揭秘MySQL優化器:為何索引在手卻選擇全表掃描?
前言:一個令人困惑的選擇
1 一個費解的SQL現象
1.1 表結構
1.2 耗時較久的SQL(10秒以上)
1.3 分析下執行計劃
1.4 explain的進階用法
1.5 分析執行計劃
2 查詢 SQL 語句執行流程
2.1 查詢優化器
2.2 執行成本
2.3 MySQL 5.7 版本的默認成本常數
3 執行成本分析
3.1 表統計信息
3.2 命令2 (指定索引) 的執行成本分析
3.3 命令1 (未指定索引) 的執行成本分析
4 優化
5 總結
前言:一個令人困惑的選擇
你是否曾遇到這樣的情況:明明表上有合適的索引,但explain的結果卻顯示 MySQL 選擇了全表掃描?這背后其實是一個看不見的指揮家——MySQL 優化器——基于一系列「成本常數」做出的決策。
今天,我們將深入探索 MySQL 成本常數的奧秘,揭開查詢優化背后的神秘面紗。
1.一個費解的SQL現象
1.1 表結構
CREATE TABLE
`mapping_filter_record` (
`id`bigint (20) NOTnull AUTO_INCREMENT,
`source_type`int (11) NOTnullCOMMENT'來源類型',
`source_id`varchar(64) NOTnullCOMMENT'來源方id',
-- ... 其他字段省略
PRIMARY KEY (`id`),
KEY`idx_source_type` (`source_type`, `update_time`) USING BTREE,
KEY`idx_source_id` (`source_id`, `source_type`, `state`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 290240042300201321DEFAULTCHARSET = utf8mb4 COMMENT = '商品發布攔截記錄表';1.2 耗時較久的SQL(10秒以上)
select *
from dbzz_ypofflinemart.mapping_filter_record
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;1.3 分析下執行計劃
需要表數據符合一定情況才會發生以下情況。
explain
select *
from dbzz_ypofflinemart.mapping_filter_record
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
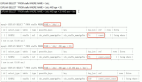
LIMIT 1;執行計劃結果:
令人困惑的是:使用了主鍵索引(PRIMARY),而非期望的 idx_source_id 索引。
1.4 explain的進階用法
explain可以輸出四種格式:傳統格式、json格式、tree格式以及可視化輸出。
傳統的explain工具只告訴我們結果,沒有告訴我們為什么。而json格式是四種格式里面輸出信息最詳盡的格式,里面包含了執行的成本信息。
我們加上format=json分析下結果。
執行命令1 (未指定索引):
explain format = json
select *
from dbzz_ypofflinemart.mapping_filter_record
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;得到執行計劃1:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "3865.20"
},
"ordering_operation": {
"using_filesort": false,
"table": {
"table_name": "mapping_filter_record",
"access_type": "index",
"possible_keys": [
"idx_source_type",
"idx_source_id"
],
"key": "PRIMARY",
"used_key_parts": [
"id"
],
"key_length": "8",
"rows_examined_per_scan": 501,
"rows_produced_per_join": 3221,
"filtered": "4.26",
"cost_info": {
"read_cost": "3221.00",
"eval_cost": "644.20",
"prefix_cost": "3865.20",
"data_read_per_join": "92M"
}
}
}
}
}強制指定使用idx_source_id索引,再分析執行計劃。 執行 命令2 (指定索引):
explain format = json
select *
from dbzz_ypofflinemart.mapping_filter_record
FORCE INDEX(idx_source_id)
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;得到執行計劃2:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "3865.20"
},
"ordering_operation": {
"using_filesort": true,
"table": {
"table_name": "mapping_filter_record",
"access_type": "ref",
"possible_keys": [
"idx_source_id"
],
"key": "idx_source_id",
"used_key_parts": [
"source_id",
"source_type"
],
"key_length": "262",
"ref": [
"const",
"const"
],
"rows_examined_per_scan": 3221,
"rows_produced_per_join": 3221,
"filtered": "100.00",
"cost_info": {
"read_cost": "3221.00",
"eval_cost": "644.20",
"prefix_cost": "3865.20",
"data_read_per_join": "92M"
