David Silver全面解讀深度強化學習:從基礎概念到AlphaGo

強化學習在與之相關的研究者中變得越來越流行,尤其是在 DeepMind 被 Google 收購以及 DeepMind 團隊在之后的 AlphaGo 上大獲成功之后。在本文中,我要回顧一下 David Silver 的演講。
David Silver 的演講視頻可在這里查看:
http://techtalks.tv/talks/deep-reinforcement-learning/62360/
在這個演講視頻中,David 做了對深度學習(DL)和強化學習(RL)的基本介紹,并討論了如何將這兩種學習方法結合成一種方法。有三種不同的可以結合深度學習和強化學習的方法:基于價值(value-based)、基于策略(policy-based)以及基于模型(model-based)的方法。在這個演講中,David 提供了許多他們自己的實驗的實例,最后以對 AlphaGo 的簡單討論結束了演講。
一、概覽
演講分為五個部分:
- 介紹深度學習
- 介紹強化學習
- 基于價值的深度強化學習
- 基于策略的深度強化學習
- 基于模型的深度強化學習
然而,當我看完講座、理解了各個主題之后,便決定在上述的演講結構中引入一個新的部分——做一個深度強化學習(Deep RL)的概述。這篇文章將會按照如下組織:
- 介紹深度學習
- 介紹強化學習
- 深度強化學習概述
- 基于價值的深度強化學習
- 基于策略的深度強化學習
- 基于模型的深度強化學習
希望上述的文章結構能夠幫助大家更好地理解整個主題。我會重點關注演講視頻中的重點,并盡可能去解釋一些問題的復雜概念。我也會給出我自己的觀點、建議以及一些可以幫助到大家的參考資料。
在深入研究更加復雜的強化學習(RL)主題之前,我會盡可能提供一些關于深度學習和強化學習的基本知識,因為對不了解這兩個主題的基本知識的人而言,這個演講是有一定難度的。希望這些基本知識可以幫助大家。如果你對自己的知識非常有信心,那么,你可以跳過文章的前兩部分。
二、深度學習介紹
什么是深度學習?
深度學習是表征學習的通用框架,它有以下特點:
- 給定一個目標(objective)
- 學習能夠實現目標的特征
- 直接的原始輸入
- 使用最少的領域知識
深度學習(deep learning)的意思就是深度表征(deep representation)。
如圖所示,一個深度表征由很多函數組成,它的梯度可以通過鏈式法則來反向傳播。

「深(deep)」的程度可以由函數或者參數的數量來推斷。計算機硬件以及算法的發展使得計算機能夠在合適的時間范圍內完成上圖所述的函數的計算,這是深度學習異軍突起背后的原因。
反向傳播(backpropagation)算法在解決深度問題中起著至關重要的作用。對任何一個想學習深度學習的人而言,理解反向傳播是很重要的。
請不要混淆深度神經網絡與深度學習。深度學習是一項實現機器學習的技術 [3]。它僅僅是一種機器學習的方法。而深度神經網絡通常被人們用來理解深度表征。

深度神經網絡通常包括以下內容:
線性變換、非線性激活函數、以及關于輸出的損失函數,例如均方差和對數似然值。
我們用隨機梯度下降的方法來訓練神經網絡。

如上圖所示,按照能夠使得損失函數 L(W) 減小的方向去調整參數 W.
實踐中一個常用的有效方法就是權值共享(Weight Sharing),它是減少參數數量的關鍵。有兩種神經網絡能夠實現權值共享,即循環神經網絡(Recurrent Neural Network)和卷積神經網絡(ConvolutionalNeural Network)。

如上圖所示,循環神經網絡在時間步長之間共享權值,卷積神經網絡在空間區域共享權值。
三、強化學習簡介
什么是強化學習?
在這個講座中,David給出了一張圖表明強化學習在不同領域中的復雜地位,如下圖所示:

