













英特爾至強(qiáng)Sandy Bridge首測(cè)(圖)
前不久,英特爾對(duì)外發(fā)布了最新的基于Sandy Bridge微架構(gòu)的32nm至強(qiáng)處理器——E3系列。雖然這并非是英特爾第一次發(fā)布基于Sandy Bridge微架構(gòu)的產(chǎn)品,雖然E3僅僅面向單路應(yīng)用而生,但不管怎么說(shuō),E3的出現(xiàn)的確標(biāo)志著英特爾在至強(qiáng)處理器發(fā)展中邁出了重要的一步,也是Tick-Tock戰(zhàn)略中重要的內(nèi)容(Tock)。

英特爾發(fā)布Sandy Bridge微架構(gòu)32nm至強(qiáng)處理器
得益于桌面級(jí)Sandy Bridge處理器的成功,許多人對(duì)于至強(qiáng)Sandy Brideg處理器也充滿了期待。雖然對(duì)于至強(qiáng)處理器應(yīng)用的服務(wù)器環(huán)境來(lái)說(shuō),多媒體性能并非是人們應(yīng)該關(guān)注的內(nèi)容。而每當(dāng)提到Sandy Bridge的技術(shù)特點(diǎn)——環(huán)形總線、AVX指令集、Turbo Boost2等內(nèi)容都是眾多報(bào)道中頻繁出現(xiàn)的內(nèi)容。究竟這些技術(shù)為我們帶來(lái)了什么?它們的存在會(huì)有哪些的好處。這些還要從Sandy Brideg之前的Nehalem開(kāi)始說(shuō)起。
#p#
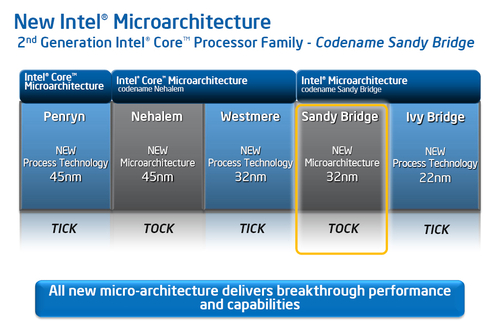
按照英特爾著名的時(shí)鐘規(guī)律——Tick-Tock來(lái)看,Sandy Bridge明顯屬于后者,也就是Tock范疇。Tock主要是指處理器微架構(gòu)方面的改變,而核心工藝的上一次升級(jí)已經(jīng)由我們熟悉的Westmere完成了,下一次22nm的升級(jí)還要再等等才行。
在進(jìn)行系統(tǒng)的分析之前,我們先來(lái)看看最新的至強(qiáng)Sandy Bridge處理器路線圖。相比以往的產(chǎn)品來(lái)說(shuō),Sandy Bridge至強(qiáng)處理器采用了與桌面級(jí)酷睿處理器類(lèi)似的命名規(guī)范,分為E3、E5和E7三個(gè)系列。其中,E3系列是面向入門(mén)級(jí)單路服務(wù)器的產(chǎn)品,E5系列則面對(duì)了主流的雙路服務(wù)器平臺(tái)。唯一有特點(diǎn)的是E7,這款產(chǎn)品雖然在型號(hào)上采用了新的命名規(guī)則,但是在本質(zhì)上E7還是上一代架構(gòu)的產(chǎn)品,它還有一個(gè)大家非常熟悉的名字——Westmere-EX 。
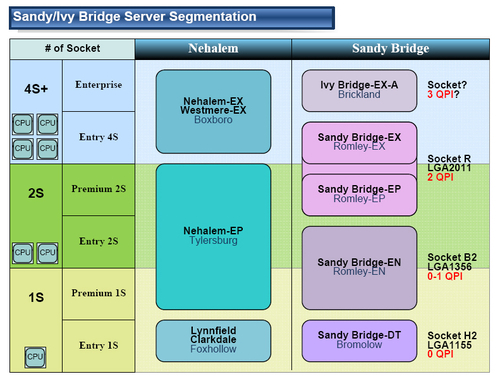
至強(qiáng)處理器路線圖
本次我們要介紹的至強(qiáng)E3系列屬于面向單路服務(wù)器應(yīng)用的產(chǎn)品,使用的是LGA115接口,也就是圖中的Sandy Bridge-DT。按照產(chǎn)品布局分析,Sandy Bridge-DT主要定位在入門(mén)級(jí)的單路服務(wù)器,雖然同樣是單路,但是高端應(yīng)用的任務(wù)則是由Sandy Bridge-EN來(lái)承擔(dān)。
#p#
正如我們剛才提到的,新一代的至強(qiáng)Sandy Bridge處理器給我們帶來(lái)的一個(gè)印象就是采用了環(huán)形總線架構(gòu),這也是英特爾在繼Nehalem和Westmere之后繼續(xù)使用環(huán)形總線的架構(gòu)。
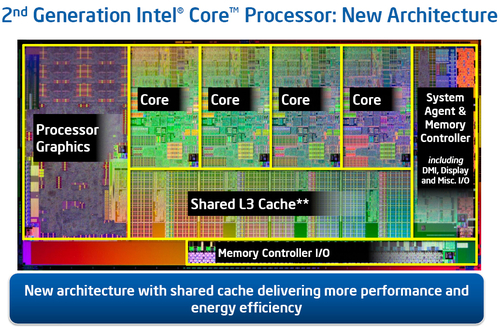
Sandy Bridge核外架構(gòu)圖
Sandy Bridge處理器使用了新的環(huán)形總線設(shè)計(jì)。事實(shí)上從之前的Nehalem開(kāi)始,英特爾就轉(zhuǎn)向了融合核心的理念。在Nehalem當(dāng)中,英特爾將內(nèi)存控制器融入其中,而在接下來(lái)的Westmere當(dāng)中,GPU也作為融入的對(duì)象而出現(xiàn)(只是那時(shí)候的GPU還僅僅使用的是45nm工藝)。在之前的8核心Nehalem-EX上,我們就看到了環(huán)形總線的身影,不過(guò)當(dāng)時(shí)的產(chǎn)品在性能和功耗上并沒(méi)有表現(xiàn)出明顯的優(yōu)勢(shì)。
本次Sandy Bridge使用的是重新設(shè)計(jì)的核外結(jié)構(gòu),全新的Ring Bus環(huán)形總線更能夠較好的展示出Sandy Bridge的真實(shí)性能。通過(guò)上圖大家可以看到,Ring Bus環(huán)形總線連接各個(gè)CPU核心、LLC緩存(L3緩存)、融合進(jìn)去的GPU以及System Agent(系統(tǒng)北橋)等部分。
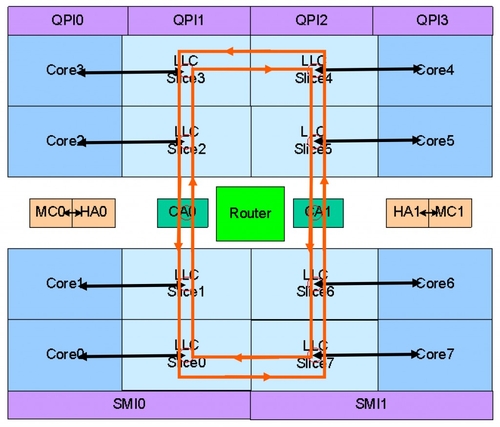
這個(gè)圖片或許可以更好的說(shuō)明問(wèn)題。新的Ring Bus環(huán)形總線由四條獨(dú)立的環(huán)組成,分別是數(shù)據(jù)環(huán)Data Ring、請(qǐng)求環(huán)Request Ring、響應(yīng)環(huán)Acknowledge Ring和偵聽(tīng)環(huán)Snoop Ring。借助于環(huán)形總線,CPU與GPU可以共享LLC緩存,將大幅度提升GPU性能。
在這個(gè)環(huán)形總線上,分布著多個(gè)Ring Stop,也就是俗稱的“站臺(tái)”。這個(gè)“站臺(tái)”在每個(gè)CPU/LLC塊上具有兩個(gè)連接點(diǎn),而之前使用環(huán)形總線的產(chǎn)品,也就是Nehalem-EX環(huán)在每個(gè)CPU/LLC塊上只有一個(gè)連接點(diǎn)。
環(huán)形總線的存在,可以大大減少核心訪問(wèn)三級(jí)緩存的周期。在以往的產(chǎn)品中,多個(gè)核心共享一個(gè)三級(jí)緩存,需要訪問(wèn)的話必須先經(jīng)過(guò)流水線發(fā)送請(qǐng)求,在進(jìn)行優(yōu)先級(jí)排序之后才能進(jìn)行。新的環(huán)形總線將三級(jí)緩存分割成了若干部分,借助于每個(gè)站臺(tái),核心可以快速的訪問(wèn)LLC。LLC小容量緩存的延遲優(yōu)勢(shì)與核心頻率一致性在這里也就體現(xiàn)了出來(lái),這就使得Sandy Bridge的周期相比以往產(chǎn)品有所縮減,從原來(lái)的35-40個(gè)縮減到了26-31個(gè)。同時(shí),由于每個(gè)核心與LLC之間可以提供若干帶寬,使得Sandy Bridge的整體帶寬也提升了4倍。
