了錯誤的數(shù)據(jù)。 現(xiàn)在,我所說的不良數(shù)據(jù)是什么意思? 讓我們嘗試了解。
假設(shè)您的機(jī)器學(xué)習(xí)模型是嬰兒,您計(jì)劃教嬰兒區(qū)分貓和狗。 因此,我們首先指著貓說"這是一只CAT",然后對DOG做同樣的事情(可能多次重復(fù)此過程)。 現(xiàn)在,孩子將能夠通過識別形狀,顏色或任何其他特征來區(qū)分貓和狗。 就這樣,嬰兒變成了天才(與眾不同)!
以類似的方式,我們使用大量數(shù)據(jù)訓(xùn)練模型。 一個孩子可以用較少的樣本數(shù)來區(qū)分動物,但是機(jī)器學(xué)習(xí)模型甚至需要針對簡單問題的數(shù)千個例子。 對于諸如圖像分類和語音識別之類的復(fù)雜問題,可能需要數(shù)以百萬計(jì)的數(shù)據(jù)。
因此,一件事很清楚。 我們需要訓(xùn)練具有足夠數(shù)據(jù)的模型。
3.非代表性訓(xùn)練數(shù)據(jù)
培訓(xùn)數(shù)據(jù)應(yīng)代表新案例以更好地進(jìn)行概括,即,我們用于培訓(xùn)的數(shù)據(jù)應(yīng)涵蓋所有發(fā)生的和即將發(fā)生的案例。 通過使用非代表性訓(xùn)練集,訓(xùn)練后的模型不太可能做出準(zhǔn)確的預(yù)測。
開發(fā)用于在業(yè)務(wù)問題視圖中對一般情況進(jìn)行預(yù)測的系統(tǒng)被認(rèn)為是很好的機(jī)器學(xué)習(xí)模型。 即使數(shù)據(jù)模型從未見過的數(shù)據(jù),也將有助于模型表現(xiàn)良好。
如果訓(xùn)練樣本的數(shù)量少,則我們的采樣噪聲是不具代表性的數(shù)據(jù),如果用于訓(xùn)練的策略存在缺陷,那么無數(shù)的訓(xùn)練測試也會帶來采樣偏差。
1936年美國總統(tǒng)大選期間(蘭登對羅斯福),發(fā)生了一個調(diào)查抽樣偏見的流行案例,《文學(xué)文摘》進(jìn)行了一次非常大的民意調(diào)查,向大約1000萬人發(fā)送郵件,其中240萬人回答了這一問題,并預(yù)測蘭登 將以高度的信心獲得57%的選票。 羅斯福以62%的選票獲勝。
這里的問題在于抽樣方法,用于獲取進(jìn)行民意測驗(yàn)的電子郵件地址,《文學(xué)文摘》使用過的雜志訂閱,俱樂部會員名單等,這些錢一定會被富有的個人用來投票給共和黨人(因此, 落在)。 此外,由于只有25%的受訪者回答了無回應(yīng)的偏見。
為了做出準(zhǔn)確的預(yù)測而沒有任何漂移,訓(xùn)練數(shù)據(jù)集必須具有代表性。
4.數(shù)據(jù)質(zhì)量差
實(shí)際上,我們不會直接開始訓(xùn)練模型,分析數(shù)據(jù)是最重要的步驟。 但是我們收集的數(shù)據(jù)可能尚未準(zhǔn)備好進(jìn)行訓(xùn)練,例如某些樣本異常,而另一些樣本則具有異常值或缺失值。