盡管我們在機器學習社區中廣泛使用強化學習,但強化學習不僅僅是一個人工智能術語。它是許多領域中的一個中心思想,因此圖片的標題是「強化學習的多個方面(Many Face of Reinforcement Learning)」。事實上,許多這些領域面臨著與機器學習相同的問題:如何優化決策以實現最佳結果。
這就是決策科學(scienceof decision-making)。在神經科學中,人類研究人腦并發現了一種遵循著名的強化算法的獎勵系統。在心理學中,人們研究的經典條件反射和操作性條件反射,也可以被認為是一個強化問題。類似的,在經濟學中我們研究理性博弈論;在數學中我們研究運籌學;在工程學中我們研究優化控制。所有的這些問題都可以被認為一種強化學習問題—它們研究同一個主題,即為了實現最佳結果而優化決策。
強化學習是一個由行為心理學啟發的機器學習領域 [4]。舉個例子,一個學生名叫 Mike,如果他今天閱讀了一篇與強化學習相關的論文,他將會在昨天的分數的基礎上獲得 1 分的獎勵(稱作正反饋)。如果他打了一整天的籃球,他的分數將會被扣掉 1 分(稱為負反饋)。因而,如果 Mike 想每天都想獲得更多的獎勵(正反饋),他會每天都去學習。
「本質上,這些都是閉環系統,因為學習系統的行為會影響它之后的輸入。此外,(1) 學習系統沒有像很多其它形式的機器學習方法一樣被告知應該做出什么行為;(2) 相反,必須在嘗試了之后才能發現哪些行為會導致獎勵的最大化;(3) 在大多數有趣并且有挑戰性的例子中,當前的行為可能不僅僅會影響即時獎勵,還會影響下一步的獎勵以及后續的所有獎勵。這三個特征是強化學習中最重要的三個區分特征,作為閉環系統的本質、沒有關于該采取什么行動和后續的包括獎勵信號和完成學習的時間的直接指示。」
強化學習和標準監督學習的區別就在于從來不呈現正確的輸入/輸出對,也不存在次優化的行為被顯式地修正。此外,還關注在線性能。在線性能涉及在對未知領域的探索和當前領域知識的利用之間尋求一個平衡。
前面說了一下什么是強化學習的問題,那么,我們為什么要關注強化學習呢? 簡而言之,強化學習是一個通用的決策框架。實際上我們關心的是開發一個能夠在現實世界中做出決策的代理(agent)。我們不僅想給它算法并讓它采取行動。我們還想讓代理做決策。而強化學習可以讓代理學會做決策。
- 強化學習用于具有行動能力的代理
- 每一個動作(action)都能影響代理將來的狀態(state)
- 通過一個標量的獎勵(reward)信號來衡量成功
- 目標:選擇一系列行動來最大化未來的獎勵

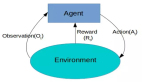
在每一個時刻 t,代理會執行一個動作 at, 收到一個觀測信號 Ot, 收到一個標量獎勵 rt。外界環境會收到一個動作 at, 發出一個觀測信號 Ot+1,發出一個獎勵信號 rt+1。
由于每個問題都有其各自不同的特點,所以,為了實現「通用」的目標,我們需要找到它們的共同點和一些規律性的東西。希望大家可以在沒有解釋的情況下理解上圖的內容。圖中的大腦是我們所說的代理,圖中的地球是代理所處的環境。任何時刻,當代理執行一個動作 at 之后,它將會收到對環境的觀測量 Ot 以及來自環境的獎勵 rt,同時,收到動作 at 之后,環境會發出下一個觀測量 Ot+1,以及獎勵 rt+1。這就引入了一個新的概念:狀態。

如上圖所示,狀態是所有經歷(experience)的總和,經歷就是上圖中的第一個序列函數。某時刻 t 的狀態 st 是該時刻以及之前所有時刻的所有觀測量、獎勵以及動作序列的函數。但是,當代理所處的環境具有一種我們所說的完全可觀測性之后,就有了上圖中的第二個狀態函數——某時刻的狀態僅僅是該時刻的觀測值 Ot 的函數,這樣一來,整個經歷似乎具備了某種類似于馬爾可夫性的性質。
然后,就有了三個新的想法:策略(policy)、價值函數(value function)和模型(model)。
、價值函數(value function)和模型(model)")
一個強化學習系統的主要組成

一個強化學習的代理可能包含一個或多個下述的組成:
- 策略:代理的行為函數
- 價值函數 (Value function):評價一個狀態或者行為的好壞及其程度
- 模型(Model):代理對環境的表征

策略指的是代理的行為,它是從狀態到行為的映射。包括確定策略和隨機策略。
- 確定策略:a =π(s)
- 隨機策略:π(a|s)= P[a|s]
1. 價值函數

價值函數是對未來獎勵的預測,表示在狀態 s 下,執行動作 a 會得到多少獎勵?
Q 價值函數表示獎勵總值的期望。表示在給定一個策略π,貼現因子γ,和狀態 s 下,執行動作 a,獲得獎勵的綜合的期望是多少?
Q 價值函數還能夠分解為上圖描述的貝爾曼方程。
貝爾曼方程,以其提出者 Richard Bellman 命名,也被稱作動態規劃方程。它是與動態規劃有關的數學優化相關的優化問題的必要條件。

