多級緩存設計詳解 | 給數(shù)據(jù)庫減負,刻不容緩!
自古兵家多謀,《謀攻篇》,“故上兵伐謀,其次伐交,其次伐兵,其下攻城。攻城之法,為不得已”,可見攻城之計有很多種,而爬墻攻城是最不明智的做法,軍隊疲憊受損、錢糧損耗、百姓遭殃。故而我們有很多迂回之策,謀略、外交、軍事手段等等,每一種都比攻城的代價小,更輕量級,緩存設計亦是如此。
為什么要設計緩存呢?
其實高并發(fā)應對的解決方案不是互聯(lián)網(wǎng)***的,計算機先祖?zhèn)兒茉缇蛯︻愃频膱鼍白隽朔桨浮1热纭队嬎銠C組成原理》這樣提到的cpu緩存概念,它是一種高速緩存,容量比內存小但是速度卻快很多,這種緩存的出現(xiàn)主要是為了解決cpu運算速度遠大于內存讀寫速度,甚至達到千萬倍。
傳統(tǒng)的cpu通過fsb直連內存的方式顯然就會因為內存訪問的等待,導致cpu吞吐量下降,內存成為性能瓶頸。同時又由于內存訪問的熱點數(shù)據(jù)集中性,所以需要在cpu與內存之間做一層臨時的存儲器作為高速緩存。
隨著系統(tǒng)復雜性的提升,這種高速緩存和內存之間的速度進一步拉開,由于技術難度和成本等原因,所以有了更大的二級、三級緩存。根據(jù)讀取順序,絕大多數(shù)的請求首先落在一級緩存上,其次二級...
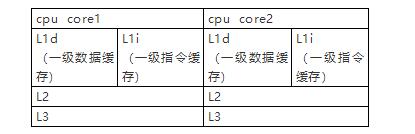
故而應用于SOA甚至微服務的場景,內存相當于存儲業(yè)務數(shù)據(jù)的持久化數(shù)據(jù)庫,其吞吐量肯定是遠遠小于緩存的,而對于java程序來講,本地的jvm緩存優(yōu)于集中式的redis緩存。
關系型數(shù)據(jù)庫操作方便、易于維護且訪問數(shù)據(jù)靈活,但是隨著數(shù)據(jù)量的增加,其檢索、更新的效率會越來越低。所以在高并發(fā)低延遲要求復雜的場景,要給數(shù)據(jù)庫減負,減少其壓力。
給數(shù)據(jù)庫減負
1. 緩存分布式,做多級緩存

(1) 讀請求時寫緩存
寫緩存時一級一級寫,先寫本地緩存,再寫集中式緩存。具體些緩存的方法可以有很多種,但是需要注意幾項原則:
- 不要復制粘貼,避免重復代碼
- 切忌和業(yè)務耦合太緊,不利于后期維護
- 開發(fā)初期剛剛上線階段,為了排查問題,常常會給緩存設置開關,但是開關設置多了則會同時升高系統(tǒng)的復雜度,需要結合一套統(tǒng)一配置管理系統(tǒng),京東物流有一套叫做UCC,且聽下回分解......
綜上所述,高耦合帶來的痛,彌補的代價是很大的,所以可以借鑒Spring cache來實現(xiàn),實現(xiàn)也比較簡單,使用時一個注解就搞定了。
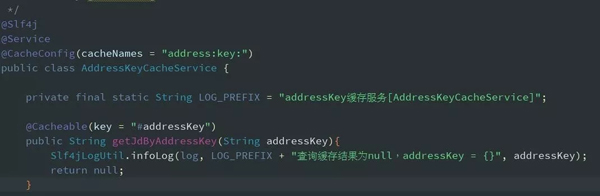
(2) 寫緩存失敗了怎么辦?應該先寫緩存還是數(shù)據(jù)庫呢?