#p#
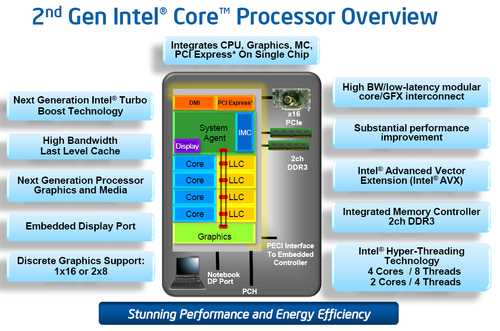
在Sandy Bridge處理器中,英特爾使用了一個(gè)全新的概念——System Agent(系統(tǒng)助手)。事實(shí)上,System Agent也就是我們之前所說(shuō)的核外架構(gòu),只是英特爾本次給予了其全新的命名,而在以往的名稱中,我們親切的稱之為系統(tǒng)北橋。
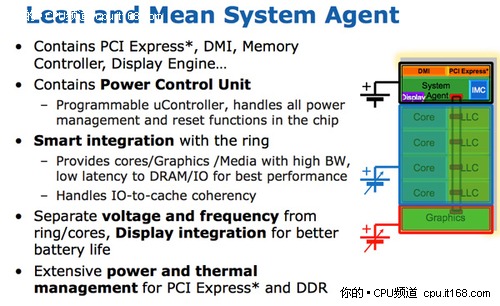
系統(tǒng)助手
System Agent包含了比以往產(chǎn)品更為豐富的功能,包括整合內(nèi)存控制器、支持16條PCIE2.0通道的PCIE控制器、圖形處理器(GPU)、電源控制單元(PCU)以及DMI總線的IO接口。
PCI-E控制器,可提供16條PCI-E 2.0信道,支持單條PCI-E x16或者兩條PCI-E x8插槽;
重新設(shè)計(jì)的雙通道DDR3內(nèi)存控制器,內(nèi)存延遲也恢復(fù)了正常水平(Westmere將內(nèi)存控制器移出CPU、放到了GPU上);
此外還有DMI總線接口、顯示引擎、電源控制單元(PCU)。
系統(tǒng)助手的頻率要低于其他部分,有自己獨(dú)立的電源層。
#p#
在Sandy Bridge處理器中,最大的改進(jìn)要算是增加了全新的AVX指令集——Advanced Vector Extensions,高級(jí)矢量擴(kuò)展。這個(gè)指令集的增加是X86處理器中的重要內(nèi)容,不僅僅是提供了更為良好的性能,同時(shí)也是對(duì)現(xiàn)有指令集的整合與優(yōu)化。

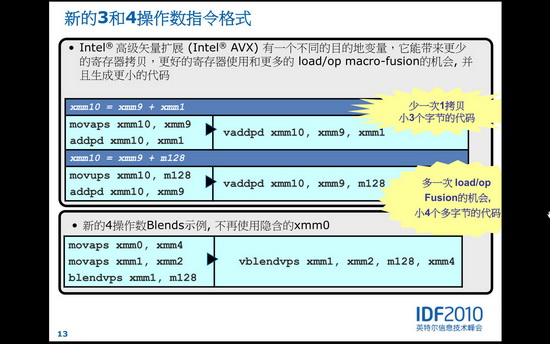
介紹AVX指令集之前,先要引入一個(gè)向量的概念。所謂向量,就是多個(gè)標(biāo)量的組合,通常意味著SIMD(單指令多數(shù)據(jù)),就是一個(gè)指令同時(shí)對(duì)多個(gè)數(shù)據(jù)進(jìn)行處理,達(dá)到很大的吞吐量。早在1996年,英特爾就在X86架構(gòu)上應(yīng)用了MMX(多媒體擴(kuò)展)指令集,那時(shí)候還僅僅是64位向量。到了1999年,SSE(流式SIMD擴(kuò)展)指令集出現(xiàn)了,這時(shí)候的向量提升到了128位。

如今,Sandy Bridge的AVX將向量化寬度擴(kuò)展到了256位,原有的16個(gè)128位XMM寄存器擴(kuò)充為256位的YMM寄存器,可以同時(shí)處理8個(gè)單精度浮點(diǎn)數(shù)和4個(gè)雙精度浮點(diǎn)數(shù)。換句話說(shuō),Sandy Bridge的浮點(diǎn)吞吐能力可以達(dá)到前代的兩倍。不過(guò)現(xiàn)在,AVX的256位向量還僅僅能夠支持浮點(diǎn)運(yùn)算。不過(guò)AVX的特別之處在于,它可以應(yīng)用128位的SIMD整數(shù)和SIMD浮點(diǎn)路徑。

#p#
既然我們一直在討論Sandy Bridge核心,那么不談到其特色的整合GPU顯然是不合適的,雖然對(duì)于服務(wù)器的應(yīng)用來(lái)說(shuō)多媒體性能的確是無(wú)足輕重。其實(shí)我們?cè)谖恼伦畛蹙吞岬竭^(guò),作為T(mén)ioc-Tock時(shí)鐘式的重要內(nèi)容,其實(shí)從Wesrtmere 32nm處理器開(kāi)始,英特爾就在處理器中整合了GPU,不過(guò)僅僅是將二者封裝在一個(gè)Die上。因?yàn)?5nm的GPU與32nm的CPU在制程上不一致,最重要的是關(guān)鍵的內(nèi)存控制器被放在了45nm的GPU當(dāng)中,造成了32nm Westmere性能并沒(méi)有想象的那么出色。而在Tock中,Sandy Bridge的出現(xiàn)解決了這一問(wèn)題,特別是將GPU整合在了環(huán)形總線之內(nèi),實(shí)現(xiàn)了二者真正的融合。
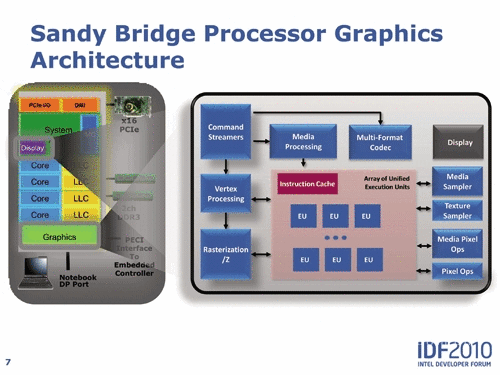
SandyBridge GPU有自己的電源島和時(shí)鐘域,也支持Turbo Boost技術(shù),可以獨(dú)立加速或降頻,并共享三級(jí)緩存。顯卡驅(qū)動(dòng)會(huì)控制訪問(wèn)三級(jí)緩存的權(quán)限,甚至可以限制GPU使用多少緩存。將圖形數(shù)據(jù)放在緩存里就不用繞道去遙遠(yuǎn)而“緩慢”的內(nèi)存了,這對(duì)提升性能、降低功耗都大有裨益。
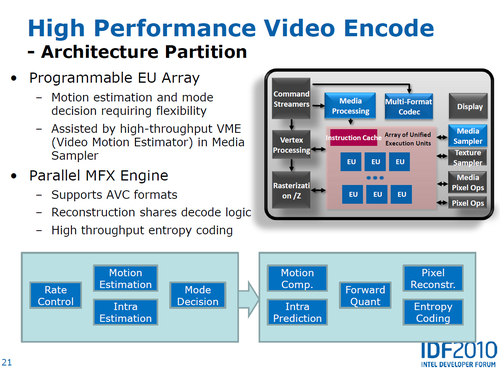
可編程著色硬件被稱為EU,包含著色器、核心、執(zhí)行單元等,可以從多個(gè)線程雙發(fā)射時(shí)取指令。內(nèi)部ISA映射和絕大多數(shù)DX10.1 API指令一一對(duì)應(yīng),架構(gòu)很像CISC,結(jié)果就是有效擴(kuò)大了EU的寬度,IPC也顯著提升。抽象數(shù)學(xué)運(yùn)算由EU內(nèi)的硬件負(fù)責(zé),性能得以同步提高。
英特爾此前的圖形架構(gòu)中,寄存器文件都是即時(shí)重新分配的。如果一個(gè)線程需要的寄存器較少,剩余寄存器就會(huì)分配給其他線程。這樣雖能節(jié)省核心面積,但也會(huì)限制性能,很多時(shí)候線程可能會(huì)面臨沒(méi)有寄存器可用的尷尬。在芯片組集成時(shí)代,每個(gè)線程平均64個(gè)寄存器,Westmere HD Graphics提高到平均80個(gè),Sandybridge則每個(gè)線程固定為120個(gè)。
#p#
好了,介紹了這么多,終于輪到我們本次評(píng)測(cè)的主角——至強(qiáng)E3系列登場(chǎng)了。關(guān)于至強(qiáng)E3系列,一共有7款產(chǎn)品,其中兩款為超低功耗版的產(chǎn)品。它們的主頻最低為2.2GHz,最高為2.5GHz。
本次我們拿到的測(cè)試產(chǎn)品是E3系列中的E3-1275和E3-1220。前者是E3系列中的高端產(chǎn)品,主頻為3.4GHz,支持超線程技術(shù),TDP為80W;后者是E3系列標(biāo)準(zhǔn)版中的最低規(guī)格,主頻僅為3.1GHz,不支持超線程技術(shù)。其中,整合GPU的處理器命名統(tǒng)一以5結(jié)尾。

至強(qiáng)E3-1220處理器

至強(qiáng)E3-1275處理器


LGA1155接口處理器
至強(qiáng)E3系列處理器采用的是LGA1155接口,從處理器的背面來(lái)看其布局與LGA1156有非常大的區(qū)別,也就是說(shuō)用戶不可能直接從LGA1156平滑升級(jí)到LGA1155處理器,必須要更換平臺(tái)。
