360自研分布式海量小文件存儲系統的設計與實現
近年來,公司業務發展迅猛,為數眾多的業務場景產生了大量的圖片,文檔,音頻,視頻等非結構化數據,尤其是隨著移動互聯網、AI、IoT技術的成熟和應用市場的全面爆發,大量智能硬件設備將會生成更大規模的非結構化多媒體數據。如此大量的小文件如何存儲,問題應運而生。傳統存儲廠商出售的存儲服務價格昂貴,公有云廠商對具體業務場景的定制化改造略有欠缺,因此,我們決定自研小文件存儲服務。
NebulasFs簡介
曾經關注小文件存儲技術的同學可能閱讀過Facebook發表的那篇關于海量小圖片存儲系統Haystack的論文(Finding a needle in Haystack: Facebook’s photo storage),Haystack通過合并多個小文件成一個大文件、以減少文件數量的方式解決了普通文件系統在存儲數量巨大的小文件時的問題:獲取一次文件多次讀取元數據信息、文件訪問的“長尾”效應導致大量文件元數據不容易緩存等。基于在Haystack的論文中得到的借鑒和參考,我們研發了自己的分布式小文件存儲系統——NebulasFs。它是一個分布式、高可用、高可靠、持久化小文件存儲系統,可以存儲數以百億的小文件。
架構設計
從分布式角色上劃分,可以分為Master和Datanode兩個大的角色。
其中,Master負責集群的元數據存儲、集群管理、任務調度等工作,它的數據一致性目前由外部一致性工具(ETCD等)實現。Master是一個主多個備。
Datanode是面向用戶的,它主要負責數據存儲和用戶請求的路由、分發。Datanode節點包括存儲Volume文件和Proxy模塊。如下圖所示:
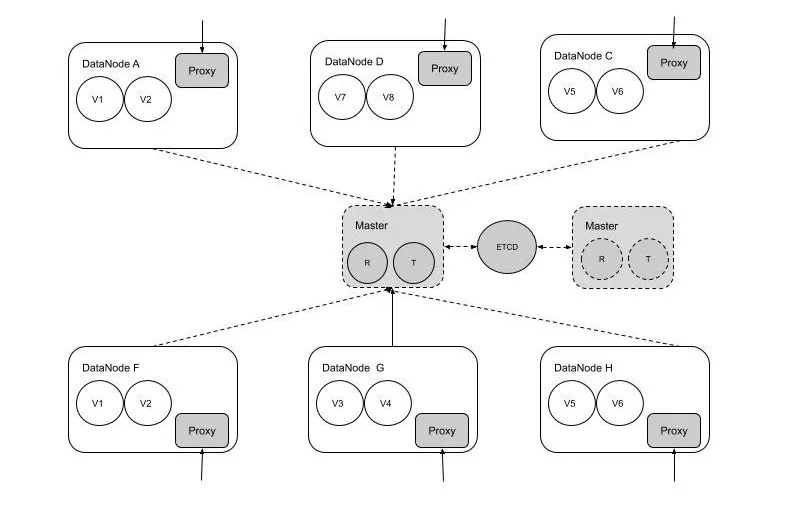