在這些情況下,我們可以刪除異常值,或者使用中位數(shù)或均值(以填充高度)填充缺失的特征/值,或者簡單地刪除具有缺失值的屬性/實(shí)例,或者在有或沒有這些實(shí)例的情況下訓(xùn)練模型。
我們不希望我們的系統(tǒng)做出錯誤的預(yù)測,對吧? 因此,數(shù)據(jù)質(zhì)量對于獲得準(zhǔn)確的結(jié)果非常重要。 數(shù)據(jù)預(yù)處理需要通過過濾缺失值,提取和重新排列模型所需的內(nèi)容來完成。
5.不相關(guān)/不需要的特征
垃圾進(jìn)垃圾出
如果訓(xùn)練數(shù)據(jù)包含大量不相關(guān)的特征和足夠的相關(guān)特征,則機(jī)器學(xué)習(xí)系統(tǒng)將不會給出預(yù)期的結(jié)果。 機(jī)器學(xué)習(xí)項(xiàng)目成功所需的重要方面之一是選擇好的特征以訓(xùn)練模型,也稱為特征選擇。
假設(shè)我們正在一個項(xiàng)目中,根據(jù)我們收集的輸入特征(年齡,性別,體重,身高和位置(即他/她的居住地))來預(yù)測一個人需要運(yùn)動的小時數(shù)。
- 在這5特征中,位置值可能不會影響我們的輸出特征。 這是不相關(guān)的功能,我們知道沒有此功能可以得到更好的結(jié)果。
- 另外,我們可以將兩個特征結(jié)合起來以產(chǎn)生更有用的一個特征,即特征提取。 在我們的示例中,我們可以通過消除體重和身高來產(chǎn)生一個稱為BMI的功能。 我們也可以對數(shù)據(jù)集應(yīng)用轉(zhuǎn)換。
- 通過收集更多數(shù)據(jù)來創(chuàng)建新特征也有幫助。
6.過度擬合訓(xùn)練數(shù)據(jù)
假設(shè)您訪問了新城市的一家餐館。 您查看了菜單以訂購商品,發(fā)現(xiàn)費(fèi)用或賬單過高。 您可能會想說"城市中的所有餐館都太貴了,負(fù)擔(dān)不起"。 過度概括是我們經(jīng)常要做的事情,令人震驚的是,框架也可能陷入類似的陷阱,在AI中,我們稱之為過擬合。
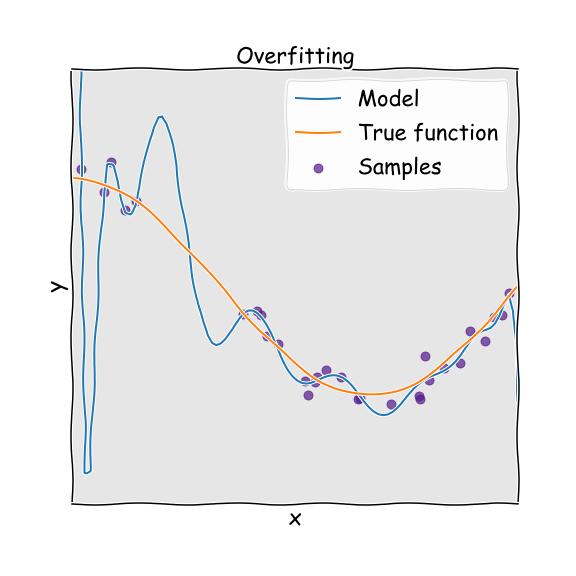
> Overfitting
這意味著該模型運(yùn)行良好,可以對訓(xùn)練數(shù)據(jù)集進(jìn)行預(yù)測,但不能很好地概括。
假設(shè)您正在嘗試實(shí)施"圖像分類"模型,分別對訓(xùn)練樣本分別為3000、500、500和500的蘋果,桃子,橘子和香蕉進(jìn)行分類。 如果我們使用這些樣本訓(xùn)練模型,則系統(tǒng)更可能將橘子分類為蘋果,因?yàn)樘O果的訓(xùn)練樣本數(shù)量過多。 這可以稱為過采樣。
當(dāng)模型與訓(xùn)練數(shù)據(jù)集的噪聲相比過于不可預(yù)測時,就會出現(xiàn)過度擬合。 我們可以通過以下方法避免這種情況:
- 收集更多的訓(xùn)練數(shù)據(jù)。
- 選擇具有較少特征的模型,與線性模型相比,較高階多項(xiàng)式模型不是優(yōu)選的。