對(duì)于桌面級(jí)的Sandy Bridge處理器來(lái)說(shuō),6系列芯片組,包括P67和H67都是比較好的選擇。而在本次測(cè)試中,由于我們暫未難道應(yīng)用于E3系列處理器的主板,因此在測(cè)試中我們只能選擇P67芯片組進(jìn)行。這次,我們將針對(duì)高端的E3-1270處理器進(jìn)行測(cè)試。
#p#
對(duì)于至強(qiáng)E3-1270處理器的測(cè)試,我們搭建了一套專門(mén)的平臺(tái),具體配置如下:
|
平臺(tái)信息服務(wù)器
|
|
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275處理器 |
| 平臺(tái)類(lèi)型 | 英特爾 P67芯片組 |
| 處理器子系統(tǒng) | |
|---|---|
| 處理器型號(hào) | 英特爾 Xeon E3-1275 |
| 處理器架構(gòu) | 英特爾 32nm Sandy Bridge |
| 代號(hào) | Sandy Bridge |
| 處理器封裝 | Socket 1155 LGA |
| 核心/線程數(shù)量 | 4/8 |
| 主頻 | 3.4GHz |
| 處理器指令集 |
MMX,SSE,SSE2,SSE3, |
| 外部總線 | 2×QPI 2933MHz 6.40GT/s 單向12.8GB/s(QPI) 雙向25.6GB/s(QPI) |
| L1 Code Cache | 4× 32KB 8路集合關(guān)聯(lián) |
| L1 Data Cache | 4× 32KB 4路集合關(guān)聯(lián) |
| L2 Cache | 4× 256KB 8路集合關(guān)聯(lián) |
| L3 Cache | 8MB 16路集合關(guān)聯(lián) |
| 服務(wù)器主板 | |
| 主板型號(hào) | 英特爾 DP67BG |
| 主板芯片組 | 英特爾 P67 |
| 北橋芯片特性 | 2×QPI VT-d Gen 2 |
| 內(nèi)存子系統(tǒng) | |
| 內(nèi)存控制器 | 每CPU集成雙通道R-ECC DDR3 1333 |
| 內(nèi)存類(lèi)型 | 2GB R-ECC DDR3 1333 SDRAM ×4條 |
| 存儲(chǔ)子系統(tǒng) | |
| 磁盤(pán)控制器 | 英特爾 ICH10R SATA AHCI Controller |
| 磁盤(pán)控制器規(guī)格 | 4x SATA 3Gb/s+2x SATA 6Gb/s AHCI w/ NCQ RAID 0/1/10 |
| 控制器驅(qū)動(dòng) | 英特爾 Matrix Storage Manager 8.8.0.1009 |
| 硬盤(pán)型號(hào)數(shù)量 | Seagate Barracuda 7200.12 ST3250318AS |
| 硬盤(pán)規(guī)格 | 7200RPM 500GB SATA 3Gb/s NCQ 16MB Cache |
| 網(wǎng)絡(luò)連通性 | |
| 網(wǎng)卡控制器 | 英特爾 82576EB Port Gigabit Network Controller |
| 網(wǎng)卡驅(qū)動(dòng) | 英特爾 PRO Set 15.8.76.0 |
| 軟件環(huán)境 | |
| 操作系統(tǒng) | Windows Server 2008 R2 Enterprise Edition SP1 x64 |
本次我們?yōu)檫@款平臺(tái)搭配的是Windows Server 2008 R2操作系統(tǒng),而且還增加了SP1補(bǔ)丁。剛剛我們?cè)诮榻BAVX指令集的時(shí)候提到,這個(gè)指令集在SP1版本下有比較好的表現(xiàn),因此我們特別安裝了SP1補(bǔ)丁。平臺(tái)方面,P67平臺(tái)是當(dāng)下我們的無(wú)奈選擇,好在這個(gè)是英特爾原廠的主板,還算是比較搭配。出于測(cè)試SPEC CPU 2006的考慮,我們?yōu)槠脚_(tái)搭配了4條宇瞻 DDR3 1333內(nèi)存,這樣系統(tǒng)的內(nèi)存容量達(dá)到了16GB。
#p#
對(duì)于服務(wù)器性能方面的考察,我們主要分為子系統(tǒng)測(cè)試和應(yīng)用性能測(cè)試。在子系統(tǒng)測(cè)試中我們按處理器、內(nèi)存以及磁盤(pán)等各個(gè)子系統(tǒng)進(jìn)行了分項(xiàng)測(cè)試,當(dāng)然各子系統(tǒng)的測(cè)試成績(jī)也是相輔相成,也需要其它子系統(tǒng)的支持,并非是完全獨(dú)立的,只是對(duì)考察的子系統(tǒng)有所偏重而已。
處理器子系統(tǒng)測(cè)試
對(duì)服務(wù)器處理器子系統(tǒng)的考察,我們主要采用的是業(yè)界公認(rèn)的SPEC CPU 2006測(cè)試,該項(xiàng)測(cè)試通過(guò)對(duì)數(shù)十個(gè)典型應(yīng)用程序的運(yùn)行,來(lái)測(cè)試系統(tǒng)處理器子系統(tǒng)在應(yīng)用中的整、浮點(diǎn)運(yùn)算效率。SPEC CPU 2006測(cè)試具有很好的開(kāi)放性,因此在業(yè)界為廣大用戶所接受,可以利用這一公開(kāi)的測(cè)試結(jié)果進(jìn)行系統(tǒng)間運(yùn)算性能的比較。
此外SiSoftware Sandra也有測(cè)試子項(xiàng)可用于處理器運(yùn)算性能測(cè)試,其結(jié)果通常以每秒完成的指令數(shù)來(lái)表現(xiàn)。也可以用作不同處理器間運(yùn)算效率的比較。
SPEC CPU 2006 v1.1
SPEC是標(biāo)準(zhǔn)性能評(píng)估公司(Standard Performance Evaluation Corporation)的簡(jiǎn)稱。SPEC是由計(jì)算機(jī)廠商、系統(tǒng)集成商、大學(xué)、研究機(jī)構(gòu)、咨詢等多家公司組成的非營(yíng)利性組織,這個(gè)組織的目標(biāo)是建立、維護(hù)一套用于評(píng)估計(jì)算機(jī)系統(tǒng)的標(biāo)準(zhǔn)。
SPEC CPU 2006是SPEC組織推出的CPU子系統(tǒng)評(píng)估軟件最新版,我們之前使用的是SPEC CPU 2000。和上一個(gè)版本一樣,SPEC CPU 2006包括了CINT2006和CFP2006兩個(gè)子項(xiàng)目,前者用于測(cè)量和對(duì)比整數(shù)性能,后者則用于測(cè)量和對(duì)比浮點(diǎn)性能,SPEC CPU 2006中對(duì)SPEC CPU 2000中的一些測(cè)試進(jìn)行了升級(jí),并拋棄/加入了一些測(cè)試,因此兩個(gè)版本測(cè)試得分并沒(méi)有可比較性。
