齊彥杰:機(jī)器學(xué)習(xí)在新浪微博個(gè)性化push的應(yīng)用
原創(chuàng)【51CTO.com原創(chuàng)稿件】新浪微博不僅僅是一個(gè)信息交流平臺(tái),同時(shí)也兼具著媒體屬性,據(jù)統(tǒng)計(jì)2013年12月新浪微博MAU(Monthly Active Users,月活躍用戶數(shù)量)達(dá)到1.29億,DAU(Daily Active Users,日活躍用戶數(shù)量)超過6100萬,到2018年3月,MAU突破4.11億,DAU達(dá)到1.84億。據(jù)2017年數(shù)據(jù)統(tǒng)計(jì),微博的主要用戶集中在23-30歲,占38.6%,性別上男性多于女性,占56.3%,而用戶興趣主要集中在明星、美女帥哥、動(dòng)漫等泛娛樂領(lǐng)域。
這么龐大的用戶體量和廣泛的興趣標(biāo)簽,如何做才能將用戶感興趣的話題、博主、事件***時(shí)間進(jìn)行精準(zhǔn)推送,是新浪微博一直要解決的事情,個(gè)性化push的應(yīng)用將精準(zhǔn)推送這項(xiàng)業(yè)務(wù)變的短時(shí)高效。

圖1 新浪微博齊彥杰
博文質(zhì)量、算法模型與分發(fā)效率共同決定push效果
在實(shí)現(xiàn)個(gè)性化push之前要先構(gòu)建一個(gè)推薦系統(tǒng),所有的推薦系統(tǒng)基本上都是從內(nèi)容源頭中去找到用戶喜歡的東西,微博的源頭就是全量的原創(chuàng)博文。但是面對(duì)每天幾千萬量級(jí)的生產(chǎn)量和大量不適宜的原創(chuàng)文章,如何才能將精準(zhǔn)推送這個(gè)訴求變現(xiàn)呢?人工篩選加機(jī)器篩選是個(gè)不錯(cuò)的組合。在push推送過程中加入人工審核程序,可以降低涉黃、不健康、不適宜內(nèi)容的傳播,同時(shí)還減少了對(duì)用戶的騷擾。
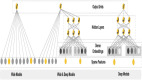
物料召回模型只是在源頭處把握了原創(chuàng)博文的篩選,如何才能將優(yōu)質(zhì)文章推薦給感興趣的用戶呢?這就需要排序算法模型了。首先,將物料生成模型進(jìn)行審核,篩選出全量?jī)?yōu)質(zhì)的內(nèi)容,放到物料池中,并且物料池要實(shí)時(shí)更新互動(dòng)特征,比如,這個(gè)微博在當(dāng)前的時(shí)間點(diǎn)的轉(zhuǎn)發(fā)量和評(píng)論數(shù)等。更新以后,每分鐘提取當(dāng)前可用物料和用戶,進(jìn)行計(jì)算和排序,從中篩選出客戶最感興趣的博文,***發(fā)送給用戶。其實(shí),在我們的推薦系統(tǒng)中,和模型計(jì)算平行的還有一個(gè)協(xié)同推薦服務(wù)。有一些推薦系統(tǒng)中把協(xié)同推薦作為一種召回的方式,把協(xié)同推薦產(chǎn)生的內(nèi)容放在物料召回的部分再做推薦。但是在我們的場(chǎng)景中,協(xié)同推薦效果好于排序模型,所以沒有必要再走一遍程序,可以直接發(fā)送給用戶。經(jīng)過基礎(chǔ)過濾下發(fā),實(shí)時(shí)收集下發(fā)日志和點(diǎn)擊日志,經(jīng)過數(shù)據(jù)處理和加工,再去更新物料池,同時(shí)更新物料生成模型和運(yùn)營(yíng)審核部分。
")
圖2 推薦系統(tǒng)
機(jī)器學(xué)習(xí)的特征維度建立
在排序策略、模型服務(wù)、特征工程、基礎(chǔ)數(shù)據(jù)的整體架構(gòu)下有博文信息、用戶信息、行為信息等,利用這些信息在上層挖掘出特征,利用特征進(jìn)行模型訓(xùn)練和評(píng)估,得出排序模型和物料模型。當(dāng)有了模型之后,再把模型運(yùn)用到線上做排序策略、CTR預(yù)估。***,將線上的數(shù)據(jù)再傳導(dǎo)回來,進(jìn)行基礎(chǔ)數(shù)據(jù)計(jì)算,供下一次模型訓(xùn)練迭代。
興趣維度
但是,對(duì)于一個(gè)博文來說,特征構(gòu)建的時(shí)候需要通過一個(gè)三級(jí)標(biāo)簽體系來具像這個(gè)博文代表的意義,以及通過用戶對(duì)博文的瀏覽程度來呈現(xiàn)用戶的興趣,這時(shí)就會(huì)建立一個(gè)三級(jí)標(biāo)簽體系,首先***級(jí)標(biāo)簽是比較寬泛的,比如說體育領(lǐng)域,一級(jí)標(biāo)簽下面會(huì)有二級(jí)標(biāo)簽,比如:足球,二級(jí)標(biāo)簽下面會(huì)有三級(jí)標(biāo)簽,比如:梅西、C羅。當(dāng)一個(gè)用戶消費(fèi)了多個(gè)打上梅西標(biāo)簽的博文的時(shí)候,我們就知道這個(gè)用戶對(duì)梅西感興趣,所以,當(dāng)有一個(gè)梅西的物料進(jìn)來的時(shí)候,就會(huì)用到這部分特征,加入到模型中進(jìn)行訓(xùn)練,再推送給興趣用戶,這個(gè)就是興趣維度。

