













容量是GPT-2的1.7倍!谷歌打造神經(jīng)對(duì)話模型Meena
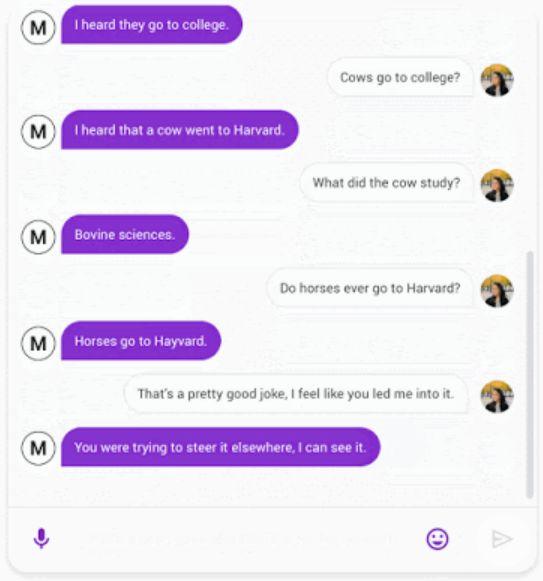
谷歌方面表示,這是“真正”對(duì)話式AI的一次嘗試。
Chatbots(對(duì)話式機(jī)器人)往往具有高度專業(yè)性,只要回答與用戶的期望相差不遠(yuǎn),它們的性能就值得肯定。為了更好地處理不同的對(duì)話主題,開放域?qū)υ捬芯?探索了一種新的方法,研究人員試圖開發(fā)一種非聊天專用機(jī)器人,雖然不以聊天為主要功能,但仍然可以滿足用戶的任何對(duì)話需求。
谷歌的研究人員認(rèn)為:開放域?qū)υ捬芯砍耸且粋€(gè)引人入勝的研究課題之外,這種對(duì)話機(jī)制還可以產(chǎn)生許多有趣的應(yīng)用程序,例如進(jìn)一步人性化的計(jì)算機(jī)交互、改進(jìn)外語(yǔ)練習(xí)以及制作可關(guān)聯(lián)的交互式電影和游戲角色。
但是,當(dāng)前的開放域聊天機(jī)器人有一個(gè)嚴(yán)重的缺陷:它們通常沒(méi)有實(shí)用意義,比如對(duì)同一個(gè)問(wèn)題的回答前后不一致,或者回答總是缺乏基本常識(shí)。此外,聊天機(jī)器人通常會(huì)給出并非特定于當(dāng)前上下文的響應(yīng),例如,“我不知道”可以是對(duì)任何問(wèn)題的回答,當(dāng)前的聊天機(jī)器人比人類更經(jīng)常這樣做,因?yàn)樗w了許多可能的用戶輸入。
近日,在一篇名為《Towards a Human-like Open-Domain Chatbot》的論文中,谷歌的研究人員介紹了一個(gè)名為“Meena”的模型,它是一個(gè)包含了 26 億參數(shù)的端到端訓(xùn)練型神經(jīng)對(duì)話模型。
在論文中,研究人員表示:他們已經(jīng)證明,與現(xiàn)有的最新聊天機(jī)器人相比,Meena 可以進(jìn)行更聰明、更具體的對(duì)話。他們針對(duì)開放域聊天機(jī)器人提出了一項(xiàng)新的人類評(píng)估指標(biāo),即 敏感度和特異性平均值(SSA),該指標(biāo)捕獲了人類對(duì)話的基本但重要的屬性。值得注意的是,研究人員證明了“困惑度”是一種易用于任何神經(jīng)對(duì)話模型的自動(dòng)指標(biāo),與 SSA 高度相關(guān)。
什么是“Meena”
