查詢 MySQL 定位優(yōu)化技巧,從10s 優(yōu)化到 300ms
今天分享一下如何快速定位慢查詢SQL以及優(yōu)化。
1.如何定位并優(yōu)化慢查詢SQL?
一般有3個思考方向:
- 根據(jù)慢日志定位慢查詢sql
- 使用explain等工具分析sql執(zhí)行計劃
- 修改sql或者盡量讓sql走索引
2.如何使用慢查詢?nèi)罩荆?/span>
先給出步驟,后面說明,有3個步驟:
1)開啟慢查詢?nèi)罩?/span>
首先開啟慢查詢?nèi)罩荆蓞?shù)slow_query_log決定是否開啟,在MySQL命令行下輸入下面的命令:
set global slow_query_log=on;默認環(huán)境下,慢查詢?nèi)罩臼顷P(guān)閉的,所以這里開啟。
2)設(shè)置慢查詢閾值
set global long_query_time=1;只要你的SQL實際執(zhí)行時間超過了這個閾值,就會被記錄到慢查詢?nèi)罩纠锩妗_@個閾值默認是10s,線上業(yè)務(wù)一般建議把long_query_time設(shè)置為1s,如果某個業(yè)務(wù)的MySQL要求比較高的QPS,可設(shè)置慢查詢?yōu)?.1s。
發(fā)現(xiàn)慢查詢及時優(yōu)化或者提醒開發(fā)改寫。一般測試環(huán)境建議long_query_time設(shè)置的閥值比生產(chǎn)環(huán)境的小,比如生產(chǎn)環(huán)境是1s,則測試環(huán)境建議配置成0.5s。便于在測試環(huán)境及時發(fā)現(xiàn)一些效率的SQL。
甚至某些重要業(yè)務(wù)測試環(huán)境long_query_time可以設(shè)置為0,以便記錄所有語句。并留意慢查詢?nèi)罩镜妮敵觯暇€前的功能測試完成后,分析慢查詢?nèi)罩久款愓Z句的輸出,重點關(guān)注Rows_examined(語句執(zhí)行期間從存儲引擎讀取的行數(shù)),提前優(yōu)化。
3)確定慢查詢?nèi)罩镜奈募吐窂?/span>
show global variables like 'slow_query_log_file'
結(jié)果會發(fā)現(xiàn)慢日志默認路徑就是MySQL的數(shù)據(jù)目錄,我們可以來看一下MySQL數(shù)據(jù)目錄。
show global variables like 'datadir';
不用關(guān)注這里為什么不是MySQL 8.0,這和版本沒什么關(guān)系的。
來,直接上菜,干巴巴的定義我自己都看不下去。
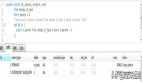
我們先來查看一下變量,我框出了需要注意的點。
查詢帶有quer的相關(guān)變量。
show global variables like '%quer%';

這里設(shè)置慢查詢閾值為1s。
set global long_query_time=1;可以看到已經(jīng)修改過來了。

但是重啟mysql客戶端設(shè)置和統(tǒng)計慢查詢?nèi)罩緱l數(shù)就會清零,即所有配置修改會還原。
命令修改配置之后,在命令行net stop mysql關(guān)閉MySQL服務(wù),再net start mysql開啟MySQL服務(wù),接著執(zhí)行show global variables like '%quer%';會發(fā)現(xiàn)配置還原了。
在配置文件修改才能永久改變,否則重啟數(shù)據(jù)庫就還原了。
3.慢查詢例子演示,新手都能看懂
數(shù)據(jù)表結(jié)構(gòu),偷懶沒寫comment。
CREATE TABLE`person_info_large` (
`id`BIGINTUNSIGNEDNOTNULL AUTO_INCREMENT,
`account`VARCHAR (10),
`name`VARCHAR (20),
`area`VARCHAR (20),
`title`VARCHAR (20),
`motto`VARCHAR (50),
PRIMARY KEY (`id`),
UNIQUE(`account`),
KEY`index_area_title`(`area`,`title`)
) ENGINE = INNODB AUTO_INCREMENT = 1DEFAULTCHARSET = utf8這里的數(shù)據(jù)是200W條。請注意表結(jié)構(gòu),記住哪幾個字段有索引即可,后續(xù)圍繞這個表進行分析。