既然是緩存的設計,那么策略一定是保證最終一致性,那么我們只需要采用異步消息來補償就好了。
大部分緩存應用的場景是讀寫比差異很大的,讀遠大于寫,在這種場景下,只需要以數(shù)據(jù)庫為主,先寫數(shù)據(jù)庫,再寫緩存就好了。
***補充一點,數(shù)據(jù)庫出現(xiàn)異常時,不要一股腦的catch RuntimeException,而是把具體關心的異常往外拋,然后進行有針對性的異常處理。
(3) 關于其他性能方面
緩存設計都是占用越少越好,內存資源昂貴以及太大不好維護都驅使我們這樣設計。所以要盡可能減少緩存不必要的數(shù)據(jù),有的同學圖省事把整個對象序列化存儲。另外,序列化與反序列化也是消耗性能的。
2. vs各種緩存同步方案
緩存同步方案有很多種,在考慮一致性、數(shù)據(jù)庫訪問壓力、實時性等方面做權衡。總的來說有以下幾種方式:
(1) 懶加載式
如上段提到的方式,讀時順便加載。為了更新緩存數(shù)據(jù),需要過期緩存。

優(yōu)點:簡單直接
缺點:
- 會造成一次緩存不***
- 這樣當用戶并發(fā)很大時,恰好緩存中無數(shù)據(jù),數(shù)據(jù)庫承擔瞬時流量過大會造成風險。
懶加載式太簡單了,沒有自動加載,異步刷新等機制,為了彌補其缺陷,請參見接下來的兩種方法。
(2) 補充式
可以在緩存時,把過期時間等信息寫到一個異步隊列里,后臺起個線程池定期掃描這個隊列,在快過期時主動reload緩存,使得數(shù)據(jù)會一直保持在緩存中,如果緩存沒有也沒有必要去數(shù)據(jù)庫查詢了。常見的處理方式有使用binlog加工成消息供增量處理。
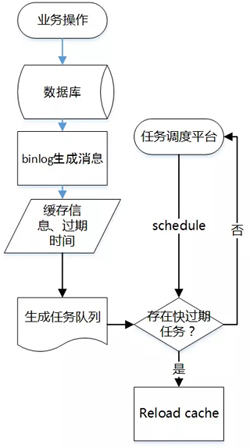
- 優(yōu)點:刷新緩存變?yōu)楫惒降娜蝿眨瑢?shù)據(jù)庫的壓力瞬間由于任務隊列的介入而降低了,削平并發(fā)的波峰。
- 缺點:消息一旦積壓會造成同步延遲,引入復雜度。
(3) 定時加載式
這就需要有個異步線程池定期把數(shù)據(jù)庫的數(shù)據(jù)刷到集中式緩存,如redis里。
- 優(yōu)點:保證所有數(shù)據(jù)最小時間差同步到緩存中,延遲很低。
- 缺點:如補充式,需要一個任務調度框架,復雜度提升,且要保證任務的順序。如果遞進一步還想加載到本地緩存,就得本地應用自己起線程抓取,方案維護成本高。可以考慮使用mq或者其他異步任務調度框架。
- ps:為了防止隊列過大調度出現(xiàn)問題,處理完的數(shù)據(jù)要盡快結轉,且要對積壓數(shù)據(jù)以及寫入情況做監(jiān)控。
3. 防止緩存穿透
緩存穿透是指查詢的key壓根不存在,從而緩存查詢不到而查詢了數(shù)據(jù)庫。若是這樣的key恰好并發(fā)請求很大,那么就會對數(shù)據(jù)庫造成不必要的壓力。怎么解決呢?
- 把所有存在的key都存到另外一個存儲的Set集合里,查詢時可以先查詢key是否存在。
- 干脆簡單一些,給查詢不到的key也加一個標識空值的Value,這樣就不會去查詢數(shù)據(jù)庫了,比如場景為查詢省市區(qū)街道對應的移動營業(yè)廳,若是某街道確實沒有移動營業(yè)廳,key規(guī)則不變,value可以設置為"0"等無意義的字符。當然此種方案要保證緩存集群的高可用。
- 這些Key可能不是永遠不存在,所以需要根據(jù)業(yè)務場景來設置過期時間。
4. 熱點緩存與緩存淘汰策略
有一些場景,需要只保持一部分的熱點緩存,不需要全量緩存,比如熱賣的商品信息,購買某類商品的熱門商圈信息等等。
綜合來講,緩存過期的策略有以下三種:
(1) FIFO(First In,F(xiàn)irst Out)
先進先出,淘汰最早進來的緩存數(shù)據(jù),一個標準的隊列。