Meena 是一種端到端的神經(jīng)對(duì)話模型,可以學(xué)會(huì)對(duì)給定的對(duì)話環(huán)境做出更加聰明的反應(yīng)。據(jù)介紹,Meena 模型具有 26 億個(gè)參數(shù),并經(jīng)過(guò) 341 GB 的文本訓(xùn)練,這些文本是從公共領(lǐng)域的社交媒體對(duì)話中過(guò)濾出來(lái)的,與現(xiàn)有的最新生成模型 OpenAI GPT-2 相比,Meena 具有 1.7 倍的模型容量,并且受過(guò) 8.5 倍的數(shù)據(jù)訓(xùn)練。
該模型訓(xùn)練的目標(biāo)是最大程度地減少“困惑度”,即預(yù)測(cè)下一個(gè)標(biāo)記(會(huì)話中的下一個(gè)單詞)的不確定性。它的核心是 Evolved Transformer seq2seq 體系結(jié)構(gòu),這是一種通過(guò)進(jìn)化神經(jīng)體系結(jié)構(gòu)搜索發(fā)現(xiàn)以改善困惑性的 Transformer 體系結(jié)構(gòu)。
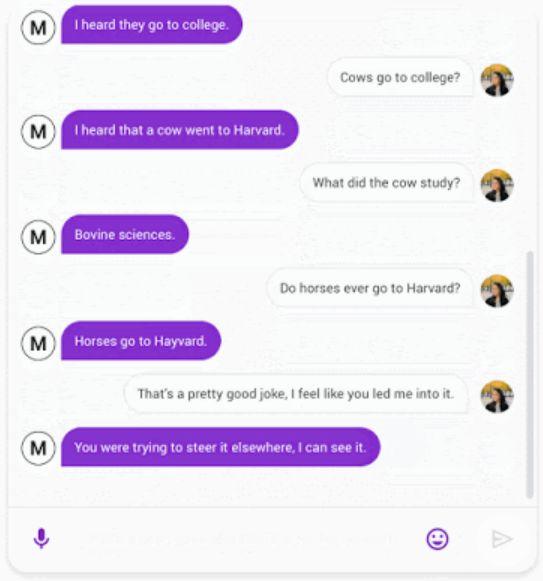
具體而言,Meena 具有單個(gè) Evolved Transformer 編碼器塊和 13 個(gè) Evolved Transformer 解碼器塊,如下所示。編碼器負(fù)責(zé)處理對(duì)話上下文,以幫助 Meena 理解對(duì)話中已經(jīng)說(shuō)過(guò)的內(nèi)容,然后,解碼器使用該信息來(lái)制定響應(yīng)。通過(guò)調(diào)整超參數(shù),研究人員發(fā)現(xiàn):功能更強(qiáng)大的解碼器是提高對(duì)話質(zhì)量的關(guān)鍵。
用于訓(xùn)練的對(duì)話被組織為樹線程,其中線程中的每個(gè)答復(fù)都被視為一個(gè)會(huì)話回合。研究人員提取了每個(gè)會(huì)話訓(xùn)練示例(包含七次上下文轉(zhuǎn)換)作為通過(guò)樹線程的一條路徑,研究人員表示,選擇七次作為一個(gè)良好的平衡,是因?yàn)榧纫凶銐蜷L(zhǎng)的上下文來(lái)訓(xùn)練會(huì)話模型,又要在內(nèi)存約束內(nèi)擬合模型(較長(zhǎng)的上下文會(huì)占用更多的內(nèi)存)。
敏感性和特異性平均值(SSA)
現(xiàn)有的關(guān)于聊天機(jī)器人質(zhì)量的人工評(píng)估指標(biāo)往往很復(fù)雜,并且未在審閱者之間達(dá)成一致。這促使谷歌的研發(fā)人員設(shè)計(jì)了一種新的人類評(píng)估指標(biāo),即敏感度和特異度平均值(SSA),它捕獲了自然對(duì)話的基本但重要的屬性。
為了計(jì)算 SSA,研究人員與參與測(cè)試的聊天機(jī)器人(Meena 和其他知名的開放域聊天機(jī)器人共同參與測(cè)試,包括 Mitsuku,Cleverbot,小冰和 DialoGPT)進(jìn)行了自由形式的對(duì)話眾包。
