













“網(wǎng)絡爬蟲+相似矩陣”技術(shù)運作流程
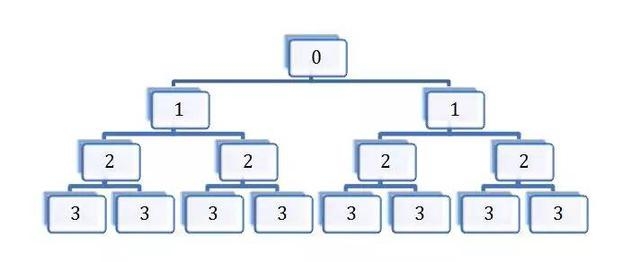
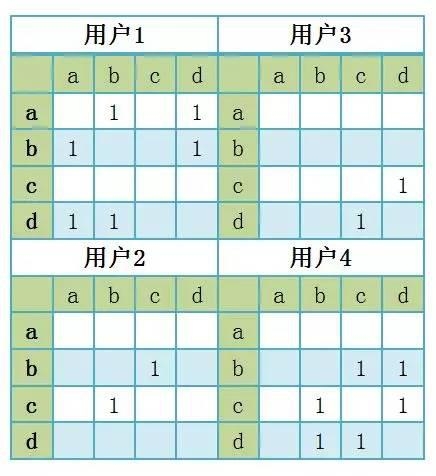
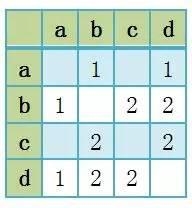
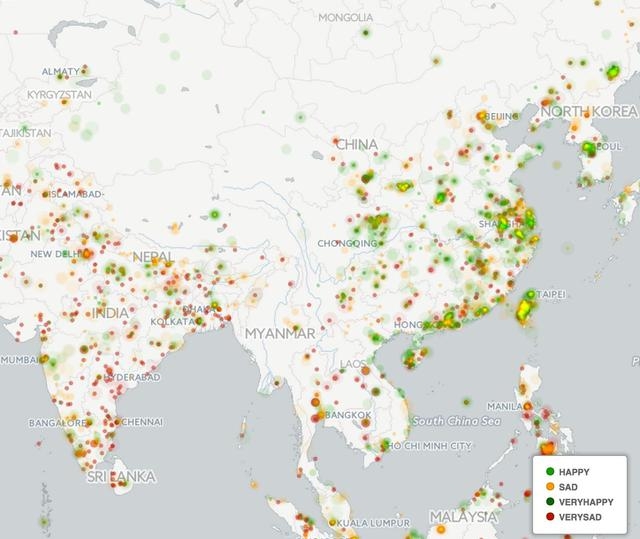
今日頭條這類資訊聚合平臺是基于數(shù)據(jù)挖掘技術(shù),篩選和推薦新聞:“它為用戶推薦有價值的、個性化的信息,提供連接人與信息的新型服務,是國內(nèi)移動互聯(lián)網(wǎng)領(lǐng)域成長最快的產(chǎn)品服務之一”。自從2012年3月創(chuàng)建以來,今日頭條至今已經(jīng)累計激活用戶3.1億,日活躍用戶超過3000萬。 本文嘗試從技術(shù)層面分析今日頭條的傳播機制和相關(guān)原理。 今日頭條是一個典型的數(shù)據(jù)新聞平臺,其新聞來源除了合作媒體之外,很大一部分來自于搜索引擎的網(wǎng)絡爬蟲。 網(wǎng)絡爬蟲是什么? STEP 1:從互聯(lián)網(wǎng)各個角落收集信息; STEP 2:將其中的新聞類信息進行匯總; STEP 3:匯總的信息經(jīng)過基于機器學習的分類和排序,劃分出每一個時刻的熱點新聞。 今日頭條作為數(shù)據(jù)新聞平臺,與一般數(shù)據(jù)新聞的區(qū)別,在于提供一個媒介平臺,展示匯總的信息,而不是一條信息。 網(wǎng)絡爬蟲的工作機制是什么? 網(wǎng)絡爬蟲的工作機制依賴于會聯(lián)網(wǎng)互聯(lián)網(wǎng)上的超鏈接網(wǎng)絡。 在互聯(lián)網(wǎng)上多數(shù)網(wǎng)頁,都有超鏈接存在。這些超鏈接將各個網(wǎng)頁鏈接起來構(gòu)成了一個龐大的網(wǎng)絡,也就是超鏈接網(wǎng)絡。爬蟲作為一種網(wǎng)絡程序從一些網(wǎng)頁出發(fā),保存網(wǎng)頁的內(nèi)容,尋找網(wǎng)頁當中的超鏈接,然后訪問這些超鏈接,并重復以上過程,這個過程可以不斷進行下去。如圖所示: “今日頭條”怎么計算:“網(wǎng)絡爬蟲+相似矩陣”技術(shù)運作流程 STEP 1:爬蟲從一個種子節(jié)點0開始爬取網(wǎng)頁內(nèi)容, STEP 2:抓取的同時發(fā)現(xiàn)兩個超鏈接,并爬取第一級節(jié)點, STEP 3:從第一級節(jié)點開始又發(fā)現(xiàn)第二級節(jié)點,這個過程不斷進行下去。 這個過程當中有兩種策略: 1、只有窮盡一個層級的所有頁面才爬取下一個層級,這種策略叫做“廣度優(yōu)先”; 2、發(fā)現(xiàn)一個超鏈接后,立刻就開始爬取這個網(wǎng)頁,并持續(xù)深入下去,這種過程叫做“深度優(yōu)先”。 補充說明: 上圖是一個樹狀網(wǎng)絡,現(xiàn)實的網(wǎng)絡不是這么簡單的,里面充滿了“回路”,即新發(fā)現(xiàn)的網(wǎng)頁里的超鏈接指向的是已經(jīng)爬取的老節(jié)點。這個時候就需要甄別那些網(wǎng)頁已經(jīng)被成功抓取。 舉個栗子—— 以今日頭條為例說明一下網(wǎng)絡爬蟲在新聞抓取中的工作流程: STEP 1:工作人員先要在后臺設置新聞來源的字典,比如“網(wǎng)易新聞”、“新浪新聞”、“鳳凰新聞”、“浙江新聞”等等, STEP 2:通過這些字典,網(wǎng)絡爬蟲將會鎖定到這些網(wǎng)站的超鏈接,從中抓取新聞。 