用戶的請求可以請求任意一個Datanode節點,節點的Proxy模塊會代理用戶請求到正確的數據存儲節點,并返回給用戶結構。對于多個副本的寫請求,Proxy模塊會按照副本的一致順序并行寫入直至全部成功后返回。對于讀請求只讀取第一個副本。
NebulasFs功能
為了在存儲容量、一致性、可用性等方面有更好的提升來滿足海量小文件存儲的需求,相對于Haystack論文,我們在接口服務、分布式架構方面做了更多的優化,主要體現在以下方面:
1. 提供給用戶使用的服務接口簡單、輕量、通用
NebulasFs提供給用戶Http Restful接口,協議更簡單,使用更方便,用戶可以通過簡單的PUT,GET等操作上傳和下載文件。用戶無需使用定制的客戶端,更加輕量級。
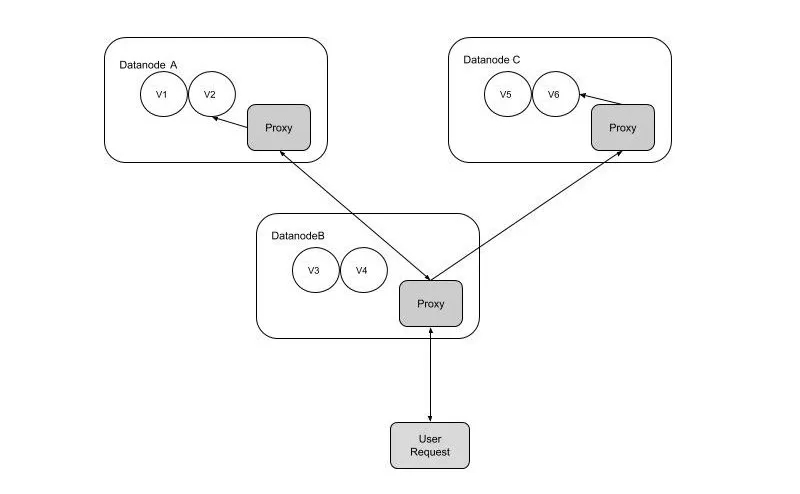
2. 用戶請求全代理、自動路由
我們知道,Datanode具有數據存儲的功能,可是對于數量眾多的Datanode來說,用戶要想知道哪些數據存儲在哪個Datanode上是需要先從Master 拿到數據路由的元數據才知道,這增加了用戶請求的復雜度。我們在Datanode上增加了請求代理、路由模塊把用戶的請求自動代理、路由到正確的Datanode上,使得用戶一次請求既能獲取數據。
3. 多租戶,提供租戶資源隔離機制,避免相互影響
一個集群提供的服務可能有多個用戶來使用,為了避免互相影響,NebulasFs抽象出了資源池的概念,不同的資源池物理上是分布在不同的硬件之上,資源池在機器維度上不交叉,可以有效的做到資源的隔離。不同的用戶可以分布在不同的資源池也可以共享資源池,這需要管理員提前做好規劃。資源池類型是多樣的,它的范圍可能是跨數據中心的,也可能是跨機柜,也可能是在一個機柜之內的。根據不同的物理硬件性能和數據副本存儲冗余需求,對不同類型的數據存儲需求也需要提前規劃。