這個3.36s并不是實際執(zhí)行時間,實際執(zhí)行時間得去慢查詢?nèi)罩救タ?/span>Query_time參數(shù)。

可以看到Query_time: 6.337729s,超過了1s,所以會被記錄,一個select語句查詢這么久,簡直無法忍受。
圖中其他的參數(shù)解釋如下:
- Time:慢查詢發(fā)生的時間
- Query_time:查詢時間
- Lock_time:等待鎖表的時間
- Rows_sent:語句返回的行數(shù)
- Rows_exanined:語句執(zhí)行期間從存儲引擎讀取的行數(shù)
上面這種方式是用系統(tǒng)自帶的慢查詢?nèi)罩静榭吹模绻X得系統(tǒng)自帶的慢查詢?nèi)罩静环奖悴榭矗梢允褂?/span>pt-query-digest或者mysqldumpslow等工具對慢查詢?nèi)罩具M行分析。
注意:有的慢查詢正在執(zhí)行,結(jié)果已經(jīng)導(dǎo)致數(shù)據(jù)庫負載過高,而由于慢查詢還沒執(zhí)行完,因此慢查詢?nèi)罩究床坏饺魏握Z句,此時可以使用show processlist命令查看正在執(zhí)行的慢查詢。show processlist顯示哪些線程正在運行,如果有PROCESS權(quán)限,則可以看到所有線程。否則,只能看到當(dāng)前會話線程。
4.查詢語句慢怎么辦?explain帶你分析sql執(zhí)行計劃
根據(jù)上一節(jié)的表結(jié)構(gòu)可以知道,account是添加了唯一索引的字段。explain分析一下執(zhí)行計劃。

我們重點需要關(guān)注select_type、type、possible_keys、key、Extra這些列,我們來一一說明,看到select_type列,這里是SIMPLE簡單查詢,其他值下面給大家列出。

type列,這里是index,表示全索引掃描。

表格從上到下代表了sql查詢性能從最優(yōu)到最差,如果是type類型是all,說明sql語句需要優(yōu)化。
“注意:如果type = NULL,則表明個MySQL不用訪問表或者索引,直接就能得到結(jié)果,比如explain select sum(1+2);。
”possible_keys代表可能用到的索引列,key表示實際用到的索引列,以實際用到的索引列為準,這是查詢優(yōu)化器優(yōu)化過后選擇的,然后我們也可以根據(jù)實際情況強制使用我們自己的索引列來查詢。
Extra列,這里是Using index。


一定要注意,Extra中出現(xiàn)Using filesort、Using temporary代表MySQL根本不能使用索引,效率會受到嚴重影響,應(yīng)當(dāng)盡可能的去優(yōu)化。
出現(xiàn)Using filesort說明MySQL對結(jié)果使用一個外部索引排序,而不是從表里按索引次序讀到相關(guān)內(nèi)容,有索引就維護了B+樹,數(shù)據(jù)本來就已經(jīng)排好序了,這說明根本沒有用到索引,而是數(shù)據(jù)讀完之后再排序,可能在內(nèi)存或者磁盤上排序。也有人將MySQL中無法利用索引的排序操作稱為“文件排序”。
出現(xiàn)Using temporary表示MySQL在對查詢結(jié)果排序時使用臨時表,常見于order by和分組查詢group by。
回到上一個話題,我們看到account是添加了唯一索引的字段。explain分析了執(zhí)行計劃后。

直接按照account降序來查。

查看慢查詢?nèi)罩景l(fā)現(xiàn),使用索引之后,查詢200W條數(shù)據(jù)的速度快了2s。
接著我們分析一下查詢name的sql執(zhí)行計劃。

然后給name字段加上索引。

加上索引之后,繼續(xù)看看查詢name的sql執(zhí)行計劃。

對比一下前面name不加索引時的執(zhí)行計劃就會發(fā)現(xiàn),加了索引后,type由ALL全表掃描變成index索引掃描。order by并沒有 using filesort,而是using index,這里B+樹已經(jīng)將這個非聚集索引的索引字段的值排好序了,而不是等到查詢的時候再去排序。
接著我們繼續(xù)執(zhí)行查詢語句,此時name已經(jīng)是添加了索引的。

結(jié)果發(fā)現(xiàn),name添加索引之前,降序查詢name是花費6.337729s,添加索引之后,降序查詢name花費了3.479827s,原因就是B+樹的結(jié)果集已經(jīng)是有序的了。

5.當(dāng)主鍵索引、唯一索引、普通索引都存在,查詢優(yōu)化器如何選擇?
查詢一下數(shù)據(jù)的條數(shù),這里count(id),分析一下sql執(zhí)行計劃。

這里實際使用的索引是account唯一索引。
分析一下:實際使用哪個索引是查詢優(yōu)化器決定的,B+樹的葉子結(jié)點就是鏈表結(jié)構(gòu),遍歷鏈表就可以統(tǒng)計數(shù)量,但是這張表,有主鍵索引、唯一索引、普通索引,優(yōu)化器選擇了account這個唯一索引,這肯定不會使用主鍵索引,因為主鍵索引是聚集索引,每個葉子包含具體的一個行記錄(很多列的數(shù)據(jù)都在里面),而非聚集索引每個葉子只包含下一個主鍵索引的指針,很顯然葉子結(jié)點包含的數(shù)據(jù)是越少越好,查詢優(yōu)化器就不會選擇主鍵索引。
當(dāng)然,也可以強制使用主鍵索引,然后分析sql執(zhí)行計劃。

我們看一下優(yōu)化器默認使用唯一索引大致執(zhí)行時間676ms。

強制使用主鍵索引大致執(zhí)行時間779ms。

我們可以用force index強制指定索引,然后去分析執(zhí)行計劃看看哪個索引是更好的,因為查詢優(yōu)化器選擇索引不一定是百分百準確的,具體情況可以根據(jù)實際場景分析來確定是否使用查詢優(yōu)化器選擇的索引。