為了確保評(píng)估之間的一致性,每個(gè)對(duì)話都以相同的問(wèn)候語(yǔ)“ 嗨!”開始,人類評(píng)估員會(huì)在對(duì)話過(guò)程中重點(diǎn)關(guān)注兩個(gè)問(wèn)題:“回答是否有意義”以及“回答是否具體”,每輪對(duì)話都要求評(píng)估者使用常識(shí)來(lái)判斷機(jī)器人的響應(yīng)是否完全合理。如果出現(xiàn)任何問(wèn)題,比如混淆,不合邏輯,脫離上下文或有事實(shí)性錯(cuò)誤的,則應(yīng)將其評(píng)定為“沒(méi)有意義”;如果響應(yīng)是有意義的,則需要評(píng)估其回答以確定是否基于給定的上下文。
例如,如果 A 回答“ 我愛(ài)網(wǎng)球 ”,而 B 回答“ 很好 ”,那么這段對(duì)話應(yīng)標(biāo)記為“不具體”,因?yàn)檫@樣的答復(fù)可以在許多不同的上下文中使用;但是如果 B 回應(yīng):“我也是,我太喜歡羅杰·費(fèi)德勒了!”那么就可以將其標(biāo)記為“特定”,因?yàn)樗幕卮鹋c前文所討論的內(nèi)容密切相關(guān)。
對(duì)于每個(gè)聊天機(jī)器人,研究人員通過(guò)大約 100 個(gè)對(duì)話收集了 1600 至 2400 種個(gè)人對(duì)話,每個(gè)模型響應(yīng)都由評(píng)估人員標(biāo)記,以表明其回答是否合理和具體。聊天機(jī)器人的敏感度是標(biāo)記為“敏感”的響應(yīng)的一部分,而特異性是標(biāo)記為“特定”的響應(yīng)的一部分,這兩個(gè)數(shù)值的平均值是 SSA 分?jǐn)?shù)。
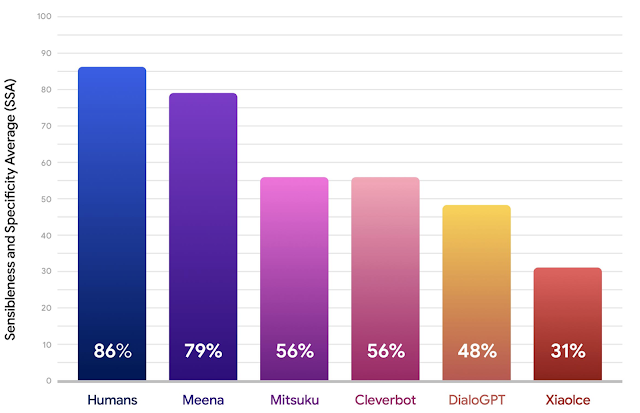
下面的結(jié)果表明,就 SSA 分?jǐn)?shù)而言,Meena 的表現(xiàn)大大優(yōu)于現(xiàn)有的最新聊天機(jī)器人,并且正在縮小與人類的差距。
自動(dòng)評(píng)估度量:困惑度
研究人員長(zhǎng)期以來(lái)一直在尋求一種與更準(zhǔn)確的人工評(píng)估相關(guān)的自動(dòng)評(píng)估度量,這樣做可以更快地開發(fā)對(duì)話模型,但是迄今為止,找到這樣的自動(dòng)度量標(biāo)準(zhǔn)一直是一個(gè)挑戰(zhàn)。出乎意料的是,谷歌研究人員發(fā)現(xiàn),在他們的工作中,“困惑度”似乎符合這一種自動(dòng)度量標(biāo)準(zhǔn),它可隨時(shí)用于任何神經(jīng) seq2seq 模型,表現(xiàn)出與人工評(píng)估(如 SSA 值)的強(qiáng)烈相關(guān)性。