以隊列為基本數(shù)據(jù)結構,從隊首進入新數(shù)據(jù),從隊尾淘汰。
(2) LRU(Least RecentlyUsed)
最近最少使用,淘汰最近不使用的緩存數(shù)據(jù)。如果數(shù)據(jù)最近被訪問過,則不淘汰。
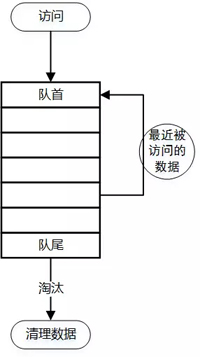
- 和FIFO不同的是,需要對鏈表做基本模型,讀寫的時間復雜度是O(1),寫入新數(shù)據(jù)進入頭部,鏈表滿了數(shù)據(jù)從尾部淘汰;
- 最近時間被訪問的數(shù)據(jù)移動到頭部,實現(xiàn)算法有很多,如hashmap+雙向鏈表等等;
- 問題在于若是偶發(fā)性某些key被最近頻繁訪問,而非常態(tài),則數(shù)據(jù)受到污染。
(3) LFU(Least Frequently used)
最近使用次數(shù)最少的數(shù)據(jù)被淘汰,注意和LRU的區(qū)別在于LRU的淘汰規(guī)則是基于訪問時間。
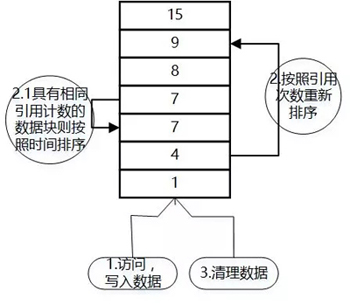
- LFU中的每個數(shù)據(jù)塊都有一個引用計數(shù),數(shù)據(jù)塊按照引用計數(shù)排序,若是恰好具有相同引用計數(shù)的數(shù)據(jù)塊則按照時間排序;
- 因為新加入的數(shù)據(jù)訪問次數(shù)為1,所以插入到隊列尾部;
- 隊列中的數(shù)據(jù)被新訪問后,引用計數(shù)增加,隊列重新排序;
- 當需要淘汰數(shù)據(jù)時,將已經(jīng)排序的列表***的數(shù)據(jù)塊刪除;
- 有很明顯問題是若短時間內被頻繁訪問多次,比如訪問異常或者循環(huán)沒有控制住,而后很長時間未使用,則此數(shù)據(jù)會因為頻率高而被錯誤的保留下來沒有被淘汰。尤其對于新來的數(shù)據(jù),由于其起始的次數(shù)是1,所以即便被正常使用也會因為比不過老的數(shù)據(jù)而被淘汰。所以維基百科說純粹的LFU算法不經(jīng)常單獨使用而是組合在其他策略中使用。
4. 緩存使用的一些常見問題
Q:那么應該選擇用本地緩存(local cache)還是集中式緩存(Cache cluster)呢?
A:首先看數(shù)據(jù)量,看緩存更新的成本,如果整體緩存數(shù)據(jù)量不是很大,而且變化的不頻繁,那么建議本地緩存。
Q:怎么批量更新一批緩存數(shù)據(jù)?
A:依次從數(shù)據(jù)庫讀取,然后批量寫入緩存,批量更新,設置版本過期key或者主動刪除。
Q:如果不知道有哪些key怎么定期刪除?
A:拿redis來說keys * 太損耗性能,不推薦。可以指定一個集合,把所有的key都存到這個集合里,然后對整個集合進行刪除,這樣便能完全清理了。
Q:一個key包含的集合很大,redis無法做到內存空間上的均勻Shard?
A:可以簡單的設置key過期,這樣就要允許有緩存不***的情況;給key設置版本,比如為兩天后的當前時間,然后讀取緩存時用時間判斷一下是否需要重新加載緩存,作為版本過期的策略。
王梓晨:物流研發(fā)部架構師,GIS技術部負責人,2012年加入京東,多年一線團隊大促備戰(zhàn)經(jīng)驗,負責物流研發(fā)一些部門的架構工作,專注于低延遲系統(tǒng)設計與海量數(shù)據(jù)處理。曾負責青龍配送分單團隊,主導重構架構設計與主要研發(fā)工作,短期內提升了服務性能數(shù)十倍。還設計研發(fā)了地址配送網(wǎng)點分類模型,實現(xiàn)了配送到路區(qū)的精準化分單,降本增效,大幅提升了自動分單準確率。目前負責物流GIS部門,先后主導了國標轉京標、物流可視化等項目。
【本文來自51CTO專欄作者張開濤的微信公眾號(開濤的博客),公眾號id: kaitao-1234567】