優化價值函數就是使得價值函數達到可實現的最大值。以此為條件就會得到整個問題的最優解,以及相應的最優策略π*。
2. 模型:
整個模型就是從經歷中學習的過程。

由于我們已經定義了強化學習代理的三個組成部分,所以不難理解,優化其中的任何一個都會得到一個較好的結果。

有三種實現強化學習的途徑,分別基于不同的原則。即:基于價值的強化學習,基于策略的強化學習,以及基于模型的強化學習。
- 基于價值的強化學習,需要估計 Q 價值函數的最大值 Q*,這是在任意策略下能夠得到的最大 Q 價值函數。
- 基于策略的強化學習,直接搜索最佳的策略π*,這將得到能夠最大化未來獎勵的策略π*。
- 基于模型的強化學習,構建一個環境的模型,用模型進行諸如前向搜索的規劃。
四、深度強化學習(DeepReinforcement Learning)
什么是深度強化學習?簡言之,就是強化學習+深度學習。
將強化學習和深度學習結合在一起,我們尋求一個能夠解決任何人類級別任務的代理。強化學習定義了優化的目標,深度學習給出了運行機制——表征問題的方式以及解決問題的方式。強化學習+深度學習就得到了能夠解決很多復雜問題的一種能力——通用智能。
DeepMind 中深度強化學習的例子有:
- 游戲:Atari 游戲、撲克、圍棋
- 探索世界:3D 世界、迷宮
- 控制物理系統:操作、步行、游泳
- 與用戶互動:推薦、優化、個性化
那么,我們如何結合強化學習和深度學習呢?
(1)用深度神經網絡來代表價值函數
- 策略
- 模型
(2)用隨機梯度下降來優化損失函數
下面的三部分,我們分別討論三種結合強化學習和深度學習的方法。
五、基于價值的深度強化學習
基于價值的深度強化學習的基本思想就是建立一個價值函數的表示,我們稱之為 Q 函數。

其中:
- s =狀態
- a =動作
- w =權值
正如我們在上邊圖片中看到的一樣,基本上就是一個黑盒子,將狀態和動作作為輸入,并輸出 Q 和一些權值參數。
我們會用到基于 Q學習的基本方法。這種方法會想出我們需要的損失函數,而且是以貝爾曼方程作為開始的。

如上圖所示,我們等號右邊作為優化的目標。現在逐步解釋這個算法:將左側的內容移到等號右邊。
隨后我們用隨機梯度下降的方法去最小化最小均方差 (MSE),一般這個方法在優化的過程中都會奏效的。如果每一個狀態和動作都有一個單獨的值,那么在這個方法下,價值函數會收斂到一個最優值。不幸的是,由于我們使用的是神經網絡,會有兩個問題出現:
- 采樣之間的相關性:加入我是一個四處走動的機器人,通過實際數據來學習。我將算法中的每一步視為采取行動的狀態,如此一來,這些狀態和動作就會和上一次執行的動作非常接近。也就是說,我們采取的方法中存在很強的相關性。
- 我們從中學習到的目標依賴于目標本身,因此這些都是非平穩的動態。正是由于非平穩動態的存在,我們的近似函數會螺旋式失控,并且導致我們的算法崩潰。
如果我們繼續使用神經網絡,上述兩個問題是不會被解決的。
為了實現穩定的深度強化學習,我們引入的第一個方法是被稱為 DQN 的深度強化網絡。如下面的 PPT 所描述的,這在 Q 學習的基礎上引入了根本的提升。其中的思想非常簡單:通過讓代理從自己的經歷中構建數據集,消除非平穩動態中的所有相關性。然后從數據集中抽取一些經歷并進行更新。


在解釋完前面的東西之后,David Silver 給大家舉了一個他們 DeepMind 團隊的一個例子:Atari 游戲。他們訓練出了一個能夠將 Atari 游戲玩的很好的系統。相信下面的插圖能夠有助于讀者理解代理和環境(包括狀態、動作以及獎勵)之間的關系

