搞懂高可用緩存架構,總結五大緩存問題解決方案
目錄
- 一、緩存特征
- 二、LRU
- 三、緩存類型
- 四、CDN
- 五、緩存問題
- 六、數據分布
- 七、一致性哈希
一、緩存特征
命中率
當某個請求能夠通過訪問緩存而得到響應時,稱為緩存命中。
緩存命中率越高,緩存的利用率也就越高。
最大空間
緩存通常位于內存中,內存的空間通常比磁盤空間小的多,因此緩存的最大空間不可能非常大。
當緩存存放的數據量超過最大空間時,就需要淘汰部分數據來存放新到達的數據。
淘汰策略
- FIFO(First In First Out):先進先出策略,在實時性的場景下,需要經常訪問最新的數據,那么就可以使用 FIFO,使得最先進入的數據(最晚的數據)被淘汰。
- LRU(Least Recently Used):最近最久未使用策略,優先淘汰最久未使用的數據,也就是上次被訪問時間距離現在最久的數據。該策略可以保證內存中的數據都是熱點數據,也就是經常被訪問的數據,從而保證緩存命中率。
- LFU(Least Frequently Used):最不經常使用策略,優先淘汰一段時間內使用次數最少的數據。
二、LRU
以下是基于 雙向鏈表 + HashMap 的 LRU 算法實現,對算法的解釋如下:
- 訪問某個節點時,將其從原來的位置刪除,并重新插入到鏈表頭部。這樣就能保證鏈表尾部存儲的就是最近最久未使用的節點,當節點數量大于緩存最大空間時就淘汰鏈表尾部的節點。
- 為了使刪除操作時間復雜度為 O(1),就不能采用遍歷的方式找到某個節點。HashMap 存儲著 Key 到節點的映射,通過 Key 就能以 O(1) 的時間得到節點,然后再以 O(1) 的時間將其從雙向隊列中刪除。
三、緩存類型
瀏覽器
當 HTTP 響應允許進行緩存時,瀏覽器會將 HTML、CSS、JavaScript、圖片等靜態資源進行緩存。
ISP
網絡服務提供商(ISP)是網絡訪問的第一跳,通過將數據緩存在 ISP 中能夠大大提高用戶的訪問速度。
反向代理
反向代理位于服務器之前,請求與響應都需要經過反向代理。通過將數據緩存在反向代理,在用戶請求反向代理時就可以直接使用緩存進行響應。
本地緩存
使用 Guava Cache 將數據緩存在服務器本地內存中,服務器代碼可以直接讀取本地內存中的緩存,速度非常快。
分布式緩存
使用 Redis、Memcache 等分布式緩存將數據緩存在分布式緩存系統中。
相對于本地緩存來說,分布式緩存單獨部署,可以根據需求分配硬件資源。不僅如此,服務器集群都可以訪問分布式緩存,而本地緩存需要在服務器集群之間進行同步,實現難度和性能開銷上都非常大。