SPEC CPU測(cè)試中,測(cè)試系統(tǒng)的處理器、內(nèi)存子系統(tǒng)和使用到的編譯器(SPEC CPU提供的是源代碼,并且允許測(cè)試用戶進(jìn)行一定的編譯優(yōu)化)都會(huì)影響最終的測(cè)試性能,而I/O(磁盤(pán))、網(wǎng)絡(luò)、操作系統(tǒng)和圖形子系統(tǒng)對(duì)于SPEC CPU2006的影響非常的小。
SPECfp測(cè)試過(guò)程中同時(shí)執(zhí)行多個(gè)實(shí)例(instance),測(cè)量系統(tǒng)執(zhí)行計(jì)算密集型浮點(diǎn)操作的能力,比如CAD/CAM、科學(xué)計(jì)算等方面應(yīng)用可以參考這個(gè)結(jié)果。SPECint測(cè)試過(guò)程中同時(shí)執(zhí)行多個(gè)實(shí)例(instances),然后測(cè)試系統(tǒng)同時(shí)執(zhí)行多個(gè)計(jì)算密集型整數(shù)操作的能力,可以很好的反映諸如數(shù)據(jù)庫(kù)服務(wù)器、電子郵件服務(wù)器和Web服務(wù)器等基于整數(shù)應(yīng)用的多處理器系統(tǒng)的性能。
我們?cè)诒粶y(cè)服務(wù)器中安裝了英特爾 C++ 11.1.034 Compiler、英特爾 Fortran 11.1.034 Compiler這兩款SPEC CPU 2006必需的編譯器,通過(guò)最新出現(xiàn)的QxS編譯參數(shù),英特爾 Compiler 10版本開(kāi)始支持對(duì)英特爾 SSE4指令集進(jìn)行優(yōu)化(假如只支持SSE3,則使用QxT編譯參數(shù))。我們另外安裝了Microsoft Visual Studio 2003 SP1提供必要的庫(kù)文件。按照SPEC的要求我們根據(jù)自己的情況編輯了新的Config文件,使用了較多的編譯選項(xiàng)。我們根據(jù)被測(cè)系統(tǒng)選擇實(shí)際可同時(shí)處理的線程數(shù)量,最后得到SPEC rate base測(cè)試結(jié)果(基于base標(biāo)準(zhǔn)編譯,SPEC base rate測(cè)試代表系統(tǒng)同時(shí)處理多個(gè)任務(wù)的能力)。
和其它測(cè)試部件不同,SPEC CPU 2006需要大量的系統(tǒng)物理內(nèi)存,我們的SPEC測(cè)試在64位的Windows Server 2008 R2 下完成,對(duì)于每個(gè)運(yùn)算核心,最低配置1.5GB內(nèi)存。
內(nèi)存子系統(tǒng)測(cè)試
對(duì)于內(nèi)存子系統(tǒng)的考察,也是利用SiSoftware Sandra來(lái)實(shí)現(xiàn),在該軟件中有相應(yīng)組件可進(jìn)行內(nèi)存帶寬、內(nèi)存延遲等方面的測(cè)試。
SiSoftware Sandra v2011
SiSoftware Sandra是一款可運(yùn)行在32bit和64bit Windows操作系統(tǒng)上的分析軟件,這款軟件可以對(duì)于系統(tǒng)進(jìn)行方便、快捷的基準(zhǔn)測(cè)試,還可以用于查看系統(tǒng)的軟件、硬件等信息。從2007開(kāi)始,Sandra的Arithmetic benchmarks增加了對(duì)SSE3&SSE4 SSE4的支持,在Multi-Media benchmark中增加了對(duì)于SSE4的支持,另外還升級(jí)了File System benchmark和Removable Storage benchmark兩個(gè)子項(xiàng)目。對(duì)于新的硬件的支持當(dāng)然也是該軟件每次升級(jí)的重要內(nèi)容之一,SiSoftware Sandra 2010對(duì)NUMA架構(gòu)以及最新的Windows 7/Windows Server 2008 R2提供了更好的支持,此外測(cè)試項(xiàng)目和測(cè)試結(jié)果也有了略微的變化。SiSoftware Sandra所有的基準(zhǔn)測(cè)試都針對(duì)SMP和SMT進(jìn)行了優(yōu)化,最高可支持32/64路平臺(tái)。
#p#
激動(dòng)人心的時(shí)刻終于到來(lái)了。對(duì)于一款處理器來(lái)說(shuō),許多人都喜歡使用CPU-Z來(lái)觀察它的規(guī)格。下面我們就一起來(lái)看看至強(qiáng)Sandy Bridge處理器給我們帶來(lái)了什么。
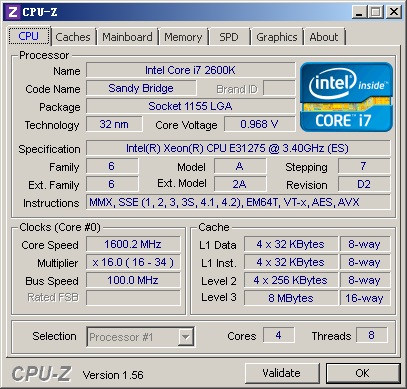
因?yàn)闇y(cè)試處理器為ES版,所以依然識(shí)別為Core i7處理器,不過(guò)下面一行倒是看得很清楚——E3 1275
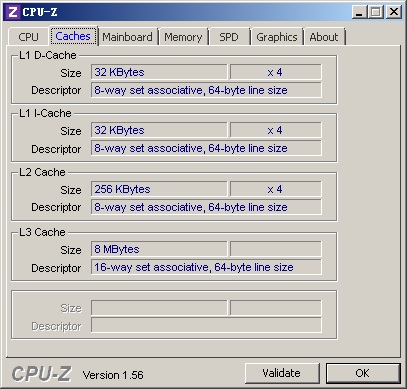
8MB三級(jí)緩存,由4個(gè)核心共享,每核心分配2MB
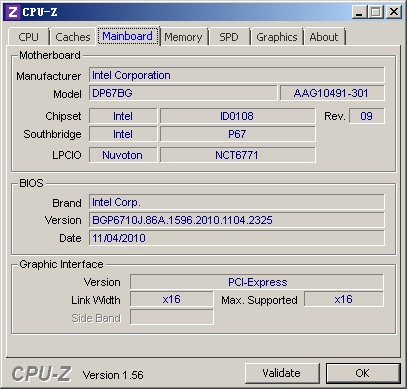
測(cè)試主板使用的是P67芯片組
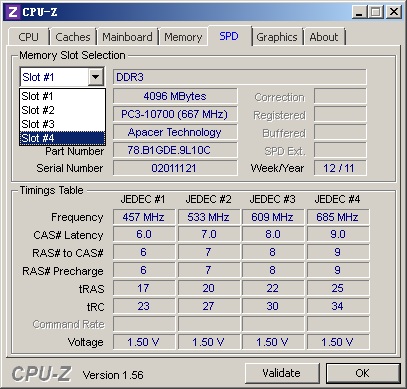
我們使用了4條宇瞻4GB DDR3 1333內(nèi)存,系統(tǒng)總內(nèi)存容量為16GB
#p#
AIDA64(原EVEREST)是一個(gè)測(cè)試軟硬件系統(tǒng)信息的工具,它可以詳細(xì)的顯示出PC硬件每一個(gè)方面的信息。支持上千種(3400+)主板,支持上百種(360+)顯卡,支持對(duì)并口/串口/USB這些PNP設(shè)備的檢測(cè),支持對(duì)各式各樣的處理器的偵測(cè)。支持查看遠(yuǎn)程系統(tǒng)信息和管理,結(jié)果導(dǎo)出為HTML、XML功能。
之前這款軟件命名為AIDA32,后改名為EVEREST,現(xiàn)在又改名為AIDA64,真是夠折騰的。

E3-1275支持超線程技術(shù),我們可以看到完整的8個(gè)線程
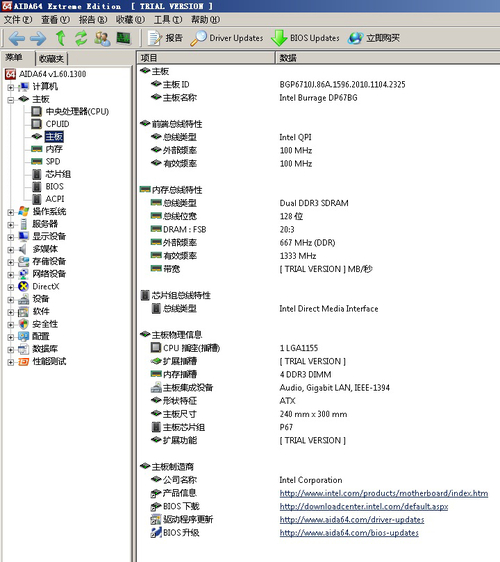
P67主板僅能夠支持雙通道內(nèi)存,不過(guò)我們剛剛在介紹System Agent的說(shuō)過(guò),這個(gè)雙通道是經(jīng)過(guò)重新設(shè)計(jì)的
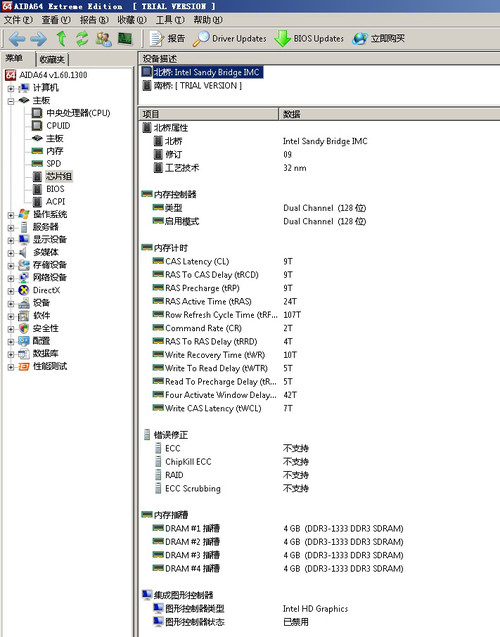
系統(tǒng)北橋?qū)嶋H上就是System Agent,因?yàn)槲覀兪褂玫氖荘67而非H67,所以顯示自帶的GPU已禁用
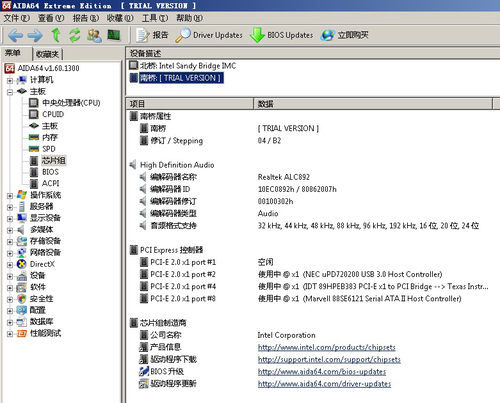
主板南橋信息
#p#
