常見的多級緩存下保證本地緩存的數據一致性的幾種方案
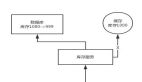
在高并發下我們通常采用Redis來扛住大流量的沖擊,但是我們知道Redis單分片的寫入瓶頸在2萬左右,讀瓶頸在10萬左右,那么在超高并發下Redis是沒有辦法支撐的,所以我們需要加多級緩存來應對,如下圖所示的多級緩存原理圖:
 圖片
圖片
在多級緩存中,如果應用服務部署到多個服務器上,那么本地緩存就有多份,如何保證本地緩存數據的一致性呢?下面我們來介紹幾種常見的保證本地緩存數據一致性的方案。
1、MQ同步方案
 圖片
圖片
當數據庫的數據完成同步Redis之后,發送一條MQ消息用于刪除本地緩存數據,此時每個有本地緩存的應用服務在接收到MQ消息后會處理本地緩存的數據,從而達到數據的最終一致性。
MQ同步方案是多級緩存保證數據最終一致性使用最多的企業級開發方案,因為此方案能夠實現快速同步數據;并且MQ也可以保證所有的節點能夠收到消息通知,進而處理本地緩存數據;MQ同步方案同步方案需要引入第三方的MQ組件,增加系統的復雜性,并且對于實時性要求高的場景,此方案是不適用的。
2、采用Redis的訂閱/發布同步方案
 圖片
圖片
Redis本身就有訂閱/發布的功能,我們采用它的訂閱/發布來替代MQ組件,這種使用Redis訂閱/發布的方案不僅實現上簡單(使用Redis原生的功能),而且也更加的輕量,不需要去依賴第三方MQ組件。
Redis訂閱/發布同步數據的缺點也比較明顯,一方面相對于MQ方案的實現方案,它的可靠性差(訂閱者離線丟消息),另一方面消息不保存,無持久化機制。所以這種方案一般不推薦使用。
3、版本號校驗方案
 圖片
圖片
在本地緩存中,不僅要保存業務數據,而且還要保存一個數據的版本號。然后每次在查詢本地緩存的時候,還要查詢Redis中數據的版本號,最后將本地緩存的數據版本號與Redis的數據版本號去做對比,如果二者的數據版本號一致,那么就表示數據是一致的,返回本地緩存數據;否則,由于版本號不一致,那么表示Redis中與本地緩存數據不一致,需要重新拉取最新的數據。
版本號校驗方案違背了本地緩存設計的初衷,之所以使用本地緩存,就是為了不頻繁地去請求Redis,進而達到減輕Redis的壓力的目的。但是版本號校驗方案每次查數據的時候都要查本地緩存和Redis緩存,所以這種利用CAS樂觀鎖的方式來保證數據一致性的方案只能作為參考的備選方案,高并發下不推薦使用。
4、采用自動刷新同步方案
 圖片
圖片
本地緩存常見的有Caffeine,它有一個自動刷新的功能,即可以設置自動刷新時間(如設置30秒)去自動去同步Redis中的數據,但是在刷新時間的時間窗口之內依然會存在數據的不一致性情況。如果對數據的一致性要求不嚴格的業務場景下,我們可以采用這種方式,因為它非常的簡單易用,不需要額外的開發實現數據一致性的功能。
對于沒有自動刷新數據能力本地緩存,我們可以采用定時任務方式來定時同步Redis中的數據,但是也一樣會存在數據的不一致性情況。
總結:
(1)本地緩存數據同步的方案中,常用的是MQ數據同步的方案和自動刷新同步方案。
(2)本地緩存也要設置過期時間,目的是即使本地緩存和Redis中數據存在不一致,那么到了過期時間后,本地緩存也會自動的同步最新數據。