Atari 中的 DQN
- 從狀態 s 中端對端地學習 Q 價值函數Q(s,a)。
- 輸入狀態 s 是最近 4 幀的原始像素組成的堆棧
- 輸出的 Q 價值函數 Q(s,a) 用于 18個操縱桿/按鈕的位置
- 獎勵就是每一步動作所對應的得分的變化
")
這是一個卷積神經網絡 (CNN)
網絡結構和超參數在所有的游戲中都是固定不變的。
1. 采用深度 Q 網絡的 Atari 的 Demo:
- Nature 上關于深度 Q 網絡 (DQN) 論文:http://www.nature.com/articles/nature14236
- GoogleDeep Mind 團隊深度 Q 網絡 (DQN) 源碼:http://sites.google.com/a/deepmind.com/dqn/
繼 Nature 上發表深度 Q 網絡之后,有好多關于 DQN 的改進。但 David 主要關注以下三點:

2. 雙深度 Q 網絡(Double DQN):
要理解第一個改進,我們首先必須明白 Q 學習中存在的一個問題。問題就踹 MAX 算子上。事實上那樣得到的近似值不足以做出決定,并且這個偏差可能在實際應用中導致一系列問題。因此,為了解決這個問題,我們用了兩個深度 Q 網絡把評價動作的方式分解為兩個路徑。一個深度 Q 網絡用來選擇動作,另一個用來評價動作,這在實踐中確實很有幫助。
確定優先級的經歷回放:
第二個改進就是我們做經歷回放的方式。舊方法做經歷回放的時候會給所有的經歷附一個相同的權重。然而相等的權重并不是一個好的思想,如果給所有的經歷給一個優先級,你可能做得更好一些。我們僅僅采用了以此誤差的絕對值,它表示在一個時刻的某一個特定狀態有多么好或者多么差。那些你并沒有很好的理解的經歷才是所有的經歷中你最想回放的。因為需要更多的更新來矯正你的鍵值。
3. 決斗網絡(DuelingNetwork)
第三個改進就是把Q 網絡分成兩個信道。一部分用來計算當你忽略了一些動作的時候你會得到多少獎勵(幻燈片中的action-independent),另一部分用來計算實際中當你采取了某一個特定的動作之后你會做得多么好。然后將兩個網絡的計算結果求和。然后取兩者的總和。正如前面視頻中演示的,如果你把這個結果正則化,結果會發現這兩個通道會閃爍,因為它們有不同的擴展(scaling)屬性。將兩個網絡分開,去幫助神經網絡學習更多的東西,這實際上是很有幫助的。
它們通過在Google 利用下面的結構(Gorila)來讓系統加速,這很適合海量數據。
")
Gorila 結構運行在很多不同的機器上,這讓它們可以共同運行深度 Q 網絡。我們有許多個代理并行運行的實例,有我們環境的許多不同的實例,這些環境都是基于許多不同的機器,這樣便能讓我們在力所能及的情況下生成盡可能多的經歷。
這些經歷被存放在一個分布式的經歷回放記憶(experience replay memory)中。本質上就是將所有并行的代理的經歷收集起來并且以分布式的方式存儲。我們由很多學習器能夠在這些經歷中并行采樣。一旦你有了這個經歷回放的緩存,我們可以從中讀取很多不同的東西并且將其應用于系統的更新上。然后,從那些學習器返回的參數更新將被共享到我們存儲的分布式神經網絡中,然后在實際上運行在這些機器上的每個代理共享。
那么,在沒有Google 的資源的情況下,我們如何做才能加速強化學習呢?可以使用異步強化學習:
- 利用標準 CPU 的多線程
- 將一個代理的多個實例并行執行
- 線程間共享網絡參數
- 并行地消除數據地相關性
- 經歷回放的可替代品
- 在單個機器上進行類似于 Gorila 的加速!
六、基于策略的深度強化學習
深度策略網絡

策略梯度

Actor-Critic算法

異步優勢Actor Critic 算法(A3C)
")
Labyrinth中的異步優勢Actor Critic 算法(A3C)
")
從輸入的像素中進行 softmax 策略 π(a|st) 的端到端學習。對環境的觀測量 ot 是當前幀的原始像素。狀態 st= f(o1, …, ot) 是一個循環神經網絡(LSTM)。網絡在策略π(a|s) 下同時輸出價值 V(s) 和激活函數 softmax 的結果值。任務是收集蘋果(+1 分獎勵)和逃跑(+10 分獎勵)。
1. 我們如何處理高維連續動作空間?