補充說明: 如果這條新聞是在這些新聞平臺相關(guān)的博客當中的內(nèi)容,而不是新聞平臺本身的新聞,網(wǎng)絡爬蟲就抓不到了。 聚合媒體的概念并非如此簡單,除了匯聚來自不同媒體的內(nèi)容之外,聚合媒體更重要的特征是對不同信息進行分類并排序,得到一個信息匯總界面(aggregator),這種信息匯總往往表現(xiàn)為某種排行榜。這種排行榜在傳播機制上滿足網(wǎng)絡科學中所說的“優(yōu)先鏈接機制”,即用戶的注意力更傾向于投向那些排名靠前的信息,這個過程可以被經(jīng)典的傳播學發(fā)現(xiàn):“樂隊花車效應”。這個發(fā)現(xiàn)起源于美國的選舉過程。候選人會站在樂隊花車上拉選票,贊同者會站到他的車上。研究發(fā)現(xiàn),人們傾向于登上那些站滿了人的花車,而非那些只有很少人的花車。 個性化推薦在今日頭條當中發(fā)揮著重要作用。 今日頭條的用戶登錄非常人性化。作為一個后起之秀,今日頭條非常具有策略性地允許用戶使用微博、QQ等社交賬號登錄。這個過程實際上授權(quán)今日頭條挖掘個人社交網(wǎng)絡的基本信息。因而,便于獲取用戶的個性化信息,比如用戶的興趣、用戶屬性。越用越懂用戶,從而進行精準的閱讀內(nèi)容推薦。 個性化推薦的基礎是構(gòu)建推薦系統(tǒng) 推薦系統(tǒng)廣泛地應用于用戶沒有明確需求的場景。推薦系統(tǒng)就算法而言,可以分為: 社會化推薦(Social recommendation, 比如向朋友咨詢); 基于內(nèi)容的推薦(content-based filtering, 例如根據(jù)用戶觀看過的電影推薦其他與之相似的電影); 基于協(xié)同過濾的推薦(collaborative filtering,例如查看排行榜,或者找到和自己興趣相似的用戶,看看他們最近看什么電影)。 所以,可以用于構(gòu)建推薦系統(tǒng)的信息也分為三類:好友、歷史興趣、注冊信息。 推薦系統(tǒng)就是可以關(guān)聯(lián)用戶和物品的一種自動化工具。除了這些信息之外,時間、地點等信息均可加入到推薦系統(tǒng)的構(gòu)建中來。現(xiàn)在,推薦系統(tǒng)已經(jīng)廣泛地應用于新聞推薦、圖書推薦、音樂推薦、電影推薦、朋友推薦等領(lǐng)域,作為人工智能的一種形式,極大地方便了人們的生活和交往。 推薦系統(tǒng)算法的基礎就是要構(gòu)造相似性矩陣 這種相似性矩陣可以是物與物的相似性,例如書籍之間的相似性、音樂之間的相似性。以下以基于物品的協(xié)同過濾算法(item-based collaborative filtering, ItemCF)為例。基于物品的協(xié)同過濾算法可以利用用戶的歷史行為,因而可以使得推薦結(jié)果具有很強解釋性。比如,可以給喜歡讀足球新聞的用戶推薦其它相似的新聞。基于物品的協(xié)同過濾算法主要分為兩步: STEP 1:計算物品之間的相似度。 STEP 2: 根據(jù)用戶的歷史行為生成用戶的推薦列表。 假設有四個用戶: 用戶1在今日頭條的瀏覽記錄是[a、b、d], 用戶2的瀏覽記錄是[b、c], 用戶3的瀏覽記錄是[c、d], 用戶4的瀏覽記錄是[b、c、d]; 可將這四個人的瀏覽行為表達為以下四個物品矩陣: 將個體用戶的物品矩陣相加,可以匯總為所有的新聞矩陣M,M[i][j]表示新聞i和新聞j被多個人同時閱讀的次數(shù)。如下所示: 矩陣邏輯 如果兩個新聞被多個人同時瀏覽,那么可以說它們之間的相似度更高。 