SPEC CPU 2006的浮點(diǎn)運(yùn)算測(cè)試包括的全部都是科學(xué)運(yùn)算,科學(xué)運(yùn)算需要用到大量的高精度浮點(diǎn)數(shù)據(jù),如410.bwaves 流體力學(xué)、416.gamess 量子化學(xué)、433.milc 量子力學(xué)、434.zeusmp 物理:計(jì)算流體力學(xué)、435.gromacs 生物化學(xué)/分子力學(xué)、436.cactusADM 物理:廣義相對(duì)論、437.leslie3d 流體力學(xué)、444.namd 生物/分子、447.dealII 有限元分析、450.soplex 線形編程、優(yōu)化、453.povray 影像光線追蹤、454.calculix 結(jié)構(gòu)力學(xué)、459.GemsFDTD 計(jì)算電磁學(xué)、465.tonto 量子化學(xué)、470.lbm 流體力學(xué)、481.wrf 天氣預(yù)報(bào)、482.sphinx3 語(yǔ)音識(shí)別共17項(xiàng)測(cè)試。
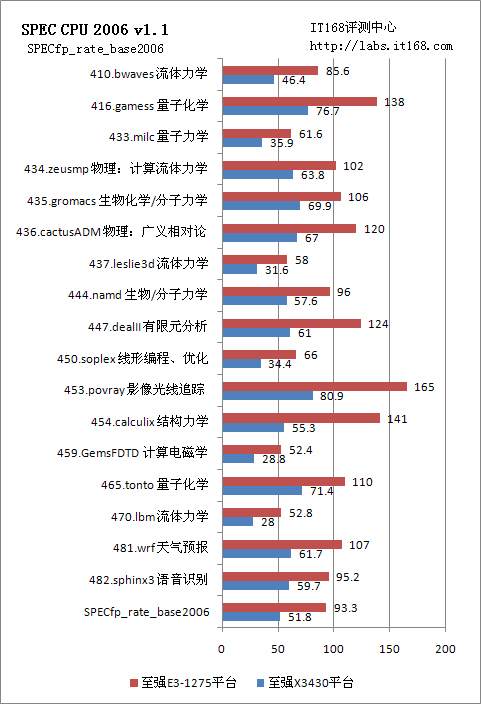
首先我們看到的是浮點(diǎn)預(yù)算的測(cè)試成績(jī),我們采用的對(duì)比處理器為至強(qiáng)X3430。至強(qiáng)X3430是上一代的單路服務(wù)器產(chǎn)品,采用45nm工藝,其主頻為2.4GHz,4核心4線程。從這個(gè)測(cè)試結(jié)果來(lái)看,E3-1275大幅度領(lǐng)先于對(duì)比產(chǎn)品,許多項(xiàng)目的性能提升在一倍以上。
這個(gè)原因是多方面的。首先從主頻上來(lái)看,E3-1275相比X3430提升了1GHz的主頻,差距很明顯;其次是超線程的應(yīng)用,8線程相比4線程也提升了一倍;第三是處理器微架構(gòu)的差別,包括整體的設(shè)計(jì)及制造工藝。因此,至強(qiáng)E3-1275的明顯優(yōu)勢(shì)也就沒(méi)什么好奇怪的了。
#p#
SPEC CPU 2006整數(shù)運(yùn)算主要包含編譯、壓縮、人工智能、視頻壓縮轉(zhuǎn)換、XML處理等,此外,各種日常操作也主要是基于整數(shù)操作。SPEC CPU 2006的整數(shù)運(yùn)算包含了400.perlbench PERL編程語(yǔ)言、401.bzip2 壓縮、403.gcc C編譯器、429.mcf 組合優(yōu)化、445.gobmk 人工智能:圍棋、456.hmmer 基因序列搜索、458.sjeng 人工智能:國(guó)際象棋、462.libquantum 物理:量子計(jì)算、464.h264ref 視頻壓縮、471.omnetpp 離散事件仿真、473.astar 尋路算法、483.xalancbmk XML處理共12項(xiàng)。
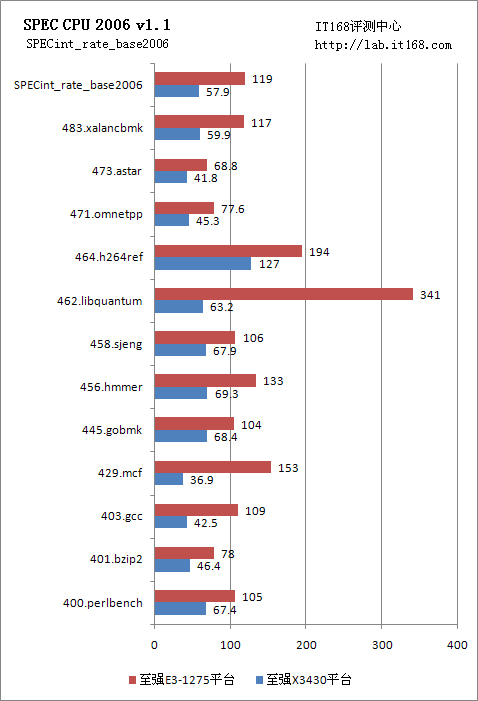
剛才我們說(shuō)過(guò)了E3-1275在硬件規(guī)格及軟件設(shè)計(jì)上的三點(diǎn)優(yōu)勢(shì),這些優(yōu)勢(shì)在整數(shù)運(yùn)算中表現(xiàn)更為明顯,部分項(xiàng)目領(lǐng)先了X3430達(dá)5倍之多。
#p#
SiSoftware Sandra是一款很不錯(cuò)的軟件,但是對(duì)于Sandy Bridge平臺(tái)來(lái)說(shuō),原來(lái)的2010版本已經(jīng)不能使用,而目前提供免費(fèi)下載的版本型號(hào)為2011Lite。相比我們之前使用的Business版本來(lái)說(shuō),Lite版簡(jiǎn)化了許多的功能,還好我們常用的測(cè)試項(xiàng)目都還在。
在成績(jī)分析前我們必須要清楚,這兩個(gè)相對(duì)比的服務(wù)器平臺(tái)所配的處理器分屬于英特爾至強(qiáng)5500和5600前后兩個(gè)不同的系列,雖然二者每個(gè)處理器都是4個(gè)核心,但是二者的工作頻率卻有比較大的差距,聯(lián)想萬(wàn)全R525 G3采用的至強(qiáng)E5620的工作主頻為2.4GHz,是至強(qiáng)5600系列中主頻最低的,而對(duì)比服務(wù)器平臺(tái)所選用的至強(qiáng)X5570卻是至強(qiáng)5500系列中工作主頻最高的,為2.93GHz。接下來(lái)的對(duì)比也將是兩個(gè)處理器配置懸殊的服務(wù)器平臺(tái)間的較量。
|
SiSoftware Sandra Lite 2011
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275 | 至強(qiáng)X3430 |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Lynnfield |
| Processor Arithmetic Benchmark 處理器算術(shù)運(yùn)算測(cè)試 |
||
|---|---|---|
| Dhrystone ALU | 136.74GIPS |
62244MIPS
|
| Dhrystone ALU vs SPEED | 35.98MIPS/MHz | 48.75MIPS/MHz |
| Whetstone iSSE3 | 83.43 GFLOPS |
29187MFLOPS
|
| Dhrystone iSSE3 vs SPEED | 21.96 MFLOPS/MHz |
12.16MFLOPS/MHz
|
| Processor Multi-Media Benchmark 處理器多媒體測(cè)試 |
||
| Multi-Media Int x16 iSSE4.1 | 201.26MPixel/s |
106.74MPixel/s
|
| Multi-Media Int x16 iSSE4.1 vs SPEED | 78.26 kPixels/s/MHz |
44.48kPixels/s/MHz
|
| Multi-Media Float x8 iSSE2 | 153MPixel/s |
81.28MPixel/s
|
| Multi-Media Float x8 iSSE2 vs SPEED | 59.48 kPixels/s/MHz |
33.87kPixels/s/MHz
|
| Multi-Media Double x4 iSSE2 | 83.54MPixel/s |
42.24MPixel/s
|
| Multi-Media Double x4 iSSE2 vs SPEED | 32.49 kPixels/s/MHz |
17.60kPixels/s/MHz
|
| Multi-Core Efficiency Benchmark 處理器效能測(cè)試 |
||
| Inter-Core Bandwidth | 16 GB/s |
13.27GB/s
|
| Inter-Core Bandwidth vs SPEED | 4.29 MB/s/MHz |
5.66MB/s/MHz
|