4. 可定制的數據多副本存儲方案,數據無丟失、多種故障域組合
為了提供可用性,保證寫入數據不丟失,文件數據一般都會做容災存儲大于1的副本數量,以便在發生不可恢復的硬件故障時保證數據可用性以及用作之后的自動補齊副本數量。不同重要級別的數據和不同級別故障類型決定了使用不同級別的存儲方案。NebulasFs預先定義了5個級別的故障域,分別是:數據中心、機柜列、機柜、機器、磁盤。要求可用性較高的數據存儲時使用跨數據中心做容災副本,以便在整個數據中心不可用時使用另外一個數據中心的數據。要求沒那么高的數據可以在做容災副本策略的時候選擇跨機柜存儲即可,使得即便在邊沿交換機故障后也可用。
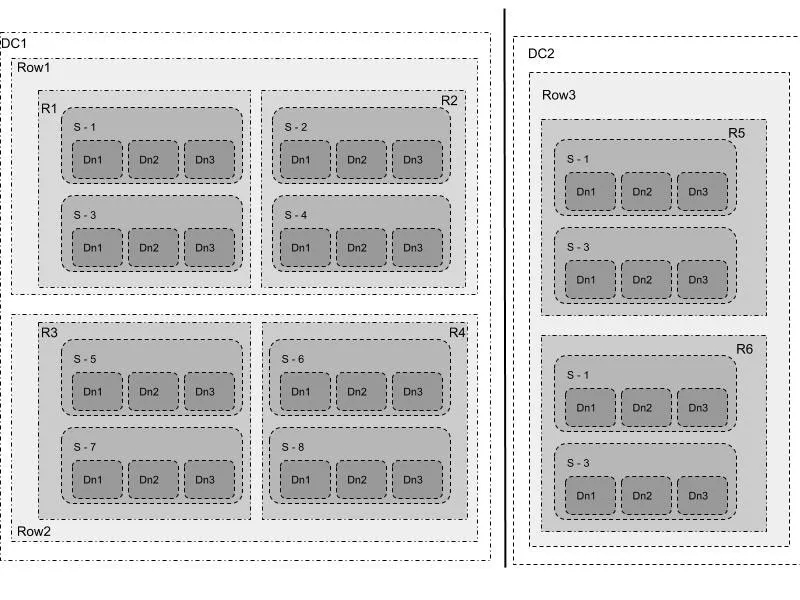
NebulasFs故障域和資源隔離池之間的關系如下:
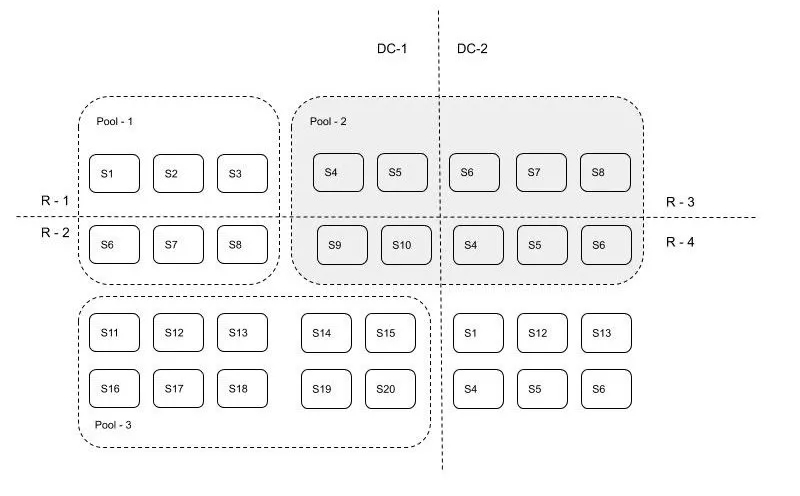
S代表服務器,R-1, R-2是屬于數據中心DC-1的兩個機柜,R-3, R42是屬于數據中心DC-2的兩個機柜。Pool-1是跨機柜故障域的資源隔離池,Pool-2是跨數據中心故障域的資源池,Pool-3是跨服務器故障域的資源池。
NebulasFs 故障域邏輯和物理概念對應如下:
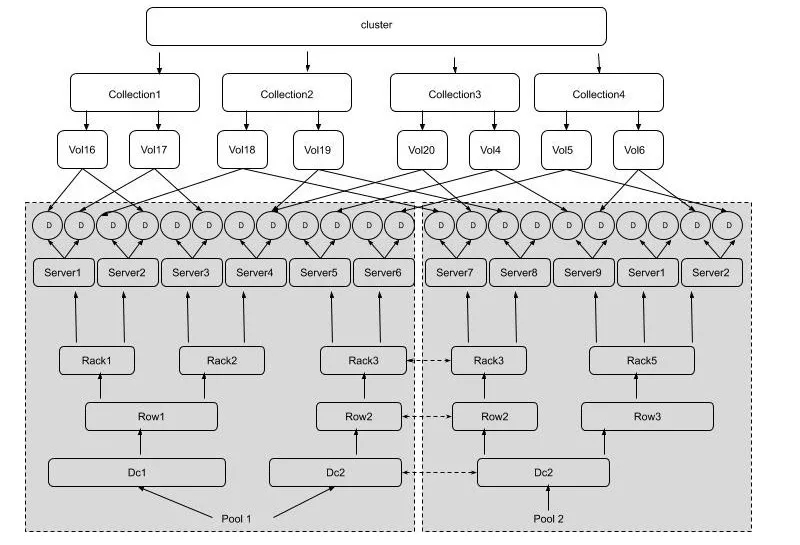
其中上半部分是邏輯概念,下半部分是物理概念。用戶及請求均與邏輯概念相關,管理運維涉及物理概念相關。一個用戶可以對應一個或者多個Collection, 一個Collection對應多個Volume, 每個Volume是存儲在DataNode上的文件(有幾個副本就有幾個文件)。一般一個DataNode對應服務器上的一塊硬盤。一臺服務器上有多個DataNode。服務器(Server)的上層是機柜(Rack)、一排機柜(Row)和數據中心(DataCenter)。