數據庫緩存
MySQL 等數據庫管理系統具有自己的查詢緩存機制來提高查詢效率。
Java 內部的緩存
Java 為了優化空間,提高字符串、基本數據類型包裝類的創建效率,設計了字符串常量池及 Byte、Short、Character、Integer、Long、Boolean 這六種包裝類緩沖池。
CPU 多級緩存
CPU 為了解決運算速度與主存 IO 速度不匹配的問題,引入了多級緩存結構,同時使用 MESI 等緩存一致性協議來解決多核 CPU 緩存數據一致性的問題。
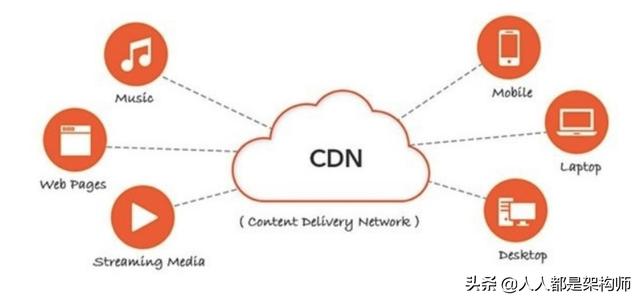
四、CDN
內容分發網絡(Content distribution network,CDN)是一種互連的網絡系統,它利用更靠近用戶的服務器從而更快更可靠地將 HTML、CSS、JavaScript、音樂、圖片、視頻等靜態資源分發給用戶。
CDN 主要有以下優點:
- 更快地將數據分發給用戶;
- 通過部署多臺服務器,從而提高系統整體的帶寬性能;
- 多臺服務器可以看成是一種冗余機制,從而具有高可用性。
五、緩存問題
緩存穿透
指的是對某個一定不存在的數據進行請求,該請求將會穿透緩存到達數據庫。
解決方案:
- 對這些不存在的數據緩存一個空數據;
- 對這類請求進行過濾。
緩存雪崩
指的是由于數據沒有被加載到緩存中,或者緩存數據在同一時間大面積失效(過期),又或者緩存服務器宕機,導致大量的請求都到達數據庫。
在有緩存的系統中,系統非常依賴于緩存,緩存分擔了很大一部分的數據請求。當發生緩存雪崩時,數據庫無法處理這么大的請求,導致數據庫崩潰。
解決方案:
- 為了防止緩存在同一時間大面積過期導致的緩存雪崩,可以通過觀察用戶行為,合理設置緩存過期時間來實現;
- 為了防止緩存服務器宕機出現的緩存雪崩,可以使用分布式緩存,分布式緩存中每一個節點只緩存部分的數據,當某個節點宕機時可以保證其它節點的緩存仍然可用。
- 也可以進行緩存預熱,避免在系統剛啟動不久由于還未將大量數據進行緩存而導致緩存雪崩。
緩存一致性
緩存一致性要求數據更新的同時緩存數據也能夠實時更新。
解決方案:
- 在數據更新的同時立即去更新緩存;
- 在讀緩存之前先判斷緩存是否是最新的,如果不是最新的先進行更新。
要保證緩存一致性需要付出很大的代價,緩存數據最好是那些對一致性要求不高的數據,允許緩存數據存在一些臟數據。
緩存 “無底洞” 現象
指的是為了滿足業務要求添加了大量緩存節點,但是性能不但沒有好轉反而下降了的現象。