| Inter-Core Latency(越小越好) | 42.4ns |
60ns
|
| Inter-Core Latency vs SPEED(越小越好) | 0.01ns/MHz |
0.03ns/MHz
|
| .NET Arithmetic Benchmark .NET算術(shù)運(yùn)算測(cè)試 |
||
| Dhrystone .NET | 18GIPS |
11567MIPS
|
| Dhrystone .NET vs SPEED | 5MIPS/MHz |
4.82MIPS/MHz
|
| Whetstone .NET | 50.1 GFLOPS |
26730MFLOPS
|
| Whetstone .NET vs SPEED | 13.92MFLOPS/MHz |
11.14MFLOPS/MHz
|
| .NET Multi-Media Benchmark .NET多媒體測(cè)試 |
||
| Multi-Media Int x1 .NET | 37.72 MPixel/s |
21.93MPixel/s
|
| Multi-Media Int x1 .NET vs SPEED | 9.93MPixel/s |
9.14kPixels/s/MHz
|
| Multi-Media Float x1 .NET | 13.7MPixel/s |
7.26MPixel/s
|
| Multi-Media Float x1 .NET vs SPEED | 3.61kPixels/s/MHz |
3.03kPixels/s/MHz
|
| Multi-Media Double x1 .NET | 27.22 MPixel/s |
11.82MPixel/s
|
| Multi-Media Double x1 .NET vs SPEED | 7.16 kPixels/s/MHz |
4.92kPixels/s/MHz
|
依然是一邊倒的成績(jī),我們甚至覺(jué)得選擇X3430作為對(duì)比產(chǎn)品有點(diǎn)怠慢了E3-1275。不過(guò)沒(méi)辦法,單路服務(wù)器處理器數(shù)量太少,我們手中的數(shù)據(jù)有較為有限。
#p#
|
SiSoftware Sandra Lite 2011
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275 | 至強(qiáng)X3430 |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Lynnfield |
| Memory Bandwidth Benchmark 內(nèi)存帶寬測(cè)試 |
||
|---|---|---|
| Int Buff'd iSSE2 Memory Bandwidth | 17.37 GB/s |
13.78GB/s
|
| Float Buff'd iSSE2 Memory Bandwidth | 17.37GB/s |
13.77GB/s
|
| Memory Latency Benchmark 內(nèi)存延遲測(cè)試 |
||
| Memory(Random Access) Latency (越小越好) | 73.3ns |
89ns
|
| Speed Factor (越小越好) | 68.20 |
57.50
|
| Internal Data Cache | 4clocks | 4clocks |
| L2 On-board Cache | 11clocks | 9clocks |
| L3 On-board Cache | 35clocks | 47clocks |
| Cache and Memory Benchmark 緩存及內(nèi)存測(cè)試 |
||
| Cache/Memory Bandwidth | 97.76GB/s |
51.08GB/s
|
| Cache/Memory Bandwidth vs SPEED | 27.06MB/s/MHz |
21.79MB/s/MHz
|
| Speed Factor (越小越好) | 38.10 |
27.10
|
| Internal Data Cache | 427.84GB/s |
205.08GB/s
|
| L2 On-board Cache | 287.5GB/s |
175.49GB/s
|
內(nèi)存帶寬測(cè)試中,同樣是雙路的兩款平臺(tái)在性能上出現(xiàn)了較大的差異,特別是L3緩存的項(xiàng)目中差距較大,這都是環(huán)形總線的功勞。
#p#
CineBench是基于Cinem4D工業(yè)三維設(shè)計(jì)軟件引擎的測(cè)試軟件,用來(lái)測(cè)試對(duì)象在進(jìn)行三維設(shè)計(jì)時(shí)的性能,它可以同時(shí)測(cè)試處理器子系統(tǒng)、內(nèi)存子系統(tǒng)以及顯示子系統(tǒng),我們的平臺(tái)偏向于服務(wù)器多一些,因此就只有前兩個(gè)的成績(jī)具有意義。和大多數(shù)工業(yè)設(shè)計(jì)軟件一樣,CineBench可以完善地支持多核/多處理器,它的顯示子系統(tǒng)測(cè)試基于OpenGL。
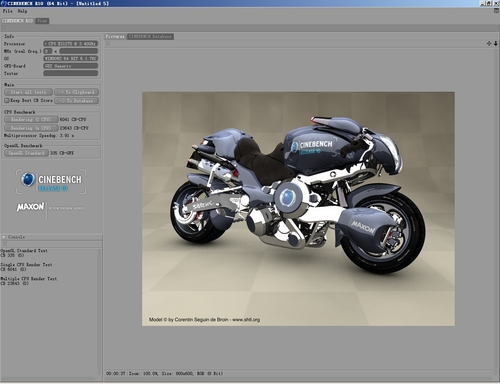
|
CineBench R10
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275 | 至強(qiáng)X3430 |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Lynnfield |
| CPU Benchmark | ||
|---|---|---|
| Rendering (1 CPU) | 6041 CB-CPU | 3868 CB-CPU |
| Rendering (x CPU) | 23643 CB-CPU | 12964 CB-CPU |
| Multiprocessor Speedup | 3.91x |
3.35x
|
| OpenGL Benchmark | ||
| OpenGL Standard | 335 CB-GFX | 7690 CB-GFX |
至強(qiáng)E3-1275處理器。
#p#
本次測(cè)試的至強(qiáng)E3-1275是E3系列的高端產(chǎn)品,具備了4核心8線程,性能非常強(qiáng)悍。下面,我們將關(guān)閉E3-1275的超線程功能,觀察在這個(gè)狀態(tài)下它的性能表現(xiàn),以便總結(jié)超線程技術(shù)對(duì)于Sandy Bridge處理器的影響。
|
SiSoftware Sandra Lite 2011
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275(開(kāi)啟) | 至強(qiáng)E3-1275(關(guān)閉) |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Sandy Bridge |