將以上矩陣歸一化就可以對矩陣進行操作并計算新聞之間的相似度,比如相關(guān)相似度或者余弦相似度。 基于物品間的相似性度,如果有一個新用戶進入系統(tǒng),并且他閱讀了新聞c,那么ItemCF算法可以很快給出與新聞c相似度最高的新聞(b和d),并推薦給這個新用戶。 在推薦過程中,推薦系統(tǒng)可以根據(jù)用戶的行為不斷優(yōu)化相似矩陣,使得推薦越來越準確。 或者,如果用戶可以手動對每個新聞的興趣(如喜歡或討厭)標出,就可以使得推薦更準確。 本質(zhì)上來說,上面兩個圖是熱點新聞、以及個人定制新聞的基礎原理。它分為兩步完成: STEP 1:先找出新聞之間的熱點與相似度 STEP 2:將熱點與相似度高的新聞推送給用戶。 舉個栗子—— 假設在抗戰(zhàn)勝利70周年當天,有4個人同時瀏覽今日頭條的新聞, A是女讀者,她點擊了秋季糖水制作方法、育兒應注意的五個事項、閱兵式、新型武器等新聞, B是中年上班族,他點擊了閱兵式、中國最新兵器譜等新聞, C是一位年長者,他點擊了養(yǎng)生、閱兵式、新型武器等新聞, D是一位剛畢業(yè)的男大學生,他點擊了英雄聯(lián)盟攻略、好萊塢旅行攻略、閱兵式、新型武器等新聞。 熱點和相似度的產(chǎn)生過程: STEP 1:這四個人同時點擊閱兵式和新型武器,系統(tǒng)算法就會通過點擊和停留的時間計算出閱兵式和新型武器是當天的熱點。 STEP 2:閱兵式和新型武器同時被多人點擊,代表他們之間具有相似性。 STEP 3:當新進用戶點擊新聞時,今日頭條會以最快速度分析他點擊的內(nèi)容,并在已經(jīng)排查出的熱點新聞當中尋找他所感興趣的相關(guān)內(nèi)容匹配給他,引導他閱讀熱點。 這一系列的行為都由計算機自動完成。 機制的缺陷 上面的例子說明了定制新聞以泛熱點新聞為基礎數(shù)據(jù)來完成的事實,這就出現(xiàn)一個問題,即當一個人關(guān)注的新聞不是熱點時,系統(tǒng)得不到相關(guān)的熱點,就會在該新聞當中尋找其他信息進行再匹配,這樣匹配出的新聞在現(xiàn)有信息的基礎上最大程度吻合了用戶的興趣,但未必會推送當天最熱點的新聞。要想達到這種長尾理論所設想的定制服務,關(guān)鍵是對新聞的細分。只有將不同主題細分成各種子主題,再細分下設內(nèi)容,才能達到真正的私人定制。要做到這一點,實際已經(jīng)脫離了機械,而在于人對于事物性質(zhì)的認知與把握。正如法國社會學家福柯在《知識考古學》當中的觀點,分類,是一事物區(qū)別于其他事物的根本。而分類,歸根結(jié)底是人的主觀能動性的體現(xiàn);當系統(tǒng)中累計的用戶行為越 多,這種分類越準確,自動化的私人定制也會越貼近用戶需求。 聚合媒體在國外的應用也非常廣闊。信息在聚合媒體的數(shù)據(jù)新聞平臺上的展現(xiàn),可以是傳統(tǒng)的搜索引擎的平面化展現(xiàn),也可以是可視化展現(xiàn)。后者如日本的新聞地圖網(wǎng)站(http://newsmap.jp)。日本的新聞地圖項目是基于谷歌新聞做的,它采用不同的顏色將新聞類別區(qū)分開來,如紅色代表“World”,黃色代表“National”,用戶可以通過勾選頁面底部的分類欄進行篩選,在頁面頂部可以按照國家和地區(qū)進行篩選。網(wǎng)站后臺算法依據(jù)相關(guān)新聞信息的數(shù)量、重要性、點擊量自動調(diào)整每個新聞所占面積的大小。 一個非常有意思的聚合新聞網(wǎng)站是GDELT。 GDELT項目(The GDELT Project,http://gdeltproject.org/)監(jiān)測全球100多種語言實時的廣播、印刷和網(wǎng)絡新聞,識別新聞中的人、地、組織、數(shù)量、主題、來源、情緒、時間。