產生原因:緩存系統通常采用 hash 函數將 key 映射到對應的緩存節點,隨著緩存節點數目的增加,鍵值分布到更多的節點上,導致客戶端一次批量操作會涉及多次網絡操作,這意味著批量操作的耗時會隨著節點數目的增加而不斷增大。此外,網絡連接數變多,對節點的性能也有一定影響。
解決方案:
- 優化批量數據操作命令;
- 減少網絡通信次數;
- 降低接入成本,使用長連接 / 連接池,NIO 等。
六、數據分布
哈希分布
哈希分布就是將數據計算哈希值之后,按照哈希值分配到不同的節點上。例如有 N 個節點,數據的主鍵為 key,則將該數據分配的節點序號為:hash(key)%N。
傳統的哈希分布算法存在一個問題:當節點數量變化時,也就是 N 值變化,那么幾乎所有的數據都需要重新分布,將導致大量的數據遷移。
順序分布
將數據劃分為多個連續的部分,按數據的 ID 或者時間分布到不同節點上。例如 User 表的 ID 范圍為 1 ~ 7000,使用順序分布可以將其劃分成多個子表,對應的主鍵范圍為 1 ~ 1000,1001 ~ 2000,...,6001 ~ 7000。
順序分布相比于哈希分布的主要優點如下:
能保持數據原有的順序;
并且能夠準確控制每臺服務器存儲的數據量,從而使得存儲空間的利用率最大。
七、一致性哈希
Distributed Hash Table(DHT) 是一種哈希分布方式,其目的是為了克服傳統哈希分布在服務器節點數量變化時大量數據遷移的問題。
基本原理
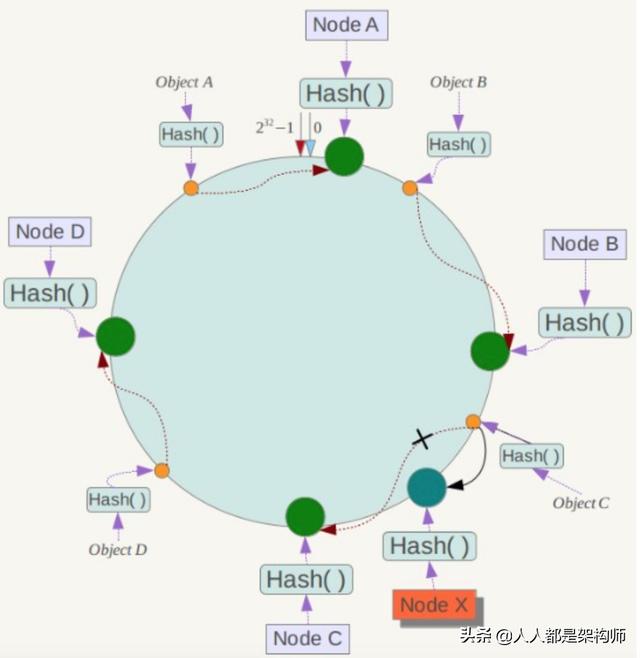
將哈希空間 [0, 2n-1] 看成一個哈希環,每個服務器節點都配置到哈希環上。每個數據對象通過哈希取模得到哈希值之后,存放到哈希環中順時針方向第一個大于等于該哈希值的節點上。
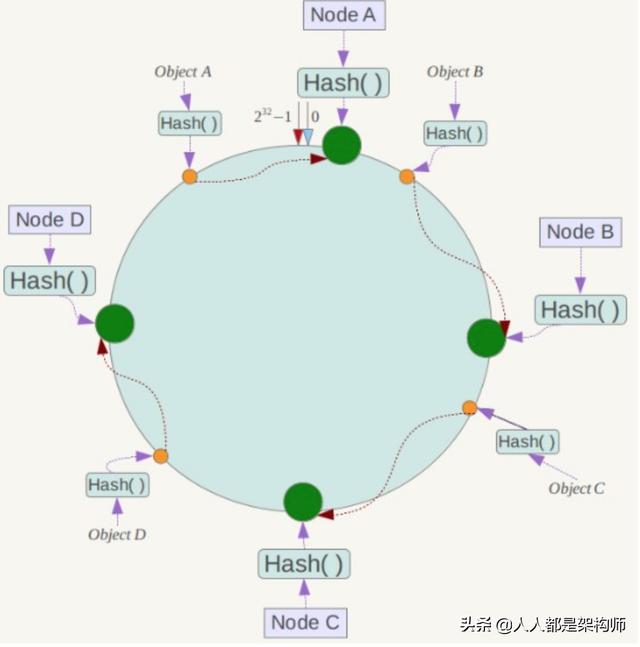
一致性哈希在增加或者刪除節點時只會影響到哈希環中相鄰的節點,例如下圖中新增節點 X,只需要將它前一個節點 C 上的數據重新進行分布即可,對于節點 A、B、D 都沒有影響。
虛擬節點
上面描述的一致性哈希存在數據分布不均勻的問題,節點存儲的數據量有可能會存在很大的不同。
數據不均勻主要是因為節點在哈希環上分布的不均勻,這種情況在節點數量很少的情況下尤其明顯。
解決方式是通過增加虛擬節點,然后將虛擬節點映射到真實節點上。虛擬節點的數量比真實節點來得多,那么虛擬節點在哈希環上分布的均勻性就會比原來的真實節點好,從而使得數據分布也更加均勻。