谷歌研究人員關(guān)于“困惑度”的解釋是這樣的:困惑度用于衡量語(yǔ)言模型的不確定性,困惑度越低,模型就越有信心生成下一個(gè)標(biāo)記(如字符、子詞或單詞)。從概念上講,困惑度表示模型在生成下一個(gè)回答時(shí)試圖選擇的選項(xiàng)數(shù)量。
在開發(fā)過(guò)程中,研發(fā)人員對(duì)具有不同超參數(shù)和體系結(jié)構(gòu)的八個(gè)不同模型版本進(jìn)行了基準(zhǔn)測(cè)試,例如層數(shù)、關(guān)注頭(attention heads)、總訓(xùn)練步驟、是否使用 Evolved Transformer 或常規(guī) Transformer 以及是否使用硬標(biāo)簽或“蒸餾”進(jìn)行訓(xùn)練。如下圖所示,困惑度越低,模型的 SSA 評(píng)分越好,相關(guān)系數(shù)也很強(qiáng)(R 2 = 0.93)。
編者注:知識(shí)蒸餾(有時(shí)也稱為師生學(xué)習(xí))是一種壓縮技術(shù),要求對(duì)小型模型進(jìn)行訓(xùn)練,以使其擁有類似于大型模型(或者模型集合)的行為特征。
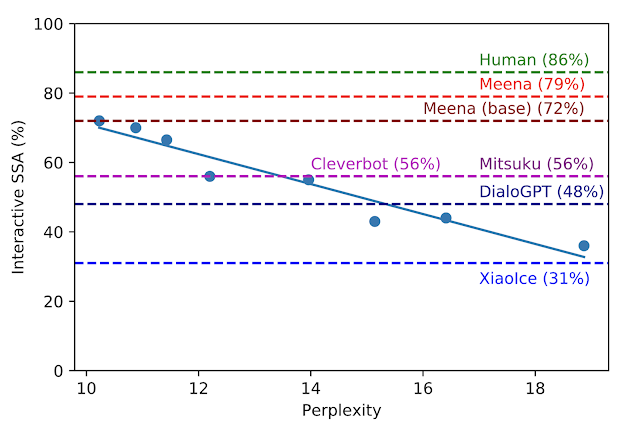
交互式 SSA 與困惑度。每個(gè)藍(lán)點(diǎn)都是 Meena 模型的不同版本,通過(guò)繪制一條回歸線,表明 SSA 和困惑之間存在很強(qiáng)的相關(guān)性。虛線分別對(duì)應(yīng)人類、其他機(jī)器人、Meena(base)、端到端訓(xùn)練模型的 SSA 性能,以及最終的具有過(guò)濾機(jī)制和已調(diào)諧解碼的完整 Meena。
谷歌表示,他們研發(fā)的最好的端到端 Meena 模型(稱為 Meena(base))的困惑度為 10.2(越小越好),并且 SSA 分?jǐn)?shù)轉(zhuǎn)換為 72%,完整版的 Meena 具有過(guò)濾機(jī)制和經(jīng)過(guò)解碼的解碼功能,可將 SSA 分?jǐn)?shù)進(jìn)一步提高到 79%。
未來(lái)的研究與挑戰(zhàn)
對(duì)于未來(lái)的規(guī)劃,谷歌的研發(fā)人員表示將繼續(xù)通過(guò)改進(jìn)算法,體系結(jié)構(gòu),數(shù)據(jù)和計(jì)算來(lái)降低神經(jīng)對(duì)話模型的困惑度。雖然目前研發(fā)人員只專注于這項(xiàng)工作中的明智性和特殊性,但其他屬性(例如事實(shí)性等)在后續(xù)工作中也值得考慮。此外,解決模型中的安全性和偏差是谷歌關(guān)注的重點(diǎn)領(lǐng)域。




