- 修復(fù)數(shù)據(jù)錯誤,消除異常值,并減少訓(xùn)練集中的實(shí)例數(shù)量。
7.訓(xùn)練數(shù)據(jù)不足
當(dāng)模型過于簡單以至于無法理解數(shù)據(jù)的基本結(jié)構(gòu)時,通常會發(fā)生與過度擬合相反的欠擬合。 這就像試圖穿上小號褲子。 通常,當(dāng)我們?nèi)鄙儆糜跇?gòu)建精確模型的信息時,或者當(dāng)我們嘗試使用非線性信息來構(gòu)建或開發(fā)線性模型時,就會發(fā)生這種情況。
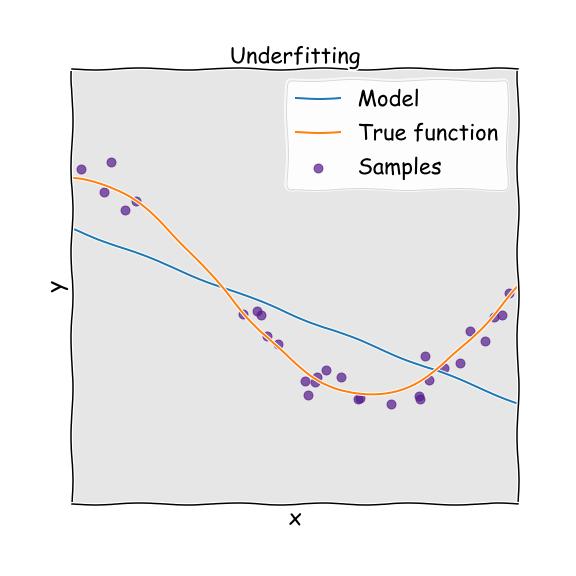
> Underfitting
減少欠擬合的主要選項(xiàng)是:
- 特征工程-為學(xué)習(xí)算法提供更好的特征。
- 消除數(shù)據(jù)中的噪音。
- 增加參數(shù)并選擇功能強(qiáng)大的模型。
8.離線學(xué)習(xí)和部署模型
機(jī)器學(xué)習(xí)工程在構(gòu)建應(yīng)用程序時遵循以下步驟:1)數(shù)據(jù)收集2)數(shù)據(jù)清理3)功能工程4)分析模式5)訓(xùn)練模型和優(yōu)化6)部署。
糟糕! 我說部署了嗎? 是的,許多機(jī)器學(xué)習(xí)從業(yè)者可以執(zhí)行所有步驟,但缺乏部署技能,由于缺乏實(shí)踐和依賴關(guān)系問題,對業(yè)務(wù)基礎(chǔ)模型的了解不足,將其出色的應(yīng)用程序投入生產(chǎn)已成為最大的挑戰(zhàn)之一, 了解業(yè)務(wù)問題,模型不穩(wěn)定。
通常,許多開發(fā)人員從像Kaggle這樣的網(wǎng)站收集數(shù)據(jù)并開始訓(xùn)練模型。 但實(shí)際上,我們需要為數(shù)據(jù)收集提供一個動態(tài)變化的源。 離線學(xué)習(xí)或批量學(xué)習(xí)不能用于這種類型的變量數(shù)據(jù)。 該系統(tǒng)經(jīng)過培訓(xùn),然后投入生產(chǎn),無需學(xué)習(xí)即可運(yùn)行。 由于動態(tài)變化,數(shù)據(jù)可能會漂移。
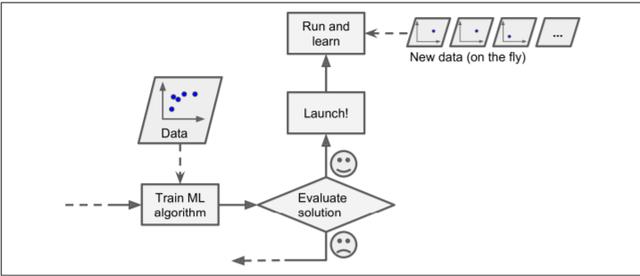
> Online Learning
始終首先建立一條管道來收集,分析,構(gòu)建/訓(xùn)練,測試和驗(yàn)證任何機(jī)器學(xué)習(xí)項(xiàng)目的數(shù)據(jù)集,并分批訓(xùn)練模型。
結(jié)論
如果訓(xùn)練集太小,或者數(shù)據(jù)沒有被泛化,嘈雜且具有不相關(guān)的功能,則系統(tǒng)將無法正常運(yùn)行。 在練習(xí)機(jī)器學(xué)習(xí)時,我們經(jīng)歷了初學(xué)者面臨的一些基本挑戰(zhàn)。
如果您有任何建議,我將很高興聽到。 我很快會再提出另一個有趣的話題。 到那時,待在家里,保持安全并繼續(xù)探索!