| Processor Arithmetic Benchmark 處理器算術(shù)運(yùn)算測(cè)試 |
||
|---|---|---|
| Dhrystone ALU | 136.74GIPS |
106.77GIPS
|
| Dhrystone ALU vs SPEED | 35.98MIPS/MHz | 28.86MIPS/MHz |
| Whetstone iSSE3 | 83.43 GFLOPS |
49.57 GFLOPS
|
| Dhrystone iSSE3 vs SPEED | 21.96 MFLOPS/MHz |
13.40MFLOPS/MHz
|
| Processor Multi-Media Benchmark 處理器多媒體測(cè)試 |
||
| Multi-Media Int x16 iSSE4.1 | 201.26MPixel/s |
163.79MPixel/s
|
| Multi-Media Int x16 iSSE4.1 vs SPEED | 78.26 kPixels/s/MHz |
63.69kPixels/s/MHz
|
| Multi-Media Float x8 iSSE2 | 153MPixel/s |
111.37 MPixel/s
|
| Multi-Media Float x8 iSSE2 vs SPEED | 59.48 kPixels/s/MHz |
43.3kPixels/s/MHz
|
| Multi-Media Double x4 iSSE2 | 83.54MPixel/s |
60.16MPixel/s
|
| Multi-Media Double x4 iSSE2 vs SPEED | 32.49 kPixels/s/MHz |
23.4kPixels/s/MHz
|
| Multi-Core Efficiency Benchmark 處理器效能測(cè)試 |
||
| Inter-Core Bandwidth | 16 GB/s |
8.84GB/s
|
| Inter-Core Bandwidth vs SPEED | 4.29 MB/s/MHz |
2.45MB/s/MHz
|
| Inter-Core Latency(越小越好) | 42.4ns |
40.2ns
|
| Inter-Core Latency vs SPEED(越小越好) | 0.01ns/MHz |
0.11ns/MHz
|
| .NET Arithmetic Benchmark .NET算術(shù)運(yùn)算測(cè)試 |
||
| Dhrystone .NET | 18GIPS |
15.81GIPS
|
| Dhrystone .NET vs SPEED | 5MIPS/MHz |
4.16MIPS/MHz
|
| Whetstone .NET | 50.1 GFLOPS |
29.34GFLOPS
|
| Whetstone .NET vs SPEED | 13.92MFLOPS/MHz |
7.72MFLOPS/MHz
|
| .NET Multi-Media Benchmark .NET多媒體測(cè)試 |
||
| Multi-Media Int x1 .NET | 37.72 MPixel/s |
29.17MPixel/s
|
| Multi-Media Int x1 .NET vs SPEED | 9.93MPixel/s |
7.68kPixels/s/MHz
|
| Multi-Media Float x1 .NET | 13.7MPixel/s |
8.16MPixel/s
|
| Multi-Media Float x1 .NET vs SPEED | 3.61kPixels/s/MHz |
2.15kPixels/s/MHz
|
| Multi-Media Double x1 .NET | 27.22 MPixel/s |
16.24MPixel/s
|
| Multi-Media Double x1 .NET vs SPEED | 7.16 kPixels/s/MHz |
4.27kPixels/s/MHz
|
對(duì)比開(kāi)啟與關(guān)閉超線程的測(cè)試數(shù)據(jù)我們發(fā)現(xiàn),處理器計(jì)算性能方面,開(kāi)啟超線程之后會(huì)有30%-50%左右的性能提升,多媒體方面的性能提升為30%左右。而在.NET測(cè)試中,這個(gè)數(shù)值被縮小到了15%-30%,效能測(cè)試的時(shí)候兩者的差距大約為40%。總體而言,在開(kāi)啟超線程之后,Sandy Bridge至強(qiáng)處理器在運(yùn)算性能上會(huì)有30%左右的提升,這個(gè)數(shù)值與Nehalem與Westmere的成績(jī)是差不多的,事實(shí)上我們也沒(méi)發(fā)現(xiàn)Sandy Bridge在超線程方面有什么特別大的改動(dòng)。
#p#
接下來(lái)同樣是開(kāi)啟與關(guān)閉超線程下的內(nèi)存/緩存系統(tǒng)測(cè)試。
|
SiSoftware Sandra Lite 2011
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275(開(kāi)啟) | 至強(qiáng)E3-1275(關(guān)閉) |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Sandy Bridge |
| Memory Bandwidth Benchmark 內(nèi)存帶寬測(cè)試 |
||
|---|---|---|
| Int Buff'd iSSE2 Memory Bandwidth | 17.37 GB/s |
17.78GB/s
|
| Float Buff'd iSSE2 Memory Bandwidth | 17.37GB/s |
17.78GB/s
|
| Memory Latency Benchmark 內(nèi)存延遲測(cè)試 |
||
| Memory(Random Access) Latency (越小越好) | 73.3ns |
73.2ns
|
| Speed Factor (越小越好) | 68.20 |
68.30
|
| Internal Data Cache | 4clocks | 4clocks |
| L2 On-board Cache | 11clocks | 11clocks |
| L3 On-board Cache | 35clocks | 35clocks |
| Cache and Memory Benchmark 緩存及內(nèi)存測(cè)試 |
||
| Cache/Memory Bandwidth | 97.76GB/s |
100.55GB/s
|
| Cache/Memory Bandwidth vs SPEED | 27.09MB/s/MHz |
27.09MB/s/MHz
|
| Speed Factor (越小越好) | 38.10 |
39.10
|
