利用Python進行數據分析之初識Pandas
Pandas是構建在Python編程語言之上的一個快速、強大、靈活且易于使用的開源數據分析和操作工具。Pandas是基于Numpy的專業數據分析工具,可以靈活高效的處理各種數據集。
在Pandas中有這樣兩種數據結構:DataFrame、Series,DataFrame就類似Excel里面的Sheet表,而Series就相當于表中的某一列。
安裝
在這里我們使用pip進行安裝(如果沒有可自行查詢如何安裝pip)安裝panda最簡單的方法是將其作為Anaconda的一部分安裝,Anaconda主要用于數據分析和科學計算。還提供源代碼、PyPI、ActivePython、各種Linux發行版或開發版本進行安裝的說明。
當然,最為基礎的Python環境還是少不了的,如果你是Linux或使用的Mac就不用安裝Python了。
pip install pandas
Pandas中的數據結構
我們都知道在Excel中是有sheet表,在sheet中每個單元格都是有坐標來表示的,例如:A1、F3等,想要哪些數據只需要定位都響應數據都坐標或某個范圍。這里有一點需要強調,Pandas無論是和Exce相比還是和SQL相比,只是調用和處理數據的方式變了,核心都是對源數據進行一系列的處理。
DataFrame
在Pandas中同樣數據表表示方式與Excel基本相同,只不過Excel中的"列",在Pandas中叫做"Series":

Series
Pandas初體驗
如果想要構建下面這個表格,在Excel中大家再熟悉不過了,在Pandas中該如何構造呢?
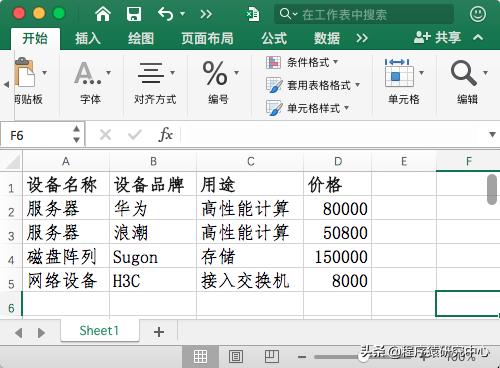
Excel表格
要想使用Pandas,首先我們需要導入模塊(這里使用的ipython,可通過pip install ipython安裝)。
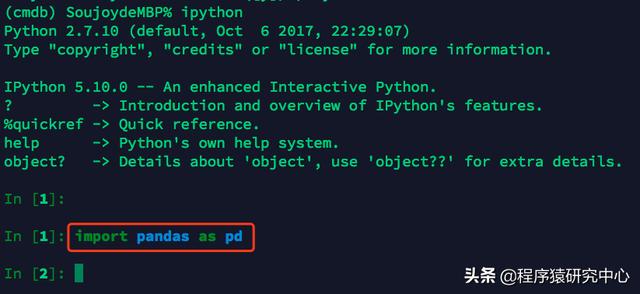
導入pandas
我們需要手動將數據存儲在表中,就要創建一個DataFrame。當使用Python列表和字典時,字典鍵將作為列頭,而每個列表中的值將用作DataFrame的行。
df = pd.DataFrame({ "設備名稱": ['服務器', '服務器', '磁盤陣列', '網絡設備'], "設備品牌": ['華為', '浪潮', 'Sugon', 'H3C'], "用途": ['高性能計算', '高性能計算', '存儲', '接入交換機'], "價格": [80000, 50800, 150000, 8000]})
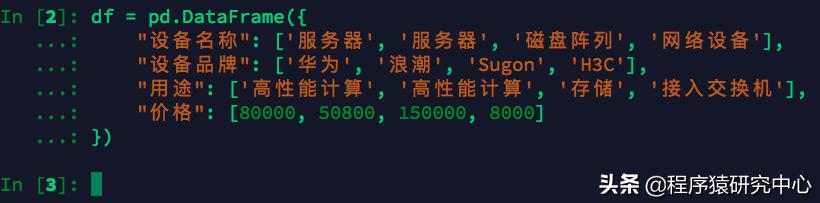
創建DataFrame
命令行直接輸入變量名稱"df"輸出DataFrame所有數據:

輸出DataFrame
注:第一眼看上去,感覺好亂,有木有!有童鞋說:我想把"設備品牌"放到最前面(在做表的時候,一般都是第一列作為表頭出現)。可不可以實現呢?當然可以!只需要在創建時指定"index"就可以了。
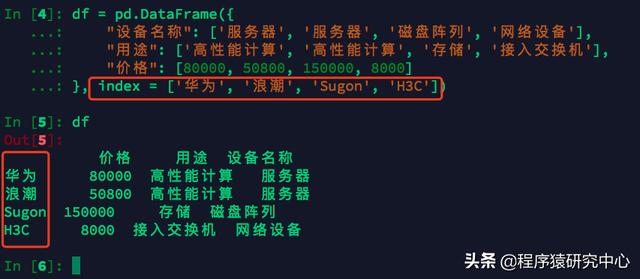
指定index后,輸出DataFrame
DataFrame是一種二維數據結構,可以在列中存儲不同類型的數據(包括字符、整數、浮點數等)。它類似于Excel表格、SQL數據庫表或R語言中的data.frame。
我只想要"設備名稱"那一列,怎么拿到呢?

獲取單個Series
注:當選擇DataFrame的單個列時,結果就是一個Series。我們想要選擇哪一列,就在方括號[]之間使用列標簽。
當然,我們也可以創建一個Series:
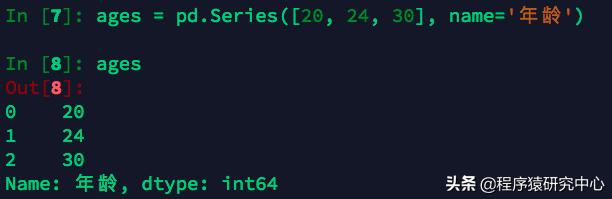
創建Series
在上面設備信息表中,我想拿到表中價格最貴的,該如何操作?這里就要用到max()方法。
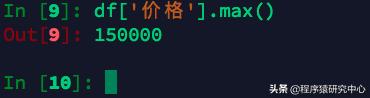
最大值
Pandas提供了很多功能,每個功能都有一個可以應用到DataFrame或Series的方法(很多方法,后面我們還會用到很多)。因為方法是函數,所以不要忘記使用括號()喲。
以上內容,簡單了解一下Pandas,Pandas功能十分強大,后面我們會由淺至深逐步了解Pandas的強大之處,如果對你有用,記得點贊+關注喲~