與深度 Q 網絡類似,我們在這里有 DPG 算法。希望你現在對深度 Q 網絡有了較好的理解,這將有助于你理解下一部分內容。
2. 確定策略梯度(DPG/DeterministicPolicy Gradient)算法
下面是 DavidSilver 關于 DPG 的論文的鏈接:
http://www.jmlr.org/proceedings/papers/v32/silver14.pdf_
深度確定策略梯度

模擬物理中的確定策略梯度算法:
在 MuJoCo 上模擬物理域
- 從原始輸入的狀態 s 中進行控制策略的端對端學習
- 輸入狀態 s 是最近 4 個幀 (4 個狀態) 的原始數據
- 對價值 Q 和策略π使用兩個分離的卷積神經網絡
- 策略π被朝著能夠最大程度提成價值 Q 的方向調節
圖為兩個分離的卷積神經網絡,分別對應 Q 價值函 Q(s,a)和策略π(s)。

然后我們來看一看其他的經典游戲,例如撲克。我們能夠使用深度強化學習的方法在多代理的游戲中找到納什均衡嗎?納什均衡就像多代理決策問題中的解決方案。在這個均衡下,每個代理都滿足它們的策略,沒人愿意偏離當前的策略。
因此,如果我們找到了納什均衡,我們就解決了這個小問題。很多研究都在關注如何在更加龐大、有趣的博弈游戲中實現這種均衡。
這里的思想是,我們首先學習一個價值 Q 網絡,然后學習一個策略網絡,然后挑選一些最佳相應和平均最佳相應之間的動作。
代理在游戲中進行虛擬自我對抗 (FSP)。
")
下面的幻燈片闡述了在德州撲克進行 FSP 的結果:隨著迭代次數的增加,不同的算法都收斂了。

3. 基于模型的深度強化學習
學習環境的模型
- Demo:Atari 的生成模型
- 復雜的誤差使規劃富有挑戰傳遞模型中的誤差會在軌跡上復合
- 規劃的軌跡會與執行的軌跡有所不同
- 在長時間的不正常軌跡結束時,獎勵是完全錯誤的
學習一個模型,即如何用深度學習完成基于模型的強化學習,并不是這個問題的難點。我們知道了如何規定學習模型的問題。事實上這不過是一個監督學習的問題罷了「如果你想預測:假設我采取了這個動作之后,環境會變成什么樣子」。在這次講座中,他沒有太多地談論這個問題,他只是展示了一個來自密歇根大學的視頻,演示你如何能夠建立一個模型,以及建立這個模型有多困難。這是該視頻的屏幕截圖:左側是預測,右側是真實情況。但是,這是很難實現的。

然而,如果我們有一個完美的模型呢?也就是說,游戲規則是已知的。是的,我們知道,AlphaGo 就是這樣的。
Nature 上關于 AlphaGo 的論文:
http://www.nature.com/articles/nature16961
AlphaGo 相關的資源: deepmind.com/research/alphago/
為什么下圍棋對于計算機而言是很困難的?
暴力搜索是很難處理的。
- 搜索空間是巨大的
- 對計算機而言,評價哪一個玩家占據上風,「幾乎是不可能的」。但是在一些諸如象棋的游戲中,就比較容易判斷了。
過去很多人都認為找到一個解決這個問題的好方法是不可能的。
DeepMind 建立了一個卷積神經網絡(CNN),這個網絡將每一個狀態(只要由棋子落下)看作一幅圖像。然后用卷積神經網絡去構造兩個不同的神經網絡。
一個代表價值網絡

另一個代表策略網絡:

為了訓練它,我們結合了監督學習和強化學習,共有三個步驟,如下所示:

經過每一步之后的表現:
每一步的表現")
每一步的表現")
每一步的表現")
價值網絡和策略網絡的效果:



七、總結
- 通用、穩定并且可拓展的強化學習現在是可能的
- 用深度網絡去代表價值、策略和模型
- 在 Atari、Labyrinth、物理、撲克、圍棋中取得了成功
- 使用一系列深度強化學習的范例
強化學習是一個受行為心理學啟發的機器學習領域。它正在變得越來越流行。在需要構建一個可以像人類一樣甚至超越人類能力去做一些事的人工智能時,它是非常有用的,比如 AlphaGo。然而,在我看來,在開始學習強化學習之前,我們首先應該理解一些基本的機器學習相關的知識。良好的數學背景將會非常有助于你的學習,并且,這至關重要!
David Silver 目前任職于 Google DeepMind 團隊。他的演講可以幫助我們獲得對強化學習(RL)和深度強化學習(Deep RL)的基本理解,這不是一件特別難的事。
【本文是51CTO專欄機構機器之心的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】