基于此,GDELT推出了全球新聞情緒地圖,數(shù)據(jù)每一個小時更新一次。其中綠色表示快樂,黃色表示悲傷。數(shù)據(jù)密度反映了新聞的規(guī)模,見下圖: 另外一個很好的例子是社交新聞網(wǎng)站,主要以Digg、Reddit等。這種類型的網(wǎng)站允許用戶注冊、相互關(guān)注、提交新聞并對新聞進行打分。其中,得分高的新聞就會進入到流行新聞的頁面。在這個過程當中,各個用戶充當了新聞的把關(guān)人,而這種信息把關(guān)的方式被稱之為群體把關(guān)。 但是,群體把關(guān)的意義主要在于將新聞推到流行頁面(webpage ofpopular news),也就是公眾面前。這個階段之后流行信息擴散更像是傳統(tǒng)媒體的新聞擴散方式。其實,這種基于用戶過濾的新聞聚合(news aggregation)存在非常普遍,例如新浪微博上的“熱門話題”、推特上的“趨勢性話題”(trend)等。根據(jù)筆者對Digg上新聞擴散的分析,這種新聞聚合對于信息擴散的影響更大,對于那些傳播廣泛的Digg新聞,70%以上的信息接觸是通過熱門新聞被Digg用戶看到的。 從媒體把關(guān)到群體把關(guān)是一個進步,從群體把關(guān)到計算機或算法把關(guān)則隱藏著危險。 過去由編輯所承擔的內(nèi)容揀選的工作,現(xiàn)在交給了計算機來處理。其信息把關(guān)機制發(fā)生了根本的變化。在這個過程當中,受到最大影響的是傳統(tǒng)的新聞生產(chǎn)邏輯。傳統(tǒng)的新聞觀重視公眾利益,報道具有長遠影響的事件并提供見解。將這些工作交給機器和算法將帶來前所未有的挑戰(zhàn): 首先,算法根據(jù)使用者所表現(xiàn)出來的“興趣”進行分類和推薦信息,往往容易給用戶推薦一些低質(zhì)量但用戶短期內(nèi)喜歡的信息。 其次,不斷地接觸低質(zhì)量的信息使得個體的新聞素養(yǎng)降低。過于依賴機器幫助我們進行信息把關(guān),容易導致視角越來越局限,不再關(guān)注社會整體利益,容易走向犬儒主義。 再次,主流的新聞操作手法保障了新聞從業(yè)者面對政治、軍事和社會力量時的獨立和從容。而推薦算法從信息和用戶出發(fā),對于國家和社會整體的關(guān)注不夠,這種新聞推送機制的偏向容易帶來攻訐。 從未來新聞的視角來思考新聞行業(yè)的轉(zhuǎn)型更加使得我們意識到回歸新聞本質(zhì)的重要性。 未來的新聞行業(yè)不僅僅是提供有限的案例訪談,而是系統(tǒng)地獲取、積累并分析數(shù)據(jù),并挖掘隱含其中的信息。在注意力經(jīng)濟的時代,向用戶提供這種專業(yè)化的信息、專 業(yè)化的評論才是媒體的責任。目前迅速崛起的數(shù)據(jù)新聞正在走向這個方向,只不過在現(xiàn)階段更注重可視化表達。聚合媒體將信息過濾自動化,體現(xiàn)了未來新聞的特 點。基于個性化的推薦,聚合媒體將人工智能的新聞整合功能進一步帶進我們的生活,提供了很多便利。但是,不應該忽略的是,要警惕太依賴機器和算法所潛藏的 危險:算法或計算機把關(guān)有損新聞價值取向。 未來的新聞業(yè),走向人機結(jié)合的時代。
網(wǎng)絡爬蟲:抓取新聞的基本技術(shù)
推薦系統(tǒng):個性化定制新聞的技術(shù)邏輯
聚合媒體:一種國際新聞界的潮流
主流新聞觀與人工智能
未來新聞業(yè)走向人機結(jié)合時代


