}
}
}
}
}1.5 分析執行計劃
對比兩個 SQL 的執行成本和排序:
命令 | query_cost | using_filesort |
命令1 | 3865.20 | false |
命令2 | 3865.20 | true |
優化器認為使用PRIMARY聚簇索引和idx_source_id二級索引的查詢數據成本相同,但是使用PRIMARY聚簇索引可以按索引順序讀取,無需再次進行排序操作,因此優化器選擇了使用PRIMARY聚簇索引來執行該 SQL。
2.查詢 SQL 語句執行流程
2.1 查詢優化器
優化器的工作流程可以簡化為四個步驟:
- 解析 SQL,理解查詢意圖;
- 生成多種可能的執行方案;
- 基于成本常數計算每種方案的代價;
- 選擇成本最低的方案執行。
 圖片
圖片
2.2 執行成本
下面需要先介紹一些比較枯燥的概念。
SQL執行總成本 = CPU成本 + I/O成本
- CPU成本
讀取以及檢測記錄是否滿足對應的搜索條件、對結果集進行排序等這些操作損耗的時間稱之為CPU成本。
- I/O成本
我們的表經常使用的MyISAM、InnoDB存儲引擎都是將數據和索引都存儲到磁盤上的,當我們想查詢表中的記錄時,需要先把數據或者索引加載到內存中然后再操作。將數據從磁盤加載到內存的過程所損耗的時間,稱為I/O成本。
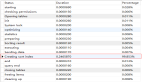
2.3 MySQL 5.7 版本的默認成本常數
在 MySQL 中,成本常數(Cost Constants)是查詢優化器用來評估不同執行計劃的資源消耗的固定數值。這些常數幫助優化器估算執行計劃的I/O和CPU成本,從而選擇最優的執行計劃。
Server層一些操作對應的成本常數:
 圖片
圖片
存儲引擎層一些操作對應的成本常數:
 圖片
圖片
3.執行成本分析
3.1 表統計信息
查詢表的一些預估信息,用于成本計算。
show table status like 'mapping_filter_record';Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free |
1615460 | 9396 | 15180234752 | 0 | 552239104 | 4194304 |
3.2 命令2 (指定索引) 的執行成本分析
先根據非聚簇索引(idx_source_id)查詢出對應數據的主鍵,然后通過主鍵回表查詢、篩選需要的數據。
 圖片
圖片
對命令2的執行成本計算如下:
- 非聚簇索引CPU成本 = 讀取的記錄數 × 讀取一條記錄的成本 = 1(等值查詢定位到單個索引位置) × 0.2(row_evaluate_cost)
- 非聚簇索引I/O成本:1(等值查詢定位到單個索引位置) × 1(io_block_read_cost)
- 回表CPU成本 = 3221(rows_examined_per_scan) × 0.2(row_evaluate_cost)
- 回表IO成本:3221(rows_examined_per_scan)× 1(io_block_read_cost)
- 總成本 = 3865.2(非聚簇索引的訪問成本相對于回表成本可以忽略不計)
計算的成本3865.2和執行計劃中的成本3865.20是一致的。
3.3 命令1 (未指定索引) 的執行成本分析
命令1使用主鍵索引,全表掃描的成本是要比正確使用非聚簇索引的成本要高很多的。實際得到的成本確實相同的。
依據1: 我們注意到rows_examined_per_scan(掃描行數)為501這是個很突兀的值。增加需要的結果數量得到以下的數據:
執行語句 | 使用的索引 | 掃描行數 | 實際執行時間 |
select * from xxx WHERE xxx order by id asc LIMIT 1; | PRIMARY | 501 | 19.4秒 |
select * from xxx WHERE xxx order by id asc LIMIT 2; | PRIMARY | 1003 | 20.2秒 |
select * from xxx WHERE xxx order by id asc LIMIT 6; | PRIMARY | 3009 | 20.24秒 |
select * from xxx WHERE xxx order by id asc LIMIT 7; | idx_source_id | 3221 | 0.026秒 |
依據2: 表中總數據為 1,615,460 條,符合WHERE條件的數據共 3,221,1,615,460 除以 3,221 約等于 501。
推斷:
- MySQL 優化器假設數據是均勻分布的,據此估算出每掃描 501 條數據,便可找到一條符合條件的記錄。這樣查詢的效率比通過非聚簇索引再回表的效率高。
- 當使用limit時,MySQL 的優化器會嘗試通過全表掃描的方式來查詢數據。當掃描行數小于非聚簇索引的掃描行數時,優化器以掃描行數 3221 作為依據計算成本。
以上是基于我遇到的情況基于 MySQL 5.7版本進行的分析,并未找到明確官方說明,有不當之處歡迎大家討論、指正。
4.優化
雖然 MySQL 按照數據均勻分布的假設使用了主鍵索引,但實際的情況查詢的數據大多在表中靠后的位置,就導致了需要掃描百萬行才能找到第一條符合條件的數據。多個此類 SQL 同時執行,會造成數據庫負載過高,進而對相關業務服務產生重大影響。
針對這種情況有很多優化思路。本例中我采用的優化方法是改為子查詢,引導優化器優先使用高效的索引,避免其因成本誤判而選擇全表掃描。
SELECT *
FROM mapping_filter_record
WHEREid = (
SELECTid
FROM mapping_filter_record
WHERE source_type = 9401003AND source_id = '1814613774586351713'
ORDERBYidASC
LIMIT1
);5.總結
這個案例深刻揭示了:
- MySQL 優化器基于成本計算而非直覺進行決策;
- 成本常數是優化器評估執行計劃的核心依據;
- 統計信息的準確性直接影響優化器的選擇;
- 理解成本計算模型是 SQL 性能優化的關鍵。
通過深入理解 MySQL 優化器的工作原理,我們能夠更好地設計索引和優化查詢,提升數據庫整體性能。
思考題:在你的項目中,是否遇到過類似索引失效的情況?歡迎在評論區分享你的經驗和解決方案!
關于作者
路科恒,轉轉JAVA開發工程師,主要負責采貨俠保賣業務的技術方案設計、開發等相關工作。