5. 自動化擴容和再平衡
擴容分為存儲容量不足進行擴容和請求流量過載進行的擴容。由于容量不足的擴容后無需再平衡,只有請求流量大擴容后需要做數據再平衡。再平衡是按照容災副本數等策略進行的,按照策略添加的Datanode會自動注冊到Master上,Master按照預定的規則進行協調再平衡。
兩種擴容情況如下:
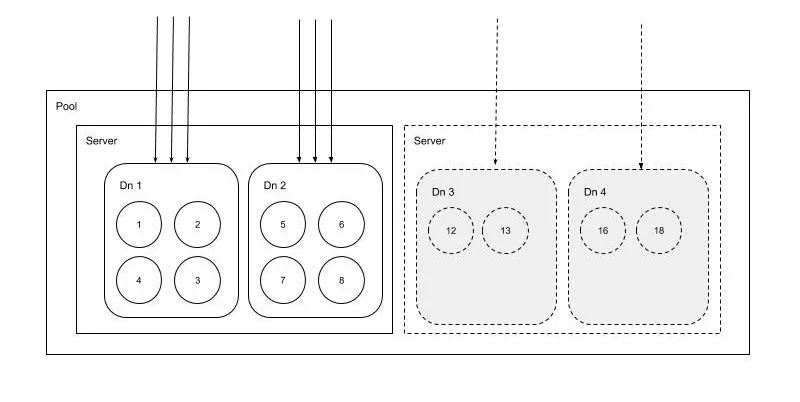
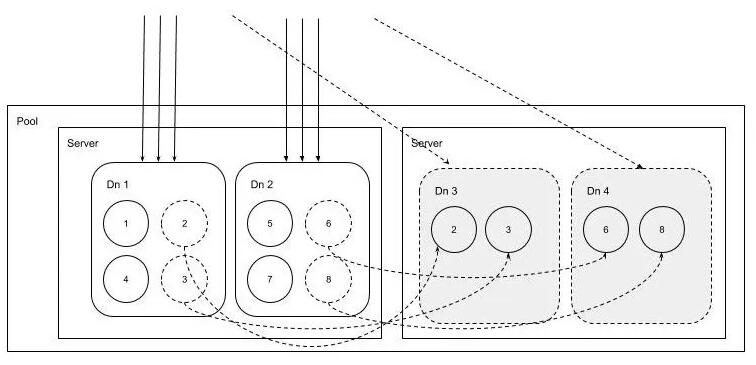
6. 自動化副本修復補齊
一定規模的集群故障可能會變的比較頻繁,在我們的系統中故障很大程度上意味著數據副本的丟失,人工補齊數據副本工作量較大,因此自動化補齊副本就成了一個比較重要的功能。自動化補齊副本是靠Master發現副本缺失和協調補齊的。在補齊的過程中數據副本都會變成只讀。過程如下圖:
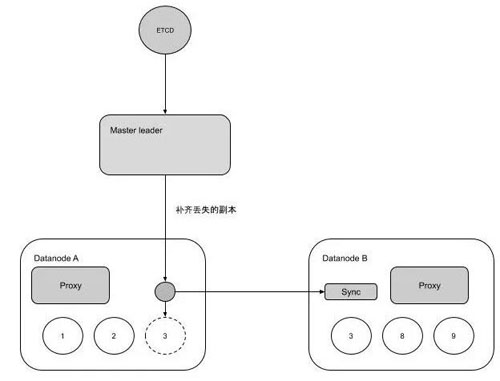
整個自動化副本補齊如下圖所示:
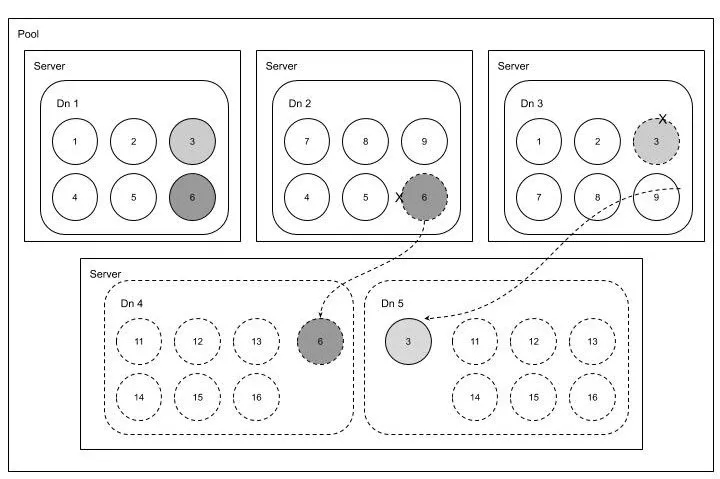
由于硬盤故障,數據節點 2 和 3 上的Volume 3 和 6 副本丟失,自動補齊自動把這兩個副本補齊到數據節點 4 和 5 上,并加入到集群中。
小結
到目前為止,NebulasFs在內部已經使用了近一年的時間。除此之外NebulasFs還做為后端存儲為另一個對象存儲(AWS S3協議)提供服務以存儲大文件。
伴隨著業務的不斷接入,NebulasFs也會不斷完善,為業務增長提供更好的保障。
【本文是51CTO專欄機構360技術的原創文章,微信公眾號“360技術( id: qihoo_tech)”】