圖3 興趣維度
關(guān)系維度
興趣維度是一個(gè)用戶對(duì)興趣領(lǐng)域的特征描述,但是如果想把博主與用戶,也就是人與人之間的特征描述加入到模型當(dāng)中,就需要關(guān)系維度了。當(dāng)一個(gè)博主和一個(gè)用戶在歷史上的互動(dòng)非常高的話,那么這個(gè)博主一定是契合這個(gè)用戶的需求的,所以他們的關(guān)系也可以作為一個(gè)維度特征加入到模型當(dāng)中。
實(shí)時(shí)維度
將興趣維度、關(guān)系維度加入到模型的同時(shí),還需要將先驗(yàn)數(shù)據(jù)傳導(dǎo)回來,這時(shí)候就需要實(shí)時(shí)維度的幫助。因?yàn)镻ush場(chǎng)景用的物料相對(duì)少一些,同時(shí)曝光機(jī)會(huì)也特別少,而點(diǎn)擊率就可以作為先驗(yàn)數(shù)據(jù)傳導(dǎo)回來,導(dǎo)入到模型中。
除了以上三種維度,還包括環(huán)境的維度,推送的時(shí)間、設(shè)備的網(wǎng)絡(luò)信息、設(shè)備本身的信息等等。
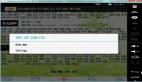
介紹完特征部分之后,再講一下模型演進(jìn)的過程。升級(jí)從LR(Logistic Regression,邏輯回歸)模型開始,LR模型基本上比較難以捕捉用戶的組合特征,所以進(jìn)一步升級(jí)到FM模型。FM( Factorization Machine,隱因子分解機(jī))模型是LR模型加上Dense(密集化)的兩兩特征組合。每一個(gè)兩兩組合特征,需要有一個(gè)權(quán)重Wij,如果直接求Wij,因?yàn)樘卣鹘M合會(huì)造成樣本過少,導(dǎo)致Wij不準(zhǔn)確,所以是通過因子Vi,Vj相乘的形式來得到Wij。但是,F(xiàn)M模型只做了兩兩組合特征,所以又升級(jí)成了wide&deep模型,通過把wide模型和deep模型進(jìn)行組合,既保留了wide模型里面的記憶能力,又有一些高級(jí)特征組合模型的能力,使這樣一個(gè)模型能夠有更強(qiáng)的表現(xiàn)能力。

圖4 Wide&deep模型
Push在使用中的實(shí)用技巧
利用用戶頻次(頻率+次數(shù))拆分提高點(diǎn)擊量和點(diǎn)擊率
微博使用中用戶的頻次差異很大,因此要將用戶的頻次進(jìn)行拆分,分別訓(xùn)練高頻次、中頻次和低頻次的用戶,所以需要在負(fù)樣本的選擇上做一些改變。
在服務(wù)器推送的時(shí)候,會(huì)遇到用戶設(shè)置系統(tǒng)不提醒新消息的狀況,也會(huì)遇到用戶不看新消息的狀況,所以,在選擇推送用戶的時(shí)候,盡量選取歷史上有過正樣本的用戶,這樣,用戶在獲得正樣本復(fù)發(fā)的時(shí)候,在正樣本上下幾條曝光(其中包含兩條負(fù)樣本),就可以提高點(diǎn)擊量和點(diǎn)擊率。
逐層控制下發(fā)物料
如果一個(gè)物料在沒有經(jīng)過充分驗(yàn)證的情況下,就對(duì)所有的人進(jìn)行計(jì)算,可能因?yàn)槟骋粋€(gè)特征特別高的時(shí)候,使下發(fā)產(chǎn)生過大,這樣可能把一個(gè)低質(zhì)物料展現(xiàn)給過多用戶。所以首先要在一個(gè)特別小的范圍內(nèi)進(jìn)行嘗試,如果點(diǎn)擊率達(dá)到預(yù)期,則會(huì)逐漸一層一層擴(kuò)大,直到放到全量。這個(gè)方式,可以控制低質(zhì)物料下發(fā)范圍,同時(shí)把曝光機(jī)會(huì)讓給經(jīng)過充分驗(yàn)證的優(yōu)質(zhì)物料。
以上內(nèi)容是51CTO記者根據(jù)新浪微博齊彥杰在WOT2018全球軟件與運(yùn)維技術(shù)峰會(huì)的演講內(nèi)容整理,更多關(guān)于WOT的內(nèi)容請(qǐng)關(guān)注51cto.com。