| Internal Data Cache | 424.22GB/s |
424.22GB/s
|
| L2 On-board Cache | 355.42GB/s |
355.42GB/s
|
相對(duì)比的兩臺(tái)服務(wù)器所作用的處理器都采用了集成內(nèi)存控制器的設(shè)計(jì),由于工作主頻的不同,這兩款不同處理器的QPI傳輸并不一樣,聯(lián)想萬(wàn)全R525 G3所用處理器的QPI帶寬為5.86GT/s,而對(duì)比平臺(tái)的至強(qiáng)X5570處理器的QPI為6.4GT/s。不過(guò)這兩個(gè)服務(wù)器平臺(tái)的內(nèi)存的實(shí)際工作頻率卻并不一樣,雖然在測(cè)試中兩個(gè)平臺(tái)所使用的內(nèi)存條都是DDR3 1333,聯(lián)想萬(wàn)全R525 G3共安裝了6條,它的實(shí)際工作頻率為1066,而對(duì)比平臺(tái)共裝配了18條內(nèi)存,內(nèi)存工作頻率只能達(dá)到800MHz,也正是以上這一內(nèi)存安裝方式的不同,直接導(dǎo)致了處理器QPI頻率較低的聯(lián)想萬(wàn)全R525 G3內(nèi)存帶寬成績(jī)占了上風(fēng)。
#p#
最后我們進(jìn)行的是CineBench項(xiàng)目的測(cè)試。CineBench測(cè)試中有一個(gè)處理器核心能效比的內(nèi)容,我們相信這個(gè)項(xiàng)目更可以看出開(kāi)關(guān)超線程之后的性能差距。
|
CineBench R10
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275(開(kāi)啟) | 至強(qiáng)E3-1275(關(guān)閉) |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Sandy Bridge |
| CPU Benchmark | ||
|---|---|---|
| Rendering (1 CPU) | 6041 CB-CPU | 6188 CB-CPU |
| Rendering (x CPU) | 23643 CB-CPU | 20886 CB-CPU |
| Multiprocessor Speedup | 3.91x | 3.38x |
| OpenGL Benchmark | ||
| OpenGL Standard | 335 CB-GFX | 336 CB-GFX |
CineBench10所進(jìn)行測(cè)試項(xiàng)目在于考察單核心與多核心的性能對(duì)比。我們可以看到,對(duì)于CineBench R10來(lái)說(shuō),開(kāi)啟超線程下的MS成績(jī)?yōu)?.91,關(guān)閉的時(shí)候只有3.38,相比之下提升了15.6%。
|
CineBench R11.5
|
||
| 產(chǎn)品名稱 | 至強(qiáng)E3-1275(開(kāi)啟) | 至強(qiáng)E3-1275(關(guān)閉) |
| 平臺(tái)類(lèi)型 | 單路Sandy Bridge | 單路Sandy Bridge |
| CPU Benchmark | ||
|---|---|---|
| Rendering (1 CPU) | 1.52 pts | 1.42 pts |
| Rendering (x CPU) | 6.84 pts | 5.59 pts |
| MP Ratio | 4.51x | 3.95x |
| OpenGL Benchmark | ||
| OpenGL | - | - |
而在最新的Cinebench R11.5進(jìn)行的測(cè)試中,兩者的成績(jī)差距并沒(méi)有拉大,依然在15%左右。因?yàn)镃ineBench只考察核心與效能的關(guān)系,而之前我們的測(cè)試項(xiàng)目更多還依賴于整體平臺(tái)的性能,因此單純從提升來(lái)說(shuō),CineBench只能看到15%的提升,但是開(kāi)啟超線程之后,整體平臺(tái)的提升會(huì)更高一些。
#p#
Tick-Tock戰(zhàn)略的出現(xiàn),使英特爾避免了在同一年更新制程和微架構(gòu),有效的規(guī)避了新平臺(tái)、新制程出現(xiàn)所帶來(lái)的商業(yè)風(fēng)險(xiǎn)。而將新品首先試水桌面平臺(tái),進(jìn)而在推廣到服務(wù)器平臺(tái)也是非常明智的舉措,這次Sandy Bridge處理器就充分說(shuō)明了這個(gè)問(wèn)題。事實(shí)上,由于配套芯片組的問(wèn)題,Sandy Bridge處理器在推廣之初就遭遇挫折,幸好英特爾的反應(yīng)夠快,在服務(wù)器平臺(tái)上我們并沒(méi)有發(fā)現(xiàn)這樣的問(wèn)題。而隨著至強(qiáng)Sandy Bridge處理器的推出,也標(biāo)志著英特爾在桌面和服務(wù)器兩個(gè)平臺(tái)上全面轉(zhuǎn)向了新的微架構(gòu),Tock時(shí)代終于到來(lái)了。

至強(qiáng)Sandy Bridge處理器終于現(xiàn)身了
Sandy Bridge處理器相比上一代的產(chǎn)品有了非常大的改進(jìn),包括AVX指令集、環(huán)形總線架構(gòu)、全新System Agent系統(tǒng)助手、革命性的整合GPU等內(nèi)容。事實(shí)上,Sandy Bridge最大的特征在于全32nm整合CPU和GPU,但對(duì)于服務(wù)器來(lái)說(shuō),GPU作為多媒體工具來(lái)說(shuō)并沒(méi)有實(shí)際的用處,除非可以通過(guò)GPU加速運(yùn)算。
我們?cè)賮?lái)看看性能。相比上一代的至強(qiáng)3400系列來(lái)說(shuō),至強(qiáng)E3系列在性能上有了大幅度的提升, 有著至少30%的性能優(yōu)勢(shì),部分項(xiàng)目的性能優(yōu)勢(shì)得到了翻倍。相比之下,超線程方面自從Nehalem開(kāi)始為至強(qiáng)處理器增加了這一功能之后,在Sandy Bridge上面我們并沒(méi)有看到明顯的革新。
對(duì)于至強(qiáng)系列來(lái)說(shuō),E3僅僅是低端的入門(mén)版本,今年英特爾主推的依然是面向雙路服務(wù)器應(yīng)用的E5系列,不過(guò)這個(gè)系列要等到下半年才可以看到。今天,英特爾發(fā)布了E7系列的產(chǎn)品,雖然使用了全新的命名,但是E7卻是我們熟知的Westmere-EX。
我們相信,隨著新一代Sandy Bridge至強(qiáng)處理器的出現(xiàn),我們?cè)诜?wù)器領(lǐng)域可以看到越來(lái)越多的、性能更為出色的產(chǎn)品出現(xiàn)。我們期待著這一天的早日到來(lái)。
【編輯推薦】










